Samouczek: tworzenie analizatora niestandardowego dla numerów telefonów
W rozwiązaniach wyszukiwania ciągi, które mają złożone wzorce lub znaki specjalne, mogą być wyzwaniem do pracy, ponieważ domyślny analizator usuwa lub błędnie interpretuje istotne części wzorca, co powoduje słabe środowisko wyszukiwania, gdy użytkownicy nie mogą znaleźć oczekiwanych informacji. Telefon liczby to klasyczny przykład ciągów, które są trudne do przeanalizowania. Są one w różnych formatach i zawierają znaki specjalne ignorowane przez analizator domyślny.
W przypadku numerów telefonów jako tematu ten samouczek przyjrzy się bliżej problemom ze wzorzystymi danymi i pokazuje, jak rozwiązać ten problem przy użyciu analizatora niestandardowego. Podejście opisane tutaj może służyć jako numery telefonów lub dostosowane do pól o takich samych cechach (wzorzysku, ze znakami specjalnymi), takich jak adresy URL, wiadomości e-mail, kody pocztowe i daty.
W tym samouczku używasz klienta REST i interfejsów API REST usługi Azure AI Search do:
- Omówienie problemu
- Opracowywanie początkowego analizatora niestandardowego do obsługi numerów telefonów
- Testowanie analizatora niestandardowego
- Iterowanie projektu analizatora niestandardowego w celu dalszego ulepszania wyników
Wymagania wstępne
Na potrzeby tego samouczka wymagane są następujące usługi i narzędzia.
Program Visual Studio Code z klientem REST.
Azure AI Search. Utwórz lub znajdź istniejący zasób usługi Azure AI Search w ramach bieżącej subskrypcji. W tym przewodniku Szybki start możesz skorzystać z bezpłatnej usługi.
Pobieranie plików
Kod źródłowy tego samouczka to plik custom-analyzer.rest w repozytorium GitHub Azure-Samples/azure-search-rest-samples .
Kopiowanie klucza i adresu URL
Wywołania REST w tym samouczku wymagają punktu końcowego usługi wyszukiwania i klucza interfejsu API administratora. Te wartości można uzyskać w witrynie Azure Portal.
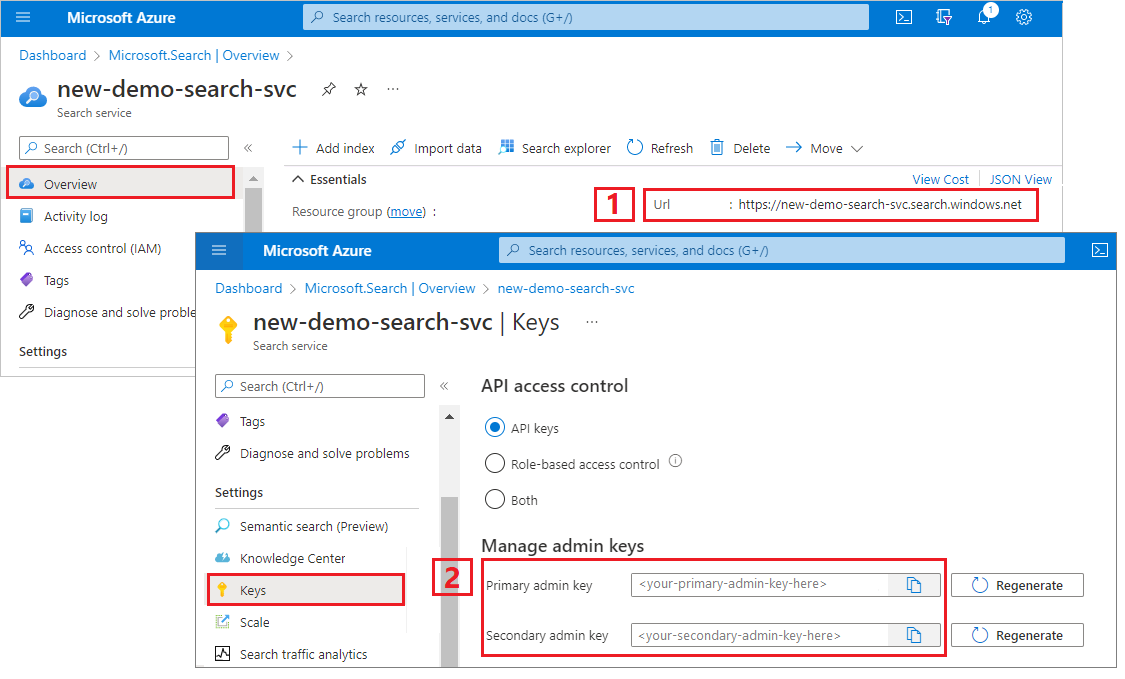
Zaloguj się do witryny Azure Portal, przejdź do strony Przegląd i skopiuj adres URL. Przykładowy punkt końcowy może wyglądać podobnie jak
https://mydemo.search.windows.net.W obszarze Ustawienia> Keys skopiuj klucz administratora. Administracja klucze służą do dodawania, modyfikowania i usuwania obiektów. Istnieją dwa zamienne klucze administratora. Skopiuj jedną z nich.
Prawidłowy klucz interfejsu API ustanawia relację zaufania dla poszczególnych żądań między aplikacją wysyłającą żądanie a usługą wyszukiwania, która go obsługuje.
Tworzenie indeksu początkowego
