Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: SQL Server
Dit artikel bevat procedures voor het vaststellen en oplossen van problemen die worden veroorzaakt door een hoog CPU-gebruik op een computer met Microsoft SQL Server. Hoewel er veel mogelijke oorzaken zijn van hoog CPU-gebruik in SQL Server, zijn de volgende oorzaken de meest voorkomende oorzaken:
- Hoge logische leesbewerkingen die worden veroorzaakt door tabel- of indexscans vanwege de volgende voorwaarden:
- Verouderde statistieken
- Ontbrekende indexen
- Problemen met parametergevoelig plan (PSP)
- Slecht ontworpen query's
- Toename van Workload
U kunt de volgende stappen gebruiken om problemen met hoog CPU-gebruik in SQL Server op te lossen.
Stap 1: Controleer of SQL Server een hoog CPU-gebruik veroorzaakt
Gebruik een van de volgende hulpprogramma's om te controleren of het SQL Server-proces daadwerkelijk bijdraagt aan een hoog CPU-gebruik:
Taakbeheer: Controleer op het tabblad Proces of de waarde van de CPU- kolom voor SQL Server Windows NT-64-bit bijna 100 procent is.
Prestaties en resourcemonitor (perfmon)
- Teller:
Process/%User Time,% Privileged Time - Exemplaar: sqlservr
- Teller:
U kunt het volgende PowerShell-script gebruiken om de tellergegevens over een bereik van 60 seconden te verzamelen:
$serverName = $env:COMPUTERNAME $Counters = @( ("\\$serverName" + "\Process(sqlservr*)\% User Time"), ("\\$serverName" + "\Process(sqlservr*)\% Privileged Time") ) Get-Counter -Counter $Counters -MaxSamples 30 | ForEach { $_.CounterSamples | ForEach { [pscustomobject]@{ TimeStamp = $_.TimeStamp Path = $_.Path Value = ([Math]::Round($_.CookedValue, 3)) } Start-Sleep -s 2 } }Als
% User Timedeze consistent groter is dan 90 procent (% gebruikerstijd is de som van de processortijd op elke processor, is de maximumwaarde 100% * (geen CPU's)), veroorzaakt het SQL Server-proces een hoog CPU-gebruik. Als% Privileged timeechter consistent groter is dan 90 procent, dragen uw antivirussoftware, andere stuurprogramma's of een ander besturingssysteemonderdeel op de computer bij aan een hoog CPU-gebruik. Werk samen met uw systeembeheerder om de hoofdoorzaak van dit gedrag te analyseren.Prestatiedashboard: Klik in SQL Server Management Studio met de rechtermuisknop op <SQLServerInstance> en selecteer >Performance Dashboard.
Het dashboard illustreert een grafiek met de titel CPU-gebruik van het systeem met een staafdiagram. De donkerdere kleur geeft het CPU-gebruik van de SQL Server-engine aan, terwijl de lichtere kleur het totale CPU-gebruik van het besturingssysteem vertegenwoordigt (zie de legenda in de grafiek ter referentie). Selecteer de knop Voor cirkelvernieuwing of F5 om het bijgewerkte gebruik weer te geven.
