Rozwiązywanie problemów z automatycznym trybem failover w środowiskach SQL Server Always On
Ten artykuł ułatwia rozwiązywanie problemów występujących podczas automatycznego trybu failover w usłudze Microsoft SQL Server.
Oryginalna wersja produktu: SQL Server
Oryginalny numer KB: 2833707
Podsumowanie
SQL Server zawsze włączone grupy dostępności można skonfigurować do automatycznego przełączania w tryb failover. Jeśli w wystąpieniu SQL Server hostującej replikę podstawową zostanie wykryty problem z kondycją, rolę podstawową można przenieść do partnera automatycznego trybu failover (repliki pomocniczej). Jednak repliki pomocniczej nie zawsze można przenieść do roli podstawowej. W niektórych przypadkach można go przenieść tylko do RESOLVING roli. W takiej sytuacji żadna replika nie będzie miała roli podstawowej, chyba że replika podstawowa powróci do stanu dobrej kondycji. Ponadto bazy danych dostępności będą niedostępne.
W tym artykule wymieniono niektóre typowe przyczyny niepowodzenia automatycznego trybu failover i omówiono kroki, które można wykonać w celu zdiagnozowania przyczyny tych błędów.
Objawy, jeśli automatyczne przejście w tryb failover zostanie pomyślnie wyzwolone
Po wyzwoleniu automatycznego trybu failover w wystąpieniu SQL Server hostującej replikę podstawową replika pomocnicza przechodzi do RESOLVING roli, a następnie do roli podstawowej. Mimo że proces zakończył się pomyślnie, wpisy błędów są rejestrowane w raporcie dziennika SQL Server, który przypomina następujący tekst:
The state of the local availability replica in availability group '\<Group name>' has changed from 'RESOLVING_NORMAL' to 'PRIMARY_PENDING'
The state of the local availability replica in availability group '\<Group name>' has changed from 'PRIMARY_PENDING' to 'PRIMARY_NORMAL'

Uwaga
Replika pomocnicza pomyślnie przechodzi ze RESOLVING_NORMAL stanu do PRIMARY_NORMAL stanu.
Objawy, jeśli automatyczne przejście w tryb failover zakończy się niepowodzeniem
Jeśli automatyczne zdarzenie trybu failover nie powiedzie się, replika pomocnicza nie przejdzie pomyślnie do roli podstawowej. W związku z tym replika dostępności zgłosi, że ta replika RESOLVING jest w stanie. Ponadto bazy danych dostępności zgłaszają, że są w NOT SYNCHRONIZING stanie, a aplikacje nie mogą uzyskać dostępu do tych baz danych.
Na przykład na poniższej ilustracji SQL Server Management Studio raporty, że replika pomocnicza jest w RESOLVING stanie, ponieważ proces automatycznego trybu failover nie może przenieść repliki pomocniczej do roli podstawowej.
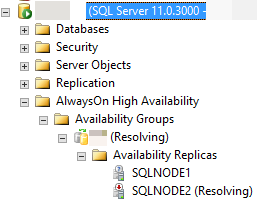
W poniższych sekcjach omówiono kilka możliwych przyczyn niepowodzenia automatycznego trybu failover i sposobu diagnozowania każdej przyczyny.
Przypadek 1. Wartość "Maksymalna liczba niepowodzeń w określonym okresie" jest wyczerpana
Grupa dostępności ma właściwości zasobów klastra systemu Windows, takie jak maksymalna liczba niepowodzeń we właściwości Określony okres . Ta właściwość służy do unikania nieograniczonego przenoszenia zasobu klastrowanego w przypadku wystąpienia wielu awarii węzłów.
Aby zbadać i zdiagnozować, czy jest to przyczyna nieudanego przejścia w tryb failover, przejrzyj dziennik klastra systemu Windows (Cluster.log), a następnie sprawdź właściwość.
Krok 1. Przeglądanie danych w dzienniku klastra systemu Windows (Cluster.log)
Użyj Windows PowerShell, aby wygenerować dziennik klastra systemu Windows w węźle klastra hostującym replikę podstawową. W tym celu uruchom następujące polecenie cmdlet w oknie programu PowerShell z podwyższonym poziomem uprawnień w wystąpieniu SQL Server hostującym replikę podstawową:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15
[! UWAGI]
- Parametr
-TimeSpan 15w tym kroku zakłada, że problem, który jest diagnozowany, wystąpił w ciągu ostatnich 15 minut. - Domyślnie plik dziennika jest tworzony w folderze %WINDIR%\cluster\reports.
