Tworzenie zapytania pełnotekstowego w usłudze Azure AI Search
Jeśli tworzysz zapytanie dotyczące wyszukiwania pełnotekstowego, ten artykuł zawiera kroki konfigurowania żądania. Wprowadzono również strukturę zapytań i wyjaśniono, jak atrybuty pól i analizatory językowe mogą mieć wpływ na wyniki zapytań.
Wymagania wstępne
Indeks wyszukiwania z polami ciągu przypisanymi jako
searchable.Uprawnienia do odczytu w indeksie wyszukiwania. Aby uzyskać dostęp do odczytu, dołącz klucz interfejsu API zapytania w żądaniu lub nadaj obiektowi wywołującemu uprawnienia Czytelnik danych indeksu wyszukiwania.
Przykład żądania zapytania pełnotekstowego
W usłudze Azure AI Search zapytanie jest żądaniem tylko do odczytu względem kolekcji dokumentacji pojedynczego indeksu wyszukiwania z parametrami, które informują o wykonywaniu zapytań i kształtują odpowiedź wracającą.
Zapytanie pełnotekstowe jest określane w parametrze search i składa się z terminów, fraz ujętych w cudzysłów i operatorów. Inne parametry dodają więcej definicji do żądania.
Następujące wywołanie interfejsu API REST wyszukiwania POST ilustruje żądanie zapytania przy użyciu wyżej wymienionych parametrów.
POST https://[service name].search.windows.net/indexes/hotels-sample-index/docs/search?api-version=2023-11-01
{
"search": "NY +view",
"queryType": "simple",
"searchMode": "all",
"searchFields": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"select": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"top": "10",
"count": "true"
}
Kluczowe punkty:
searchzawiera kryteria dopasowania, zazwyczaj całe terminy lub frazy, z operatorami lub bez. Każde pole, które jest przypisywane jako "możliwe do wyszukiwania" w schemacie indeksu, jest kandydatem dla tego parametru.queryTypeUstawia analizator:simple,full. Domyślny prosty analizator zapytań jest optymalny dla wyszukiwania pełnotekstowego. Pełny analizator zapytań Lucene jest przeznaczony dla zaawansowanych konstrukcji zapytań, takich jak wyrażenia regularne, wyszukiwanie w pobliżu, wyszukiwanie rozmyte i wieloznaczne. Ten parametr można również ustawić dlasemanticsemantycznego klasyfikacji dla zaawansowanego modelowania semantycznego w odpowiedzi na zapytanie.searchModeOkreśla, czy dopasowania są oparte na kryteriach "wszystkie" (faworyzuje precyzję) lub "dowolne" kryteria (faworyzowanie kompletności) w wyrażeniu. Wartość domyślna to "any". Jeśli przewidujesz duże wykorzystanie operatorów logicznych, co jest bardziej prawdopodobne w indeksach zawierających duże bloki tekstowe (pole zawartości lub długie opisy), pamiętaj, aby przetestować zapytania z parametremsearchMode=Any|All, aby ocenić wpływ tego ustawienia na wyszukiwanie logiczne.searchFieldsogranicza wykonywanie zapytań do określonych pól z możliwością wyszukiwania. Podczas programowania warto użyć tej samej listy pól do wyboru i wyszukiwania. W przeciwnym razie dopasowanie może być oparte na wartościach pól, których nie widać w wynikach, co powoduje niepewność co do tego, dlaczego dokument został zwrócony.
Parametry używane do kształtowania odpowiedzi:
selectokreśla, które pola mają być zwracane w odpowiedzi. W instrukcji select można używać tylko pól oznaczonych jako "możliwe do pobrania" w indeksie.topZwraca określoną liczbę najlepiej pasujących dokumentów. W tym przykładzie zwracanych jest tylko 10 trafień. Możesz użyć górnej i pominiętej (nie pokazanej) do stronicowania wyników.countinformuje o tylu dokumentach w całym indeksie, co może być więcej niż zwracane.orderbyjest używany, jeśli chcesz sortować wyniki według wartości, takiej jak ocena lub lokalizacja. W przeciwnym razie wartością domyślną jest użycie oceny istotności do klasyfikacji wyników. Pole musi być przypisywane jako "sortowalne", aby być kandydatem dla tego parametru.
Wybieranie klienta
W przypadku wczesnego programowania i testowania koncepcji zacznij od witryny Azure Portal lub klienta REST. Oba podejścia są interaktywne, przydatne do testowania docelowego i ułatwiają ocenę skutków różnych właściwości bez konieczności pisania kodu.
Aby wywołać wyszukiwanie z poziomu aplikacji, użyj bibliotek klienckich Azure.Document.Search w zestawach Azure SDK dla platformy .NET, Java, JavaScript i Python.
W portalu po otwarciu indeksu możesz pracować z Eksploratorem wyszukiwania wraz z definicją indeksu JSON na kartach obok siebie, aby ułatwić dostęp do atrybutów pól. Sprawdź tabelę Pola , aby zobaczyć, które z nich można wyszukiwać, sortować, filtrować i konfigurować aspekty podczas testowania zapytań.
Zaloguj się do witryny Azure Portal i znajdź usługę wyszukiwania.
Otwórz indeksy i wybierz indeks.
Indeks zostanie otwarty na karcie Eksplorator wyszukiwania, aby można było wykonać zapytanie od razu. Przejdź do widoku JSON, aby określić składnię zapytania.
Oto wyrażenie zapytania wyszukiwania pełnotekstowego, które działa dla przykładowego indeksu Hotels:
{ "search": "pool spa +airport", "queryType": "simple", "searchMode": "any", "searchFields": "Description, Tags", "select": "HotelName, Description, Tags", "top": 10, "count": true }Poniższy zrzut ekranu przedstawia zapytanie i odpowiedź:
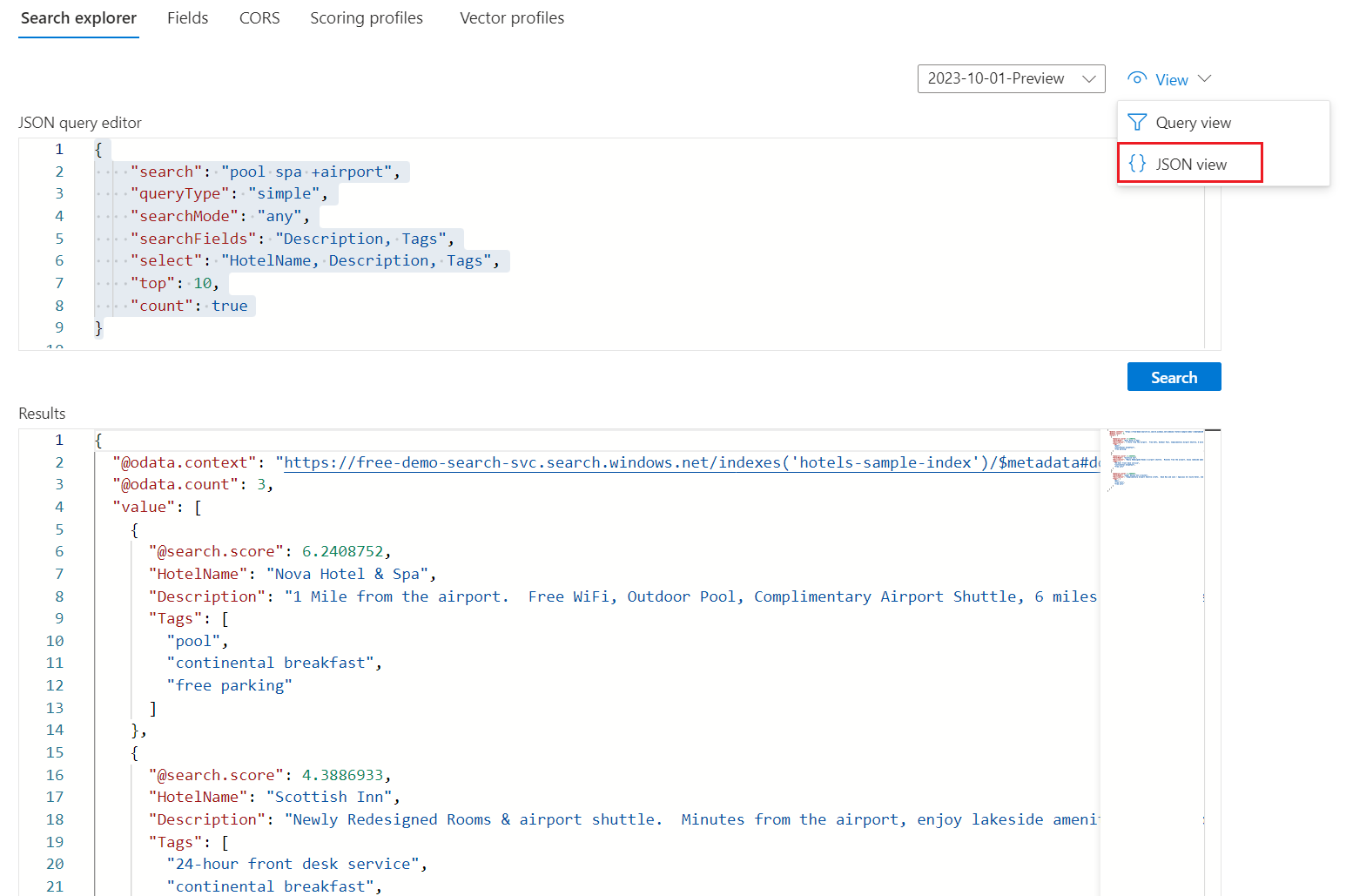
Wybierz typ zapytania: prosty | Pełne
