Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Voert een bewerking met meerdere hoofden uit (zie Aandacht is alles wat u nodig hebt). Precies één tensor query, sleutel en waarde moet aanwezig zijn, ongeacht of deze zijn gestapeld. Als bijvoorbeeld StackedQueryKey is opgegeven, moeten zowel de query - als de sleuteltensor null zijn, omdat deze al zijn opgegeven in een gestapelde indeling. Hetzelfde geldt voor StackedKeyValue en StackedQueryKeyValue. De gestapelde tensoren hebben altijd vijf dimensies en worden altijd gestapeld op de vierde dimensie.
Logisch kan het algoritme worden opgesplitst in de volgende bewerkingen (bewerkingen tussen haakjes zijn optioneel):
[Add Bias to query/key/value] -> GEMM(Query, Transposed(Key)) * Scale -> [Add RelativePositionBias] -> [Add Mask] -> Softmax -> GEMM(SoftmaxResult, Value);
Belangrijk
Deze API is beschikbaar als onderdeel van het zelfstandige redistributable-pakket van DirectML (zie Microsoft.AI.DirectML versie 1.12 en hoger). Zie ook de Versiegeschiedenis van DirectML.
Syntaxis
struct DML_MULTIHEAD_ATTENTION_OPERATOR_DESC
{
_Maybenull_ const DML_TENSOR_DESC* QueryTensor;
_Maybenull_ const DML_TENSOR_DESC* KeyTensor;
_Maybenull_ const DML_TENSOR_DESC* ValueTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedQueryKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedKeyValueTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedQueryKeyValueTensor;
_Maybenull_ const DML_TENSOR_DESC* BiasTensor;
_Maybenull_ const DML_TENSOR_DESC* MaskTensor;
_Maybenull_ const DML_TENSOR_DESC* RelativePositionBiasTensor;
_Maybenull_ const DML_TENSOR_DESC* PastKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* PastValueTensor;
const DML_TENSOR_DESC* OutputTensor;
_Maybenull_ const DML_TENSOR_DESC* OutputPresentKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* OutputPresentValueTensor;
FLOAT Scale;
FLOAT MaskFilterValue;
UINT HeadCount;
DML_MULTIHEAD_ATTENTION_MASK_TYPE MaskType;
};
Leden
QueryTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Query's uitvoeren met vorm [batchSize, sequenceLength, hiddenSize], waarbij hiddenSize = headCount * headSize. Deze tensor is wederzijds exclusief met StackedQueryKeyTensor en StackedQueryKeyValueTensor. De tensor kan ook 4 of 5 dimensies hebben, zolang de voorloopdimensies 1 zijn.
KeyTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Sleutel met vorm [batchSize, keyValueSequenceLength, hiddenSize], waar hiddenSize = headCount * headSize. Deze tensor is wederzijds exclusief met StackedQueryKeyTensor, StackedKeyValueTensor en StackedQueryKeyValueTensor. De tensor kan ook 4 of 5 dimensies hebben, zolang de voorloopdimensies 1 zijn.
ValueTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Waarde met vorm [batchSize, keyValueSequenceLength, valueHiddenSize], waarbij valueHiddenSize = headCount * valueHeadSize. Deze tensor is wederzijds exclusief met StackedKeyValueTensor en StackedQueryKeyValueTensor. De tensor kan ook 4 of 5 dimensies hebben, zolang de voorloopdimensies 1 zijn.
StackedQueryKeyTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Gestapelde query en sleutel met vorm [batchSize, sequenceLength, headCount, 2, headSize]. Deze tensor is wederzijds exclusief met QueryTensor, KeyTensor, StackedKeyValueTensor en StackedQueryKeyValueTensor.
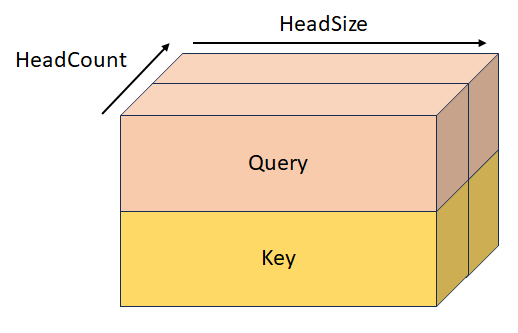
StackedKeyValueTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Gestapelde sleutel en waarde met vorm [batchSize, keyValueSequenceLength, headCount, 2, headSize]. Deze tensor is wederzijds exclusief met KeyTensor, ValueTensor, StackedQueryKeyTensor en StackedQueryKeyValueTensor.