Otwórz nowy plik tekstowy w programie Visual Studio Code.
Ustaw zmienne na punkt końcowy wyszukiwania i klucz interfejsu API zebrany w poprzednim kroku.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HEREZapisz plik z
.restrozszerzeniem pliku.Wklej poniższy przykład, aby utworzyć mały indeks o nazwie
phone-numbers-indexz dwoma polami:idiphone_number. Nie zdefiniowaliśmy jeszcze analizatora, więcstandard.luceneanalizator jest używany domyślnie.### Create a new index POST {{baseUrl}}/indexes?api-version=2023-11-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }Wybierz pozycję Wyślij wniosek. Powinna zostać wyświetlona
HTTP/1.1 201 Createdodpowiedź, a treść odpowiedzi powinna zawierać reprezentację JSON schematu indeksu.Załaduj dane do indeksu przy użyciu dokumentów zawierających różne formaty numerów telefonów. Są to dane testowe.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2023-11-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }Spróbujmy wykonać kilka zapytań podobnych do tego, co użytkownik może wpisać. Użytkownik może wyszukać
(425) 555-0100dowolną liczbę formatów i nadal spodziewać się zwrócenia wyników. Rozpocznij od wyszukania(425) 555-0100:### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2023-11-01&search=(425) 555-0100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}Zapytanie zwraca trzy z czterech oczekiwanych wyników, ale zwraca również dwa nieoczekiwane wyniki:
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }Spróbujmy ponownie bez żadnego formatowania:
4255550100.### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2023-11-01&search=4255550100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}To zapytanie działa jeszcze gorzej, zwracając tylko jedno z czterech poprawnych dopasowań.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
Jeśli znajdziesz te wyniki mylące, nie jesteś sam. W następnej sekcji przyjrzyjmy się, dlaczego uzyskujemy te wyniki.
Zapoznaj się ze sposobem działania analizatorów
Aby zrozumieć te wyniki wyszukiwania, musimy zrozumieć, co robi analizator. Z tego miejsca możemy przetestować domyślny analizator przy użyciu interfejsu API analizowania, zapewniając podstawy do projektowania analizatora, który lepiej spełnia nasze potrzeby.
Analizator jest składnikiem wyszukiwarki pełnotekstowej odpowiedzialnej za przetwarzanie tekstu w ciągach zapytania i indeksowanych dokumentach. Różne analizatory manipulują tekstem na różne sposoby w zależności od scenariusza. W tym scenariuszu musimy utworzyć analizator dostosowany do numerów telefonów.
