Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Dit artikel helpt u bij het oplossen van problemen die optreden tijdens automatische failover in Microsoft SQL Server.
Oorspronkelijke productversie: SQL Server
Oorspronkelijk KB-nummer: 2833707
Samenvatting
SQL Server AlwaysOn-beschikbaarheidsgroepen kunnen worden geconfigureerd voor automatische failover. Als er een statusprobleem wordt gedetecteerd op het exemplaar van SQL Server dat als host fungeert voor de primaire replica, kan de primaire rol worden overgezet naar de automatische failoverpartner (secundaire replica). De secundaire replica kan echter niet altijd worden overgezet naar de primaire rol. In sommige gevallen kan deze alleen worden overgezet naar de RESOLVING rol. In deze situatie heeft geen replica de primaire rol, tenzij de primaire replica terugkeert naar een goede status. Bovendien zijn de beschikbaarheidsdatabases niet toegankelijk.
In dit artikel vindt u enkele veelvoorkomende oorzaken van mislukte automatische failover en worden de stappen besproken die u kunt uitvoeren om de oorzaak van deze fouten vast te stellen.
Symptomen als een automatische failover is geactiveerd
Wanneer een automatische failover wordt geactiveerd op het exemplaar van SQL Server dat als host fungeert voor de primaire replica, wordt de secundaire replica overgezet naar de RESOLVING rol en vervolgens naar de primaire rol. Hoewel het proces is geslaagd, worden foutvermeldingen vastgelegd in het SQL Server-logboekrapport dat lijkt op de volgende tekst:
The state of the local availability replica in availability group '\<Group name>' has changed from 'RESOLVING_NORMAL' to 'PRIMARY_PENDING'
The state of the local availability replica in availability group '\<Group name>' has changed from 'PRIMARY_PENDING' to 'PRIMARY_NORMAL'

Notitie
De secundaire replica wordt overgezet van een RESOLVING_NORMAL status naar een PRIMARY_NORMAL status.
Symptomen als een automatische failover mislukt
Als een automatische failover-gebeurtenis niet lukt, wordt de secundaire replica niet overgezet naar de primaire rol. Daarom rapporteert de beschikbaarheidsreplica dat deze replica een RESOLVING status heeft. Bovendien rapporteren de beschikbaarheidsdatabases dat ze zich in een NOT SYNCHRONIZING status bevinden en hebben toepassingen geen toegang tot deze databases.
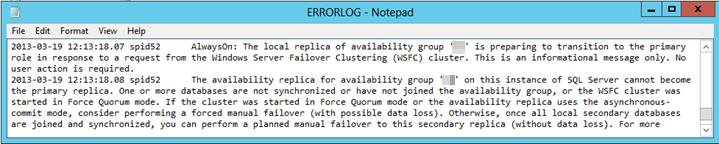
In de volgende afbeelding rapporteert SQL Server Management Studio bijvoorbeeld dat de secundaire replica een RESOLVING status heeft, omdat het automatische failoverproces de secundaire replica niet kan omzetten in de primaire rol.
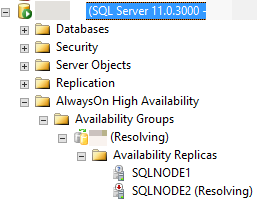
In de volgende secties worden verschillende mogelijke redenen besproken waarom automatische failover mogelijk niet slaagt en hoe u elke oorzaak kunt diagnosticeren.
Case 1: 'Maximumfouten in de opgegeven periode' is uitgeput
De beschikbaarheidsgroep heeft eigenschappen voor Windows-clusterresources, zoals de eigenschap Maximumfouten in de eigenschap Opgegeven periode . Deze eigenschap wordt gebruikt om onbeperkte verplaatsing van een geclusterde resource te voorkomen wanneer er meerdere knooppuntfouten optreden.
Als u wilt onderzoeken of dit de oorzaak is van een mislukte failover, controleert u het Windows-clusterlogboek (Cluster.log) en controleert u de eigenschap.
