Chcesz więc dowiedzieć się więcej o usłudze Service Fabric?
Usługa Azure Service Fabric to platforma systemów rozproszonych ułatwiająca pakowanie i wdrażanie skalowalnych i niezawodnych mikrousług oraz zarządzanie nimi. Usługa Service Fabric ma jednak duży obszar powierzchni i jest wiele do nauki. Ten artykuł zawiera opis podstawowych pojęć, modeli programowania, cyklu życia aplikacji, testowania, klastrów i monitorowania kondycji. Przeczytaj artykuł Omówienie i Co to są mikrousługi? aby zapoznać się z wprowadzeniem i sposobem użycia usługi Service Fabric do tworzenia mikrousług. Ten artykuł nie zawiera kompleksowej listy zawartości, ale zawiera linki do artykułów z omówieniem i wprowadzeniem dla każdego obszaru usługi Service Fabric.
Podstawowe pojęcia
Terminologia usługi Service Fabric, model aplikacji i Obsługiwane modele programowania zawierają więcej pojęć i opisów, ale oto podstawy.
- Klaster usługi Service Fabric:Sprawdź ten link, aby zapoznać się z filmem wideo szkoleniowym, aby zapoznać się z wprowadzeniem do architektury usługi Service Fabric i jej podstawowych pojęć oraz zapoznać się z wieloma funkcjami usługi Service Fabric.
- Pojęcia dotyczące środowiska uruchomieniowego:sprawdź ten link, aby zapoznać się z filmem wideo szkoleniowym, aby poznać pojęcia dotyczące środowiska uruchomieniowego i najlepsze rozwiązania dotyczące usługi Service Fabric.
- Pojęcia dotyczące typu projektu:sprawdź ten link, aby zapoznać się z filmem wideo szkoleniowym, aby zrozumieć aplikacje, pakowanie i wdrażanie; kluczową terminologię, abstrakcję i pojęcia dotyczące usługi Service Fabric.
Czas projektowania: typ usługi, pakiet usługi i manifest, typ aplikacji, pakiet aplikacji i manifest
Typ usługi to nazwa/wersja przypisana do pakietów kodu usługi, pakietów danych i pakietów konfiguracji. Jest to zdefiniowane w pliku ServiceManifest.xml. Typ usługi składa się z ustawień konfiguracji kodu wykonywalnego i usługi, które są ładowane w czasie wykonywania i danych statycznych używanych przez usługę.
Pakiet usługi to katalog dysku zawierający plik ServiceManifest.xml typu usługi, który odwołuje się do kodu, danych statycznych i pakietów konfiguracji dla typu usługi. Na przykład pakiet usługi może odwoływać się do kodu, danych statycznych i pakietów konfiguracji tworzących usługę bazy danych.
Typ aplikacji to nazwa/wersja przypisana do kolekcji typów usług. Jest to zdefiniowane w pliku ApplicationManifest.xml.
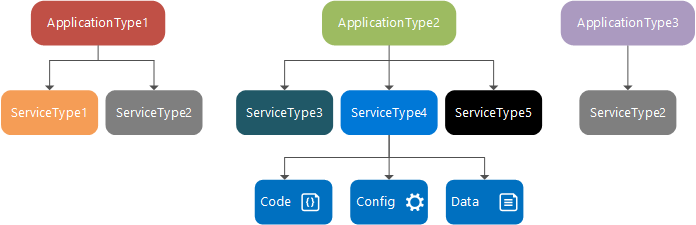
Pakiet aplikacji jest katalogiem dysku zawierającym plik ApplicationManifest.xml typu aplikacji, który odwołuje się do pakietów usług dla każdego typu usługi tworzącego typ aplikacji. Na przykład pakiet aplikacji dla typu aplikacji poczty e-mail może zawierać odwołania do pakietu usługi kolejki, pakietu usługi frontonu i pakietu usługi bazy danych.
Pliki w katalogu pakietów aplikacji są kopiowane do magazynu obrazów klastra usługi Service Fabric. Następnie możesz utworzyć nazwaną aplikację na podstawie tego typu aplikacji, która następnie jest uruchamiana w klastrze. Po utworzeniu nazwanej aplikacji można utworzyć nazwaną usługę na podstawie jednego z typów usług typu aplikacji.