Stap 2: Query's identificeren die bijdragen aan het CPU-gebruik
Als het Sqlservr.exe proces een hoog CPU-gebruik veroorzaakt, is de meest voorkomende reden SQL Server-query's waarmee tabel- of indexscans worden uitgevoerd, gevolgd door sorteer- en hashbewerkingen en -lussen (geneste lusoperator of WHILE (T-SQL)). Voer de volgende instructie uit om een idee te krijgen van hoeveel CPU de query's momenteel gebruiken, buiten de totale CPU-capaciteit:
DECLARE @init_sum_cpu_time int,
@utilizedCpuCount int
--get CPU count used by SQL Server
SELECT @utilizedCpuCount = COUNT( * )
FROM sys.dm_os_schedulers
WHERE status = 'VISIBLE ONLINE'
--calculate the CPU usage by queries OVER a 5 sec interval
SELECT @init_sum_cpu_time = SUM(cpu_time) FROM sys.dm_exec_requests
WAITFOR DELAY '00:00:05'
SELECT CONVERT(DECIMAL(5,2), ((SUM(cpu_time) - @init_sum_cpu_time) / (@utilizedCpuCount * 5000.00)) * 100) AS [CPU from Queries as Percent of Total CPU Capacity]
FROM sys.dm_exec_requests
Voer de volgende instructie uit om de query's te identificeren die verantwoordelijk zijn voor de activiteit met hoog CPU-gebruik:
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
Als query's de CPU op dit moment niet aansturen, kunt u de volgende instructie uitvoeren om te zoeken naar historische CPU-gebonden query's:
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
Stap 3: Statistieken bijwerken
Nadat u de query's hebt geïdentificeerd die het hoogste CPU-verbruik hebben, werkt u de statistieken bij van de tabellen die door deze query's worden gebruikt. U kunt de door het sp_updatestats systeem opgeslagen procedure gebruiken om de statistieken bij te werken van alle door de gebruiker gedefinieerde en interne tabellen in de huidige database. Bijvoorbeeld:
exec sp_updatestats
Notitie
De sp_updatestats door het systeem opgeslagen procedure wordt uitgevoerd UPDATE STATISTICS voor alle door de gebruiker gedefinieerde en interne tabellen in de huidige database. Voor regelmatig onderhoud moet u ervoor zorgen dat regelmatig onderhoud de statistieken up-to-date houdt. Gebruik oplossingen zoals Adaptieve indexdefragmentatie om automatisch indexdefragmentatie en statistiekenupdates voor een of meer databases te beheren. Met deze procedure wordt automatisch gekozen of u een index wilt herbouwen of opnieuw wilt ordenen op basis van het fragmentatieniveau, onder andere parameters, en statistieken wilt bijwerken met een lineaire drempelwaarde.
Raadpleeg sp_updatestats voor meer informatie over .
Als SQL Server nog steeds overmatige CPU-capaciteit gebruikt, gaat u naar de volgende stap.
Stap 4: Ontbrekende indexen toevoegen
Ontbrekende indexen kunnen leiden tot tragere query's en een hoog CPU-gebruik. U kunt ontbrekende indexen identificeren en deze maken om deze invloed op de prestaties te verbeteren.
Voer de volgende query uit om query's te identificeren die een hoog CPU-gebruik veroorzaken en die ten minste één ontbrekende index in het queryplan bevatten:
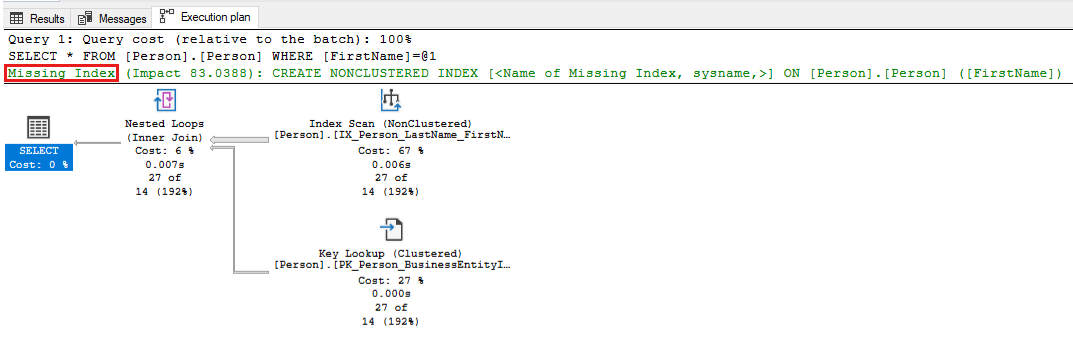
-- Captures the Total CPU time spent by a query along with the query plan and total executions SELECT qs_cpu.total_worker_time / 1000 AS total_cpu_time_ms, q.[text], p.query_plan, qs_cpu.execution_count, q.dbid, q.objectid, q.encrypted AS text_encrypted FROM (SELECT TOP 500 qs.plan_handle, qs.total_worker_time, qs.execution_count FROM sys.dm_exec_query_stats qs ORDER BY qs.total_worker_time DESC) AS qs_cpu CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q CROSS APPLY sys.dm_exec_query_plan(plan_handle) p WHERE p.query_plan.exist('declare namespace qplan = "http://schemas.microsoft.com/sqlserver/2004/07/showplan"; //qplan:MissingIndexes')=1Controleer de uitvoeringsplannen voor de geïdentificeerde query's en stem de query af door de vereiste wijzigingen aan te brengen. In de volgende schermopname ziet u een voorbeeld waarin SQL Server wijst op een ontbrekende index voor uw query. Klik met de rechtermuisknop op het ontbrekende indexgedeelte van het queryplan en selecteer vervolgens Ontbrekende indexdetails om de index in een ander venster in SQL Server Management Studio te maken.