Jeśli zapytanie jest wyszukiwaniem pełnotekstowym, analizator zapytań jest używany do przetwarzania dowolnego tekstu przekazanego jako terminy wyszukiwania i frazy. Usługa Azure AI Search oferuje dwa analizatory zapytań.
Prosty analizator rozumie prostą składnię zapytania. Ten analizator został wybrany jako domyślny dla jego szybkości i skuteczności w wolnych zapytaniach tekstowych formularza. Składnia obsługuje typowe operatory wyszukiwania (AND, OR, NOT) dla wyszukiwań terminów i fraz oraz wyszukiwanie prefiksu (
*jak w "sea*" dla Seattle i Seaside). Ogólną rekomendacją jest wypróbowanie najpierw prostego analizatora, a następnie przejście do pełnego analizatora, jeśli wymagania aplikacji wywołają bardziej zaawansowane zapytania.Pełna składnia zapytania Lucene włączona podczas dodawania
queryType=fulldo żądania jest oparta na analizatorze Apache Lucene.
Pełna składnia i prosta składnia nakładają się na zakres, który obsługuje ten sam prefiks i operacje logiczne, ale pełna składnia zapewnia więcej operatorów. W całości istnieje więcej operatorów dla wyrażeń logicznych i więcej operatorów dla zaawansowanych zapytań, takich jak wyszukiwanie rozmyte, wyszukiwanie wieloznaczne, wyszukiwanie w pobliżu i wyrażenia regularne.
Wybieranie metod zapytań
Wyszukiwanie to zasadniczo ćwiczenie oparte na użytkowniku, w którym terminy lub frazy są zbierane z pola wyszukiwania lub zdarzeń kliknięć na stronie. Poniższa tabela zawiera podsumowanie mechanizmów, za pomocą których można zbierać dane wejściowe użytkownika wraz z oczekiwanym środowiskiem wyszukiwania.