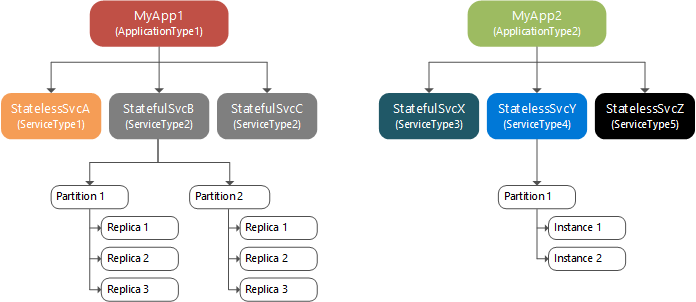
Czas wykonywania: klastry i węzły, nazwane aplikacje, nazwane usługi, partycje i repliki
Klaster usługi Service Fabric to połączony z siecią zestaw maszyn wirtualnych lub fizycznych, do których są wdrażane i zarządzane mikrousługi. Klastry mogą obejmować nawet tysiące maszyn.
Maszyna lub maszyna wirtualna, która jest częścią klastra, jest nazywana węzłem. Każdy węzeł ma przypisaną nazwę węzła (ciąg). Węzły mają swoje właściwości — na przykład właściwości dotyczące umieszczania. Każda maszyna lub maszyna wirtualna ma automatycznie uruchamianą usługę systemu Windows, która uruchamia się po rozruchu, FabricHost.exea następnie uruchamia dwa pliki wykonywalne: Fabric.exe i FabricGateway.exe. Te dwa pliki wykonywalne tworzą węzeł. W przypadku scenariuszy programowania lub testowania można hostować wiele węzłów na jednej maszynie lub maszynie wirtualnej, uruchamiając wiele wystąpień i Fabric.exeFabricGateway.exe.
Nazwana aplikacja to kolekcja nazwanych usług, która wykonuje określoną funkcję lub funkcje. Usługa wykonuje pełną i autonomiczną funkcję (może uruchamiać i uruchamiać niezależnie od innych usług) i składa się z kodu, konfiguracji i danych. Po skopiowaniu pakietu aplikacji do magazynu obrazów należy utworzyć wystąpienie aplikacji w klastrze, określając typ aplikacji pakietu aplikacji (przy użyciu jego nazwy/wersji). Każde wystąpienie typu aplikacji ma przypisaną nazwę identyfikatora URI, która wygląda następująco : sieć szkieletowa:/MyNamedApp. W klastrze można utworzyć wiele nazwanych aplikacji z jednego typu aplikacji. Możesz również tworzyć nazwane aplikacje na podstawie różnych typów aplikacji. Każda nazwana aplikacja jest zarządzana i obsługiwana niezależnie.
Po utworzeniu nazwanej aplikacji można utworzyć wystąpienie jednego z jego typów usług (nazwanej usługi) w klastrze, określając typ usługi (przy użyciu jego nazwy/wersji). Każde wystąpienie typu usługi ma przypisaną nazwę identyfikatora URI o zakresie w obszarze identyfikatora URI nazwanej aplikacji. Jeśli na przykład utworzysz usługę o nazwie "MyDatabase" w nazwie "MyNamedApp", identyfikator URI będzie wyglądać następująco: fabric:/MyNamedApp/MyDatabase. W nazwanej aplikacji można utworzyć co najmniej jedną nazwaną usługę. Każda nazwana usługa może mieć własny schemat partycji i liczbę wystąpień/replik.
Istnieją dwa typy usług: bezstanowe i stanowe. Usługi bezstanowe nie przechowują stanu w usłudze. Usługi bezstanowe nie mają magazynu trwałego w ogóle ani nie przechowują stanu trwałego w zewnętrznej usłudze magazynu, takiej jak Azure Storage, Azure SQL Database lub Azure Cosmos DB. Stanowa usługa przechowuje stan w usłudze i używa modeli programowania Reliable Collections lub Reliable Actors do zarządzania stanem.
Podczas tworzenia nazwanej usługi należy określić schemat partycji. Usługi o dużych ilościach stanu dzielą dane między partycjami. Każda partycja jest odpowiedzialna za część pełnego stanu usługi, która jest rozłożona na węzły klastra.
