Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
This article was written for Microsoft by John Hudson, and originally published in 2000. Since it is now more than twenty years old, some of the information may be either out-of-date or incomplete in terms of describing current Windows glyph processing. The article describes the infrastructure in place prior to the DirectWrite platform that is now responsible for much of the text layout and display in Windows and does not take into account other platforms such as that used by recent versions of the Edge browser. The basic principles of OpenType Layout and shaping engine interaction described in the article remain relevant.
In a relatively simple digital font architecture, as typified by the original TrueType format developed at Apple Computers, there is a one-to-one relationship between an encoded character and the glyph that represents it. Systems and applications that make use of such fonts do not need to make a distinction between character processing and glyph processing. In working with such fonts, it is most often convenient to think only in terms of character processing, or simply text processing: that is, the sequential rendering of glyphs representing character codes as input in logical order. When applications have needed to provide more complicated text processing for complex scripts [1] or sophisticated typography, they have generally made use of proprietary engines to shape text based on custom character sets, or have obliged users to resort to font switching to access variant glyph forms. The idiosyncratic nature of these solutions frequently results in text that cannot be exchanged outside of particular systems and applications.
(The term “complex script” refers to any writing system that requires some degree of character reordering and/or glyph processing to display, print or edit. In other words, scripts for which Unicode logical order and nominal glyph rendering of codepoints do not result in acceptable text. Such scripts, examples of which are Arabic and the numerous Indic scripts descended from the Brahmi writing system, are generally identifiable by their morphographic characteristics: the changing of the shape or position of glyphs as determined by their relationship to each other. It should be noted that such processing is not optional, but is essential to correctly rendering text in these scripts. Additional glyph processing to render appropriately sophisticated typography may be desirable beyond the minimum required to make the text readable.)
The wide adoption of the Unicode Standard for character encoding provides a means to make text interchangeable across different systems and between applications that implement the standard. The Unicode Standard is strictly concerned with character processing, and presumes that Unicode text strings will be input and stored in a simple sequence defined as “logical order”. The Unicode Standard also presumes the existence of rendering systems above the Unicode text string that will, as necessary, reorder codepoints and affect sophisticated glyph processing to shape the rendering of the text through glyph substitution and positioning features. This article introduces the different elements of the Microsoft Windows implementation of Unicode character and glyph processing, and explains how they can be used by font and application developers to provide users with sophisticated typographic controls and the ability to process text in complex scripts.
(For more information about the Unicode Standard and the work of the Unicode Consortium and its technical committees, see www.unicode.org.)
This article explains three principal elements of Windows technology and their interaction: the OpenType font format, the Windows Unicode Script Processor (Uniscribe), and the OpenType Layout Services library (OTLS). The first part of the article provides an overview of Windows glyph processing, explaining the role of each of these elements and demonstrating how they render a sample string of complex script text. The second part of the article covers each of these elements in greater detail, explaining some of the internal workings of font tables, Uniscribe script shaping engines, and the interaction of OTLS with client applications. The audience for this article includes type designers and font vendors, software engineers and application developers. These groups do not always speak the same language, so I have tried to provide concise definitions, in the notes, of terminology that may be confusing for some readers; these and other notes are indicated in the text by bracketed numbers. One person’s daily vocabulary is another’s impenetrable jargon, and not all type designers are comfortable with terms such as API and DLL that are common currency among software engineers. Likewise, most engineers are likely to scratch their heads when typographers start speaking of nuts and mutton.
Overview
As mentioned in the introduction, some writing systems in the world require processing of both characters and glyphs beyond logical order input. Looking at the problems and solutions of system, application and font support for these complex scripts is a good place to start in discussing Windows glyph processing. The demands of these scripts require all the features of character string processing and glyph substitution and positioning that are available through OpenType, Uniscribe and OTLS. In addition, because glyph processing is an absolute requirement of their rendering, complex scripts demand the attention of developers hoping to produce fonts and software for the significant markets that use them. I will discuss later, in the conclusion of this article, why sophisticated typographic controls for non-complex scripts should not be treated as secondary to complex script support or necessarily of a lower priority. It is likely, however, that many application developers will first encounter system components like Uniscribe and libraries like OTLS during internationalization development involving complex scripts.