Stap 1: Controleer de gegevens in het Windows-clusterlogboek (Cluster.log)
Gebruik Windows PowerShell om het Windows-clusterlogboek te genereren op het clusterknooppunt dat als host fungeert voor de primaire replica. Voer hiervoor de volgende cmdlet uit in een PowerShell-venster met verhoogde bevoegdheid op het exemplaar van SQL Server dat als host fungeert voor de primaire replica:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15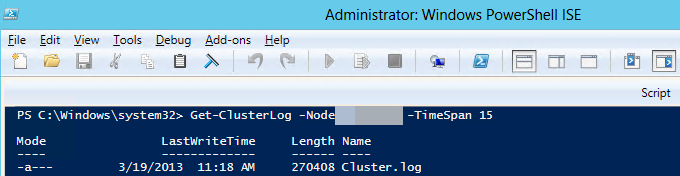
[! OPMERKINGEN BIJ DE]
- Bij
-TimeSpan 15de parameter in deze stap wordt ervan uitgegaan dat het probleem dat in de afgelopen 15 minuten wordt aangegeven, is opgetreden. - Standaard wordt het logboekbestand gemaakt in %WINDIR%\cluster\reports.
- Bij
Open het Cluster.log-bestand in Kladblok om het Windows-clusterlogboek te controleren.
Selecteer Zoeken bewerken> in Kladblok en zoek vervolgens naar de tekenreeks 'failoverCount' aan het einde van het bestand. In de resultaten ziet u een bericht dat lijkt op het volgende bericht:
Geen failover van groepsresourcenaam<>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2

Stap 2: De eigenschap Maximumfouten in de eigenschap Opgegeven periode controleren
Start Failoverclusterbeheer.
Selecteer Rollen in het navigatiedeelvenster.
Klik in het deelvenster Rollen met de rechtermuisknop op de geclusterde resource en selecteer Vervolgens Eigenschappen.
Selecteer het tabblad Failover en selecteer de maximumfouten in de opgegeven periodewaarde .
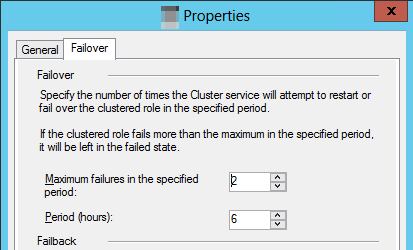
Notitie
Het standaardgedrag geeft aan dat als de geclusterde resource drie keer binnen zes uur mislukt, deze de status Mislukt moet blijven. Voor een beschikbaarheidsgroep betekent dit dat de replica in de
RESOLVINGstatus blijft.
Conclusie
Nadat u het logboek hebt geanalyseerd, ziet u dat de failoverCount-waarde van 3 groter is dan de berekende WaardeFailoverThreshold van 2. Daarom kan het Windows-cluster de failoverbewerking van de resource van de beschikbaarheidsgroep niet voltooien naar de failoverpartner.
Oplossing
U kunt dit probleem oplossen door de maximumfouten in de opgegeven periodewaarde te verhogen.
Notitie
Als u deze waarde verhoogt, wordt het probleem mogelijk niet opgelost. Er kan een kritieker probleem zijn waardoor de beschikbaarheidsgroep meerdere keren binnen een korte periode mislukt. Deze periode is standaard 15 minuten. Als u deze waarde verhoogt, kan dit ertoe leiden dat de beschikbaarheidsgroep vaker mislukt en de status Mislukt blijft. U wordt aangeraden agressieve probleemoplossing te gebruiken om te bepalen waarom automatische failover blijft optreden.