| Dane wejściowe | Środowisko |
|---|---|
| Metoda wyszukiwania | Użytkownik wpisze terminy lub frazy w polu wyszukiwania z operatorami lub bez operatorów, a następnie klika pozycję Wyszukaj, aby wysłać żądanie. Wyszukiwanie może być używane z filtrami w tym samym żądaniu, ale nie w przypadku autouzupełniania lub sugestii. |
| Autouzupełnianie, metoda | Użytkownik wpisze kilka znaków, a zapytania są inicjowane po wpisaniu każdego nowego znaku. Odpowiedź to ukończony ciąg z indeksu. Jeśli podany ciąg jest prawidłowy, użytkownik kliknie pozycję Wyszukaj, aby wysłać to zapytanie do usługi. |
| Metoda sugestii | Podobnie jak w przypadku autouzupełniania, użytkownik wpisze kilka znaków i generowane są zapytania przyrostowe. Odpowiedź to lista rozwijana pasujących dokumentów, zwykle reprezentowana przez kilka unikatowych lub opisowych pól. Jeśli którykolwiek z wybranych opcji jest prawidłowy, użytkownik kliknie jeden i zostanie zwrócony pasujący dokument. |
| Nawigacja aspektowa | Na stronie są wyświetlane klikalne linki nawigacyjne lub linki do stron nadrzędnych, które zawężają zakres wyszukiwania. Struktura nawigacji aspektowej składa się dynamicznie na podstawie początkowego zapytania. Aby na przykład search=* wypełnić drzewo nawigacji aspektowej składające się z każdej możliwej kategorii. Struktura nawigacji aspektowej jest tworzona na podstawie odpowiedzi zapytania, ale jest również mechanizmem wyrażania następnego zapytania. n Dokumentacja interfejsu API REST jest facets udokumentowana jako parametr zapytania operacji Search Documents, ale może być używana bez parametru search . |
| Metoda filter | Filtry są używane z aspektami w celu zawężenia wyników. Możesz również zaimplementować filtr za stroną, na przykład w celu zainicjowania strony przy użyciu pól specyficznych dla języka. W dokumentacji $filter interfejsu API REST jest udokumentowany jako parametr zapytania operacji Search Documents, ale może być używany bez parametru search . |
Wpływ atrybutów pól na zapytania
Jeśli znasz typy zapytań i kompozycję, możesz pamiętać, że parametry żądania zapytania zależą od atrybutów pól w indeksie. Na przykład tylko pola oznaczone jako searchable i retrievable mogą być używane w zapytaniach i wynikach wyszukiwania. Podczas ustawiania searchparametrów , filteri orderby w żądaniu należy sprawdzić atrybuty, aby uniknąć nieoczekiwanych wyników.
Na zrzucie ekranu portalu poniżej przykładowego indeksu hoteli tylko dwa ostatnie pola "LastRenovationDate" i "Rating" są sortablewymagane do użycia tylko w "$orderby" klauzuli .

Aby zapoznać się z definicjami atrybutów pól, zobacz Tworzenie indeksu (interfejs API REST).
Wpływ tokenów na zapytania
Podczas indeksowania aparat wyszukiwania używa analizatora tekstu w ciągach, aby zmaksymalizować potencjał znalezienia dopasowania w czasie zapytania. Co najmniej ciągi są małe litery, ale w zależności od analizatora mogą również przejść lemmatyzację i zatrzymać usuwanie wyrazów. Większe ciągi lub wyrazy złożone są zwykle podzielone przez białe znaki, łączniki lub łączniki i indeksowane jako oddzielne tokeny.
Chodzi o to, że to, co uważasz, że indeks zawiera i co jest w nim rzeczywiście, może być inny. Jeśli zapytania nie zwracają oczekiwanych wyników, możesz sprawdzić tokeny utworzone przez analizatora za pomocą interfejsu API REST (Analyze Text). Aby uzyskać więcej informacji na temat tokenizacji i wpływu na zapytania, zobacz Częściowe wyszukiwanie terminów i wzorce ze znakami specjalnymi.
Następne kroki
Teraz, gdy masz lepsze zrozumienie sposobu działania żądań zapytań, wypróbuj następujące przewodniki Szybki start, aby uzyskać praktyczne doświadczenie.