It is important to point out, at the beginning of this overview, that the Windows glyph processing model does not force particular solutions on application developers, although it does expect certain things. For example, applications are responsible for storing backing strings of text codepoints, for buffering them when necessary for line justification and breaking (this is particularly crucial for complex scripts), and for all aspects of memory management. Applications are entirely free to choose how to present layout features to users, and free to select which features to support. It should be noted that all the line layout, character reordering and glyph substitution and positioning features discussed in this article can be implemented entirely at the application level, or across application suites, using private code and DLLs. [3] However, this requires major investments in code writing and maintenance, and in understanding implementation of individual scripts with very complex requirements. This article focuses on how developers can insulate themselves from script support issues and from much of the nuts and bolts of glyph processing by using the Uniscribe APIs and helper functions in the OTLS library. It always remains possible for client applications to override or supplement Windows glyph processing.
OpenType fonts
We will begin our overview by looking at the font format, OpenType. All the information controlling the substitution and relative positioning of glyphs during glyph processing is contained within the font itself. This information is defined in OpenType Layout (OTL) features that are, in turn, associated with specific scripts and language systems. Placing control of glyph substitution and positioning directly in the font puts a great deal of responsibility for the success of complicated glyph processing on the shoulders of type designers and font developers, but since the work involves making decisions about the appearance of text, this is the correct place for the responsibility to land. OpenType font developers enjoy a great deal of freedom in defining what features are suitable to a particular typeface design, but they remain dependent on application support to make those features accessible to users. As we shall see, in the case of complex scripts requiring the presence of specific OTL features for correct shaping, it is very important that font developers ensure that the feature lookups they define meet the expectations of other elements of Windows glyph processing technology, particularly Uniscribe.
The OpenType font format is discussed in more depth later, but two internal tables need to be introduced now. These are the GSUB and GPOS tables that contain instructions for, respectively, glyph substitution and glyph positioning. Glyph substitution involves replacing one or more glyphs with one or more different glyphs representing the same text string. The backing string of Unicode characters is not changed; only the visual presentation is changed. These substitutions may be required (as part of script rendering), recommended as default behavior, or activated at the discretion of the user; they may also be contextual, active only when preceded or followed by a certain glyph or sequence of glyphs, or contextually chained so that one substitution affects another. In the first of the following simple examples, substitutions are made by activating the “Standard Ligatures” OTL feature in a line of Latin script text. This replaces colliding letter combinations with ligatured forms: a better solution than adding space between the colliding glyphs that would result in gaping wounds in the middle of words. This font also contains a ligature for the frequent Th combination that reduces the amount of white space between the T and the h.

In this second example, a user has chosen to activate the “Discretionary Ligatures” feature to replace the ct letter combination with a decorative, historical ligature. This flamboyant typographer has also used the “Swash” feature to replace the initial Th ligature with a more calligraphic form, replace the y with a subtly swung form, and substitute corsiva versions of h and l.
(Swash letters are stylised, flourished variants of their staid typographic cousins, generally found accompanying italic fonts but occasionally in romans. They are at home in the major European scripts—Latin, Cyrillic and Greek—but have relatives around the world. The term corsiva literally means cursive, a word that is often applied to any type style that displays some aspects of a handwritten model. In this instance it is used, as it was by renaissance scribes, to distinguish the informal flowing style of ascender from the more carefully formed formata seen in the first example.)
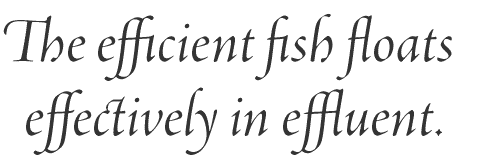
None of these changes requires any font switching, because all the variant glyphs are included in a single italic font. Because all substitutions take place at the glyph level, rather than at the character level, the text string remains unchanged and can be selected, copied and pasted between Unicode savvy programs without semantic damage.
