Samouczek: debugowanie zestawu umiejętności przy użyciu sesji debugowania
Zestaw umiejętności koordynuje działania umiejętności, które analizują, przekształcają lub tworzą zawartość z możliwością wyszukiwania. Często dane wyjściowe jednej umiejętności stają się danymi wejściowymi innego. Gdy dane wejściowe zależą od danych wyjściowych, błędy w definicjach zestawu umiejętności i skojarzeniach pól mogą spowodować nieodebrane operacje i dane.
Sesje debugowania to narzędzie witryny Azure Portal, które zapewnia całościową wizualizację zestawu umiejętności. Za pomocą tego narzędzia możesz przejść do szczegółów określonych kroków, aby łatwo sprawdzić, gdzie może spadać akcja.
W tym artykule użyj sesji debugowania, aby znaleźć i naprawić brakujące dane wejściowe i wyjściowe. Samouczek jest all-inclusive. Udostępnia przykładowe dane, plik REST, który tworzy obiekty i instrukcje dotyczące debugowania problemów w zestawie umiejętności.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
Azure AI Search. Utwórz usługę lub znajdź istniejącą usługę w ramach bieżącej subskrypcji. W tym samouczku możesz skorzystać z bezpłatnej usługi.
Konto usługi Azure Storage z usługą Blob Storage używane do hostowania przykładowych danych oraz utrwalanie buforowanych danych utworzonych podczas sesji debugowania.
Program Visual Studio Code z klientem REST.
Przykładowy plik debug-sessions.rest używany do tworzenia potoku wzbogacania.
Uwaga
W tym samouczku używane są również usługi Azure AI do wykrywania języka, rozpoznawania jednostek i wyodrębniania kluczowych fraz. Ponieważ obciążenie jest tak małe, usługi azure AI są zakulisowe, aby bezpłatnie przetwarzać do 20 transakcji. Oznacza to, że możesz wykonać to ćwiczenie bez konieczności tworzenia rozliczanego zasobu usług Azure AI.
Konfigurowanie przykładowych danych
W tej sekcji tworzony jest przykładowy zestaw danych w usłudze Azure Blob Storage, dzięki czemu indeksator i zestaw umiejętności mają zawartość do pracy.
Pobierz przykładowe dane (clinical-trials-pdf-19), składające się z 19 plików.
Utwórz konto usługi Azure Storage lub znajdź istniejące konto.
Wybierz ten sam region co usługa Azure AI Search, aby uniknąć opłat za przepustowość.
Wybierz typ konta StorageV2 (ogólnego przeznaczenia w wersji 2).
Przejdź do stron usług Azure Storage w portalu i utwórz kontener obiektów blob. Najlepszym rozwiązaniem jest określenie poziomu dostępu "prywatny". Nadaj kontenerowi
clinicaltrialdatasetnazwę .W kontenerze wybierz pozycję Przekaż , aby przekazać pobrane i rozpakowane pliki przykładowe w pierwszym kroku.
W portalu skopiuj parametry połączenia dla usługi Azure Storage. Możesz uzyskać parametry połączenia z poziomu kluczy Ustawienia> Access w portalu.
Kopiowanie klucza i adresu URL
Wywołania REST wymagają punktu końcowego usługi wyszukiwania i klucza interfejsu API dla każdego żądania. Te wartości można uzyskać w witrynie Azure Portal.
Zaloguj się do witryny Azure Portal, przejdź do strony Przegląd i skopiuj adres URL. Przykładowy punkt końcowy może wyglądać podobnie jak
https://mydemo.search.windows.net.W obszarze Ustawienia> Keys skopiuj klucz administratora. Administracja klucze służą do dodawania, modyfikowania i usuwania obiektów. Istnieją dwa zamienne klucze administratora. Skopiuj jedną z nich.
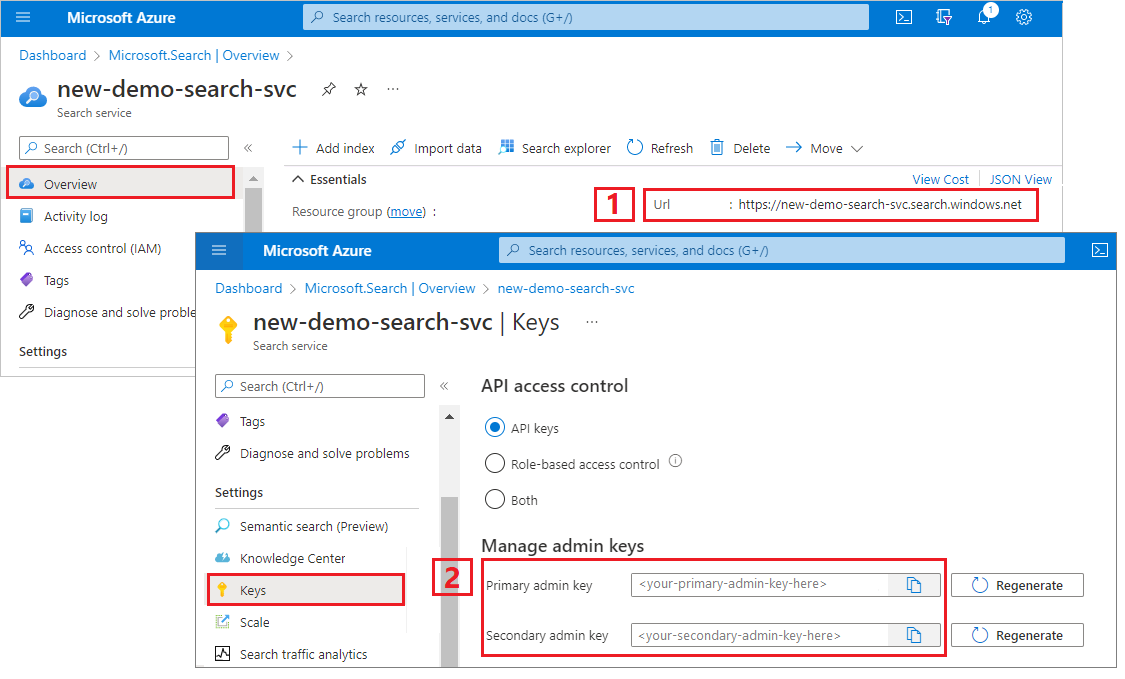
Prawidłowy klucz interfejsu API ustanawia relację zaufania dla poszczególnych żądań między aplikacją wysyłającą żądanie a usługą wyszukiwania, która go obsługuje.
Tworzenie źródła danych, zestawu umiejętności, indeksu i indeksatora
W tej sekcji utwórz przepływ pracy "buggy", który można naprawić w tym samouczku.
Uruchom program Visual Studio Code i otwórz
debug-sessions.restplik.Podaj następujące zmienne: adres URL usługi wyszukiwania, klucz interfejsu API administratora usług wyszukiwania, parametry połączenia magazynu i nazwę kontenera obiektów blob przechowując pliki PDF.
Wyślij każde żądanie z kolei. Tworzenie indeksatora trwa kilka minut.
Zamknij plik.
Sprawdzanie wyników w portalu
Przykładowy kod celowo tworzy indeks usterek w wyniku problemów, które wystąpiły podczas wykonywania zestawu umiejętności. Problem polega na tym, że w indeksie brakuje danych.
W witrynie Azure Portal na stronie Przegląd usługi wyszukiwania wybierz kartę Indeksy.
Wybierz badania kliniczne.
Wprowadź ten ciąg zapytania JSON w widoku JSON eksploratora wyszukiwania. Zwraca pola dla określonych dokumentów (zidentyfikowanych przez unikatowe
metadata_storage_pathpole)."select": "metadata_storage_path, organizations, locations", "count"=true`Uruchamianie zapytania. Powinny zostać wyświetlone puste wartości dla
organizationsilocations.Te pola powinny zostać wypełnione za pomocą umiejętności rozpoznawania jednostek zestawu umiejętności, używanej do wykrywania organizacji i lokalizacji w dowolnym miejscu zawartości obiektu blob. W następnym ćwiczeniu z debugujesz zestaw umiejętności, aby określić, co poszło nie tak.
Innym sposobem zbadania błędów i ostrzeżeń jest witryna Azure Portal.
Otwórz kartę Indeksatory i wybierz pozycję clinical-trials-idxr.
Zwróć uwagę, że chociaż zadanie indeksatora zakończyło się pomyślnie, wystąpiły ostrzeżenia.
Wybierz pozycję Powodzenie , aby wyświetlić ostrzeżenia (jeśli wystąpiły głównie błędy, link szczegółów będzie niepowodzeniem). Zobaczysz długą listę wszystkich ostrzeżeń emitowanych przez indeksator.