Na poniższym diagramie przedstawiono relację między aplikacjami i wystąpieniami usług, partycjami i replikami.
Partycjonowanie, skalowanie i dostępność
Partycjonowanie nie jest unikatowe dla usługi Service Fabric. Znaną formą partycjonowania jest partycjonowanie danych lub dzielenie na fragmenty. Usługi stanowe z dużymi ilościami stanu dzielą dane między partycje. Każda partycja jest odpowiedzialna za część pełnego stanu usługi.
Repliki każdej partycji są rozłożone na węzły klastra, co umożliwia skalowanie stanu nazwanej usługi. Wraz ze wzrostem potrzeb związanych z danymi partycje rosną i ponowne równoważenie partycji usługi Service Fabric między węzłami w celu wydajnego korzystania z zasobów sprzętowych. Jeśli dodasz nowe węzły do klastra, usługa Service Fabric ponownie zrównoważy repliki partycji w zwiększonej liczbie węzłów. Ogólna wydajność aplikacji poprawia się i rywalizacja o dostęp do pamięci zmniejsza się. Jeśli węzły w klastrze nie są używane wydajnie, możesz zmniejszyć liczbę węzłów w klastrze. Usługa Service Fabric ponownie równoważy repliki partycji w zmniejszonej liczbie węzłów, aby lepiej wykorzystać sprzęt w każdym węźle.
W ramach partycji bezstanowe nazwane usługi mają wystąpienia, podczas gdy stanowe nazwane usługi mają repliki. Zwykle bezstanowe nazwane usługi mają tylko jedną partycję, ponieważ nie mają stanu wewnętrznego, chociaż istnieją wyjątki. Wystąpienia partycji zapewniają dostępność. Jeśli jedno wystąpienie zakończy się niepowodzeniem, inne wystąpienia nadal działają normalnie, a następnie usługa Service Fabric tworzy nowe wystąpienie. Stanowe nazwane usługi zachowują swój stan w ramach replik, a każda partycja ma własny zestaw replik. Operacje odczytu i zapisu są wykonywane w jednej repliki (nazywanej podstawową). Zmiany stanu operacji zapisu są replikowane do wielu innych replik (nazywanych aktywnymi sekundami). Jeśli replika nie powiedzie się, usługa Service Fabric utworzy nową replikę z istniejących replik.
Mikrousługi stanowe i bezstanowe dla usługi Service Fabric
Usługa Service Fabric umożliwia tworzenie aplikacji składających się z mikrousług lub kontenerów. Mikrousługi bezstanowe (na przykład bramy protokołów i internetowe serwery proxy) nie utrzymują modyfikowalnego stanu poza żądaniem i odpowiedzią serwera. Przykładem usługi bezstanowej są procesy robocze usług Azure Cloud Services. Mikrousługi stanowe (na przykład konta użytkowników, bazy danych, urządzenia, koszyki zakupów i kolejki) utrzymują modyfikowalny, autorytatywny stan poza żądaniem i odpowiedzią. Współczesne aplikacje internetowe łączą w sobie mikrousługi stanowe i bezstanowe.
Kluczową różnicą w usłudze Service Fabric jest silna koncentracja na tworzeniu usług stanowych, zarówno z wbudowanymi modelami programowania , jak i z konteneryzowanymi usługami stanowymi. Scenariusze zastosowania opisują sytuacje, w których używane są usługi stanowe.
Dlaczego mają stanowe mikrousługi wraz z bezstanowymi? Oto dwa główne przyczyny:
- Możesz tworzyć usługi przetwarzania transakcji online o wysokiej przepływności, małych opóźnieniach, odporne na awarie, dzięki zamknięciu kodu i danych na tym samym komputerze. Niektóre przykłady to interaktywne witryny sklepów, wyszukiwanie, systemy internetu rzeczy (IoT), systemy handlowe, systemy handlowe, przetwarzanie kart kredytowych i systemy wykrywania oszustw oraz zarządzanie rekordami osobistymi.
- Możesz uprościć projektowanie aplikacji. Mikrousługi stanowe usuwają potrzebę dodatkowych kolejek i pamięci podręcznych, które są tradycyjnie wymagane do spełnienia wymagań dotyczących dostępności i opóźnień aplikacji bezstanowej. Usługi stanowe to naturalnie wysoka dostępność i małe opóźnienia, co zmniejsza liczbę ruchomych części do zarządzania w aplikacji jako całości.
Obsługiwane modele programowania
Usługa Service Fabric oferuje wiele sposobów pisania usług i zarządzania nimi. Usługi mogą korzystać z interfejsów API usługi Service Fabric, aby w pełni korzystać z funkcji i struktur aplikacji platformy. Usługi mogą być również dowolnym skompilowanym programem wykonywalnym napisanym w dowolnym języku i hostowanym w klastrze usługi Service Fabric. Aby uzyskać więcej informacji, zobacz Obsługiwane modele programowania.
Kontenery
Domyślnie usługa Service Fabric wdraża i aktywuje usługi jako procesy. Usługa Service Fabric może również wdrażać usługi w kontenerach. Co ważne, można mieszać usługi w procesach i usługach w kontenerach w tej samej aplikacji. Usługa Service Fabric obsługuje wdrażanie kontenerów systemu Linux i kontenerów systemu Windows na Windows Server 2016. Istniejące aplikacje, usługi bezstanowe lub usługi stanowe można wdrożyć w kontenerach.
Reliable Services
Reliable Services to uproszczona struktura do pisania usług, które integrują się z platformą Service Fabric i korzystają z pełnego zestawu funkcji platformy. Usługi Reliable Services mogą być bezstanowe (podobne do większości platform usług, takich jak serwery internetowe lub role procesów roboczych na platformie Azure Cloud Services), gdzie stan jest utrwalany w rozwiązaniu zewnętrznym, takim jak usługa Azure DB lub Azure Table Storage. Usługi Reliable Services mogą być również stanowe, gdzie stan jest utrwalany bezpośrednio w samej usłudze przy użyciu niezawodnych kolekcji. Stan jest wysoce dostępny za pośrednictwem replikacji i dystrybuowany przez partycjonowanie, wszystkie zarządzane automatycznie przez usługę Service Fabric.
Reliable Actors
Oparta na usługach Reliable Services platforma Reliable Actor to struktura aplikacji, która implementuje wzorzec wirtualnego aktora na podstawie wzorca projektowego aktora. Platforma Reliable Actor używa niezależnych jednostek obliczeniowych i stanu z wykonywaniem jednowątkowym nazywanym aktorami. Platforma Reliable Actor zapewnia wbudowaną komunikację dla aktorów i wstępnie ustawioną trwałość stanu i konfiguracje skalowania w poziomie.
ASP.NET Core
Usługa Service Fabric integruje się z ASP.NET Core jako pierwszoklasowy model programowania do tworzenia aplikacji internetowych i interfejsów API. ASP.NET Core można używać na dwa różne sposoby w usłudze Service Fabric:
- Hostowane jako plik wykonywalny gościa. Jest to używane głównie do uruchamiania istniejących aplikacji ASP.NET Core w usłudze Service Fabric bez zmian w kodzie.
- Uruchamianie wewnątrz usługi Reliable Service. Umożliwia to lepszą integrację ze środowiskiem uruchomieniowym usługi Service Fabric i umożliwia stanowe ASP.NET Core usług.
Pliki wykonywalne gościa
Plik wykonywalny gościa to istniejący, dowolny plik wykonywalny (napisany w dowolnym języku) hostowany w klastrze usługi Service Fabric wraz z innymi usługami. Pliki wykonywalne gościa nie są integrujące się bezpośrednio z interfejsami API usługi Service Fabric. Jednak nadal korzystają z funkcji oferowanych przez platformę, takich jak niestandardowe raportowanie kondycji i obciążenia oraz możliwość odnajdywania usług przez wywołanie interfejsów API REST. Mają również pełną obsługę cyklu życia aplikacji.
Cykl życia aplikacji
Podobnie jak w przypadku innych platform, aplikacja w usłudze Service Fabric zwykle przechodzi następujące fazy: projektowanie, programowanie, testowanie, wdrażanie, uaktualnianie, konserwacja i usuwanie. Usługa Service Fabric zapewnia najwyższej klasy obsługę pełnego cyklu życia aplikacji w chmurze, od programowania przez wdrażanie, codzienne zarządzanie i konserwację po ostateczne zlikwidowanie. Model usługi umożliwia niezależne uczestnictwo kilku różnych ról w cyklu życia aplikacji. Cykl życia aplikacji usługi Service Fabric zawiera omówienie interfejsów API i sposobu ich użycia przez różne role w fazach cyklu życia aplikacji usługi Service Fabric.