Features associated with the GPOS table shift glyphs from their normative positions and reposition them relative to each other. This is particularly useful for complex scripts in which graphic elements change position contextually, or in which quality typographic or manuscript tradition demands that two or more glyphs maintain a particular relationship when one or more of them are adjusted. For instance, GPOS lookups can be used to control the precise positioning of matras (vowel markers) in Indic scripts relative to base consonants or conjuncts, and can then adjust the position of other markers above and below the syllable to avoid collisions. The conjuncts themselves will have been rendered using GSUB lookups, and this is a good example of how GSUB and GPOS features work together to provide sophisticated solutions for complex script rendering.
In the following Latin script example, two quite simple GPOS features—“Case-Sensitive Forms” and “Capital Spacing”—are applied to the Spanish and English text when it is converted to an all uppercase setting.

In the mixed upper and lowercase setting above, the dot of the initial inverted question mark is vertically aligned with the x-height of the lowercase letters and descends below the baseline. Likewise, the parentheses around the English text are optically aligned with the mix of letter cases. In the image below, the same text has been set in all uppercase letters, and the two GPOS features have been applied. The “Case-Sensitive Forms” feature has raised the inverted question mark to align with the capital letters, and has slightly raised the parentheses so that they vertically align with the new setting.
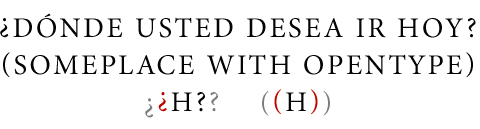
The third line allows direct comparison of the adjusted glyph positions to the normative vertical positioning. The light grey glyphs are in normative positions; the red glyphs show the new positions after the “Case-Sensitive Forms” feature has been applied. It should also be noted that the same effect could have been achieved using GSUB lookups to replace the normative glyphs with glyphs in new positions; in fact, the registered definition of the “Case-Sensitive Forms” feature explicitly notes that either solution is legitimate.
The second GPOS feature applied in the above example—“Capital Spacing”—is a metrics adjustment feature that increases the normal spacing between letters to make uppercase settings easier to read. These two features together are a good example of something that an application might choose to present to users as a single UI choice, associating both with an “All Caps” option that uses Unicode case mapping to switch between lower and uppercase. An application might leave it to the user to select and apply these kind of case sensitive features to text, or it might use heuristics to identify words and phrases that the user has set in uppercase and apply the features automatically.
Both the features demonstrated above are examples of GPOS lookups that adjust the position of glyphs relative to their normative positions. It is also possible to adjust glyph positions relative to specific elements of other glyphs, and this is discussed in more detail later.
OpenType Layout Services
The OpenType font format is the central element of the Windows glyph processing model. The OpenType Layout Services library (OTLS), on the other hand, is not essential, but it has great benefits to application developers who need to support glyph processing but want to be insulated from details of the font file format. OTLS allows client applications to concentrate on those aspects of text processing with which they are familiar—character handling and presentation of formatting features to users—by using OTLS to handle the unfamiliar details of lookup tables and glyph IDs.
The OTLS library is a set of helper functions that serve a text processing client by retrieving information from fonts and guiding the operating system in rendering text. The client and OTLS work together to layout text, using some, all or none of the OpenType Layout features defined within a font, as decided by the application developer. The client can use OTLS functions to query a font about what layout feature it supports and with what script and language systems they are associated. Using this information, the client can implement required features for specific scripts and present other features to users. An application may tightly integrate specific features into its UI, associating one or more OpenType features with formatting options—as suggested in the GPOS example earlier—, or may present the features dynamically as they are returned from individual fonts.
Many of the OTLS functions need to be applied to “runs” of text, and one of the basic responsibilities of a client using OTLS is the ability to parse and tag runs. A run is normally a maximum of one line in length and consists of a text string formatted in a single font at a particular size, in a single direction, in a particular script and a particular language system. Obviously, in many documents, the majority of consecutive runs of text will simply equate to individual lines. In multilingual documents, however, a client may need to be able to identify and tag a number of runs within a single line of text. In the example below, two lines of bilingual text need to be separated into eight runs. At the top of the illustration, the two lines appear with formatting; below this, the same lines appear as Unicode plain text, with the formatting runs indicated in red. Lastly, the Unicode codepoints stored by the application are shown, also with runs marked in red, which makes clear exactly where one run ends and another begins (punctuation characters are dark grey, and space characters are light grey).