- Parametr
Otwórz plik Cluster.log w Notatniku, aby przejrzeć dziennik klastra systemu Windows.
W Notatniku wybierz pozycję Edytuj>wyszukiwanie, a następnie wyszukaj ciąg "failoverCount" na końcu pliku. W wynikach powinien zostać wyświetlony komunikat podobny do następującego:
Nie można przełączać w tryb failover nazwy zasobu grupy<, trybu failoverCount 3, trybu failoverThresholdSetting <Number>, computedFailoverThreshold 2>

Krok 2. Sprawdzanie maksymalnej liczby niepowodzeń we właściwości Określony okres
Uruchom Menedżera klastra trybu failover.
W okienku nawigacji wybierz pozycję Role.
W okienku Role kliknij prawym przyciskiem myszy zasób klastrowany, a następnie wybierz pozycję Właściwości.
Wybierz kartę Tryb failover i wybierz wartość Maksymalna liczba niepowodzeń w wartości Określony okres .
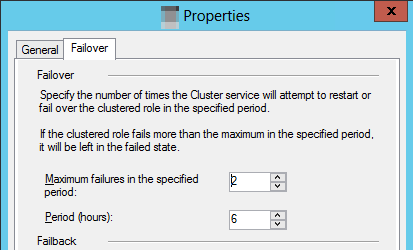
Uwaga
Zachowanie domyślne określa, że jeśli zasób klastrowany zakończy się niepowodzeniem trzy razy w ciągu sześciu godzin, powinien pozostać w stanie niepowodzenia. W przypadku grupy dostępności oznacza to, że replika pozostaje w
RESOLVINGstanie.
Wniosku
Po przeanalizowaniu dziennika okaże się, że wartość failoverCountwynosząca 3 jest większa niż wartość computedFailoverThresholdwynosząca 2. W związku z tym klaster systemu Windows nie może ukończyć operacji trybu failover zasobu grupy dostępności dla partnera trybu failover.
Rozwiązanie
Aby rozwiązać ten problem, zwiększ wartość Maksymalna liczba niepowodzeń w wartości Określony okres .
Uwaga
Zwiększenie tej wartości może nie rozwiązać problemu. Może wystąpić bardziej krytyczny problem, który powoduje, że grupa dostępności wielokrotnie kończy się niepowodzeniem w krótkim okresie. Domyślnie ten okres wynosi 15 minut. Zwiększenie tej wartości może po prostu spowodować, że grupa dostępności będzie więcej razy kończyć się niepowodzeniem i pozostanie w stanie niepowodzenia. Zalecamy użycie agresywnego rozwiązywania problemów, aby określić, dlaczego automatyczna praca w trybie failover nadal występuje.
Przypadek 2. Niewystarczające uprawnienia do konta NT Authority\SYSTEM
Bibliotekę DLL zasobu aparatu bazy danych SQL Server łączy się z wystąpieniem SQL Server hostującym replikę podstawową przy użyciu funkcji ODBC do monitorowania kondycji. Poświadczenia logowania używane na potrzeby tego połączenia to konto logowania SQL Server NT AUTHORITY\SYSTEM lokalnej. Domyślnie to lokalne konto logowania ma następujące uprawnienia:
- Zmienianie dowolnej grupy dostępności
- Łączenie z programem SQL
- Wyświetlanie stanu serwera
NT AUTHORITY\SYSTEM Jeśli konto logowania nie ma żadnego z tych uprawnień dla partnera automatycznego trybu failover (repliki pomocniczej), SQL Server nie może rozpocząć wykrywania kondycji w przypadku automatycznego przejścia w tryb failover. W związku z tym replika pomocnicza nie może przejść do roli podstawowej. Aby zbadać i zdiagnozować, czy jest to przyczyna, przejrzyj dziennik klastra systemu Windows. Aby to zrobić, wykonaj następujące kroki.
Użyj Windows PowerShell, aby wygenerować dziennik klastra systemu Windows w węźle klastra. W tym celu uruchom następujące polecenie cmdlet w oknie programu PowerShell z podwyższonym poziomem uprawnień w wystąpieniu SQL Server hostującej replikę pomocniczą, która nie przeszła do roli podstawowej:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15
Otwórz plik Cluster.log w Notatniku, aby przejrzeć dziennik klastra systemu Windows.