Analizatory składają się z trzech składników:
- Filtry znaków, które usuwają lub zamieniają poszczególne znaki z tekstu wejściowego.
- Tokenizator, który dzieli tekst wejściowy na tokeny, które stają się kluczami w indeksie wyszukiwania.
- Filtry tokenów , które manipulują tokenami utworzonymi przez tokenizatora.
Na poniższym diagramie widać, jak te trzy składniki współpracują ze sobą w celu tokenizowania zdania:

Te tokeny są następnie przechowywane w odwróconym indeksie, co umożliwia szybkie wyszukiwanie pełnotekstowe. Odwrócony indeks umożliwia wyszukiwanie pełnotekstowe przez mapowanie wszystkich unikatowych terminów wyodrębnionych podczas analizy leksykalnej do dokumentów, w których występują. Przykład można zobaczyć na następnym diagramie:

Wyszukiwanie sprowadza się do wyszukiwania terminów przechowywanych w odwróconym indeksie. Gdy użytkownik wystawia zapytanie:
- Zapytanie jest analizowane, a terminy zapytania są analizowane.
- Indeks odwrócony jest następnie skanowany pod kątem dokumentów z zgodnymi terminami.
- Na koniec pobrane dokumenty są klasyfikowane przez algorytm oceniania.

Jeśli terminy zapytania nie są zgodne z terminami w odwróconym indeksie, wyniki nie są zwracane. Aby dowiedzieć się więcej o sposobie działania zapytań, zobacz ten artykuł dotyczący wyszukiwania pełnotekstowego.
Uwaga
Zapytania częściowe terminów są ważnym wyjątkiem od tej reguły. Te zapytania (zapytanie prefiksu, zapytanie wieloznaczne, zapytanie regularne) pomijają proces analizy leksykalnej w przeciwieństwie do zapytań terminów regularnych. Terminy częściowe są tylko małymi literami przed dopasowaniem względem terminów w indeksie. Jeśli analizator nie jest skonfigurowany do obsługi tego typu zapytań, często otrzymujesz nieoczekiwane wyniki, ponieważ pasujące terminy nie istnieją w indeksie.
Analizatory testów przy użyciu interfejsu API analizy
Usługa Azure AI Search udostępnia interfejs API analizowania, który umożliwia testowanie analizatorów w celu zrozumienia sposobu przetwarzania tekstu.
Interfejs API analizy jest wywoływany przy użyciu następującego żądania:
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
Interfejs API zwraca tokeny wyodrębnione z tekstu przy użyciu określonego analizatora. Standardowy analizator Lucene dzieli numer telefonu na trzy oddzielne tokeny:
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
Z drugiej strony numer 4255550100 telefonu sformatowany bez żadnej interpunkcji jest tokenizowany na jeden token.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
Reakcja:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
Należy pamiętać, że zarówno terminy zapytania, jak i indeksowane dokumenty są analizowane. Myśląc o wynikach wyszukiwania z poprzedniego kroku, możemy zacząć widzieć, dlaczego te wyniki zostały zwrócone.
W pierwszym zapytaniu zwracano nieoczekiwane numery telefonów, ponieważ jeden z ich tokenów był zgodny z jednym z wyszukiwanych terminów 555. W drugim zapytaniu zwrócono tylko jedną liczbę, ponieważ był to jedyny rekord, który miał token pasujący 4255550100do elementu .
Tworzenie analizatora niestandardowego
Teraz, gdy rozumiemy wyniki, które widzimy, utwórzmy analizator niestandardowy, aby ulepszyć logikę tokenizacji.
Celem jest zapewnienie intuicyjnego wyszukiwania numerów telefonów niezależnie od formatu zapytania lub indeksowanego ciągu. Aby osiągnąć ten wynik, określimy filtr znaków, tokenizator i filtr tokenu.