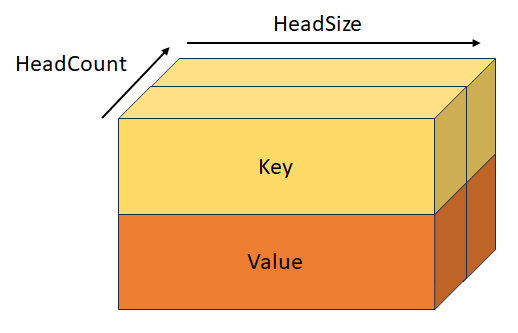
StackedQueryKeyValueTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Gestapelde query, sleutel en waarde met shape [batchSize, sequenceLength, headCount, 3, headSize]. Deze tensor is wederzijds exclusief met QueryTensor, KeyTensor, ValueTensor, StackedQueryKeyTensor en StackedKeyValueTensor.
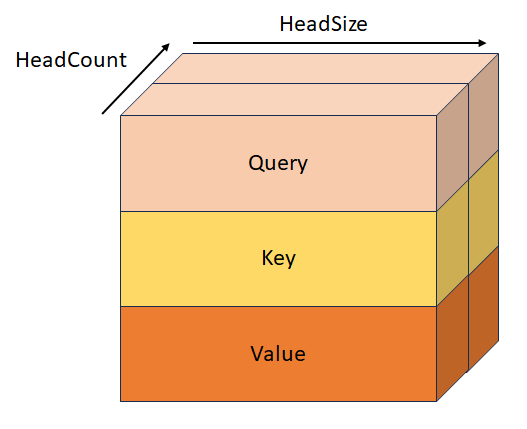
BiasTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Dit is de vooroordelen van de shape[hiddenSize + hiddenSize + valueHiddenSize], die vóór de eerste GEMM-bewerking wordt toegevoegd aan de//. Deze tensor kan ook 2, 3, 4 of 5 dimensies hebben, zolang de voorloopdimensies 1 zijn.
MaskTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Dit is het masker dat bepaalt welke elementen hun waarde instellen op MaskFilterValue na de QxK GEMM-bewerking. Het gedrag van dit masker is afhankelijk van de waarde van MaskType en wordt toegepast na RelativePositionBiasTensor of na de eerste GEMM-bewerking als RelativePositionBiasTensor null is. Zie de definitie van MaskType voor meer informatie.
RelativePositionBiasTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Dit is de vooroordelen die worden toegevoegd aan het resultaat van de eerste GEMM-bewerking.
PastKeyTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Sleuteltensor uit de vorige iteratie met vorm [batchSize, headCount, pastSequenceLength, headSize]. Wanneer deze tensor niet null is, wordt deze samengevoegd met de sleuteltensor, wat resulteert in een tensor van de vorm [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize].
PastValueTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Waarde-tensor uit de vorige iteratie met vorm [batchSize, headCount, pastSequenceLength, headSize]. Wanneer deze tensor niet null is, wordt deze samengevoegd met ValueDesc , wat resulteert in een tensor van de vorm [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize].
OutputTensor
Type: const DML_TENSOR_DESC*
Uitvoer, van vorm [batchSize, sequenceLength, valueHiddenSize].
OutputPresentKeyTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Huidige status voor kruislingse aandachtssleutel, met vorm [batchSize, headCount, keyValueSequenceLength, headSize] of huidige status voor zelf aandacht met vorm [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize]. Deze bevat de inhoud van de sleuteltensor of de inhoud van de samengevoegdePastKey-sleuteltensor + die moet worden doorgegeven aan de volgende iteratie.
OutputPresentValueTensor
Type: _Maybenull_ const DML_TENSOR_DESC*
Huidige status voor kruislingse aandachtswaarde, met vorm [batchSize, headCount, keyValueSequenceLength, headSize] of huidige status voor zelf aandacht met vorm [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize]. Deze bevat de inhoud van de waarde tensor of de inhoud van de samengevoegde PastValueValue-tensor + die moet worden doorgegeven aan de volgende iteratie.