Gebruik de volgende query om te controleren op ontbrekende indexen en om aanbevolen indexen toe te passen die hoge meetwaarden voor verbetering hebben. Begin met de top 5 of 10 aanbevelingen van de uitvoer met de hoogste waarde voor improvement_measure. Deze indexen hebben het belangrijkste positieve effect op de prestaties. Bepaal of u deze indexen wilt toepassen en zorg ervoor dat er prestatietests worden uitgevoerd voor de toepassing. Ga vervolgens door met het toepassen van aanbevelingen voor ontbrekende indexen totdat u de gewenste prestatieresultaten voor de toepassing hebt bereikt. Zie Niet-geclusterde indexen afstemmen met ontbrekende indexsuggesties voor meer informatie over dit onderwerp.
SELECT CONVERT(VARCHAR(30), GETDATE(), 126) AS runtime, mig.index_group_handle, mid.index_handle, CONVERT(DECIMAL(28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) AS improvement_measure, 'CREATE INDEX missing_index_' + CONVERT(VARCHAR, mig.index_group_handle) + '_' + CONVERT(VARCHAR, mid.index_handle) + ' ON ' + mid.statement + ' (' + ISNULL(mid.equality_columns, '') + CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL(mid.inequality_columns, '') + ')' + ISNULL(' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement, migs.*, mid.database_id, mid.[object_id] FROM sys.dm_db_missing_index_groups mig INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle WHERE CONVERT (DECIMAL (28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) > 10 ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC

Stap 5: Parametergevoelige problemen onderzoeken en oplossen
U kunt de opdracht DBCC FREEPROCCACHE gebruiken om de plancache vrij te maken en te controleren of dit het probleem met het hoge CPU-gebruik oplost. Als het probleem is opgelost, is dit een indicatie van een parametergevoelig probleem (PSP, ook wel bekend als 'parameter-sniffingprobleem').
Notitie
Als u de DBCC FREEPROCCACHE zonder parameters gebruikt, worden alle gecompileerde plannen uit de plancache verwijderd. Hierdoor worden nieuwe query-uitvoeringen opnieuw gecompileerd, wat leidt tot een eenmalige langere duur voor elke nieuwe query. De beste aanpak is om DBCC FREEPROCCACHE ( plan_handle | sql_handle ) te gebruiken om te bepalen welke query het probleem veroorzaakt en vervolgens die individuele query of query's aan te pakken.
Gebruik de volgende methoden om de parametergevoelige problemen te verhelpen. Aan elke methode zijn afwegingen en nadelen gekoppeld.
Gebruik de queryhint RECOMPILE. U kunt een queryhint
RECOMPILEtoevoegen aan een of meer van de hoge CPU-query's die zijn geïdentificeerd in stap 2. Deze hint helpt de lichte toename van het CPU-gebruik van compilaties in evenwicht te brengen met een meer optimale prestatie voor elke uitvoering van de query. Raadpleeg Hergebruik van parameters en uitvoeringsplan, Parametergevoeligheid en queryhint RECOMPILE voor meer informatie.Hier ziet u een voorbeeld van hoe u deze hint kunt toepassen op uw query.