Znajdź wpis błędu podobny do następującego tekstu:
Nie można uruchomić polecenia diagnostycznego. Użytkownik nie ma uprawnień do wykonania tej akcji.
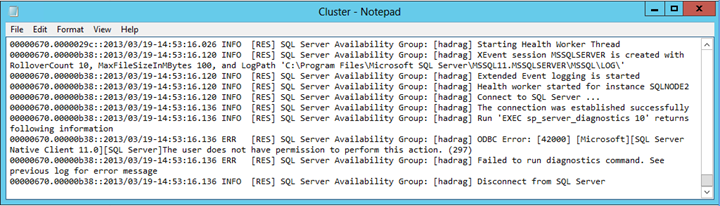
Wniosku
Plik Cluster.log zgłasza, że problem z uprawnieniami występuje, gdy SQL Server uruchamia polecenie diagnostyczne. W tym przykładzie awaria została spowodowana usunięciem uprawnienia Wyświetl stan serwera z NT AUTHORITY\SYSTEM konta logowania w wystąpieniu SQL Server hostującym replikę pomocniczą pary automatycznego trybu failover.
Rozwiązanie
Aby rozwiązać ten problem, przyznaj kontu NT AUTHORITY\SYSTEM logowania wystarczające uprawnienia do wykrywania kondycji biblioteki DLL zasobu aparatu bazy danych SQL Server.
Przypadek 3. Bazy danych dostępności nie są w stanie SYNCHRONIZOWANE
Aby automatycznie przełączać się w tryb failover, wszystkie bazy danych dostępności zdefiniowane w grupie dostępności muszą znajdować się w stanie między repliką podstawową SYNCHRONIZED a repliką pomocniczą. W przypadku automatycznego przejścia w tryb failover ten warunek synchronizacji musi zostać spełniony, aby upewnić się, że nie ma utraty danych. W związku z tym, jeśli jedna baza danych dostępności w grupie dostępności jest w stanie synchronizacji lub NOT SYNCHRONIZED stanu, automatyczne przejście w tryb failover nie spowoduje pomyślnego przeniesienia repliki pomocniczej do roli podstawowej.
Aby uzyskać więcej informacji na temat wymaganych warunków automatycznego trybu failover, zobacz Warunki wymagane dla automatycznego trybu failover, a repliki synchroniczne zatwierdzania obsługują dwie sekcje ustawieńtrybu failover i trybu failover (zawsze włączone grupy dostępności).
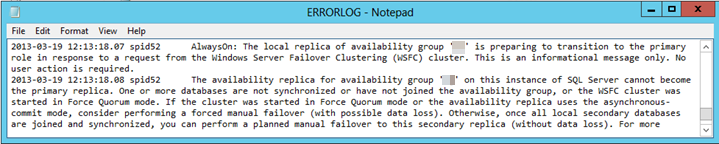
Aby zbadać i zdiagnozować, czy jest to przyczyna nieudanego przejścia w tryb failover, przejrzyj dziennik błędów SQL Server. Powinien zostać znaleziony wpis błędu podobny do następującego tekstu:
Co najmniej jedna baza danych nie jest zsynchronizowana lub nie dołączyła do grupy dostępności.
Aby sprawdzić, czy bazy danych dostępności są w SYNCHRONIZED stanie, wykonaj następujące kroki:
Połącz się z repliką pomocniczą.
Uruchom następujący skrypt SQL, aby sprawdzić
is_failover_readywartość dla wszystkich baz danych dostępności w grupie dostępności, która nie przekroczęła trybu failover.Uwaga
Wartość zero dla dowolnej bazy danych dostępności może uniemożliwić automatyczne przejście w tryb failover. Ta wartość wskazuje, że baza danych dostępności nie
SYNCHRONIZEDbyła .SELECT database_name, is_failover_ready FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id IN (SELECT replica_id FROM sys.dm_hadr_availability_replica_states)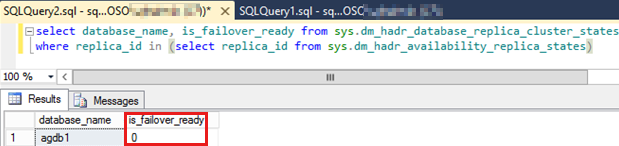
Wniosku
Pomyślne automatyczne przejście w tryb failover grupy dostępności wymaga, aby wszystkie bazy danych dostępności były w SYNCHRONIZED stanie. Aby uzyskać więcej informacji na temat trybów dostępności, zobacz Tryby dostępności w zawsze włączonych grupach dostępności.
Przypadek 4. Dla protokołów klienckich w replice pomocniczej (docelowej podstawowej) wybrano konfigurację "Wymuś szyfrowanie protokołu", chociaż replika nie jest skonfigurowana do szyfrowania
Podczas pracy w trybie failover, gdy serwer podstawowy wykryje problem z kondycją, bibliotekę DLL klastra u partnera trybu failover (repliki pomocniczej) próbuje nawiązać połączenie z repliką lokalną w celu zainicjowania monitorowania kondycji. Jest to część przejścia do roli podstawowej. Jeśli replika pomocnicza nie jest skonfigurowana do szyfrowania, ale ustawienie Wymuszaj szyfrowanie protokołu zostało przypadkowo ustawione w konfiguracji klienta, połączenie zakończy się niepowodzeniem i nie będzie możliwe przejście w tryb failover.
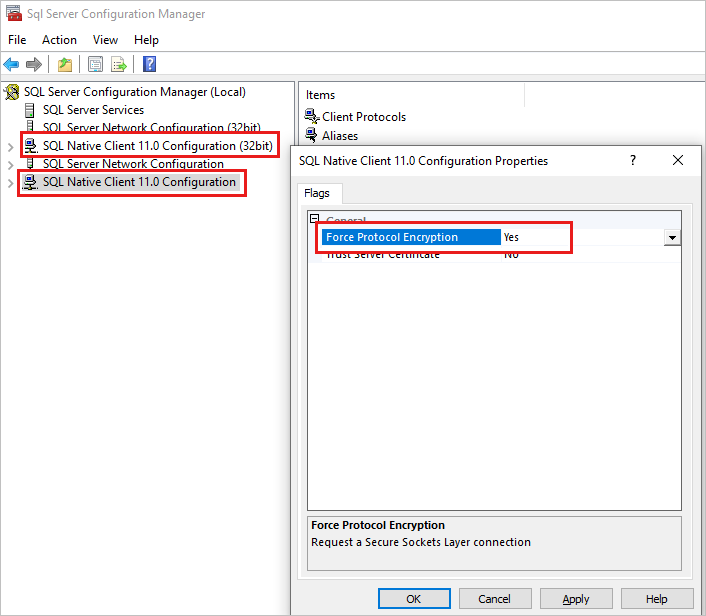
Aby sprawdzić tę konfigurację:
- Uruchom program SQL Server Configuration Manager.
- W okienku po lewej stronie kliknij prawym przyciskiem myszy konfigurację klienta natywnego SQL 11.0, a następnie wybierz pozycję Właściwości.
- W oknie dialogowym zaznacz ustawienie Wymuś szyfrowanie protokołu . Jeśli jest ustawiona wartość Tak, zmień wartość na Nie.
- Przetestuj ponownie tryb failover.
Wniosku
SQL Server zawsze włączone monitorowanie kondycji używa lokalnego połączenia ODBC do monitorowania kondycji SQL Server. Szyfrowanie protokołu wymuszania powinno być włączone w sekcji Konfiguracja klienta SQL Server Configuration Manager tylko wtedy, gdy sam SQL Server został skonfigurowany do wymuszania szyfrowania w SQL Server Configuration Manager w programie SQL Server sekcji Konfiguracja sieci. Aby uzyskać więcej informacji, zobacz Włączanie zaszyfrowanych połączeń z aparatem bazy danych.
Przypadek 5. Problemy z wydajnością repliki pomocniczej lub węzła powodują niepowodzenie zawsze włączonych kontroli kondycji
Przed przejściem w tryb failover z repliki podstawowej do repliki pomocniczej SQL Server biblioteki DLL zasobu aparatu bazy danych nawiązuje połączenie z repliką pomocniczą w celu ustalenia kondycji repliki. Jeśli to połączenie zakończy się niepowodzeniem z powodu problemów z wydajnością repliki pomocniczej, automatyczne przejście w tryb failover nie nastąpi.
Aby zbadać i zdiagnozować, czy jest to przyczyna, wykonaj następujące kroki:
Przejrzyj dziennik klastra repliki pomocniczej, aby sprawdzić komunikat o błędzie "Nie można ukończyć procesu logowania z powodu opóźnienia w otwarciu połączenia serwera".
0000110c.00002bcc::2020/08/06-01:17:54.943 INFO [RCM] move of group AOCProd01AG from CO2ICMV3SQL09(1) to CO2ICMV3SQL10(2) of type MoveType::Manual is about to succeed, failoverCount=3, lastFailoverTime=2020/08/05-02:08:54.524 targeted=true 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]Unable to complete login process due to delay in opening server connection (0) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Could not connect to SQL Server (rc -1) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] SQLDisconnect returns following information 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08003] [Microsoft][ODBC Driver Manager] Connection not open (0) 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Failed to connect to SQL Server 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RHS] Online for resource AOCProd01AG failed.Taka sytuacja może wystąpić w przypadku przejścia w tryb failover do repliki pomocniczej SQL Server, która ma zajęte istniejące obciążenie. Może to opóźnić odpowiedź SQL Server na próbę połączenia kondycji usługi HADR i zapobiec pomyślnej próbie przejścia w tryb failover.
Aby ustalić, czy istnieje presja na harmonogramy systemowe, użyj SQL Server Management Studio, aby uruchomić następujący skrypt w replice pomocniczej:
USE MASTER GO WHILE 1=1 BEGIN PRINT convert(varchar(20), getdate(),120) DECLARE @max INT; SELECT @max = max_workers_count FROM sys.dm_os_sys_info; SELECT GETDATE() AS 'CurrentDate', @max AS 'TotalThreads', SUM(active_Workers_count) AS 'CurrentThreads', @max - SUM(active_Workers_count) AS 'AvailableThreads', SUM(runnable_tasks_count) AS 'WorkersWaitingForCpu', SUM(work_queue_count) AS 'RequestWaitingForThreads' --SUM(current_workers_count) AS 'AssociatedWorkers' FROM sys.dm_os_Schedulers WHERE STATUS = 'VISIBLE ONLINE'; wait for delay '0:0:15' ENDPoniżej przedstawiono przykładowe dane wyjściowe poprzedniego zapytania:
CurrentDate TotalThreads CurrentThreads AvailableThreads WorkersWaitingForCpu RequestWaitingForThreads 2020-10-06 01:27:01.337 1216 361 855 33 0 2020-10-06 01:27:08.340 1216 1412 -196 22 76 2020-10-06 01:27:15.340 1216 1304 -88 2 161 2020-10-06 01:27:22.340 1216 1242 -26 21 185 2020-10-06 01:27:29.343 1216 1346 -130 19 476 2020-10-06 01:27:36.350 1216 1350 -134 9 630 2020-10-06 01:27:43.353 1216 1346 -130 13 539 2020-10-06 01:27:50.360 1216 1378 -162 5 328 2020-10-06 01:27:57.360 1216 197 1019 0 0 Wysokie wartości zgłaszane dla
WorkersWaitingForCpuiRequestWaitingForThreadswskazują, że występuje rywalizacja o planowanie i że SQL Server nie może obsługiwać bieżącego obciążenia w odpowiednim czasie.
Rozwiązanie
Jeśli wystąpi ten problem, ponownie zbalansuj obciążenie repliki pomocniczej lub rozważ zwiększenie mocy obliczeniowej (dodaj procesory) na komputerach z tymi obciążeniami.
Rozwiązywanie problemów z innymi zdarzeniami trybu failover zakończonymi niepowodzeniem
Aby monitorować kondycję nowej repliki podstawowej podczas pracy w trybie failover, należy lokalnie połączyć monitorowanie kondycji AlwaysOn z wystąpieniem SQL Server, które przechodzi do roli podstawowej.
Oprócz bardziej typowych przyczyn, które zostały omówione w tym artykule, istnieje wiele innych powodów, dla których ta próba połączenia może zakończyć się niepowodzeniem. Aby dokładniej zbadać próbę przejścia w tryb failover w trybie failover, przejrzyj dziennik klastra u partnera trybu failover (repliki, do którego nie można przełączyć się w tryb failover):
Użyj Windows PowerShell, aby wygenerować dziennik klastra systemu Windows w węźle klastra. W tym celu uruchom następujące polecenie cmdlet w oknie programu PowerShell z podwyższonym poziomem uprawnień w wystąpieniu SQL Server hostującej replikę pomocniczą, która nie przeszła do roli podstawowej. Dziennik klastra zostanie wygenerowany w ciągu ostatnich 60 minut działania.