Filtry znaków
Filtry znaków są używane do przetwarzania tekstu przed ich wprowadzeniem do tokenizatora. Typowe zastosowania filtrów znaków obejmują filtrowanie elementów HTML lub zastępowanie znaków specjalnych.
W przypadku numerów telefonów chcemy usunąć białe znaki i znaki specjalne, ponieważ nie wszystkie formaty numerów telefonów zawierają te same znaki specjalne i spacje.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
Filtr usuwa spacje -+(). i z danych wejściowych.
| Dane wejściowe | Dane wyjściowe |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Tokenizatory
Tokenizatory dzielą tekst na tokeny i odrzucają niektóre znaki, takie jak interpunkcja, po drodze. W wielu przypadkach celem tokenizacji jest podzielenie zdania na poszczególne wyrazy.
W tym scenariuszu użyjemy tokenizatora słowa kluczowego , keyword_v2ponieważ chcemy przechwycić numer telefonu jako pojedynczy termin. Należy pamiętać, że nie jest to jedyny sposób rozwiązania tego problemu. Zobacz sekcję Alternatywne podejścia poniżej.
Tokenizatory słów kluczowych zawsze wyświetlają ten sam tekst, który został podany jako pojedynczy termin.
| Dane wejściowe | Dane wyjściowe |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
Filtry tokenów
Filtry tokenów będą filtrować lub modyfikować tokeny wygenerowane przez tokenizatora. Jednym z typowych zastosowań filtru tokenu jest małe litery wszystkich znaków przy użyciu filtru tokenu małe litery. Innym typowym zastosowaniem jest filtrowanie stopwords , takich jak the, andlub is.
Chociaż nie musimy używać jednego z tych filtrów w tym scenariuszu, użyjemy filtru tokenu nGram, aby umożliwić częściowe wyszukiwanie numerów telefonów.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
Filtr tokenu nGram_v2 dzieli tokeny na n-gramy danego rozmiaru minGram na podstawie parametrów i maxGram .
W przypadku analizatora telefonów ustawiliśmy wartość minGram na 3 , ponieważ jest to najkrótszy podciąg, którego oczekujemy od użytkowników wyszukiwania. maxGram ma mieć pewność 20 , że wszystkie numery telefonów, nawet z rozszerzeniami, będą pasowały do jednego n-grama.
Niefortunny efekt uboczny n-gramów jest to, że niektóre fałszywie dodatnie zostaną zwrócone. Naprawimy to w późniejszym kroku, tworząc oddzielny analizator wyszukiwania, który nie zawiera filtru tokenu n-gram.
| Dane wejściowe | Dane wyjściowe |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Analizator
Dzięki filtrom znaków, tokenizatorowi i filtrom tokenów możemy zdefiniować nasz analizator.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
W interfejsie API analizy, biorąc pod uwagę następujące dane wejściowe, dane wyjściowe z analizatora niestandardowego są wyświetlane w poniższej tabeli.
| Dane wejściowe | Dane wyjściowe |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Wszystkie tokeny w kolumnie wyjściowej istnieją w indeksie. Jeśli nasze zapytanie zawiera dowolne z tych terminów, zwracany jest numer telefonu.
Ponowne kompilowanie przy użyciu nowego analizatora
Usuń bieżący indeks:
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2023-11-01 HTTP/1.1 api-key: {{apiKey}}Utwórz ponownie indeks przy użyciu nowego analizatora. Ten schemat indeksu dodaje definicję analizatora niestandardowego i przypisanie analizatora niestandardowego w polu numer telefonu.