SELECT * FROM Person.Person WHERE LastName = 'Wood' OPTION (RECOMPILE)Gebruik de queryhint OPTIMIZE FOR om de werkelijke parameterwaarde te overschrijven met een meer gebruikelijke parameterwaarde die de meeste waarden in de gegevens dekt. Deze optie vereist een volledig begrip van optimale parameterwaarden en bijbehorende plankenmerken. Hier is een voorbeeld van hoe u deze hint in uw query kunt gebruiken.
DECLARE @LastName Name = 'Frintu' SELECT FirstName, LastName FROM Person.Person WHERE LastName = @LastName OPTION (OPTIMIZE FOR (@LastName = 'Wood'))Gebruik de queryhint OPTIMIZE FOR UNKNOWN om de werkelijke parameterwaarde te overschrijven met het gemiddelde van de dichtheidsvector. U kunt dit ook doen door de binnenkomende parameterwaarden vast te leggen in lokale variabelen en vervolgens de lokale variabelen binnen de predicaten te gebruiken in plaats van de parameters zelf te gebruiken. Voor deze oplossing kan de gemiddelde dichtheid voldoende zijn om acceptabele prestaties te bieden.
Gebruik de queryhint DISABLE_PARAMETER_SNIFFING om parameter-sniffing volledig uit te schakelen. Hier is een voorbeeld van hoe u het in een query kunt gebruiken:
SELECT * FROM Person.Address WHERE City = 'SEATTLE' AND PostalCode = 98104 OPTION (USE HINT ('DISABLE_PARAMETER_SNIFFING'))Gebruik de queryhint KEEPFIXED PLAN om hercompilaties in de cache te voorkomen. Bij deze tijdelijke oplossing wordt ervan uitgegaan dat het 'goed genoeg' algemene plan het plan is dat zich al in de cache bevindt. U kunt automatische updates voor statistieken ook uitschakelen om de kans te verkleinen dat het goede plan wordt verwijderd en een nieuw slecht plan wordt gecompileerd.
Gebruik de opdracht DBCC FREEPROCCACHE als tijdelijke oplossing totdat de toepassingscode is hersteld. U kunt de opdracht
DBCC FREEPROCCACHE (plan_handle)gebruiken om alleen het plan te verwijderen dat het probleem veroorzaakt. Als u bijvoorbeeld queryplannen wilt vinden die verwijzen naar de tabelPerson.Personin AdventureWorks, kunt u deze query gebruiken om de query-ingang te vinden. Vervolgens kunt u het specifieke queryplan uit de cache vrijgeven met behulp van deDBCC FREEPROCCACHE (plan_handle)die wordt geproduceerd in de tweede kolom van de queryresultaten.SELECT text, 'DBCC FREEPROCCACHE (0x' + CONVERT(VARCHAR (512), plan_handle, 2) + ')' AS dbcc_freeproc_command FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_query_plan(plan_handle) CROSS APPLY sys.dm_exec_sql_text(plan_handle) WHERE text LIKE '%person.person%'
Stap 6: Problemen met SARGabiliteit onderzoeken en oplossen
Een predicaat in een query wordt beschouwd als SARGable (Search ARGument-able) wanneer de SQL Server-engine een indexzoekopdracht kan gebruiken om de uitvoerbewerking van de query te versnellen. Veel queryontwerpen voorkomen SARGability en leiden tot tabel- of indexscans en een hoog CPU-gebruik. Bekijk de volgende query voor de AdventureWorks-database, waarbij elke ProductNumber moet worden opgehaald en waarop de SUBSTRING() functie moet worden toegepast, voordat deze wordt vergeleken met een letterlijke tekenreekswaarde. Zoals u ziet, moet u eerst alle rijen van de tabel ophalen en vervolgens de functie toepassen voordat u een vergelijking kunt maken. Het ophalen van alle rijen uit de tabel betekent een tabel- of indexscan, wat leidt tot een hoger CPU-gebruik.