Case 2: Onvoldoende NT Authority\SYSTEM-accountmachtigingen
De DLL van de SQL Server Database Engine-resource maakt verbinding met het exemplaar van SQL Server dat als host fungeert voor de primaire replica met behulp van ODBC om de status te bewaken. De aanmeldingsreferenties die voor deze verbinding worden gebruikt, zijn het lokale SQL Server-aanmeldingsaccount NT AUTHORITY\SYSTEM . Dit lokale aanmeldingsaccount krijgt standaard de volgende machtigingen:
- Een beschikbaarheidsgroep wijzigen
- Verbinding maken met SQL
- Serverstatus weergeven
Als het NT AUTHORITY\SYSTEM aanmeldingsaccount geen van deze machtigingen heeft voor de automatische failoverpartner (de secundaire replica), kan SQL Server de statusdetectie niet starten wanneer er een automatische failover plaatsvindt. De secundaire replica kan daarom niet worden overgezet naar de primaire rol. Als u wilt onderzoeken en diagnosticeren of dit de oorzaak is, raadpleegt u het Windows-clusterlogboek. Hiervoor volgt u deze stappen:
Gebruik Windows PowerShell om het Windows-clusterlogboek op het clusterknooppunt te genereren. Voer hiervoor de volgende cmdlet uit in een PowerShell-venster met verhoogde bevoegdheid op het exemplaar van SQL Server dat als host fungeert voor de secundaire replica die niet is overgezet naar de primaire rol:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15
Open het Cluster.log-bestand in Kladblok om het Windows-clusterlogboek te controleren.
Foutvermelding zoeken die lijkt op de volgende tekst:
Kan de diagnostische opdracht niet uitvoeren. De gebruiker is niet gemachtigd om deze actie uit te voeren.
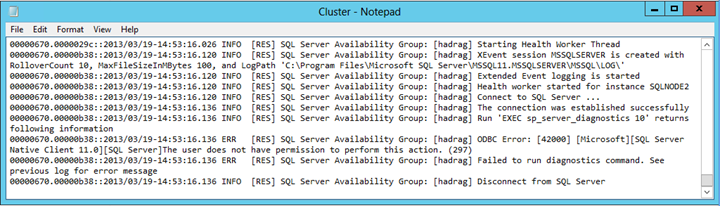
Conclusie
Het Cluster.log-bestand meldt dat er een machtigingsprobleem bestaat wanneer SQL Server de diagnostische opdracht uitvoert. In dit voorbeeld is de fout veroorzaakt door het verwijderen van de machtiging Serverstatus weergeven uit het NT AUTHORITY\SYSTEM aanmeldingsaccount op het exemplaar van SQL Server dat als host fungeert voor de secundaire replica van een automatische failoverpaar.
Oplossing
U kunt dit probleem oplossen door voldoende machtigingen te verlenen aan het NT AUTHORITY\SYSTEM aanmeldingsaccount voor de statusdetectie van de DLL van de SQL Server Database Engine-resource.
Case 3: De beschikbaarheidsdatabases hebben niet de status GESYNCHRONISEERD
Als u automatisch een failover wilt uitvoeren, moeten alle beschikbaarheidsdatabases die in de beschikbaarheidsgroep zijn gedefinieerd, een SYNCHRONIZED status hebben tussen de primaire replica en de secundaire replica. Wanneer een automatische failover optreedt, moet aan deze synchronisatievoorwaarde worden voldaan om ervoor te zorgen dat er geen gegevensverlies is. Dus als één beschikbaarheidsdatabase in de beschikbaarheidsgroep de synchronisatie of NOT SYNCHRONIZED status heeft, wordt de secundaire replica niet met succes overgezet naar de primaire rol.
Zie voor meer informatie over de vereiste voorwaarden voor een automatische failover de voorwaarden die vereist zijn voor een automatische failover en de synchrone doorvoerreplica's ondersteunen twee instellingensecties van failover- en failovermodi (AlwaysOn-beschikbaarheidsgroepen).
Als u wilt onderzoeken en diagnosticeren of dit de oorzaak is van een mislukte failover, raadpleegt u het FOUTENlogboek van SQL Server. Er moet een foutvermelding worden gevonden die lijkt op de volgende tekst:
Een of meer databases worden niet gesynchroniseerd of zijn niet toegevoegd aan de beschikbaarheidsgroep.