### Create a new index POST {{baseUrl}}/indexes?api-version=2023-11-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
Testowanie analizatora niestandardowego
Po ponownym utworzeniu indeksu możesz teraz przetestować analizator przy użyciu następującego żądania:
POST {{baseUrl}}/indexes/tutorial-first-analyzer/analyze?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
Teraz powinna zostać wyświetlona kolekcja tokenów wynikających z numeru telefonu:
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
Poprawianie analizatora niestandardowego w celu obsługi wyników fałszywie dodatnich
Po wykonaniu przykładowych zapytań względem indeksu za pomocą analizatora niestandardowego okaże się, że kompletność została ulepszona, a wszystkie pasujące numery telefonów są teraz zwracane. Jednak filtr tokenu n-gram powoduje również zwrócenie niektórych wyników fałszywie dodatnich. Jest to typowy efekt uboczny filtru tokenu n-gram.
Aby zapobiec fałszywie dodatnim, utworzymy oddzielny analizator do wykonywania zapytań. Ten analizator jest identyczny z poprzednim, z tą różnicą, że pomija element custom_ngram_filter.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
W definicji indeksu określamy wartości i indexAnalyzersearchAnalyzer.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
Dzięki tej zmianie wszystko jest ustawione. Oto następne kroki do wykonania:
Usuń indeks.
Utwórz ponownie indeks po dodaniu nowego analizatora niestandardowego (
phone_analyzer-search) i przypisaniu tego analizatorasearchAnalyzerdophone-numberwłaściwości pola.Załaduj ponownie dane.
Ponownie przetestuj zapytania, aby sprawdzić, czy wyszukiwanie działa zgodnie z oczekiwaniami. Jeśli używasz przykładowego pliku, ten krok tworzy trzeci indeks o nazwie
phone-number-index-3.
Alternatywne podejścia
Analizator opisany w poprzedniej sekcji został zaprojektowany w celu zmaksymalizowania elastyczności wyszukiwania. Jednak to robi po kosztach przechowywania wielu potencjalnie nieważnych terminów w indeksie.
W poniższym przykładzie przedstawiono alternatywny analizator, który jest bardziej wydajny w tokenizacji, ale ma wady.
Biorąc pod uwagę dane wejściowe 14255550100, analizator nie może logicznie fragmentować numeru telefonu. Na przykład nie może oddzielić kodu kraju , 1od kodu 425obszaru , . Ta rozbieżność doprowadziłaby do braku zwracanego numeru telefonu, jeśli użytkownik nie uwzględnił kodu kraju w wyszukiwaniu.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
W poniższym przykładzie widać, że numer telefonu jest podzielony na fragmenty, których zwykle oczekujesz, że użytkownik będzie wyszukiwał.
| Dane wejściowe | Dane wyjściowe |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
W zależności od wymagań może to być bardziej wydajne podejście do problemu.
Wnioski
W tym samouczku przedstawiono proces tworzenia i testowania analizatora niestandardowego. Utworzono indeks, indeksowane dane, a następnie wykonano zapytanie względem indeksu, aby zobaczyć, jakie wyniki wyszukiwania zostały zwrócone. W tym miejscu użyto interfejsu API analizy, aby zobaczyć proces analizy leksykalnej w działaniu.
Chociaż analizator zdefiniowany w tym samouczku oferuje łatwe rozwiązanie do wyszukiwania numerów telefonów, ten sam proces może służyć do tworzenia analizatora niestandardowego dla dowolnego scenariusza, który ma podobne cechy.
Czyszczenie zasobów
Gdy pracujesz we własnej subskrypcji, dobrym pomysłem jest usunięcie zasobów, które nie są już potrzebne na końcu projektu. Uruchomione zasoby mogą generować koszty. Zasoby możesz usuwać pojedynczo lub jako grupę zasobów, usuwając cały zestaw zasobów.
Zasoby można znaleźć w portalu i zarządzać nimi, korzystając z linku Wszystkie zasoby lub Grupy zasobów w okienku nawigacji po lewej stronie.
Następne kroki
Teraz, gdy znasz sposób tworzenia analizatora niestandardowego, przyjrzyjmy się wszystkim różnym filtrom, tokenizatorom i analizatorom, które można utworzyć w celu utworzenia rozbudowanego środowiska wyszukiwania.