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE SUBSTRING(ProductNumber, 0, 4) = 'HN-'
Het toepassen van een functie of berekening op de kolom(men) in het zoekpredicaat maakt de query over het algemeen niet-sargable en leidt tot een hoger CPU-verbruik. Oplossingen omvatten meestal het herschrijven van de query's op een creatieve manier om ze SARGable te maken. Een mogelijke oplossing voor dit voorbeeld is deze herschrijfbewerking waarbij de functie wordt verwijderd uit het querypredicaat, een andere kolom wordt doorzocht en dezelfde resultaten worden bereikt:
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE Name LIKE 'Hex%'
Hier volgt een ander voorbeeld, waarbij een verkoopmanager mogelijk 10% verkoopcommissie wil geven voor grote orders en wil zien welke orders een commissie van meer dan $ 300 hebben. Dit is de logische, maar niet-sargable manier om dit te doen.
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice * 0.10 > 300
Hier volgt een mogelijk minder intuïtieve maar SARGable herschrijving van de query, waarin de berekening wordt verplaatst naar de andere kant van het predicaat.
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice > 300/0.10
SARGability is niet alleen van toepassing op WHERE-clausules, maar ook op JOINs-, HAVING- en GROUP BYORDER BY-clausules. Frequente gevallen van preventie van SARGability in query's hebben betrekking op CONVERT()-, CAST()-, ISNULL()-, COALESCE()- functies die worden gebruikt in WHERE- of JOIN-clausules die leiden tot het scannen van kolommen. In de gevallen van conversie van gegevenstypen (CONVERT of CAST), kan de oplossing zijn om ervoor te zorgen dat u dezelfde gegevenstypen vergelijkt. Hier volgt een voorbeeld waarin de T1.ProdID-kolom expliciet wordt geconverteerd naar het INT-gegevenstype in een JOIN. De conversie verslaat het gebruik van een index in de join-kolom. Hetzelfde probleem treedt op bij impliciete conversie waarbij de gegevenstypen verschillen en SQL Server er een converteert om de join uit te voeren.
SELECT T1.ProdID, T1.ProdDesc
FROM T1 JOIN T2
ON CONVERT(int, T1.ProdID) = T2.ProductID
WHERE t2.ProductID BETWEEN 200 AND 300
Om een scan van de T1-tabel te voorkomen, kunt u het onderliggende gegevenstype van de ProdID-kolom wijzigen na de juiste planning en het juiste ontwerp en vervolgens de twee kolommen samenvoegen zonder de conversiefunctie ON T1.ProdID = T2.ProductID te gebruiken.
Een andere oplossing is om een berekende kolom in T1 te maken waarin dezelfde CONVERT()-functie wordt gebruikt en er vervolgens een index voor te maken. Hierdoor kan de query-optimizer die index gebruiken zonder dat u de query hoeft te wijzigen.
ALTER TABLE dbo.T1 ADD IntProdID AS CONVERT (INT, ProdID);
CREATE INDEX IndProdID_int ON dbo.T1 (IntProdID);
In sommige gevallen kunnen query's niet eenvoudig worden herschreven om SARGability mogelijk te maken. In dergelijke gevallen kunt u zien of de berekende kolom met een index ervoor kan helpen, of dat u de query kunt behouden zoals die was met de kennis dat deze kan leiden tot scenario's met een hogere CPU.