Get-ClusterLog -Node <SQLServerNodeName> -TimeSpan 60Aby przejrzeć dziennik klastra systemu Windows, otwórz plik Cluster.log w Notatniku.
Wyszukaj ciąg "Połącz z SQL Server", który przypada podczas nieudanego zdarzenia trybu failover.
Przejrzyj kolejne komunikaty logowania przy użyciu identyfikatora wątku (zobacz poniższy zrzut ekranu), aby skorelować zdarzenia powiązane ze zdarzeniem logowania. W poniższym przykładzie przedstawiono wyszukiwanie frazy "Połącz z SQL Server". Pokazuje on również użycie identyfikatora wątku (po lewej stronie) do zlokalizowania innych diagnostyki opisujących przyczynę niepowodzenia próby nawiązania połączenia.
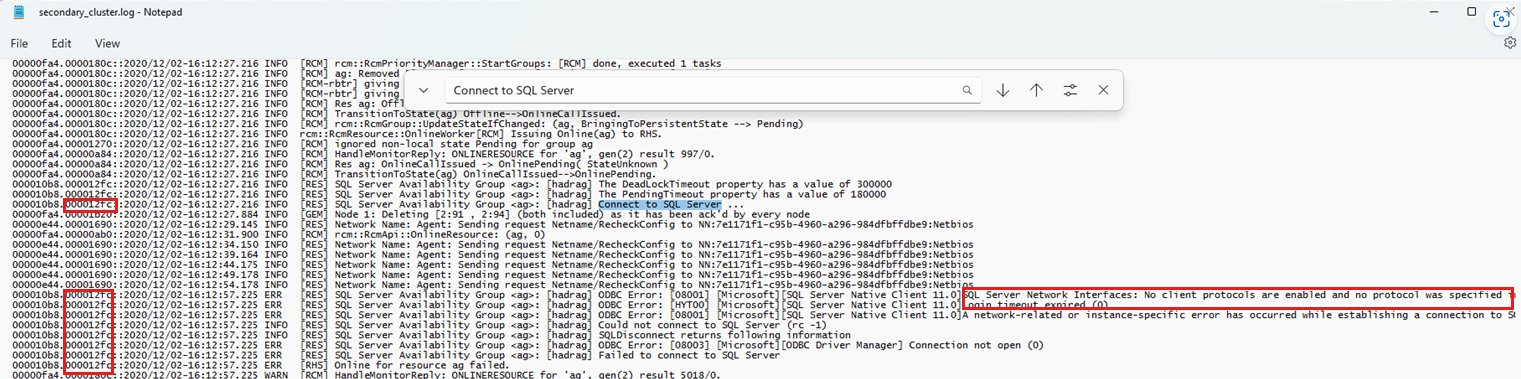

W poniższych przykładach przedstawiono błędy połączeń z nową repliką podstawową.
Przykładowy zestaw 1
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: No client protocols are enabled and no protocol was specified in the connection
string [xFFFFFFFF]. (268435455)
Rozwiązanie
Uruchom SQL Server Configuration Manager, a następnie sprawdź, czy włączono pamięć udostępnioną lub protokół TCP/IP w obszarze Protokoły klienta dla konfiguracji klienta natywnego SQL.
Przykładowy zestaw 2
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: Server doesn't support requested protocol [xFFFFFFFF]. (268435455)
Rozwiązanie
Uruchom SQL Server Configuration Manager, a następnie sprawdź, czy włączono pamięć udostępnioną lub protokół TCP/IP w obszarze Protokoły klienta dla konfiguracji klienta natywnego SQL.
Przykładowy zestaw 3
000010b8.00001764::2020/12/02-16:52:49.808 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Cannot alter the availability
group 'ag', because it does not exist or you do not have permission. (15151)
000010b8.00000fd0::2020/12/02-17:01:14.821 ERR [RES] SQL Server Availability Group: [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]The user does not have permission to perform this action. (297)
000010b8.00001838::2020/12/02-17:10:04.427 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Login failed for user
'SQLREPRO\NODE2$'. Reason: The account is disabled. (18470)
Rozwiązanie
Przejrzyj sprawę 2: Niewystarczające uprawnienia do konta NT Authority\SYSTEM.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla