Tworzenie zapytania wektorowego w usłudze Azure AI Search
Jeśli w usłudze Azure AI Search masz pola wektorowe w indeksie wyszukiwania, w tym artykule wyjaśniono, jak:
W tym artykule użyto architektury REST na potrzeby ilustracji. Przykłady kodu w innych językach można znaleźć w repozytorium GitHub azure-search-vector-samples , które zawiera kompleksowe rozwiązania obejmujące zapytania wektorowe.
Wymagania wstępne
Usługa Azure AI Search w dowolnym regionie i w dowolnej warstwie.
Program Visual Studio Code z klientem REST i przykładowymi danymi, jeśli chcesz uruchomić te przykłady samodzielnie. Zobacz Szybki start: azure AI Search using REST (Przewodnik Szybki start: wyszukiwanie sztucznej inteligencji platformy Azure przy użyciu interfejsu REST ), aby uzyskać pomoc dotyczącą rozpoczynania pracy.
Napiwek
Aby szybko określić, czy indeks ma wektory, poszukaj pól typu Collection(Edm.Single), z atrybutem dimensions i przypisaniem vectorSearchProfile .
Konwertowanie danych wejściowych ciągu zapytania na wektor
Aby wysłać zapytanie do pola wektora, samo zapytanie musi być wektorem. Jedną z metod konwertowania ciągu zapytania tekstowego użytkownika na jego reprezentację wektorową jest wywołanie biblioteki osadzania lub interfejsu API w kodzie aplikacji. Najlepszym rozwiązaniem jest użycie tych samych modeli osadzania używanych do generowania osadzania w dokumentach źródłowych.
Przykłady kodu przedstawiające sposób generowania osadzania można znaleźć w repozytorium azure-search-vector-samples .
Oto przykładowy ciąg zapytania przesłany do wdrożenia modelu osadzania usługi Azure OpenAI za pomocą interfejsu API REST:
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
Oczekiwana odpowiedź to 202 w przypadku pomyślnego wywołania wdrożonego modelu. Pole "osadzanie" w treści odpowiedzi jest wektorową reprezentacją ciągu zapytania "input". W celach testowych należy skopiować wartość tablicy "osadzanie" do "vectorQueries.vector" w żądaniu zapytania przy użyciu składni pokazanej w kilku następnych sekcjach.
Rzeczywista odpowiedź dla tego wywołania POST do wdrożonego modelu obejmuje 1536 osadzania, przycięte tutaj tylko do kilku pierwszych wektorów w celu zapewnienia czytelności.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
W tym podejściu kod aplikacji jest odpowiedzialny za nawiązywanie połączenia z modelem, generowanie osadzonych i obsługę odpowiedzi.
Napiwek
Wypróbuj zapytanie ze zintegrowaną wektoryzacją, obecnie w publicznej wersji zapoznawczej, aby usługa Azure AI Search obsługiwała dane wejściowe i wyjściowe wektoryzacji zapytań.
Żądanie zapytania wektorowego
W tej sekcji przedstawiono podstawową strukturę zapytania wektorowego. Aby sformułować zapytanie wektorowe, możesz użyć witryny Azure Portal, interfejsów API REST lub zestawów SDK platformy Azure. W przypadku migracji z wersji 2023-07-01-Preview istnieją zmiany powodujące niezgodność. Aby uzyskać szczegółowe informacje, zobacz Uaktualnianie do najnowszego interfejsu API REST.
2023-11-01 to stabilna wersja interfejsu API REST dla wyszukiwania POST. Ta wersja obsługuje następujące wersję:
vectorQueriesto konstrukcja wyszukiwania wektorowego.kindustaw wartość , abyvectorokreślić, że zapytanie jest tablicą wektorów.vectorto zapytanie (wektorowa reprezentacja tekstu lub obrazu).exhaustive(opcjonalnie) wywołuje wyczerpującą nazwę KNN w czasie zapytania, nawet jeśli pole jest indeksowane dla HNSW.
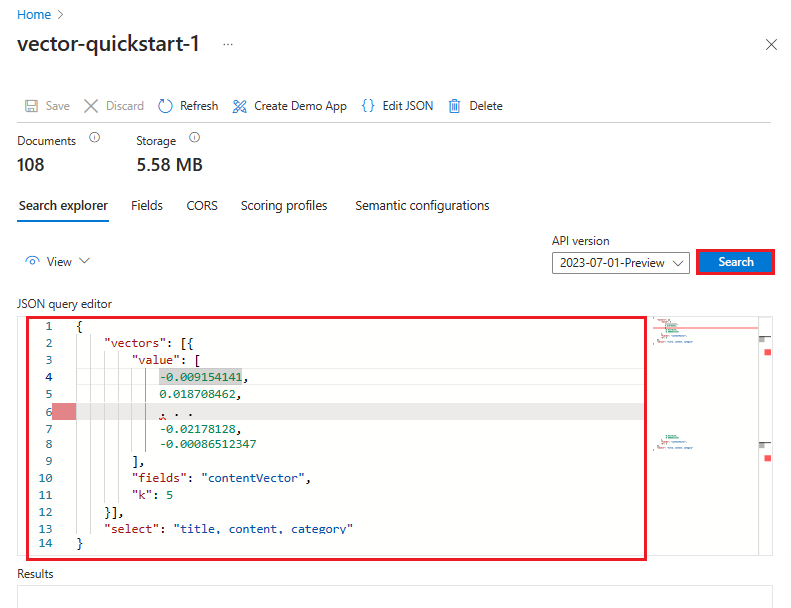
W poniższym przykładzie wektor jest reprezentacją tego ciągu: "to, co usługi platformy Azure obsługują wyszukiwanie pełnotekstowe". Zapytanie jest przeznaczone dla contentVector pola . Zapytanie zwraca k wyniki. Rzeczywisty wektor ma 1536 osadzonych elementów, więc jest przycinany w tym przykładzie pod kątem czytelności.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"k": 5
}
]
}
Odpowiedź zapytania wektorowego
W usłudze Azure AI Search odpowiedzi zapytań składają się z wszystkich retrievable pól domyślnie. Jednak często można ograniczyć wyniki wyszukiwania do podzestawu retrievable pól, wyświetlając je w instrukcji select .
W zapytaniu wektorowym należy dokładnie rozważyć, czy należy wektorować pola w odpowiedzi. Pola wektorowe nie są czytelne dla człowieka, więc jeśli wypychasz odpowiedź na stronę internetową, wybierz pola niewektorowe, które są reprezentatywne dla wyniku. Jeśli na przykład zapytanie jest wykonywane względem contentVectorelementu , możesz zamiast tego zwrócić content wartość .
Jeśli chcesz, aby pola wektorów w wynikach, oto przykład struktury odpowiedzi. contentVector to tablica ciągów osadzania, przycinana tutaj w celu zwięzłości. Wynik wyszukiwania wskazuje istotność. Inne pola niewektorowe są uwzględniane w kontekście.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
Kluczowe punkty:
kokreśla liczbę zwracanych wyników najbliższego sąsiada, w tym przypadku trzy. Zapytania wektorowe zawsze zwracająkwyniki, zakładając, że istnieją co najmniejkdokumenty, nawet jeśli istnieją dokumenty o niskiej podobieństwie, ponieważ algorytm znajduje najbliższychksąsiadów do wektora zapytania.Element
@search.scorejest określany przez algorytm wyszukiwania wektorowego.Pola w wynikach wyszukiwania to wszystkie
retrievablepola lub pola w klauzuliselect. Podczas wykonywania zapytania wektorowego dopasowanie jest wykonywane tylko na danych wektorowych. Jednak odpowiedź może zawierać dowolneretrievablepole w indeksie. Ponieważ nie ma możliwości dekodowania wyniku pola wektorowego, włączenie pól tekstowych niewektorów jest przydatne dla ich ludzkich wartości czytelnych.
Zapytanie wektorowe z filtrem
Żądanie zapytania może zawierać zapytanie wektorowe i wyrażenie filtru. Filtry mają zastosowanie do filterable pól tekstowych i liczbowych oraz są przydatne do dołączania lub wykluczania dokumentów wyszukiwania na podstawie kryteriów filtrowania. Chociaż pole wektorowe nie jest możliwe do filtrowania, zapytanie może określać filtry w innych polach w tym samym indeksie.
W nowszych wersjach interfejsu API można ustawić tryb filtrowania, aby zastosować filtry przed wykonaniem zapytania wektorowego lub po nim. Aby uzyskać porównanie poszczególnych trybów i oczekiwanej wydajności na podstawie rozmiaru indeksu, zobacz Filtry w zapytaniach wektorowych.
Napiwek
Jeśli nie masz pól źródłowych z wartościami tekstowymi lub liczbowymi, sprawdź metadane dokumentu, takie jak Właściwości LastModified lub CreatedBy, które mogą być przydatne w filtrze metadanych.
2023-11-01 jest stabilną wersją tego interfejsu API. Ma:
vectorFilterModedla trybów filtrowania wstępnego (domyślne) lub postfiltrowania.filterzawiera kryteria.
W poniższym przykładzie wektor jest reprezentacją tego ciągu zapytania: "to, co usługi platformy Azure obsługują wyszukiwanie pełnotekstowe". Zapytanie jest przeznaczone dla contentVector pola . Rzeczywisty wektor ma 1536 osadzonych elementów, więc jest przycinany w tym przykładzie pod kątem czytelności.
Kryteria filtrowania są stosowane do pola tekstowego z możliwością filtrowania (category w tym przykładzie), zanim aparat wyszukiwania wykona zapytanie wektorowe.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"filter": "category eq 'Databases'",
"vectorFilterMode": "preFilter",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"k": 5
}
]
}
Wiele pól wektorów
Właściwość "vectorQueries.fields" można ustawić na wiele pól wektorowych. Zapytanie wektorowe jest wykonywane względem każdego pola wektora podanego na fields liście. Podczas wykonywania zapytań dotyczących wielu pól wektorowych upewnij się, że każdy z nich zawiera osadzanie z tego samego modelu osadzania i że zapytanie jest również generowane na podstawie tego samego modelu osadzania.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
Wiele zapytań wektorowych
Wyszukiwanie wektorów wielozasyłowych wysyła wiele zapytań w wielu polach wektorów w indeksie wyszukiwania. Typowym przykładem tego żądania zapytania jest użycie modeli, takich jak CLIP dla wyszukiwania wektorów wielomodalnych, w którym ten sam model może wektoryzować zawartość obrazu i tekstu.
Poniższy przykład zapytania szuka podobieństwa w obu myImageVector i myTextVector, ale wysyła odpowiednio w dwóch różnych osadzaniu zapytań, z których każda wykonuje równolegle. To zapytanie generuje wynik, który jest oceniany przy użyciu wzajemnego łączenia rangi (RRF) .
vectorQueriesudostępnia tablicę zapytań wektorowych.vectorzawiera wektory obrazów i wektory tekstowe w indeksie wyszukiwania. Każde wystąpienie jest oddzielnym zapytaniem.fieldsokreśla, które pole wektora ma być docelowe.kto liczba dopasowań najbliższych sąsiadów do uwzględnienia w wynikach.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
Wyniki wyszukiwania obejmują kombinację tekstu i obrazów, zakładając, że indeks wyszukiwania zawiera pole dla pliku obrazu (indeks wyszukiwania nie przechowuje obrazów).
Wykonywanie zapytań ze zintegrowaną wektoryzacją (wersja zapoznawcza)
W tej sekcji przedstawiono zapytanie wektorowe, które wywołuje nową funkcję wektoryzacji zintegrowanej w wersji zapoznawczej, która konwertuje zapytanie tekstowe na wektor. Użyj interfejsu API REST 2023-10-01-Preview lub zaktualizowanego pakietu zestawu Azure SDK w wersji beta.
Warunkiem wstępnym jest indeks wyszukiwania ze skonfigurowanym wektoryzatorem i przypisanym do pola wektora. Wektoryzator udostępnia informacje o połączeniu z modelem osadzania używanym w czasie wykonywania zapytania.
Zapytania udostępniają ciągi tekstowe zamiast wektorów:
kindmusi być ustawiona natext.textmusi mieć ciąg tekstowy. Jest on przekazywany do wektoryzatora przypisanego do pola wektorowego.fieldsto pole wektora do wyszukania.
Oto prosty przykład zapytania, który jest wektoryzowany w czasie zapytania. Ciąg tekstowy jest wektoryzowany, a następnie używany do wykonywania zapytań względem pola descriptionVector.
POST https://{{search-service}}.search.windows.net/indexes/{{index}}/docs/search?api-version=2023-10-01-preview
{
"select": "title, genre, description",
"vectorQueries": [
{
"kind": "text",
"text": "mystery novel set in London",
"fields": "descriptionVector",
"k": 5
}
]
}
Oto zapytanie hybrydowe używające zintegrowanej wektoryzacji zapytań tekstowych. To zapytanie zawiera wiele pól wektorów zapytania, wiele pól niewektorów, filtr i klasyfikację semantyczną. Ponownie różnice to kind zapytanie wektorowe i text ciąg zamiast vector.
W tym przykładzie aparat wyszukiwania wykonuje trzy wywołania wektoryzacji do wektoryzatorów przypisanych do descriptionVector, synopsisVectori authorBioVector w indeksie. Wektory wynikowe są używane do pobierania dokumentów względem odpowiednich pól. Wyszukiwarka wykonuje również wyszukiwanie słów kluczowych w search zapytaniu "tajemnicza powieść osadzona w Londynie".
POST https://{{search-service}}.search.windows.net/indexes/{{index}}/docs/search?api-version=2023-10-01-preview
Content-Type: application/json
api-key: {{admin-api-key}}
{
"search":"mystery novel set in London",
"searchFields":"description, synopsis",
"semanticConfiguration":"my-semantic-config",
"queryType":"semantic",
"select": "title, author, synopsis",
"filter": "genre eq 'mystery'",
"vectorFilterMode": "postFilter",
"vectorQueries": [
{
"kind": "text",
"text": "mystery novel set in London",
"fields": "descriptionVector, synopsisVector",
"k": 5
},
{
"kind": "text"
"text": "living english author",
"fields": "authorBioVector",
"k": 5
}
]
}
Wyniki z wszystkich czterech zapytań są połączone przy użyciu klasyfikacji RRF. Dodatkowa klasyfikacja semantyczna jest wywoływana na połączonych wynikach wyszukiwania, ale tylko searchFields w celu zwiększenia wyników, które są najbardziej semantycznie wyrównane do "search":"mystery novel set in London".
Uwaga
Wektoryzatory są używane podczas indeksowania i wykonywania zapytań. Jeśli nie potrzebujesz fragmentowania i wektoryzacji danych w indeksie, możesz pominąć kroki, takie jak tworzenie indeksatora, zestawu umiejętności i źródła danych. W tym scenariuszu wektoryzator jest używany tylko w czasie zapytania, aby przekonwertować ciąg tekstowy na osadzanie.
Ilość sklasyfikowanych wyników w odpowiedzi na zapytanie wektorowe
Zapytanie wektorowe k określa parametr, który określa liczbę dopasowań zwracanych w wynikach. Aparat wyszukiwania zawsze zwraca k liczbę dopasowań. Jeśli k liczba dokumentów w indeksie jest większa niż liczba dokumentów, liczba dokumentów określa górny limit zwracanych dokumentów.
Jeśli znasz wyszukiwanie pełnotekstowe, wiesz, że oczekujesz zerowych wyników, jeśli indeks nie zawiera terminu ani frazy. Jednak w wyszukiwaniu wektorowym operacja wyszukiwania identyfikuje najbliższych sąsiadów i zawsze zwraca k wyniki, nawet jeśli najbliżsi sąsiedzi nie są podobne. Dlatego można uzyskać wyniki dla niesensownych lub poza tematem zapytań, zwłaszcza jeśli nie używasz monitów do ustawiania granic. Mniej istotne wyniki mają gorszy wynik podobieństwa, ale nadal są to "najbliższe" wektory, jeśli nie ma nic bliżej. W związku z tym odpowiedź bez znaczących wyników może nadal zwracać k wyniki, ale wynik podobieństwa każdego wyniku będzie niski.
Hybrydowe podejście obejmujące wyszukiwanie pełnotekstowe może wyeliminować ten problem. Innym ograniczeniem ryzyka jest ustawienie minimalnego progu dla wyniku wyszukiwania, ale tylko wtedy, gdy zapytanie jest czystym pojedynczym zapytaniem wektorowym. Zapytania hybrydowe nie sprzyja minimalnym progom, ponieważ zakresy RRF są o wiele mniejsze i nietrwałe.
Parametry zapytania wpływające na liczbę wyników obejmują:
"k": nwyniki dla zapytań tylko wektorów"top": nwyniki zapytań hybrydowych zawierających parametr "search"
Oba "k" i "top" są opcjonalne. Nieokreślona domyślna liczba wyników w odpowiedzi to 50. Możesz ustawić wartość "top" i "skip" na stronę za pomocą większej liczby wyników lub zmienić wartość domyślną.
Algorytmy klasyfikowania używane w zapytaniu wektorowym
Klasyfikacja wyników jest obliczana przez:
- Metryka podobieństwa
- Wzajemne łączenie rangi (RRF), jeśli istnieje wiele zestawów wyników wyszukiwania.
Metryka podobieństwa
Metryka podobieństwa określona w sekcji indeksu vectorSearch dla zapytania tylko wektorów. Prawidłowe wartości to cosine, euclidean i dotProduct.
Modele osadzania usługi Azure OpenAI używają podobieństwa cosinus, więc jeśli używasz modeli osadzania w usłudze Azure OpenAI, cosine to zalecana metryka. Inne obsługiwane metryki klasyfikacji to euclidean i dotProduct.
Korzystanie z protokołu RRF
Tworzone są wiele zestawów, jeśli zapytanie jest przeznaczone dla wielu pól wektorów, uruchamia równolegle wiele zapytań wektorowych lub jeśli zapytanie jest hybrydą wyszukiwania wektorowego i pełnotekstowego, z lub bez semantycznego klasyfikacji.
Podczas wykonywania zapytania zapytanie wektorowe może dotyczyć tylko jednego indeksu wektora wewnętrznego. Dlatego w przypadku wielu pól wektorowych i wielu zapytań wektorowych aparat wyszukiwania generuje wiele zapytań, które są przeznaczone dla odpowiednich indeksów wektorów każdego pola. Dane wyjściowe to zestaw sklasyfikowanych wyników dla każdego zapytania, które są połączone przy użyciu protokołu RRF. Aby uzyskać więcej informacji, zobacz Ocenianie istotności przy użyciu wzajemnego łączenia rangi (RRF).
Następne kroki
W następnym kroku przejrzyj przykłady kodu zapytania wektorowego w języku Python, C# lub JavaScript.