Stap 7: Zware tracering uitschakelen
Controleer op SQL tracering of XEvent-tracering die de prestaties van SQL Server beïnvloedt en een hoog CPU-gebruik veroorzaakt. Als u bijvoorbeeld de volgende gebeurtenissen gebruikt, kan dit een hoog CPU-gebruik veroorzaken als u zware SQL Server-activiteiten traceren:
- XML-gebeurtenissen voor queryplan (
query_plan_profile,query_post_compilation_showplan,query_post_execution_plan_profile,query_post_execution_showplan,query_pre_execution_showplan) - Gebeurtenissen op instructieniveau (
sql_statement_completed,sql_statement_starting,sp_statement_starting,sp_statement_completed) - Aanmeldings- en afmeldingsgebeurtenissen (
login,process_login_finish,login_event,logout) - Gebeurtenissen vergrendelen (
lock_acquired,lock_cancel,lock_released) - Wacht-gebeurtenissen (
wait_info,wait_info_external) - SQL Controlegebeurtenissen (afhankelijk van de gecontroleerde groep en SQL Server-activiteit in die groep)
Voer de volgende query's uit om actieve XEvent- of Server-traceringen te identificeren:
PRINT '--Profiler trace summary--'
SELECT traceid, property, CONVERT(VARCHAR(1024), value) AS value FROM::fn_trace_getinfo(
default)
GO
PRINT '--Trace event details--'
SELECT trace_id,
status,
CASE WHEN row_number = 1 THEN path ELSE NULL end AS path,
CASE WHEN row_number = 1 THEN max_size ELSE NULL end AS max_size,
CASE WHEN row_number = 1 THEN start_time ELSE NULL end AS start_time,
CASE WHEN row_number = 1 THEN stop_time ELSE NULL end AS stop_time,
max_files,
is_rowset,
is_rollover,
is_shutdown,
is_default,
buffer_count,
buffer_size,
last_event_time,
event_count,
trace_event_id,
trace_event_name,
trace_column_id,
trace_column_name,
expensive_event
FROM
(SELECT t.id AS trace_id,
row_number() over(PARTITION BY t.id order by te.trace_event_id, tc.trace_column_id) AS row_number,
t.status,
t.path,
t.max_size,
t.start_time,
t.stop_time,
t.max_files,
t.is_rowset,
t.is_rollover,
t.is_shutdown,
t.is_default,
t.buffer_count,
t.buffer_size,
t.last_event_time,
t.event_count,
te.trace_event_id,
te.name AS trace_event_name,
tc.trace_column_id,
tc.name AS trace_column_name,
CASE WHEN te.trace_event_id in (23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180) THEN CAST(1 as bit) ELSE CAST(0 AS BIT) END AS expensive_event FROM sys.traces t CROSS APPLY::fn_trace_geteventinfo(t.id) AS e JOIN sys.trace_events te ON te.trace_event_id = e.eventid JOIN sys.trace_columns tc ON e.columnid = trace_column_id) AS x
GO
PRINT '--XEvent Session Details--'
SELECT sess.NAME 'session_name', event_name, xe_event_name, trace_event_id,
CASE WHEN xemap.trace_event_id IN(23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180)
THEN Cast(1 AS BIT)
ELSE Cast(0 AS BIT)
END AS expensive_event
FROM sys.dm_xe_sessions sess
JOIN sys.dm_xe_session_events evt
ON sess.address = evt.event_session_address
INNER JOIN sys.trace_xe_event_map xemap
ON evt.event_name = xemap.xe_event_name
GO
Stap 8: Hoog CPU-gebruik oplossen dat wordt veroorzaakt door spinlockconflicten
Zie de volgende secties om veelvoorkomend hoog CPU-gebruik op te lossen dat wordt veroorzaakt door conflicten tussen spinlocks.
SOS_CACHESTORE spinlockconflict
Als uw SQL Server-exemplaar een zware SOS_CACHESTORE spinlockconflict ondervindt of u merkt dat uw queryplannen vaak worden verwijderd voor niet-geplande queryworkloads, raadpleegt u het volgende artikel en schakelt u traceringsvlag T174 in met behulp van de DBCC TRACEON (174, -1) opdracht:
Als de voorwaarde voor hoog CPU-gebruik wordt opgelost met behulp vanT174, schakelt u deze in als opstartparameter met behulp van SQL Server configuratiebeheer.
Willekeurig hoog CPU-gebruik vanwege SOS_BLOCKALLOCPARTIALLIST spinlockconflict op machines met een groot geheugen
Als uw SQL Server-exemplaar een willekeurig hoog CPU-gebruik ondervindt vanwege SOS_BLOCKALLOCPARTIALLIST conflicten tussen spinlocks, raden we u aan cumulatieve update 21 toe te passen voor SQL Server 2019. Zie bug reference 2410400 en DBCC DROPCLEANBUFFERS die tijdelijke oplossingen biedt voor meer informatie over het oplossen van het probleem.