(This example is adapted from the chapter on Arabic typesetting in Théotiste Lefevre’s Guide Pratique du Compositeur et de L’Imprimeur Typographes. The business of complex script and multilingual typography is not new, nor was it in the 1870s when this book was first published. If anything, digital typography is only just beginning to catch up with its analogue history.)
In this example, there are three types of run boundary, indicated by the small red letters:
- a. Change of font (bold to roman, roman to italic, italic to roman).
- b. Change of script, language system and direction. Any one of these changes is sufficient to require the start of a new run. In many multilingual texts, a change of script might also occasion a change in font, but for this example we will presume that this is a multiscript font with both Latin and Arabic support.
- c. End of line (the end of the first line is also a change in script, language system and direction, because the second line starts with an Arabic character).
When runs have been identified and tagged, OTLS text layout functions can be used to implement glyph substitution and glyph positioning in individual runs. OpenType features are never applied across run boundaries; the run is the basic element to which glyph processing is applied, although, for complex scripts, it is necessary to further divide the run into smaller segments (see “Uniscribe” below).
OTLS is designed to expose the full functionality of OpenType fonts to an application, so it is a powerful assistant in implementing support for even the most complicated aspects of Windows glyph processing: for instance, GSUB layout features that are designed to present the user with a choice of variant glyphs. OTLS supports these features by enabling clients to specify features with parameters to enumerate possible substitutions. In response to, for example, a user’s application of the “Stylistic Alternates” feature (using GSUB lookup type 3, replacing one glyph with one of many), the application would call OTLS repeatedly until the possible parameters for that feature—i.e. the number of possible glyphs to be substituted—were exhausted. The application would record the resulting glyph alternates and present them to the user. In the image below, a user wants to replace a particular occurrence of the letter e with a stylistic variant. The application has called OTLS to query the font, and has found that there are eight variant glyphs available (including the normative glyph); these variants are presented to the user in a simple pop-up menu.
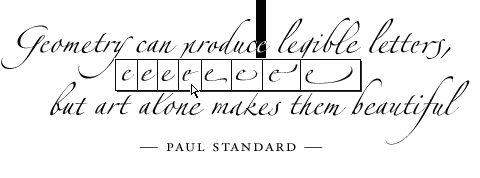
In addition to parsing and tagging runs, an OTLS client remains responsible for line breaking, layout direction and justification, and for memory allocation. The internal structure of the OTLS library and details of the various helper functions are explained later.
Uniscribe
Uniscribe—the Windows Unicode Script Processor, to give it its full name—is a collection of APIs and shaping engines that enable text layout clients to format complex scripts.
(API is an abbreviation for Application Programming Interface. An API is a function, or set of functions, that applications use to take advantage of system components. For example, amost all Windows applications that process plain text use the common TextOut or ExtTextOut system APIs to draw text.)
The Uniscribe DLL (USP10.DLL) currently ships with Windows 2000 and with Internet Explorer 5.0+. After the release of Windows Xp, later in 2001, Uniscribe will be made available via the Microsoft Developer Network (MSDN), which will allow for more frequent updates supporting new scripts and languages. Although Uniscribe is of greatest benefit under Windows 2000, where it can take advantage of input method support for Arabic and Indic languages, it can also be used in Windows NT4, 98 and 95 to view and print Unicode text for complex scripts. The Uniscribe APIs include a core set of ScriptString functions similar to the familiar TextOut for plain text clients, with advanced caret placement, and functions that prepare complex scripts for shaping in the Uniscribe engines.
Each of the shaping engines in Uniscribe contains the shaping knowledge for a particular script or closely related group of scripts. This shaping knowledge focuses on the basic element of each script, which will vary depending on the nature of the writing system. In the Indic scripts, for example, the basic element that needs to be processed is the syllable; in the Arabic script the basic element is always a pair of letters, with the second letter of a pair becoming the first letter of the next. Uniscribe analyses and prepares strings of Unicode text by breaking runs—i.e. strings of text in a single script with uniform formatting—into clusters corresponding to the basic element for that script. The kind of character preprocessing that some complex scripts require—reordering of certain characters in the string, for example—are detailed in the Unicode Standard. Character preprocessing takes logical order text as supplied by the client, and outputs it in a form that can take efficient advantage of glyph processing. Once this pre-processing is complete, Uniscribe takes advantage of OpenType Layout Services to render complex scripts, activating specific layout features based on cluster analysis. Uniscribe is an OTLS client, using the library functions to apply specific OpenType Layout features that are required to correctly render complex scripts. This does not preclude an application that uses Uniscribe from also being an OTLS client itself. Applications may use Uniscribe for basic rendering of complex script text, but interact with OTLS directly to offer users additional discretionary typographic features, such as stylistic variant forms. These discretionary features would be enabled by applying OpenType Layout lookups to the GIDs received from Uniscribe.