Voer de volgende stappen uit om te controleren of de beschikbaarheidsdatabases de SYNCHRONIZED status hebben:
Maak verbinding met de secundaire replica.
Voer het volgende SQL-script uit om de
is_failover_readywaarde voor alle beschikbaarheidsdatabases in de beschikbaarheidsgroep te controleren waarvoor geen failover is uitgevoerd.Notitie
Een waarde van nul voor een van de beschikbaarheidsdatabases kan automatische failover voorkomen. Deze waarde geeft aan dat de beschikbaarheidsdatabase niet
SYNCHRONIZEDwas.SELECT database_name, is_failover_ready FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id IN (SELECT replica_id FROM sys.dm_hadr_availability_replica_states)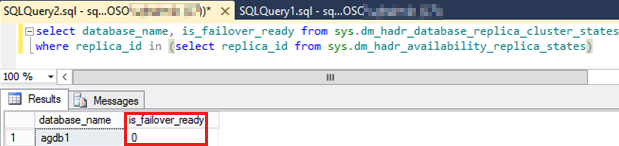
Conclusie
Een geslaagde automatische failover van de beschikbaarheidsgroep vereist dat alle beschikbaarheidsdatabases de SYNCHRONIZED status hebben. Zie Beschikbaarheidsmodi in AlwaysOn-beschikbaarheidsgroepen voor meer informatie over beschikbaarheidsmodi.
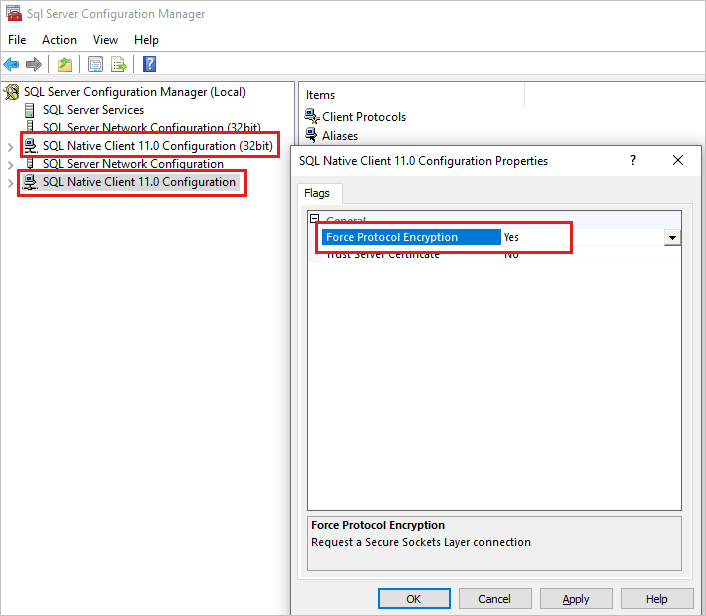
Case 4: De configuratie 'Geforceerde protocolversleuteling' is geselecteerd voor de clientprotocollen op secundaire replica (primaire doel) hoewel de replica niet is geconfigureerd voor versleuteling
Wanneer tijdens een failover op de primaire server een statusprobleem wordt gedetecteerd, probeert de cluster-DLL op failoverpartner (secundaire replica) verbinding te maken met lokale replica om statuscontrole te starten. Dit maakt deel uit van de overgang naar de primaire rol. Als de secundaire replica niet is geconfigureerd voor versleuteling, maar de instelling Force Protocol Encryption per ongeluk is ingesteld in de clientconfiguratie, mislukt de verbinding en kan de failover niet plaatsvinden.
Ga als volgt te werk om te controleren op deze configuratie:
- Start SQL Server Configuration Manager.
- Klik in het linkerdeelvenster met de rechtermuisknop op de SQL Native Client 11.0-configuratie en selecteer vervolgens Eigenschappen.