Hoog CPU-gebruik vanwege spinlockconflicten op XVB_list op high-end machines
Als uw SQL Server-exemplaar een hoog CPU-scenario ondervindt dat wordt veroorzaakt door spinlockconflicten op de XVB_LIST spinlock op hoge configuratiemachines (high-endsystemen met een groot aantal processors van nieuwere generatie (CPU's)), schakelt u de traceringsvlag TF8102 in samen met TF8101.
Notitie
Hoog CPU-gebruik kan het gevolg zijn van spinlockconflicten op veel andere spinlocktypen. Zie Spinlock-conflicten vaststellen en oplossen op SQL Server voor meer informatie over spinlocks.
Stap 9: Controleer de instellingen van uw energiebeheerschema op besturingssysteemniveau
SQL Server-workloads kunnen verminderde prestaties ondervinden en leiden tot een hoog CPU-gebruik op het systeem wanneer Windows is geconfigureerd met het standaard energiebeheerschema Met gelijke taakverdeling. De instelling Gebalanceerd energiebeheerplan kan de CPU-kloksnelheid verlagen om energie te besparen. Een processor met een snelheid van 3,00 GHz kan bijvoorbeeld terugschakelen naar 1,2 GHz. Als gevolg hiervan kunnen workloads die doorgaans ongeveer 30% CPU verbruiken, 100% gebruik bereiken vanwege de verminderde kloksnelheid. Als u consistente en optimale prestaties wilt behouden voor rekenintensieve SQL Server-workloads, raden we u aan het systeem te configureren voor het gebruik van het energiebeheerschema met hoge prestaties . Deze instelling zorgt ervoor dat de CPU werkt met de volledige snelheid, waardoor knelpunten in de prestaties worden voorkomen. Zie Trage prestaties op Windows Server bij het gebruik van het energiebeheerschema Met gelijke balans voor meer informatie.
Stap 10: Uw virtuele machine configureren
Als u een virtuele machine gebruikt, moet u ervoor zorgen dat u CPU's niet teveel belast en dat ze correct zijn geconfigureerd. Zie voor meer informatie Het oplossen van prestatieproblemen met virtuele ESX/ESXi-machines (2001003).
Stap 11: het systeem omhoog schalen om meer CPU's te gebruiken
Als afzonderlijke query-exemplaren weinig CPU-capaciteit gebruiken, maar de algehele werkbelasting van alle query's samen een hoog CPU-verbruik veroorzaakt, kunt u overwegen om uw computer omhoog te schalen door meer CPU's toe te voegen. Gebruik de volgende query om het aantal query's te vinden dat een bepaalde drempelwaarde van gemiddeld en maximaal CPU-verbruik per uitvoering heeft overschreden en die meerdere keren op het systeem zijn uitgevoerd (zorg ervoor dat u de waarden van de twee variabelen wijzigt zodat deze overeenkomen met uw omgeving):
-- Shows queries where Max and average CPU time exceeds 200 ms and executed more than 1000 times
DECLARE @cputime_threshold_microsec INT = 200*1000
DECLARE @execution_count INT = 1000
SELECT qs.total_worker_time/1000 total_cpu_time_ms,
qs.max_worker_time/1000 max_cpu_time_ms,
(qs.total_worker_time/1000)/execution_count average_cpu_time_ms,
qs.execution_count,
q.[text]
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
WHERE (qs.total_worker_time/execution_count > @cputime_threshold_microsec
OR qs.max_worker_time > @cputime_threshold_microsec )
AND execution_count > @execution_count
ORDER BY qs.total_worker_time DESC
Zie ook
- Hoge CPU- of geheugentoewijzingen kunnen optreden bij query's die gebruikmaken van geoptimaliseerde geneste lus of batchsortering
- Aanbevolen updates en configuratieopties voor SQL Server met werklasten met hoge prestaties
- Aanbevolen updates en configuratieopties voor SQL Server 2017 en 2016 met werklasten met hoge prestaties