Używanie programu Apache Hive jako narzędzia wyodrębniania, przekształcania i ładowania (ETL)
Zazwyczaj należy oczyścić i przekształcić dane przychodzące przed załadowaniem ich do miejsca docelowego odpowiedniego do analizy. Operacje wyodrębniania, przekształcania i ładowania (ETL) służą do przygotowywania danych i ładowania ich do miejsca docelowego danych. Usługa Apache Hive w usłudze HDInsight może odczytywać dane bez struktury, przetwarzać je zgodnie z potrzebami, a następnie ładować je do relacyjnego magazynu danych na potrzeby systemów pomocy technicznej podejmowania decyzji. W tym podejściu dane są wyodrębniane ze źródła. Następnie przechowywane w magazynie dostosowywalnym, takim jak obiekty blob usługi Azure Storage lub usługa Azure Data Lake Storage. Dane są następnie przekształcane przy użyciu sekwencji zapytań hive. Następnie przygotowane w programie Hive w ramach przygotowania do zbiorczego ładowania do docelowego magazynu danych.
Omówienie przypadku użycia i modelu
Na poniższej ilustracji przedstawiono przegląd przypadku użycia i modelu automatyzacji ETL. Dane wejściowe są przekształcane w celu wygenerowania odpowiednich danych wyjściowych. Podczas tej transformacji dane zmieniają kształt, typ danych, a nawet język. Procesy ETL mogą konwertować imperialne na metryki, zmieniać strefy czasowe i poprawiać precyzję w celu prawidłowego dopasowania do istniejących danych w miejscu docelowym. Procesy ETL mogą również łączyć nowe dane z istniejącymi danymi, aby zapewnić aktualność raportowania lub zapewnić dalszy wgląd w istniejące dane. Aplikacje, takie jak narzędzia do raportowania i usługi, mogą następnie korzystać z tych danych w żądanym formacie.
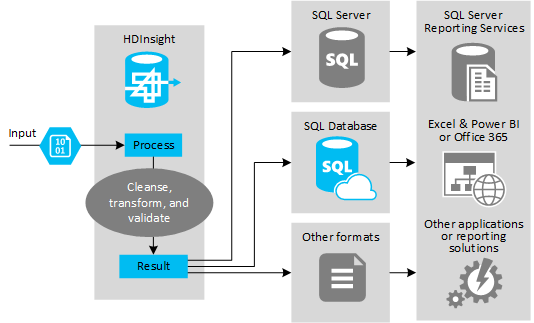
Usługa Hadoop jest zwykle używana w procesach ETL, które importują dużą liczbę plików tekstowych (takich jak woluminy CSV). Albo mniejsza, ale często zmieniana liczba plików tekstowych lub obu tych plików. Hive to doskonałe narzędzie do przygotowania danych przed załadowaniem ich do miejsca docelowego danych. Program Hive umożliwia tworzenie schematu w pliku CSV i używanie języka przypominającego sql do generowania programów MapReduce, które współdziałają z danymi.
Typowe kroki używania programu Hive do etL są następujące:
Załaduj dane do usługi Azure Data Lake Storage lub Azure Blob Storage.
Utwórz bazę danych magazynu metadanych (przy użyciu usługi Azure SQL Database) do użycia przez program Hive w przechowywaniu schematów.
Utwórz klaster usługi HDInsight i połącz magazyn danych.
Zdefiniuj schemat, który ma być stosowany w czasie odczytu danych w magazynie danych:
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';Przekształć dane i załadować je do miejsca docelowego. Istnieje kilka sposobów używania programu Hive podczas przekształcania i ładowania:
- Wykonywanie zapytań i przygotowywanie danych przy użyciu programu Hive i zapisywanie ich jako woluminu CSV w usłudze Azure Data Lake Storage lub usłudze Azure Blob Storage. Następnie użyj narzędzia, takiego jak usługi SQL Server Integration Services (SSIS), aby uzyskać te woluminy CSV i załadować dane do docelowej relacyjnej bazy danych, takiej jak program SQL Server.
- Wykonywanie zapytań dotyczących danych bezpośrednio z programu Excel lub C# przy użyciu sterownika Hive ODBC.
- Użyj narzędzia Apache Sqoop , aby odczytać przygotowane płaskie pliki CSV i załadować je do docelowej relacyjnej bazy danych.
Źródła danych
Źródła danych to zazwyczaj dane zewnętrzne, które mogą być dopasowane do istniejących danych w magazynie danych, na przykład:
- Dane mediów społecznościowych, pliki dziennika, czujniki i aplikacje generujące pliki danych.
- Zestawy danych uzyskane od dostawców danych, takie jak statystyki pogody lub numery sprzedaży dostawców.
- Dane przesyłane strumieniowo przechwytywane, filtrowane i przetwarzane za pomocą odpowiedniego narzędzia lub struktury.
Miejsca docelowe danych wyjściowych
Możesz użyć programu Hive do wyprowadzania danych do różnych rodzajów obiektów docelowych, w tym:
- Relacyjna baza danych, taka jak SQL Server lub Azure SQL Database.
- Magazyn danych, taki jak Azure Synapse Analytics.
- Excel.
- Usługa Azure Table i blob Storage.
- Aplikacje lub usługi, które wymagają przetwarzania danych w określonych formatach lub jako pliki zawierające określone typy struktury informacji.
- Magazyn dokumentów JSON, taki jak Azure Cosmos DB.
Kwestie wymagające rozważenia
Model ETL jest zwykle używany, gdy chcesz:
* Załaduj dane strumienia lub duże ilości częściowo ustrukturyzowanych lub nieustrukturyzowanych danych ze źródeł zewnętrznych do istniejącej bazy danych lub systemu informacyjnego.
* Wyczyść, przekształć i zweryfikuj dane przed załadowaniem, na przykład za pomocą więcej niż jednej transformacji przekazywanej przez klaster.
* Generowanie raportów i wizualizacji, które są regularnie aktualizowane. Jeśli na przykład generowanie raportu trwa zbyt długo w ciągu dnia, możesz zaplanować uruchamianie raportu w nocy. Aby automatycznie uruchomić zapytanie hive, możesz użyć usług Azure Logic Apps i PowerShell.
Jeśli element docelowy dla danych nie jest bazą danych, możesz wygenerować plik w odpowiednim formacie w zapytaniu, na przykład csv. Ten plik można następnie zaimportować do programu Excel lub usługi Power BI.
Jeśli musisz wykonać kilka operacji na danych w ramach procesu ETL, rozważ sposób zarządzania nimi. W przypadku operacji kontrolowanych przez program zewnętrzny, a nie jako przepływu pracy w rozwiązaniu, zdecyduj, czy niektóre operacje mogą być wykonywane równolegle. I wykryć, kiedy każde zadanie zostanie ukończone. Korzystanie z mechanizmu przepływu pracy, takiego jak Oozie w usłudze Hadoop, może być łatwiejsze niż organizowanie sekwencji operacji przy użyciu skryptów zewnętrznych lub programów niestandardowych.