Cały cykl życia aplikacji można zarządzać przy użyciu poleceń cmdlet programu PowerShell, poleceń interfejsu wiersza polecenia, interfejsów API języka C#, interfejsów APIjęzyka Java i interfejsów API REST. Możesz również skonfigurować potoki ciągłej integracji/ciągłego wdrażania przy użyciu narzędzi, takich jak Azure Pipelines lub Jenkins.
Testowanie aplikacji i usług
Aby utworzyć naprawdę usługi w skali chmury, ważne jest sprawdzenie, czy aplikacje i usługi mogą wytrzymać rzeczywiste awarie. Usługa Analizy błędów jest przeznaczona do testowania usług opartych na usłudze Service Fabric. Usługa Analizy błędów umożliwia wywoływanie znaczących błędów i uruchamianie kompletnych scenariuszy testowych względem aplikacji. Te błędy i scenariusze wykonują ćwiczenia oraz weryfikują liczne stany i przejścia, które usługa będzie doświadczać przez cały okres istnienia, a wszystko to w kontrolowany, bezpieczny i spójny sposób.
Akcje są przeznaczone dla usługi do testowania przy użyciu pojedynczych błędów. Deweloper usługi może użyć ich jako bloków konstrukcyjnych do pisania skomplikowanych scenariuszy. Przykłady symulowanych błędów to:
- Uruchom ponownie węzeł, aby zasymulować dowolną liczbę sytuacji, w których maszyna lub maszyna wirtualna została ponownie uruchomiona.
- Przenieś replikę usługi stanowej, aby symulować równoważenie obciążenia, tryb failover lub uaktualnianie aplikacji.
- Wywołaj utratę kworum w usłudze stanowej, aby utworzyć sytuację, w której nie można kontynuować operacji zapisu, ponieważ nie ma wystarczającej liczby replik "kopii zapasowych" lub "pomocniczych", aby akceptować nowe dane.
- Wywołaj utratę danych w usłudze stanowej, aby utworzyć sytuację, w której cały stan w pamięci zostanie całkowicie wyczyszczony.
Scenariusze to złożone operacje składające się z co najmniej jednej akcji. Usługa Analizy błędów udostępnia dwa wbudowane kompletne scenariusze:
- Scenariusz chaosu — symuluje ciągłe, przeplatane błędy (zarówno bezproblemowe, jak i niegrzeczne) w całym klastrze przez dłuższy czas.
- Scenariusz trybu failover — wersja scenariusza testu chaosu, która jest przeznaczona dla określonej partycji usługi, pozostawiając inne usługi bez wpływu.
Klastry
Klaster usługi Service Fabric to połączony z siecią zestaw maszyn wirtualnych lub fizycznych, w którym są wdrażane mikrousługi i zarządzane. Klastry mogą obejmować nawet tysiące maszyn. Maszyna lub maszyna wirtualna, która jest częścią klastra, jest nazywana węzłem klastra. Każdy węzeł ma przypisaną nazwę węzła (ciąg). Węzły mają swoje właściwości — na przykład właściwości dotyczące umieszczania. Każda maszyna lub maszyna wirtualna ma usługę automatycznego uruchamiania, która uruchamia się po rozruchu, FabricHost.exea następnie uruchamia dwa pliki wykonywalne: Fabric.exe i FabricGateway.exe. Te dwa pliki wykonywalne tworzą węzeł. W przypadku scenariuszy testowania można hostować wiele węzłów na jednej maszynie lub maszynie wirtualnej, uruchamiając wiele wystąpień Fabric.exe elementów i FabricGateway.exe.
Klastry usługi Service Fabric można tworzyć na maszynach wirtualnych lub fizycznych z systemem Windows Server lub Linux. Możesz wdrażać i uruchamiać aplikacje usługi Service Fabric w dowolnym środowisku, w którym masz zestaw komputerów z systemem Windows Server lub Linux, które są połączone: lokalnie, na platformie Microsoft Azure lub u dowolnego dostawcy usług w chmurze.
Klastry na platformie Azure
Uruchamianie klastrów usługi Service Fabric na platformie Azure zapewnia integrację z innymi funkcjami i usługami platformy Azure, dzięki czemu operacje i zarządzanie klastrem są łatwiejsze i bardziej niezawodne. Klaster to zasób usługi Azure Resource Manager, dzięki czemu można modelować klastry jak wszystkie inne zasoby na platformie Azure. Resource Manager zapewnia również łatwe zarządzanie wszystkimi zasobami używanymi przez klaster jako pojedynczą jednostką. Klastry na platformie Azure są zintegrowane z diagnostyką platformy Azure i dziennikami usługi Azure Monitor. Typy węzłów klastra to zestawy skalowania maszyn wirtualnych, dlatego wbudowane są funkcje skalowania automatycznego.
Klaster na platformie Azure można utworzyć za pomocą Azure Portal, szablonu lub programu Visual Studio.
Usługa Service Fabric w systemie Linux umożliwia tworzenie, wdrażanie i zarządzanie wysoce skalowalnymi aplikacjami o wysokiej dostępności w systemie Linux, tak jak w systemie Windows. Struktury usługi Service Fabric (Reliable Services i Reliable Actors) są dostępne w języku Java w systemie Linux oprócz języka C# (.NET Core). Możesz również tworzyć usługi wykonywalne gościa przy użyciu dowolnego języka lub platformy. Organizowanie kontenerów platformy Docker jest również obsługiwane. Kontenery platformy Docker mogą uruchamiać pliki wykonywalne gościa lub natywne usługi Service Fabric, które korzystają ze struktur usługi Service Fabric. Aby uzyskać więcej informacji, przeczytaj o usłudze Service Fabric w systemie Linux.
Istnieją pewne funkcje, które są obsługiwane w systemie Windows, ale nie w systemie Linux. Aby dowiedzieć się więcej, przeczytaj różnice między usługą Service Fabric w systemie Linux i Windows.
Klastry autonomiczne
Usługa Service Fabric udostępnia pakiet instalacyjny umożliwiający tworzenie autonomicznych klastrów usługi Service Fabric lokalnie lub u dowolnego dostawcy chmury. Klastry autonomiczne zapewniają swobodę hostowania klastra niezależnie od potrzeb. Jeśli dane podlegają ograniczeniom zgodności lub regulacjom lub chcesz przechowywać dane lokalnie, możesz hostować własny klaster i aplikacje. Aplikacje usługi Service Fabric mogą być uruchamiane w wielu środowiskach hostingu bez wprowadzania zmian, więc wiedza na temat tworzenia aplikacji jest prowadzona z jednego środowiska hostingu do innego.
Tworzenie pierwszego autonomicznego klastra usługi Service Fabric
Klastry autonomiczne systemu Linux nie są jeszcze obsługiwane.
Zabezpieczenia klastra
Klastry muszą być zabezpieczone, aby uniemożliwić nieautoryzowanym użytkownikom łączenie się z klastrem, zwłaszcza w przypadku uruchamiania na nim obciążeń produkcyjnych. Chociaż istnieje możliwość utworzenia niezabezpieczonego klastra, dzięki temu użytkownicy anonimowi mogą łączyć się z nim, jeśli punkty końcowe zarządzania są widoczne w publicznym Internecie. Nie można później włączyć zabezpieczeń w niezabezpieczonym klastrze: zabezpieczenia klastra są włączone w czasie tworzenia klastra.
Scenariusze zabezpieczeń klastra to:
- Zabezpieczenia typu węzeł-węzeł
- Zabezpieczenia klient-węzeł
- Kontrola dostępu oparta na rolach usługi Service Fabric
Aby uzyskać więcej informacji, zobacz Zabezpieczanie klastra.
Skalowanie
Jeśli dodasz nowe węzły do klastra, usługa Service Fabric ponownie zrównoważy repliki partycji i wystąpienia w zwiększonej liczbie węzłów. Ogólna wydajność aplikacji poprawia się i rywalizacja o dostęp do pamięci zmniejsza się. Jeśli węzły w klastrze nie są używane wydajnie, można zmniejszyć liczbę węzłów w klastrze. Usługa Service Fabric ponownie równoważy repliki partycji i wystąpienia w zmniejszonej liczbie węzłów, aby lepiej wykorzystać sprzęt w każdym węźle. Klastry można skalować na platformie Azure ręcznie lub programowo. Klastry autonomiczne można skalować ręcznie.