Uruchamianie sesji debugowania
W okienku nawigacji po lewej stronie usługi wyszukiwania w obszarze Zarządzanie wyszukiwaniem wybierz pozycję Sesje debugowania.
Wybierz pozycję + Dodaj sesję debugowania.
Nadaj sesji nazwę.
Połączenie sesji na koncie magazynu. Utwórz kontener o nazwie "sesje debugowania". Tego kontenera można wielokrotnie używać do przechowywania wszystkich danych sesji debugowania.
Jeśli skonfigurowano zaufane połączenie między wyszukiwaniem i magazynem, wybierz tożsamość zarządzaną przez użytkownika lub tożsamość systemu dla połączenia. W przeciwnym razie użyj wartości domyślnej (Brak).
W szablonie indeksatora podaj nazwę indeksatora. Indeksator zawiera odwołania do źródła danych, zestawu umiejętności i indeksu.
Zaakceptuj domyślny wybór dokumentu dla pierwszego dokumentu w kolekcji. Sesja debugowania działa tylko z jednym dokumentem. Możesz wybrać dokument do debugowania lub po prostu użyć pierwszego dokumentu.
Zapisz sesję. Zapisanie sesji spowoduje uruchomienie potoku wzbogacania zgodnie z definicją zestawu umiejętności dla wybranego dokumentu.

Po zakończeniu inicjowania sesji debugowania sesja jest domyślnie ustawiona na karcie Wzbogacanie sztucznej inteligencji z wyróżnionym wykresem umiejętności. Wykres umiejętności zapewnia wizualną hierarchię zestawu umiejętności oraz kolejność wykonywania sekwencyjnie i równolegle.

Znajdowanie problemów z zestawem umiejętności
Wszelkie problemy zgłaszane przez indeksator można znaleźć na sąsiedniej karcie Błędy /Ostrzeżenia.

Zwróć uwagę, że karta Błędy /Ostrzeżenia będzie zawierać znacznie mniejszą listę niż wyświetlana wcześniej, ponieważ ta lista zawiera tylko szczegóły błędów dla pojedynczego dokumentu. Podobnie jak lista wyświetlana przez indeksator, możesz wybrać komunikat ostrzegawczy i wyświetlić szczegóły tego ostrzeżenia.
Wybierz pozycję Błędy /ostrzeżenia, aby przejrzeć powiadomienia. Powinny zostać wyświetlone cztery:
"Nie można wykonać umiejętności, ponieważ co najmniej jeden wkład umiejętności był nieprawidłowy. Brak wymaganych danych wejściowych umiejętności. Nazwa: "text", Źródło: '/document/content'".
"Nie można zamapować pola wyjściowego "locations" na indeks wyszukiwania. Sprawdź właściwość "outputFieldMappings" indeksatora. Brak wartości "/document/merged_content/locations".
"Nie można mapować pola wyjściowego "organizacje" na indeks wyszukiwania. Sprawdź właściwość "outputFieldMappings" indeksatora. Brak wartości "/document/merged_content/organizations".
"Wykonane umiejętności, ale mogą mieć nieoczekiwane wyniki, ponieważ co najmniej jeden wkład umiejętności był nieprawidłowy. Brak opcjonalnych danych wejściowych umiejętności. Nazwa: 'languageCode', Źródło: '/document/languageCode'. Problemy z analizowaniem języka wyrażeń: Brak wartości "/document/languageCode".
Wiele umiejętności ma parametr "languageCode". Sprawdzając operację, możesz zobaczyć, że w danych wyjściowych tego języka brakuje EntityRecognitionSkill.#1danych wejściowych kodu języka , co jest tą samą umiejętnością rozpoznawania jednostek, która ma problemy z danymi wyjściowymi "lokalizacji" i "organizacji".
Ponieważ wszystkie cztery powiadomienia dotyczą tej umiejętności, następnym krokiem jest debugowanie tej umiejętności. Jeśli to możliwe, najpierw rozwiąż problemy z danymi wejściowymi przed przejściem do problemów z danymi wyjściowymi.
Naprawianie brakujących wartości wejściowych umiejętności
Na karcie Błędy /ostrzeżenia brakuje dwóch danych wejściowych dla operacji oznaczonej EntityRecognitionSkill.#1etykietą . Szczegóły pierwszego błędu wyjaśniają, że brakuje wymaganych danych wejściowych dla "tekstu". Drugi wskazuje problem z wartością wejściową "/document/languageCode".
W grafie umiejętności wzbogacania>sztucznej inteligencji wybierz umiejętności oznaczone jako #1, aby wyświetlić jego szczegóły w okienku po prawej stronie.
Wybierz kartę Wykonania i znajdź dane wejściowe "text".
Wybierz symbol />, <aby otworzyć ewaluator wyrażeń. Wyświetlany wynik dla tych danych wejściowych nie wygląda jak wprowadzanie tekstu. Wygląda jak seria nowych znaków
\n \n\n\n\nwiersza zamiast tekstu. Brak tekstu oznacza, że nie można zidentyfikować żadnych jednostek, więc ten dokument nie spełnia wymagań wstępnych umiejętności lub istnieje inne dane wejściowe, które powinny być używane.
Przełącz okienko po lewej stronie na wzbogaconą strukturę danych i przewiń listę węzłów wzbogacania dla tego dokumentu. Zwróć uwagę, że właściwość
\n \n\n\n\n"content" nie ma źródła źródłowego, ale inna wartość "merged_content" ma dane wyjściowe OCR. Chociaż nie ma żadnych wskazówek, zawartość tego pliku PDF wydaje się być plikiem JPEG, co jest dowodem wyodrębnionego i przetworzonego tekstu w "merged_content".
W okienku po prawej stronie wybierz pozycję Wykonania dla umiejętności #1 i otwórz ewaluator <wyrażeń /> dla wejściowego "tekstu".
Zmień wyrażenie z
/document/contentna/document/merged_content, a następnie wybierz pozycję Oceń. Zwróć uwagę, że zawartość jest teraz fragmentem tekstu i w związku z tym można go podjąć w celu rozpoznawania jednostek.
Przejdź do edytora JSON umiejętności.
W wierszu 16 w obszarze "inputs" zmień wartość
/document/contentna/document/merged_content.{ "name": "text", "source": "/document/merged_content" },Wybierz pozycję Zapisz w okienku Szczegóły umiejętności.

