Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Usługa Azure Managed Redis działa na stosie Redis Enterprise , który zapewnia znaczne korzyści w porównaniu z wersją Community Edition usługi Redis. Poniższe informacje zawierają więcej szczegółowych danych na temat sposobu, w jaki usługa Azure Managed Redis jest zaprojektowana, w tym informacje, które mogą być przydatne dla zaawansowanych użytkowników.
Porównanie z usługą Azure Cache for Redis
Warstwy Podstawowa, Standardowa i Premium usługi Azure Cache for Redis działają w wersji Community Edition usługi Redis. Ta wersja społecznościowa Redis ma kilka znaczących ograniczeń, w tym to, że jest jednowątkowa. To ograniczenie znacznie zmniejsza wydajność i sprawia, że skalowanie jest mniej wydajne, ponieważ usługa nie wykorzystuje w pełni większej liczby procesorów wirtualnych. Typowe wystąpienie usługi Azure Cache for Redis używa architektury podobnej do następującej:
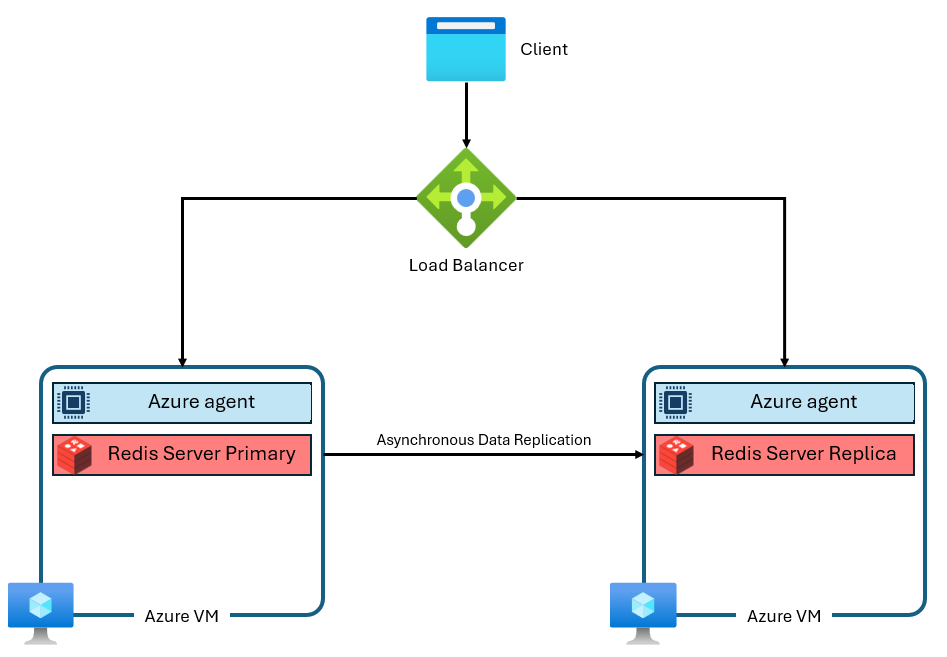
Zwróć uwagę, że są używane dwie maszyny wirtualne — podstawowa i replika. Te maszyny wirtualne są również nazywane węzłami. Główny węzeł przechowuje proces Redis i przyjmuje wszystkie zapisy. Replikacja jest przeprowadzana asynchronicznie na węzeł repliki w celu zapewnienia kopii zapasowej podczas konserwacji, skalowania lub nieoczekiwanej awarii. Każdy węzeł może uruchamiać tylko jeden proces serwera Redis ze względu na jednowątkowy projekt Redis społecznościowego.
Ulepszenia architektury usługi Azure Managed Redis
Usługa Azure Managed Redis korzysta z bardziej zaawansowanej architektury, która wygląda mniej więcej tak:
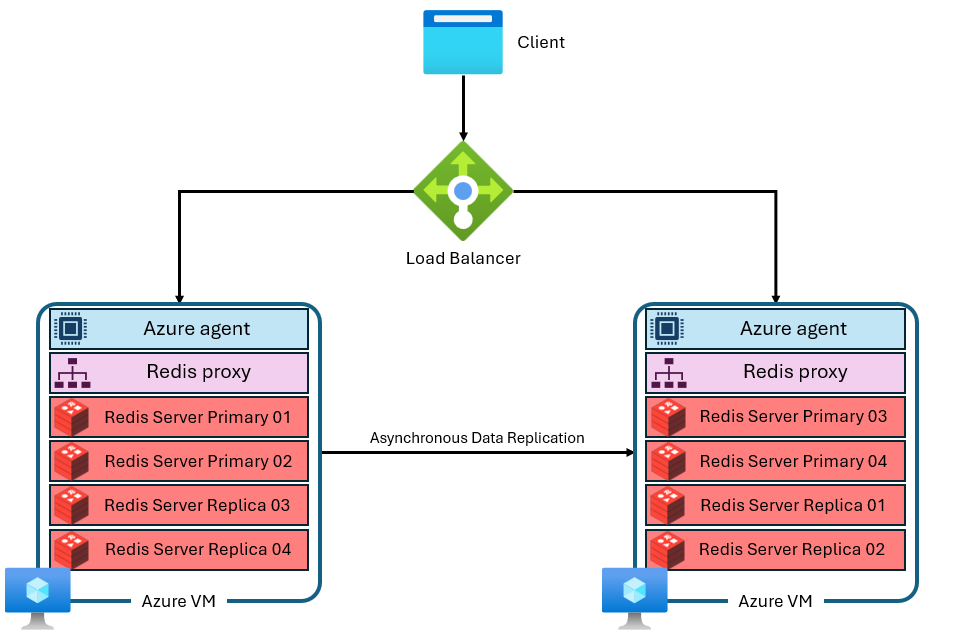
Istnieje kilka różnic:
- Każda maszyna wirtualna (lub węzeł) uruchamia wiele procesów serwera Redis (nazywanych fragmentami) równolegle. Wiele fragmentów umożliwia bardziej wydajne wykorzystanie wirtualnych jednostek centralnych (vCPU) na każdej maszynie wirtualnej oraz zwiększa wydajność.
- Nie wszystkie podstawowe fragmenty usługi Redis znajdują się na tej samej maszynie wirtualnej/węźle. Zamiast tego fragmenty podstawowe i repliki są rozproszone pomiędzy oboma węzłami. Ponieważ podstawowe fragmenty używają więcej zasobów procesora NIŻ fragmenty repliki, takie podejście umożliwia równoległe uruchamianie większej liczby podstawowych fragmentów.
- Każdy węzeł ma wysokowydajny proces proxy do zarządzania fragmentami, zarządzania połączeniami i uruchamiania samoleczenia.
Ta architektura umożliwia zarówno wyższą wydajność, jak i zaawansowane funkcje, takie jak aktywna replikacja geograficzna.
Klastrowanie
Każde wystąpienie usługi Azure Managed Redis jest wewnętrznie skonfigurowane do używania klastrowania we wszystkich warstwach i jednostkach SKU. Usługa Azure Managed Redis jest oparta na usłudze Redis Enterprise, która może używać wielu fragmentów na węzeł. Ta funkcja obejmuje mniejsze instancje, które są skonfigurowane tylko do używania pojedynczego sharda. Klastrowanie to sposób dzielenia danych w instancji Redis na wiele procesów Redis, co jest również nazywane fragmentowaniem. Usługa Azure Managed Redis oferuje trzy polityki klastra, które określają, który protokół jest dostępny dla klientów Redis do nawiązywania połączenia z wystąpieniem pamięci podręcznej.
Zasady klastra
Usługa Azure Managed Redis oferuje trzy zasady klastrowania: OSS, Enterprise i nieklasterowany. Zasady klastra systemu operacyjnego są dobre dla większości aplikacji, ponieważ obsługują wyższą maksymalną przepływność, ale każda wersja ma własne zalety i wady.
- Jeśli przenosisz się z topologii podstawowej, standardowej lub Premium, która nie jest klastrowana, rozważ użycie klastrowania OSS (oprogramowania open-source) w celu zwiększenia wydajności. Używaj konfiguracji nieklastrowanych tylko wtedy, gdy aplikacja nie może obsługiwać topologii systemu operacyjnego lub przedsiębiorstwa. Zasady klastrowania systemu operacyjnego implementują ten sam interfejs API co oprogramowanie open source redis. Interfejs API klastra Redis umożliwia klientowi Redis bezpośrednie łączenie się z fragmentami w każdym węźle usługi Redis, minimalizując opóźnienie i optymalizując przepływność sieci. Przepustowość skaluje się niemal liniowo wraz ze wzrostem liczby fragmentów i wirtualnych procesorów. Zasady klastrowania systemu operacyjnego zazwyczaj oferują najmniejsze opóźnienia i najlepszą wydajność przepływności. Jednak zasady klastra systemu operacyjnego wymagają biblioteki klienta do obsługi interfejsu API klastra Redis. Obecnie prawie wszyscy klienci usługi Redis obsługują interfejs API klastra Redis, ale zgodność może być problemem ze starszymi wersjami klienta lub wyspecjalizowanymi bibliotekami.
Nie można używać zasad klastrowania systemu operacyjnego z modułem RediSearch.
Protokół klastrowania OSS wymaga, aby klient nawiązał poprawne połączenia shardów. Początkowe połączenie odbywa się za pośrednictwem portu 10000. Łączenie się z poszczególnymi węzłami odbywa się przez porty w zakresie 85XX. Porty 85xx mogą się zmieniać w czasie i nie należy kodować ich na stałe w aplikacji. Klienci usługi Redis, którzy obsługują klastrowanie, używają polecenia CLUSTER NODES, aby określić dokładne porty używane dla podstawowych i replikowych fragmentów oraz nawiązać połączenia z fragmentami.
Zasady klastrowania przedsiębiorstwa to prostsza konfiguracja, która używa pojedynczego punktu końcowego dla wszystkich połączeń klientów. W przypadku korzystania z zasad klastrowania przedsiębiorstwa kieruje wszystkie żądania do pojedynczego węzła usługi Redis, który działa jako serwer proxy. Ten węzeł wewnętrznie kieruje żądania do poprawnego węzła w klastrze. Zaletą tego podejścia jest to, że usługa Azure Managed Redis wygląda bez klastrowania dla użytkowników. Oznacza to, że biblioteki klienckie usługi Redis nie muszą obsługiwać klastrowania Redis, aby uzyskać niektóre zalety wydajności usługi Redis Enterprise. Korzystanie z jednego punktu końcowego zwiększa zgodność z poprzednimi wersjami i upraszcza połączenie. Wadą jest to, że proxy z pojedynczym węzłem może być wąskim gardłem w przypadku wykorzystania zasobów obliczeniowych lub przepustowości sieci.
Zasady klastrowania przedsiębiorstwa to jedyna, której można używać z modułem RediSearch. Chociaż polityka klastra Enterprise powoduje, że instancja Azure Managed Redis wydaje się nie być klastrowana dla użytkowników, nadal ma pewne ograniczenia w przypadku komend wielokluczowych.
Polityka klastrowania Non-Clustered przechowuje dane w każdym węźle bez fragmentowania. Dotyczy tylko pamięci podręcznych o rozmiarze 25 GB i mniejszych. Scenariusze używania zasad klastrowania nieklastrowanego obejmują:
- Podczas migracji ze środowiska Redis, które nie jest podzielone na fragmenty. Na przykład nieuhardowane topologie jednostek SKU w warstwie Podstawowa, Standardowa i Premium usługi Azure Cache for Redis.
- Podczas częstego uruchamiania poleceń krzyżujących sloty i dzielenia danych na fragmenty mogą wystąpić błędy. Na przykład komendy MULTI.
- Podczas używania usługi Redis jako brokera komunikatów i bez potrzeby fragmentacji.
Zagadnienia dotyczące używania zasad nieklastrowanych są następujące:
- Te zasady dotyczą tylko warstw usługi Azure Managed Redis, które są mniejsze lub równe 25 GB.
- Nie jest tak wydajne, jak inne zasady klastrowania, ponieważ procesory CPU mogą korzystać z wielowątkowości tylko z oprogramowaniem Redis Enterprise, gdy pamięć podręczna jest dzielona na fragmenty.
- Jeśli chcesz zwiększyć skalę pamięci podręcznej Azure Managed Redis Cache, musisz najpierw zmienić zasady klastra.
- Jeśli przenosisz się z topologii Basic, Standard lub Premium, rozważ skorzystanie z klastrów OSS w celu zwiększenia wydajności. Używaj konfiguracji nieklastrowanych tylko wtedy, gdy aplikacja nie może obsługiwać topologii systemu operacyjnego lub przedsiębiorstwa.
Skalowanie w górę lub dodawanie węzłów
Podstawowe oprogramowanie Redis Enterprise skaluje się w górę poprzez użycie większych maszyn wirtualnych lub skaluje się w poziomie przez dodanie większej liczby węzłów lub maszyn wirtualnych. Obie opcje skalowania dodają więcej pamięci, więcej procesorów wirtualnych i więcej fragmentów. Ze względu na tę nadmiarowość usługa Azure Managed Redis nie zapewnia możliwości kontrolowania określonej liczby węzłów używanych w każdej konfiguracji. Ten szczegół implementacji jest abstrakcyjny, aby uniknąć nieporozumień, złożoności i nieoptymalnych konfiguracji. Zamiast tego każde SKU jest zaprojektowane z konfiguracją węzła, która maksymalizuje vCPU i pamięć. Niektóre jednostki SKU usługi Azure Managed Redis używają dwóch węzłów, a inne używają więcej.
Polecenia wieloklawiszowe
Ponieważ wystąpienia usługi Azure Managed Redis używają konfiguracji klastrowanej, mogą być widoczne CROSSSLOT wyjątki w poleceniach, które działają na wielu kluczach. Zachowanie różni się w zależności od używanych zasad klastrowania. Jeśli używasz zasad klastrowania OSS, wszystkie klucze w poleceniach wielokluczowych muszą być zmapowane na ten sam slot skrótu.
Mogą również występować błędy CROSSSLOT związane z zasadami klastrowania przedsiębiorstwa. Tylko następujące polecenia wieloklucze są dozwolone w różnych gniazdach z klastrowaniem Enterprise: DEL, MSET, MGET, EXISTS, UNLINK, i TOUCH.
W bazach danych Active-Active, polecenia zapisu dla wielu kluczy (DEL, MSET, UNLINK) mogą być uruchamiane tylko na kluczach, które znajdują się w tym samym slocie. Jednak następujące polecenia wielokluczowe są dozwolone w różnych slotach w bazach danych Active-Active: MGET, EXISTS, i TOUCH. Aby uzyskać więcej informacji, zobacz Klastrowanie baz danych.
Konfiguracja fragmentowania
Każda jednostka SKU usługi Azure Managed Redis uruchamia określoną liczbę procesów serwera Redis, nazywanych segmentami, równolegle. Relacja między wydajnością przepustowości, liczbą fragmentów a liczbą wirtualnych rdzeni CPU dostępnych w każdym wystąpieniu jest złożona. Nie można ręcznie zmienić liczby fragmentów.
W przypadku danego rozmiaru pamięci zoptymalizowana pod kątem pamięci wersja ma najmniejszą liczbę procesorów wirtualnych i fragmentów, podczas gdy wersja zoptymalizowana pod kątem obliczeń ma najwyższą liczbę.
Zwiększenie liczby fragmentów zwykle zwiększa wydajność, ponieważ operacje Redis mogą być uruchamiane równolegle. Jeśli jednak do wykonywania poleceń nie są dostępne żadne procesory wirtualne, wydajność może spaść.
Fragmenty są mapowane w celu zoptymalizowania użycia każdego vCPU, jednocześnie rezerwując cykle vCPU dla procesu serwera Redis, agenta zarządzania i zadań systemu operacyjnego, które również wpływają na wydajność. Tworzone aplikacje klienckie współdziałają z usługą Azure Managed Redis tak, jakby była to pojedyncza logiczna baza danych. Usługa obsługuje routing między procesorami wirtualnymi i fragmentami.
Aby zwiększyć liczbę fragmentów w jednostce SKU, użyj większej warstwy w tej jednostce SKU. Możesz również zmienić jednostki SKU, aby odpowiadały potrzebom w zakresie wydajności.
W poniższej tabeli przedstawiono stosunek vCPU do podstawowych shardów na danym poziomie warstwy. Dane w kolumnach nie reprezentują gwarancji, że jest to liczba procesorów wirtualnych lub fragmentów. Tabele są przeznaczone tylko dla ilustracji.
Uwaga / Notatka
Usługa Azure Managed Redis optymalizuje wydajność w czasie, zmieniając liczbę fragmentów i procesorów wirtualnych używanych w każdej jednostce SKU.
Zoptymalizowane pod kątem pamięci, zrównoważone i zoptymalizowane pod kątem obliczeń wersje
W tej tabeli przedstawiono ogólny przykład związku pomiędzy rozmiarem a wirtualnymi procesorami/podstawowymi odłamkami.
| Poziomy | Zoptymalizowana pamięć | Zrównoważone | Zoptymalizowany pod obliczenia |
|---|---|---|---|
| Rozmiar (GB) | Procesory wirtualne/podstawowe fragmenty | Procesory wirtualne/podstawowe fragmenty | Procesory wirtualne/podstawowe fragmenty |
| 24 ¹ | 4/2 | 8/6 | 16.12 |
| 60 ¹ | 8/6 | 16.12 | 32/24 |
¹ Stosunek vCPU do podstawowych shardów przy danym rozmiarze warstwy nie stanowi gwarancji dla SKU ani warstwy.
Wersja zoptymalizowana pod kątem flash
W tej tabeli przedstawiono ogólny przykład zależności między Rozmiarem a procesorami wirtualnymi/podstawowymi fragmentami.
| Poziomy | Zoptymalizowane dla pamięci flash (przegląd) |
|---|---|
| Rozmiar (GB) | Procesory wirtualne/podstawowe fragmenty |
| 480 ¹ ² | 16.12 |
| 720 ¹ ² | 24/24 |
¹ Te warstwy są dostępne w publicznej wersji zapoznawczej.
² Stosunek procesorów wirtualnych do podstawowych fragmentów w danym rozmiarze warstwy nie reprezentuje gwarancji dla jednostki SKU lub warstwy.
Ważne
Wszystkie warstwy w pamięci korzystające z ponad 235 GB miejsca do magazynowania są dostępne w publicznej wersji zapoznawczej, w tym zoptymalizowane pod kątem pamięci M350 i nowsze; Zrównoważony B350 i wyższy; i zoptymalizowane pod kątem obliczeń X350 i nowsze. Wszystkie te warstwy i wyższe są dostępne w publicznej wersji zapoznawczej.
Wszystkie warstwy zoptymalizowane pod kątem technologii Flash są w publicznej wersji zapoznawczej.
Uruchamianie bez włączonego trybu wysokiej dostępności
Można uruchomić system bez włączonego trybu wysokiej dostępności. Ta konfiguracja oznacza, że Twoja instancja Redis nie ma włączonej replikacji i nie ma dostępu do SLA dostępności. Nie uruchamiaj w trybie nie-HA poza scenariuszami rozwoju i testowania. Nie można wyłączyć wysokiej dostępności w instancji, którą już utworzono. Możesz włączyć wysoką dostępność w wystąpieniu, które go nie ma. Ponieważ wystąpienie działające bez wysokiej dostępności korzysta z mniejszej liczby maszyn wirtualnych i węzłów, vCPU nie są używane efektywnie, więc wydajność może być niższa.
Pamięć zarezerwowana
W każdym wystąpieniu usługi Azure Managed Redis około 20% dostępnej pamięci jest zarezerwowane jako bufor dla operacji niebuforowych, takich jak replikacja w trybie failover i bufor aktywnej replikacji geograficznej. Ten bufor pomaga zwiększyć wydajność pamięci podręcznej i zapobiegać głodowaniu pamięci.
Zmniejszanie
Skalowanie w dół nie jest obecnie obsługiwane w usłudze Azure Managed Redis. Aby uzyskać więcej informacji, zobacz Ograniczenia skalowania usługi Azure Managed Redis.
Warstwa zoptymalizowana dla flash
Warstwa zoptymalizowana dla pamięci flash korzysta zarówno z magazynu flash NVMe, jak i pamięci RAM. Ponieważ magazyn flash jest tańszy, użycie warstwy zoptymalizowanej pod kątem Flash pozwala na kompromis między wydajnością a efektywnością kosztową.
W przypadku instancji zoptymalizowanych pod kątem Flash 20% miejsca w pamięci podręcznej znajduje się w pamięci RAM, a pozostałe 80% używa pamięci Flash. Wszystkie klucze są przechowywane w pamięci RAM, podczas gdy wartości mogą być przechowywane w magazynie flash lub pamięci RAM. Oprogramowanie Redis inteligentnie określa lokalizację wartości. Gorące wartości, do których często uzyskuje się dostęp, są przechowywane w pamięci RAM, podczas gdy wartości zimne , które są rzadziej używane, są przechowywane w pamięci Flash. Zanim dane zostaną odczytane lub zapisane, należy przenieść je do pamięci RAM, stając się gorącymi danymi.
Ponieważ Redis optymalizuje wydajność, instancja najpierw wypełnia dostępną pamięć RAM przed dodaniem elementów do pamięci Flash. Wypełnienie pamięci RAM najpierw ma kilka konsekwencji dla wydajności:
- Można osiągnąć lepszą wydajność i mniejsze opóźnienia podczas testowania przy niskim użyciu pamięci. Testowanie z pełną instancją pamięci podręcznej może przynieść słabszą wydajność, ponieważ w fazie testowania przy niskim wykorzystaniu pamięci jest używana tylko pamięć RAM.
- Podczas zapisywania większej ilości danych w pamięci podręcznej odsetek danych w pamięci RAM w porównaniu z pamięcią Flash spada, zazwyczaj powodując spadek opóźnienia i wydajności przepływności.
Obciążenia odpowiednie dla zoptymalizowanej pod kątem technologii flash warstwy
Obciążenia, które działają dobrze w warstwie Flash Optimized, często mają następujące cechy:
- Odczyt jest ciężki, z wysokim współczynnikiem poleceń odczytu do zapisu poleceń.
- Dostęp koncentruje się na podzestawie kluczy, których używasz znacznie częściej niż reszta zestawu danych.
- Stosunkowo duże wartości w porównaniu do nazw kluczowych. (Ponieważ nazwy kluczy są zawsze przechowywane w pamięci RAM, duże wartości mogą powodować ograniczenia w rozwoju pamięci).
Obciążenia, które nie są odpowiednie dla warstwy zoptymalizowanej pod kątem pamięci flash
Niektóre obciążenia mają cechy dostępu, które są mniej zoptymalizowane pod kątem projektowania warstwy zoptymalizowanej dla technologii Flash.
- Wykonywanie dużych obciążeń.
- Losowe lub jednolite wzorce dostępu do danych w większości zestawu danych.
- Długie nazwy kluczy o stosunkowo małych rozmiarach.