- Schakel in het dialoogvenster de instelling Force Protocol Encryption in. Als deze optie is ingesteld op Ja, wijzigt u de waarde in Nee.
- Test de failover opnieuw.
Conclusie
SQL Server AlwaysOn-statusbewaking maakt gebruik van een lokale ODBC-verbinding om de SQL Server-status te bewaken. Force Protocol Encryption moet worden ingeschakeld in de sectie Clientconfiguratie van SQL Server Configuration Manager alleen als SQL Server zelf is geconfigureerd voor geforceerde versleuteling in SQL Server Configuration Manager in de sectie SQL Server-netwerkconfiguratie. Zie Versleutelde verbindingen met de database-engine inschakelen voor meer informatie.
Case 5: Prestatieproblemen op secundaire replica of knooppunt zorgen ervoor dat AlwaysOn-statuscontroles mislukken
Voordat een failover van de primaire replica naar de secundaire replica wordt uitgevoerd, maakt SQL Server Database Engine resource DLL verbinding met de secundaire replica om de status van de replica vast te stellen. Als deze verbinding mislukt vanwege prestatieproblemen op de secundaire replica, treedt automatische failover niet op.
Als u wilt onderzoeken en diagnosticeren of dit de oorzaak is, voert u de volgende stappen uit:
Controleer het clusterlogboek op de secundaire replica om te controleren op het foutbericht 'Kan aanmeldingsproces niet voltooien vanwege vertraging bij het openen van de serververbinding'.
0000110c.00002bcc::2020/08/06-01:17:54.943 INFO [RCM] move of group AOCProd01AG from CO2ICMV3SQL09(1) to CO2ICMV3SQL10(2) of type MoveType::Manual is about to succeed, failoverCount=3, lastFailoverTime=2020/08/05-02:08:54.524 targeted=true 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]Unable to complete login process due to delay in opening server connection (0) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Could not connect to SQL Server (rc -1) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] SQLDisconnect returns following information 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08003] [Microsoft][ODBC Driver Manager] Connection not open (0) 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Failed to connect to SQL Server 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RHS] Online for resource AOCProd01AG failed.Deze situatie kan optreden als de failover wordt uitgevoerd naar een secundaire SQL Server-replica met een drukke bestaande workload. Hierdoor kan het antwoord van SQL Server op de poging tot de HADR-statusverbinding worden vertraagd en kan een geslaagde failoverpoging worden voorkomen.
Als u wilt bepalen of er sprake is van druk op systeemplanners, gebruikt u SQL Server Management Studio om het volgende script uit te voeren op de secundaire replica:
USE MASTER GO WHILE 1=1 BEGIN PRINT convert(varchar(20), getdate(),120) DECLARE @max INT; SELECT @max = max_workers_count FROM sys.dm_os_sys_info; SELECT GETDATE() AS 'CurrentDate', @max AS 'TotalThreads', SUM(active_Workers_count) AS 'CurrentThreads', @max - SUM(active_Workers_count) AS 'AvailableThreads', SUM(runnable_tasks_count) AS 'WorkersWaitingForCpu', SUM(work_queue_count) AS 'RequestWaitingForThreads' --SUM(current_workers_count) AS 'AssociatedWorkers' FROM sys.dm_os_Schedulers WHERE STATUS = 'VISIBLE ONLINE'; wait for delay '0:0:15' ENDHier volgt een voorbeeld van de uitvoer van de voorgaande query:
CurrentDate TotalThreads CurrentThreads AvailableThreads WorkersWaitingForCpu RequestWaitingForThreads 2020-10-06 01:27:01.337 1216 361 855 33 0 2020-10-06 01:27:08.340 1216 1412 -196 22 76 2020-10-06 01:27:15.340 1216 1304 -88 2 161 2020-10-06 01:27:22.340 1216 1242 -26 21 185 2020-10-06 01:27:29.343 1216 1346 -130 19 476 2020-10-06 01:27:36.350 1216 1350 -134 9 630 2020-10-06 01:27:43.353 1216 1346 -130 13 539 2020-10-06 01:27:50.360 1216 1378 -162 5 328 2020-10-06 01:27:57.360 1216 197 1019 0 0 Hoge waarden die zijn gerapporteerd voor
WorkersWaitingForCpuenRequestWaitingForThreadsgeven aan dat er conflicten optreden in de planning en dat SQL Server de huidige workload niet tijdig kan verwerken.