Scale
Type: VLOTTER
Schaal om het resultaat van de QxK GEMM-bewerking te vermenigvuldigen, maar vóór de Softmax-bewerking. Deze waarde is meestal 1/sqrt(headSize).
MaskFilterValue
Type: VLOTTER
Waarde die wordt toegevoegd aan het resultaat van de QxK GEMM-bewerking aan de posities die het masker heeft gedefinieerd als opvullingselementen. Deze waarde moet een zeer groot negatief getal zijn (meestal -10000,0f).
HeadCount
Soort: UINT
Aantal aandachtskoppen.
MaskType
Soort: DML_MULTIHEAD_ATTENTION_MASK_TYPE
Beschrijft het gedrag van MaskTensor.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_BOOLEAN. Wanneer het masker een waarde van 0 bevat, wordt MaskFilterValue toegevoegd; maar als deze een waarde van 1 bevat, wordt er niets toegevoegd.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_SEQUENCE_LENGTH. Het masker, van vorm [1, batchSize], bevat de reekslengten van het niet-gepadde gebied voor elke batch en alle elementen nadat de reekslengte de waarde heeft ingesteld op MaskFilterValue.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_SEQUENCE_END_START. Het masker, van vorm [2, batchSize], bevat de eindindexen (exclusief) en beginindexen van het niet-afgeschermde gebied en alle elementen buiten het gebied krijgen hun waarde ingesteld op MaskFilterValue.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_QUERY_SEQUENCE_LENGTH_START_END. Het masker, van vorm[batchSize * 3 + 2], heeft de volgende waarden: [keyLength[0], ..., keyLength[batchSize - 1], queryStart[0], ..., queryStart[batchSize - 1], queryEnd[batchSize - 1], keyStart[0], ..., keyStart[batchSize - 1], keyEnd[batchSize - 1]]
Beschikbaarheid
Deze operator is geïntroduceerd in DML_FEATURE_LEVEL_6_1.
Tensor-beperkingen
BiasTensor, KeyTensor, OutputPresentKeyTensor, OutputPresentValueTensor, OutputTensor, PastKeyTensor, PastValueTensor, QueryTensor, RelativePositionBiasTensor, StackedKeyValueTensor, StackedQueryKeyTensor, StackedQueryKeyValueTensor en ValueTensor moeten hetzelfde DataType hebben.
Ondersteuning voor Tensor
| Tensor | Soort | Ondersteunde dimensieaantallen | Ondersteunde gegevenstypen |
|---|---|---|---|
| QueryTensor | Optionele invoer | 3 tot 5 | FLOAT32, FLOAT16 |
| KeyTensor | Optionele invoer | 3 tot 5 | FLOAT32, FLOAT16 |
| WaardeTensor | Optionele invoer | 3 tot 5 | FLOAT32, FLOAT16 |
| GestapeldeQueryKeyTensor | Optionele invoer | 5 | FLOAT32, FLOAT16 |
| Gestapelde KeyValueTensor | Optionele invoer | 5 | FLOAT32, FLOAT16 |
| GestapeldeQueryKeyValueTensor | Optionele invoer | 5 | FLOAT32, FLOAT16 |
| Vooringenomenheid Tensor | Optionele invoer | 1 tot 5 | FLOAT32, FLOAT16 |
| Masker Tensor | Optionele invoer | 1 tot 5 | INT32 |
| RelativePositionBiasTensor | Optionele invoer | 4 tot 5 | FLOAT32, FLOAT16 |
| PastKeyTensor | Optionele invoer | 4 tot 5 | FLOAT32, FLOAT16 |
| VerledenWaardeTensor | Optionele invoer | 4 tot 5 | FLOAT32, FLOAT16 |
| Uitvoer Tensor | Uitvoer | 3 tot 5 | FLOAT32, FLOAT16 |
| OutputPresentKeyTensor | Optionele uitvoer | 4 tot 5 | FLOAT32, FLOAT16 |
| OutputPresentValueTensor | Optionele uitvoer | 4 tot 5 | FLOAT32, FLOAT16 |
Behoeften
| Rubriek | directml.h |