Odporność i odzyskiwania po awarii w usłudze Azure SignalR Service
Odporność i odzyskiwanie po awarii to typowe potrzeby systemów online. Usługa Azure SignalR Service zapewnia już dostępność na poziomie 99,9%, jednak nadal jest to usługa regionalna. W przypadku awarii całego regionu wystąpienie usługi nie przechodzi w tryb failover do innego regionu, ponieważ zawsze działa w jednym regionie.
W przypadku regionalnego odzyskiwania po awarii zalecamy następujące dwa podejścia:
- Włącz replikację geograficzną (łatwy sposób). Ta funkcja automatycznie obsługuje regionalne przejście w tryb failover. Po włączeniu jest tylko jedno wystąpienie usługi Azure SignalR i nie wprowadzono żadnych zmian w kodzie. Sprawdź replikację geograficzną, aby uzyskać szczegółowe informacje.
- Korzystanie z wielu punktów końcowych w zestawie SDK usługi. Nasz zestaw SDK usługi obsługuje wiele wystąpień usługi SignalR i automatycznie przełącza się do innych wystąpień, gdy niektóre z nich są niedostępne. Dzięki tej funkcji możesz odzyskać dane po awarii, ale musisz samodzielnie skonfigurować właściwą topologię systemu. Dowiesz się, jak to zrobić w tym dokumencie.
Architektura wysokiej dostępności usługi SignalR
Aby zapewnić odporność między regionami dla usługi SignalR, należy skonfigurować wiele wystąpień usługi w różnych regionach. Wtedy gdy jeden region nie działa, można użyć innych jako zapasowych. Gdy serwery aplikacji łączą się z wieloma wystąpieniami usługi, istnieją dwie role: podstawowa i pomocnicza. Primary jest wystąpieniem odpowiedzialnym za odbieranie ruchu online, a pomocnicze służy jako wystąpienie rezerwowe, które jest w pełni funkcjonalne. W implementacji zestawu SDK negocjacja zwraca tylko podstawowe punkty końcowe, więc klienci łączą się tylko z podstawowymi punktami końcowymi w normalnych przypadkach. Jednak gdy wystąpienie podstawowe nie działa, negocjacja zwraca pomocnicze punkty końcowe, aby klient mógł nadal wykonywać połączenia. Wystąpienie podstawowe i serwer aplikacji są połączone za pośrednictwem normalnych połączeń serwera, ale wystąpienie pomocnicze i serwer aplikacji są połączone za pośrednictwem specjalnego typu połączenia nazywanego słabym połączeniem. Jedną z cech wyróżniających słabe połączenie jest to, że nie można zaakceptować routingu połączeń klienta ze względu na lokalizację wystąpienia pomocniczego w innym regionie. Routing klienta do innego regionu nie jest optymalnym wyborem (zwiększa opóźnienie).
Jedno wystąpienie usługi może mieć różne role, jeśli łączy się z wieloma serwerami aplikacji. Jedną z typowych konfiguracji scenariusza między regionami jest posiadanie co najmniej dwóch par wystąpień usługi SignalR i serwerów aplikacji. W każdej parze serwer aplikacji i usługa SignalR znajdują się w tym samym regionie, a usługa SignalR jest połączona z serwerem aplikacji za pomocą roli podstawowej. Serwer aplikacji i usługa SignalR w różnych parach są także połączone, lecz usługa SignalR łączy się z serwerem w innym regionie jako pomocnicza.
W takiej topologii komunikat z jednego serwera może być w dalszym ciągu dostarczony do wszystkich klientów, ponieważ wszystkie serwery aplikacji i wystąpienia usługi SignalR są wzajemnie połączone. Jednak po nawiązaniu połączenia klient kieruje go do serwera aplikacji w tym samym regionie, aby uzyskać optymalne opóźnienie sieci.