In the following example, we will follow the progress of a short piece of complex script text as it makes its way from input to rendering. The focus will be on what happens to the text within Uniscribe. The sample text is a single word in the Sanskrit language, as written in the Devanagari script. It is a long, compound word that exhibits many of the character pre-processing and OTL feature requirements of Indic scripts. The word is extracted from a short sentence in the Aitreyopanishad; the sample word is indicated in red and transliterated below. [7]

(The Aitreyopanishad or Aitareya Upanishad is one of the classical Hindu spiritual texts collectively known as the Upanishads.)
Note: in this example, the Sanskrit text is displayed in the Microsoft Devanagari UI font, Mangal. This is not an ideal font for classical Sanskrit, being somewhat simplified and with a limited set of ligatured conjunct forms, but it has the benefit of being well hinted for low resolution which will make the illustrations easier to follow.
Here are the characters in the backing string for our sample word, as input by the user using the Windows 2000 Sanskrit keyboard. Beneath it are the codepoints stored by the application in logical order.

Because we are dealing with a single word, using a single font at a single size, our sample constitutes a run of text, as understood by both Uniscribe and OTLS. The first task of the Indic script shaping engine is to break the run into clusters. As mentioned above, the basic element of script processing for Indic scripts is the syllable, so the result of this operation will be separation of our word into syllables. The script shaping engine makes use of Unicode character properties to identify the different types of characters in the run, and its own knowledge of the possible relationships of these characters to identify syllable boundaries. Here are the characters, still in logical order, separated into clusters as indicated by the blue bars.

Once the run is separated into clusters, the shaping engine analyses each cluster to determine if any character reordering is necessary. The rules for character processing in Devanagari are explained in the Unicode Standard.
(In The Unicode Standard Version 3.0, the Devanagari shaping rules are explained in §9.1, pp. 211-223. Devanagari provides the model for the shaping of other Indic scripts in Unicode, and this section should be read in conjunction with the descriptions of script shaping requirements for Bengali, Gurmukhi, Gujarati, etc.. Note that Thai, although closely related to the Indic scripts, has unique requirements that justify a separate Thai shaping engine in Uniscribe--see Part Two.)
In the next illustration, the characters affected by reordering are indicated in red.

Only four clusters in our sample run require character reordering; three of these involve below-base and above-base forms of the ra consonant, and the other involves moving the i matra to the left of the consonant conjunct. Once this character processing has been done, Uniscribe calls text layout functions in OTLS to apply OpenType substitution and positioning features. All the features required to render the Indic scripts supported by Uniscribe are published in the OpenType specification, and are explained in detail in the Microsoft Typography document Creating and supporting OpenType fonts for Indic Scripts.
In all, eighteen applications of GSUB and GPOS features are required to render this one Sanskrit word.
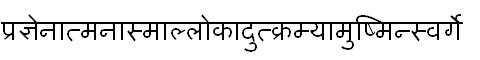
Uniscribe completely insulates client applications from the shaping knowledge required for complex scripts. Once Uniscribe has finished calling OTLS to apply the required features for a complex script like Devanagari, it can pass the glyph string back to the application and to device drivers and system font rasterizers. The application, meanwhile, only needs to manage the original backing string of logical order Unicode text. Uniscribe never changes the backing string, and any character reordering required by Unicode script shaping rules occurs in a buffer. Uniscribe maintains one index from the buffered characters to the original backing string, and another from the buffered characters to the font glyph string. Client applications can utilize additional Uniscribe APIs to control cursor positioning and caret movement in the rendered text.