Uaktualnienia klastra
Okresowo są wydawane nowe wersje środowiska uruchomieniowego usługi Service Fabric. Wykonaj uaktualnienie środowiska uruchomieniowego lub sieci szkieletowej w klastrze, aby zawsze uruchamiać obsługiwaną wersję. Oprócz uaktualnień sieci szkieletowej można również zaktualizować konfigurację klastra, taką jak certyfikaty lub porty aplikacji.
Klaster usługi Service Fabric to zasób, którego jesteś właścicielem, ale jest częściowo zarządzany przez firmę Microsoft. Firma Microsoft jest odpowiedzialna za stosowanie poprawek do bazowego systemu operacyjnego i wykonywanie uaktualnień sieci szkieletowej w klastrze. Klaster można ustawić tak, aby otrzymywał automatyczne uaktualnienia sieci szkieletowej, gdy firma Microsoft wyda nową wersję, lub wybrać obsługiwaną wersję sieci szkieletowej. Uaktualnienia sieci szkieletowej i konfiguracji można ustawić za pośrednictwem Azure Portal lub za pośrednictwem Resource Manager. Aby uzyskać więcej informacji, zobacz Uaktualnianie klastra usługi Service Fabric.
Autonomiczny klaster to zasób, który jest całkowicie właścicielem. Odpowiadasz za stosowanie poprawek do bazowego systemu operacyjnego i inicjowanie uaktualnień sieci szkieletowej. Jeśli klaster może nawiązać połączenie z https://www.microsoft.com/downloadusługą , możesz ustawić klaster tak, aby automatycznie pobierał i aprowizować nowy pakiet środowiska uruchomieniowego usługi Service Fabric. Następnie zainicjuj uaktualnienie. Jeśli klaster nie może uzyskać dostępu https://www.microsoft.com/download, możesz ręcznie pobrać nowy pakiet środowiska uruchomieniowego z komputera połączonego z Internetem, a następnie zainicjować uaktualnienie. Aby uzyskać więcej informacji, zobacz Uaktualnianie autonomicznego klastra usługi Service Fabric.
Monitorowanie kondycji
Usługa Service Fabric wprowadza model kondycji zaprojektowany pod kątem flagowania złej kondycji klastra i warunków aplikacji dla określonych jednostek (takich jak węzły klastra i repliki usług). Model kondycji używa reporterów kondycji (składników systemowych i watchdogów). Celem jest łatwa i szybka diagnoza i naprawa. Autorzy usług muszą myśleć z góry o kondycji i sposobie projektowania raportowania kondycji. Każdy warunek, który może mieć wpływ na kondycję, powinien być zgłaszany, zwłaszcza jeśli może pomóc flagować problemy blisko katalogu głównego. Informacje o kondycji mogą zaoszczędzić czas i nakład pracy na debugowanie i badanie po uruchomieniu usługi na dużą skalę w środowisku produkcyjnym.
Reporterzy usługi Service Fabric monitorują zidentyfikowane warunki zainteresowania. Zgłaszają te warunki na podstawie ich lokalnego widoku. Magazyn kondycji agreguje dane kondycji wysyłane przez wszystkich reporterów w celu ustalenia, czy jednostki są globalnie w dobrej kondycji. Model ma być bogaty, elastyczny i łatwy w użyciu. Jakość raportów kondycji określa dokładność widoku kondycji klastra. Fałszywie dodatnie, które błędnie pokazują problemy ze złą kondycją, mogą negatywnie wpłynąć na uaktualnienia lub inne usługi korzystające z danych o kondycji. Przykłady takich usług to usługi naprawy i mechanizmy zgłaszania alertów. W związku z tym niektóre myśli są potrzebne do zapewnienia raportów, które przechwytują warunki zainteresowania w najlepszy możliwy sposób.
Raportowanie można wykonać na podstawie:
- Monitorowana replika usługi Service Fabric lub wystąpienie.
- Wewnętrzne watchdogs wdrożone jako usługa Service Fabric (na przykład usługa bezstanowa usługi Service Fabric, która monitoruje warunki i problemy raporty). Watchdogs można wdrożyć na wszystkich węzłach lub być zainicjowane w monitorowanej usłudze.