Wybierz pozycję Uruchom w menu okna sesji. Spowoduje to rozpoczęcie kolejnego wykonania zestawu umiejętności przy użyciu dokumentu.
Po zakończeniu wykonywania sesji debugowania sprawdź kartę Błędy/ostrzeżenia i zostanie wyświetlony komunikat o błędzie dla wprowadzania tekstu, ale pozostałe ostrzeżenia pozostaną. Następnym krokiem jest rozwiązanie problemu z ostrzeżeniem o "languageCode".

Wybierz kartę Wykonania i znajdź dane wejściowe dla pozycji "languageCode".
Wybierz symbol />, <aby otworzyć ewaluator wyrażeń. Zwróć uwagę na potwierdzenie, że właściwość "languageCode" nie jest prawidłowym wejściem.

Istnieją dwa sposoby badania tego błędu. Po pierwsze należy przyjrzeć się, skąd pochodzą dane wejściowe — jaka umiejętność w hierarchii ma wygenerować ten wynik? Karta Wykonania w okienku szczegółów umiejętności powinna zawierać źródło danych wejściowych. Jeśli nie ma źródła, oznacza to błąd mapowania pól.
Na karcie Wykonania sprawdź dane WEJŚCIOWE i znajdź ciąg "languageCode". Brak źródła dla tych danych wejściowych na liście.
Przełącz okienko po lewej stronie na wzbogaconą strukturę danych. Przewiń w dół listę węzłów wzbogacania dla tego dokumentu. Zwróć uwagę, że nie ma węzła "languageCode", ale istnieje jeden dla "language". W ustawieniach umiejętności jest więc literówka.