Na poniższym diagramie przedstawiono taką topologię:
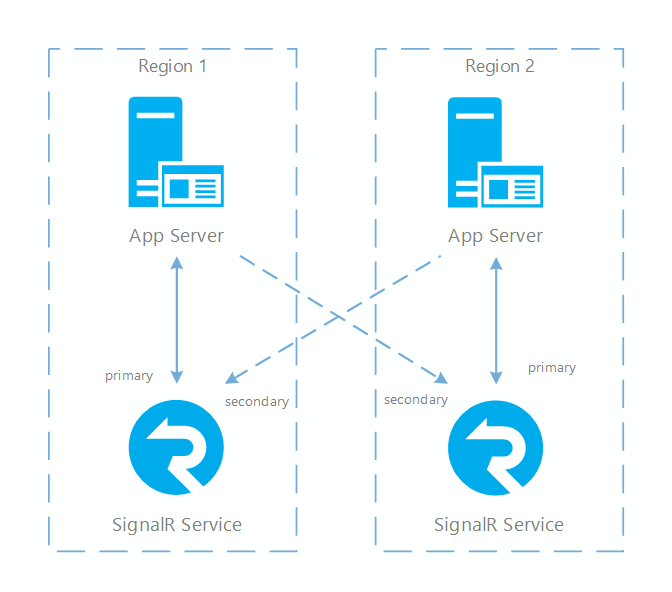
Konfigurowanie wielu wystąpień usługi SignalR
Wiele wystąpień usługi SignalR jest obsługiwanych zarówno na serwerach aplikacji, jak i w usłudze Azure Functions.
Po utworzeniu usługi SignalR i serwerów aplikacji/usługi Azure Functions utworzonych w każdym regionie możesz skonfigurować serwery aplikacji/usługę Azure Functions tak, aby łączyły się ze wszystkimi wystąpieniami usługi SignalR Service.
Konfigurowanie na serwerach aplikacji
Można to zrobić na dwa sposoby:
Za pomocą konfiguracji
Musisz już wiedzieć, jak ustawić usługę SignalR service parametry połączenia za pomocą zmiennych środowiskowych/ustawień aplikacji/web.cofig w wpisie konfiguracji o nazwie Azure:SignalR:ConnectionString.
Jeśli masz wiele punktów końcowych, możesz je umieścić w wielu wpisach konfiguracji, z których każdy jest w następującym formacie:
Azure:SignalR:ConnectionString:<name>:<role>
W Połączenie ionString <name> jest nazwą punktu końcowego i <role> jest jego rolą (podstawową lub pomocniczą).
Nazwa jest opcjonalna, ale jest przydatna, jeśli chcesz jeszcze bardziej dostosować zachowanie routingu między wieloma punktami końcowymi.
Za pomocą kodu
Jeśli wolisz przechowywać parametry połączenia w innym miejscu, możesz je również odczytać w kodzie i użyć ich jako parametrów podczas wywoływania AddAzureSignalR() (w ASP.NET Core) lub MapAzureSignalR() (w ASP.NET).
Oto przykładowy kod:
ASP.NET Core:
services.AddSignalR()
.AddAzureSignalR(options => options.Endpoints = new ServiceEndpoint[]
{
new ServiceEndpoint("<connection_string1>", EndpointType.Primary, "region1"),
new ServiceEndpoint("<connection_string2>", EndpointType.Secondary, "region2"),
});
ASP.NET:
app.MapAzureSignalR(GetType().FullName, hub, options => options.Endpoints = new ServiceEndpoint[]
{
new ServiceEndpoint("<connection_string1>", EndpointType.Primary, "region1"),
new ServiceEndpoint("<connection_string2>", EndpointType.Secondary, "region2"),
};
Można skonfigurować wiele wystąpień podstawowych lub pomocniczych. Jeśli istnieje wiele wystąpień podstawowych i/lub pomocniczych, negocjacja zwraca punkt końcowy w następującej kolejności:
- Jeśli istnieje co najmniej jedno wystąpienie podstawowe w trybie online, zwróć losowe wystąpienie podstawowe online.
- Jeśli wszystkie wystąpienia podstawowe nie działają, zwróć losowe pomocnicze wystąpienie online.
Konfigurowanie w usłudze Azure Functions
Zobacz ten artykuł.
Sekwencja trybu failover i najlepsze rozwiązania
Teraz masz skonfigurowaną właściwą topologię systemu. Za każdym razem, gdy jedno wystąpienie usługi SignalR nie działa, ruch online jest kierowany do innych wystąpień. Oto, co się stanie, gdy wystąpienie podstawowe nie działa (i odzyskuje się po pewnym czasie):
- Wystąpienie usługi podstawowej nie działa, a wszystkie połączenia serwera na tym wystąpieniu upuszczają.
- Wszystkie serwery połączone z tym wystąpieniem oznaczają je jako offline, a negocjacja zatrzymuje zwracanie tego punktu końcowego i rozpoczyna zwracanie pomocniczego punktu końcowego.
- Wszystkie połączenia klienta w tym wystąpieniu są również zamknięte, klienci następnie ponownie nawiązuj połączenie. Ponieważ serwery aplikacji zwracają teraz pomocniczy punkt końcowy, klienci łączą się z wystąpieniem pomocniczym.
- Teraz wystąpienie pomocnicze obsługuje cały ruch w trybie online. Wszystkie komunikaty wysyłane przez serwer do klientów nadal mogą być dostarczane, ponieważ wystąpienie pomocnicze jest połączone ze wszystkimi serwerami aplikacji. Jednak komunikaty wysyłane przez klienta do serwera są kierowane tylko do serwera aplikacji w tym samym regionie.
- Po odzyskaniu wystąpienia podstawowego i jego przejściu z powrotem w tryb online serwer aplikacji nawiąże z nim połączenie ponownie i oznaczy je jako będące w trybie online. Negocjacja zwraca teraz ponownie podstawowy punkt końcowy, więc nowi klienci są połączeni z powrotem z serwerem podstawowym. Ale istniejący klienci nie upuszczają się i są nadal kierowani do pomocniczej, dopóki nie rozłączą się.
Poniższe diagramy przedstawiają przechodzenie w tryb failover przez usługę SignalR:
Rys.1 Przed przejściem w tryb failover 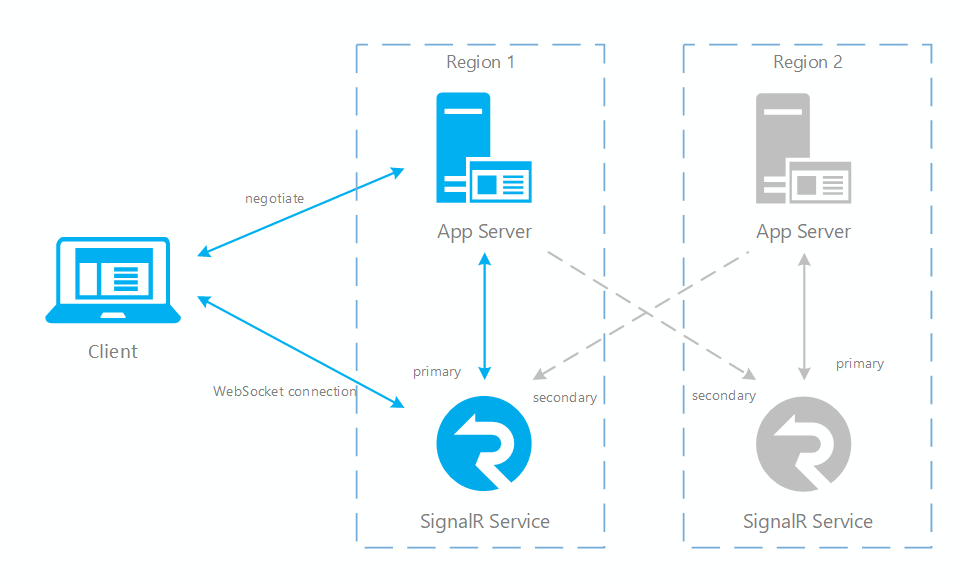
Rysunek 2 po przejściu w tryb failover 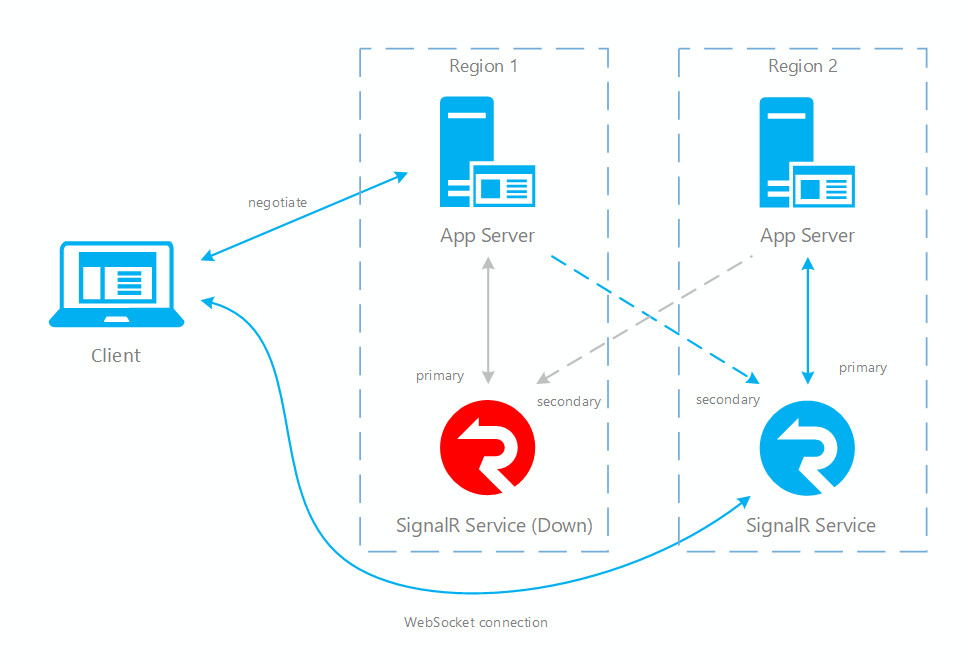
Rys.3 Krótki czas po odzyskaniu podstawowego 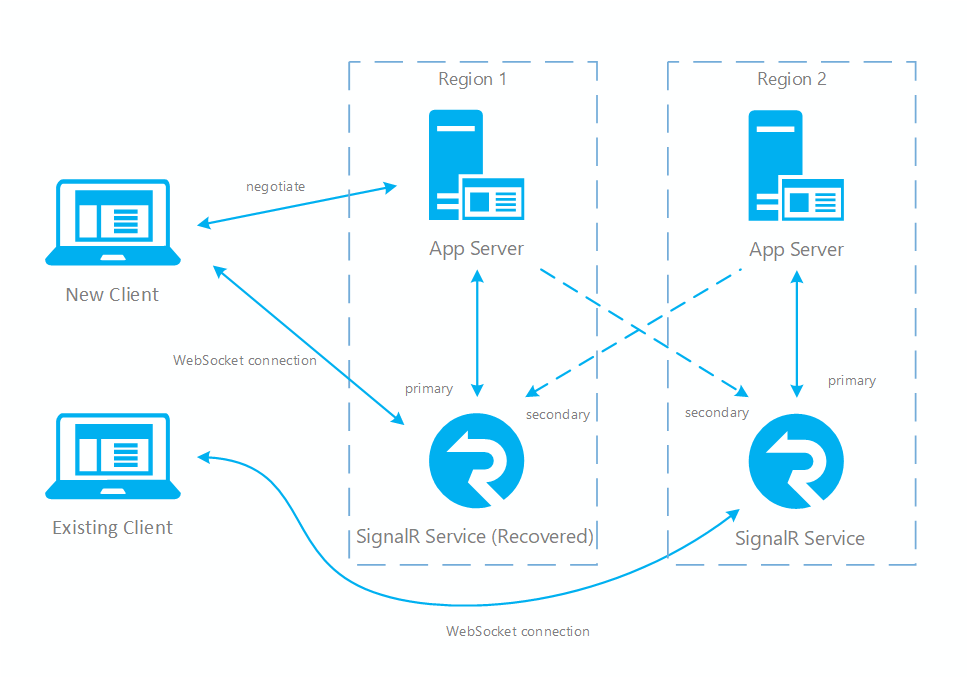
Jak widać, w normalnym przypadku tylko podstawowy serwer aplikacji i podstawowa usługa SignalR obsługują ruch online (w kolorze niebieskim). Po przejściu w tryb failover pomocniczy serwer aplikacji i pomocnicza usługa SignalR także stają się aktywne. Gdy podstawowa usługa SignalR wróci do trybu online, nowi klienci będą łączyć się z podstawową usługą SignalR. Lecz istniejący klienci nadal będą łączyć się z wystąpieniem pomocniczym, więc oba wystąpienia będą obsługiwać ruch. Gdy wszyscy istniejący klienci rozłączą się, system wróci do normalnego stanu (Rys. 1).
Architekturę wysokiej dostępności z wieloma regionami można zaimplementować za pomocą dwóch głównych wzorców:
- Pierwszy to para serwer aplikacji i wystąpienie usługi SignalR obsługujące cały ruch online z inną parą jako zapasem (wzorzec aktywny/pasywny przedstawiony na rysunku 1).
- Drugi to dwie (lub więcej) pary serwerów aplikacji i wystąpień usługi SignalR, przy czym wszystkie obsługują ruch online i służą jako zapas dla innych par (wzorzec aktywny/aktywny podobny do przedstawionego na rysunku 3).
Usługa SignalR może obsługiwać oba wzorce, a główna różnica zależy od sposobu implementacji serwerów aplikacji. Jeśli serwery aplikacji są aktywne/pasywne, usługa SignalR jest również aktywna/pasywna (ponieważ podstawowy serwer aplikacji zwraca tylko jego podstawowe wystąpienie usługi SignalR). Jeśli serwery aplikacji są aktywne/aktywne, usługa SignalR jest również aktywna/aktywna (ponieważ wszystkie serwery aplikacji zwracają własne podstawowe wystąpienia usługi SignalR, więc wszystkie z nich mogą uzyskać ruch).
Należy zauważyć, że niezależnie od wzorców, które należy użyć, należy połączyć każde wystąpienie usługi SignalR z serwerem aplikacji jako podstawowym.
Ponadto ze względu na charakter połączenia usługi SignalR (jest to długie połączenie), klienci doświadczają przerywania połączenia w przypadku awarii i przejścia w tryb failover. Należy obsługiwać takie przypadki po stronie klienta, aby były niewidoczne dla klientów końcowych. Na przykład należy nawiązać ponownie połączenie po zamknięciu połączenia.
Jak przetestować tryb failover
Wykonaj kroki, aby wyzwolić tryb failover:
- Na karcie Sieć zasobu podstawowego w portalu wyłącz dostęp do sieci publicznej. Jeśli zasób ma włączoną sieć prywatną, użyj reguł kontroli dostępu, aby odmówić całego ruchu.
- Uruchom ponownie zasób podstawowy.
Następne kroki
W tym artykule przedstawiono sposób konfigurowania aplikacji w celu uzyskania odporności na potrzeby usługi SignalR Service. Aby dowiedzieć się więcej na temat połączenia serwera/klienta i routingu połączenia w usłudze SignalR, możesz przeczytać ten artykuł przedstawiający elementy wewnętrzne usługi SignalR.
W przypadku scenariuszy skalowania, takich jak fragmentowanie, które używa wielu wystąpień razem do obsługi dużej liczby połączeń, przeczytaj , jak skalować wiele wystąpień.
Aby uzyskać szczegółowe informacje na temat konfigurowania usługi Azure Functions z wieloma wystąpieniami usługi SignalR Service, przeczytaj wiele wystąpień usługi Azure SignalR Service obsługujących usługę Azure Functions.