- Wewnętrzne elementy watchdog uruchamiane w węzłach usługi Service Fabric, ale nie są implementowane jako usługi Service Fabric.
- Zewnętrzni obserwatorzy sondujący zasób spoza klastra usługi Service Fabric (na przykład usługę monitorowania, np. Gomez).
Poza tym składniki usługi Service Fabric raportują kondycję wszystkich jednostek w klastrze. Raporty kondycji systemu zapewniają wgląd w funkcje klastra i aplikacji oraz flagowanie problemów za pośrednictwem kondycji. W przypadku aplikacji i usług raporty kondycji systemu sprawdzają, czy jednostki są implementowane i działają prawidłowo z perspektywy środowiska uruchomieniowego usługi Service Fabric. Raporty nie zapewniają monitorowania kondycji logiki biznesowej usługi lub wykrywania procesów, które przestały odpowiadać. Aby dodać informacje o kondycji specyficzne dla logiki usługi, zaimplementuj niestandardowe raportowanie kondycji w usługach.
Usługa Service Fabric udostępnia wiele sposobów wyświetlania raportów kondycji zagregowanych w magazynie kondycji:
- Service Fabric Explorer lub inne narzędzia do wizualizacji.
- Zapytania dotyczące kondycji (za pomocą programu PowerShell, interfejsu wiersza polecenia, interfejsów API klienta języka C# i interfejsów API klienta Java FabricClient lub interfejsów API REST).
- Zapytania ogólne zwracające listę jednostek, które mają kondycję jako jedną z właściwości (za pomocą programu PowerShell, interfejsu wiersza polecenia, interfejsów API lub rest).
Monitorowanie i diagnostyka
Monitorowanie i diagnostyka mają kluczowe znaczenie dla tworzenia, testowania i wdrażania aplikacji i usług w dowolnym środowisku. Rozwiązania usługi Service Fabric działają najlepiej podczas planowania i implementowania monitorowania i diagnostyki, które pomagają zapewnić, że aplikacje i usługi działają zgodnie z oczekiwaniami w lokalnym środowisku deweloperskim lub w środowisku produkcyjnym.
Głównymi celami monitorowania i diagnostyki są:
- Wykrywanie i diagnozowanie problemów ze sprzętem i infrastrukturą
- Wykrywanie problemów z oprogramowaniem i aplikacją, zmniejszenie przestoju usługi
- Omówienie użycia zasobów i pomoc w podejmowaniu decyzji dotyczących operacji
- Optymalizowanie wydajności aplikacji, usługi i infrastruktury
- Generowanie szczegółowych informacji biznesowych i identyfikowanie obszarów poprawy
Ogólny przepływ pracy monitorowania i diagnostyki składa się z trzech kroków:
- Generowanie zdarzeń: obejmuje to zdarzenia (dzienniki, ślady, zdarzenia niestandardowe) na poziomie infrastruktury (klastra), platformy i aplikacji / usługi
- Agregacja zdarzeń: przed ich wyświetleniem należy zebrać i zagregować zdarzenia
- Analiza: zdarzenia muszą być wizualizowane i dostępne w pewnym formacie, aby umożliwić analizę i wyświetlanie w razie potrzeby
Dostępnych jest wiele produktów, które obejmują te trzy obszary i możesz wybrać różne technologie dla każdego z nich. Aby uzyskać więcej informacji, zobacz Monitorowanie i diagnostyka usługi Azure Service Fabric.
Następne kroki
- Dowiedz się, jak utworzyć klaster na platformie Azure lub autonomiczny klaster w systemie Windows.
- Spróbuj utworzyć usługę za pomocą usług Reliable Services lub modelu programowania Reliable Actors.
- Dowiedz się, jak przeprowadzić migrację z Cloud Services.
- Dowiedz się, jak monitorować i diagnozować usługi.
- Dowiedz się, jak testować aplikacje i usługi.
- Dowiedz się, jak zarządzać zasobami klastra i organizować je.
- Zapoznaj się z przykładami usługi Service Fabric.
- Dowiedz się więcej o opcjach pomocy technicznej usługi Service Fabric.
- Przeczytaj blog zespołu , aby zapoznać się z artykułami i ogłoszeniami.