Uniscribe likewise insulates font developers from complex script shaping requirements by taking on the task of analyzing clusters and preparing them for OpenType layout. This means that type designers and developers can work with efficient and predictable sets of lookups and features, rather than trying to define the incredibly large number of complicated contextual lookups that would be necessary to render directly from the Unicode backing string. Because the OpenType lookup types were not designed to perform all the reordering required by Unicode shaping rules, some complex script rendering would be impossible without the kind of character preprocessing available in Uniscribe.
This overview should have given you a basic insight into what glyph processing is, why it is necessary, and how it is implemented in Windows. Part Two covers each of the three elements of Windows glyph processing—OpenType, OTLS and Uniscribe—in more technical detail and provides information on licensing, distribution and online resources.
Syllable-by-syllable OpenType Layout features applied to our sample Sanskrit word
For readers especially interested in Indic script glyph processing, here is a syllable-by-syllable—i.e. cluster-by-cluster—description of the Indic OpenType Layout features applied to our sample Sanskrit word. These are the features used to render this text string in the Mangal Devanagari UI font; other OpenType fonts may well employ more full conjunct form substitutions in place of the half forms used heavily in Mangal. The codepoint sequence of each cluster is presented in bold type, followed by a Latin transliteration of the syllable, followed by a detailed description of the applied OTL features and their effects.
092A 0930 094D : pra : The “Below-Base Forms” feature is applied to substitute the 0930 (ra) and 094D (halant, vowel killer) with a default below-base form of 0930 (vattu). The “Below-Base Substitutions” feature is then applied to 092A (pa) and the default below-base form (**vattu) to render the required ligature.
091C 094D 091E 0947 : jñe : The “Akhand” feature is applied to replace 091C (ja) 094D (halant) 091E (nya) with the necessary ligature. The “Above-Base Mark Positioning” feature is applied to position 0947 (e matra, vowel sign) above the ligature.
0928 093E : na : No OpenType Layout features required.
0924 094D 092E : tma : The “Half Forms” feature is applied to the combination 0924 (ta) 094D (halant) to substitute the half form of 0924 (t).
0928 093E : na : No OTL features required.
0938 094D 092E 093E : sma : The “Half Forms” feature is applied to the combination 0938 (sa) 094D (halant) to substitute the half form of 0938 (s).
0932 094D 0932 094B : llo : The “Half Forms” feature is applied to the combination 0932 (la) 094D (halant) to substitute the half form of 0932 (l).
0915 093E : ka : No OTL features required.
0926 0941 : du : The “Below-Base Mark Positioning” feature is applied to position 0941 (u matra) below 0926 (da).
0924 094D 0915 0930 094D : tkra : The “Half Forms” feature is applied to the combination 0924 (ta) 094D (halant) to get the half form of 0924 (t). The “Below-Base Form” feature is applied to 0930 (ra) and 094D (halant) to substitute it with a default below base form of 0930 (vattu). The “Below-base Substitutions” is then applied to 0915 (ka) and the default below base form (vattu) to render the required ligature.
092E 094D 092F 093E : mya : The “Half Forms” feature is applied to the combination 092E (ma) 094D (halant) to substitute the half form of 092E (m).
092E 0941 : mu : No OTL features required.
093F 0937 094D 092E : smi : The “Pre-Base Substitutions” feature is applied to get the desired glyph variant of 093F (i matra); this feature substitutes one of five different i matras in the Mangal font that are designed to fit over different widths of consonants and conjuncts.
0928 094D 0938 094D 0935 : nsva : The “Half Forms” feature is applied to the combinations 0928 (na) 094D (halant) and 0938 (sa) 094D (halant) to substitute the respective half forms of 0928 (n) and 0938 (s).
0917 0947 0930 094D : rge : The “Reph” feature is applied to substitute 0930 (ra) and 094D (halant) with a default glyph for the reph (the above-base form of ra). The “Above-Base Substitutions” feature is then applied to 0947 (e matra) and the reph to substitute them with a composite. The “Above-Base Mark Positioning” feature is applied to position the composite above 0917 (ga).
Next: Part 2
Learn about glyph processing in more detail in Windows glyph processing, part 2.