Oplossing
Als u dit probleem ondervindt, moet u de werkbelasting op de secundaire replica opnieuw verdelen of de verwerkingskracht verhogen (processors toevoegen) op de computers waarop deze workloads worden uitgevoerd.
Problemen met andere mislukte failovergebeurtenissen oplossen
Als u de status van de nieuwe primaire replica tijdens een failover wilt bewaken, moet u AlwaysOn-statuscontrole lokaal verbinden met het SQL Server-exemplaar dat overgaat naar de primaire rol.
Naast de meest voorkomende redenen die in dit artikel worden besproken, zijn er veel andere redenen waarom deze verbindingspoging kan mislukken. Als u een mislukte failoverpoging verder wilt onderzoeken, raadpleegt u het clusterlogboek van de failoverpartner (de replica waarnaar u geen failover kunt uitvoeren):
Gebruik Windows PowerShell om het Windows-clusterlogboek op het clusterknooppunt te genereren. Voer hiervoor de volgende cmdlet uit in een PowerShell-venster met verhoogde bevoegdheid op het exemplaar van SQL Server dat als host fungeert voor de secundaire replica die niet is overgezet naar de primaire rol. Er wordt een clusterlogboek gegenereerd voor de afgelopen 60 minuten aan activiteit.
Get-ClusterLog -Node <SQLServerNodeName> -TimeSpan 60Als u het Windows-clusterlogboek wilt bekijken, opent u het Cluster.log-bestand in Kladblok.
Zoek naar de tekenreeks 'Verbinding maken met SQL Server' die valt tijdens de mislukte failover-gebeurtenis.
Bekijk de volgende aanmeldingsberichten met behulp van de thread-id (zie de volgende schermopname) om de gebeurtenissen te correleren die zijn gerelateerd aan de aanmeldings gebeurtenis. In het volgende voorbeeld ziet u een zoekopdracht naar Verbinding maken met SQL Server. Ook ziet u hoe u de thread-id (links) gebruikt om de andere diagnostische gegevens te vinden die beschrijven waarom de verbindingspoging is mislukt.


In de volgende voorbeelden ziet u verbindingsfouten met de nieuwe primaire replica.
Voorbeeldset 1
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: No client protocols are enabled and no protocol was specified in the connection
string [xFFFFFFFF]. (268435455)
Oplossing
Start SQL Server Configuration Manager en controleer of gedeeld geheugen of TCP/IP is ingeschakeld onder Clientprotocollen voor de SQL Native Client Configuration.
Voorbeeldset 2
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: Server doesn't support requested protocol [xFFFFFFFF]. (268435455)
Oplossing
Start SQL Server Configuration Manager en controleer of gedeeld geheugen of TCP/IP is ingeschakeld onder Clientprotocollen voor de SQL Native Client Configuration.
Voorbeeldset 3
000010b8.00001764::2020/12/02-16:52:49.808 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Cannot alter the availability
group 'ag', because it does not exist or you do not have permission. (15151)
000010b8.00000fd0::2020/12/02-17:01:14.821 ERR [RES] SQL Server Availability Group: [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]The user does not have permission to perform this action. (297)
000010b8.00001838::2020/12/02-17:10:04.427 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Login failed for user
'SQLREPRO\NODE2$'. Reason: The account is disabled. (18470)
Oplossing
Beoordelingscase 2: Onvoldoende NT Authority\SYSTEM-accountmachtigingen.