Nadal w wzbogaconej strukturze danych otwórz węzeł Ewaluator <wyrażeń /> dla węzła "language" i skopiuj wyrażenie
/document/language.W okienku po prawej stronie wybierz pozycję Umiejętności Ustawienia dla umiejętności #1 i otwórz ewaluator< wyrażeń /> dla danych wejściowych "languageCode".
Wklej nową wartość w
/document/languagepolu Wyrażenie i wybierz pozycję Oceń. Powinien on wyświetlić poprawne dane wejściowe "en".Wybierz pozycję Zapisz.
Wybierz Uruchom.
Po zakończeniu wykonywania sesji debugowania sprawdź kartę Błędy/ostrzeżenia i pokaże, że wszystkie ostrzeżenia wejściowe nie zostaną wyświetlone. Istnieją teraz tylko dwa ostrzeżenia dotyczące pól wyjściowych dla organizacji i lokalizacji.
Naprawianie brakujących wartości wyjściowych umiejętności
Komunikaty mówią, aby sprawdzić właściwość "outputFieldMappings" indeksatora, więc zacznijmy tam.
Przejdź do pozycji Wykres umiejętności i wybierz pozycję Mapowania pól wyjściowych. Mapowania są rzeczywiście poprawne, ale zwykle należy sprawdzić definicję indeksu, aby upewnić się, że pola istnieją dla "lokalizacji" i "organizacji".

Jeśli nie ma problemu z indeksem, następnym krokiem jest sprawdzenie danych wyjściowych umiejętności. Tak jak poprzednio, wybierz wzbogaconą strukturę danych i przewiń węzły, aby znaleźć "lokalizacje" i "organizacje". Zwróć uwagę, że element nadrzędny to "zawartość" zamiast "merged_content". Kontekst jest nieprawidłowy.

Wróć do grafu umiejętności i wybierz umiejętności rozpoznawania jednostek.
Przejdź do Ustawienia umiejętności, aby znaleźć "kontekst".

Kliknij dwukrotnie ustawienie "context" i edytuj je, aby odczytać "/document/merged_content".
Wybierz pozycję Zapisz.
Wybierz Uruchom.
Wszystkie błędy zostały rozwiązane.
Zatwierdzanie zmian w zestawie umiejętności
Po zainicjowaniu sesji debugowania usługa wyszukiwania utworzyła kopię zestawu umiejętności. Zostało to zrobione w celu ochrony oryginalnego zestawu umiejętności w usłudze wyszukiwania. Po zakończeniu debugowania zestawu umiejętności można przekazać poprawki (zastąpić oryginalny zestaw umiejętności).
Alternatywnie, jeśli nie jesteś gotowy do zatwierdzenia zmian, możesz zapisać sesję debugowania i ponownie otworzyć ją później.
Wybierz pozycję Zatwierdź zmiany w głównym menu Sesje debugowania.
Wybierz przycisk OK , aby potwierdzić, że chcesz zaktualizować zestaw umiejętności.
Zamknij sesję debugowania i otwórz indeksatory w okienku nawigacji po lewej stronie.
Wybierz pozycję "clinical-trials-idxr".
Wybierz Resetuj.
Wybierz Uruchom.
Wybierz pozycję Odśwież , aby wyświetlić stan poleceń resetowania i uruchamiania.
Po zakończeniu działania indeksatora powinien istnieć zielony znacznik wyboru i słowo Powodzenie obok sygnatury czasowej dla najnowszego uruchomienia na karcie Historia wykonywania. Aby upewnić się, że zmiany zostały zastosowane:
W okienku nawigacji po lewej stronie otwórz pozycję Indeksy.
Wybierz indeks "badania kliniczne", a następnie na karcie Eksplorator wyszukiwania wprowadź ten ciąg zapytania:
$select=metadata_storage_path, organizations, locations&$count=trueaby zwrócić pola dla określonych dokumentów (zidentyfikowanych przez unikatowemetadata_storage_pathpole).Wybierz Wyszukaj.
Wyniki powinny wskazywać, że organizacje i lokalizacje są teraz wypełniane oczekiwanymi wartościami.
Czyszczenie zasobów
Jeśli pracujesz w ramach własnej subskrypcji, dobrym pomysłem po zakończeniu projektu jest sprawdzenie, czy dalej potrzebujesz utworzonych zasobów. Uruchomione zasoby mogą generować koszty. Zasoby możesz usuwać pojedynczo lub jako grupę zasobów, usuwając cały zestaw zasobów.
Zasoby można znaleźć w portalu i zarządzać nimi, korzystając z linku Wszystkie zasoby lub Grupy zasobów w okienku nawigacji po lewej stronie.
Bezpłatna usługa jest ograniczona do trzech indeksów, indeksatorów i źródeł danych. Możesz usunąć poszczególne elementy w portalu, aby pozostać w limicie.
Następne kroki
Ten samouczek dotyczył różnych aspektów definicji i przetwarzania zestawu umiejętności. Aby dowiedzieć się więcej na temat pojęć i przepływów pracy, zapoznaj się z następującymi artykułami: