Tworzenie niestandardowego modelu analizy obrazów
Ważne
Ta funkcja jest teraz przestarzała. 10 stycznia 2025 r. zostanie wycofana usługa Azure AI Image Analysis 4.0 Custom Image Classification, Custom Object Detection i Product Recognition (wersja zapoznawcza). Po tej dacie wywołania interfejsu API do tych usług nie powiedzą się.
Aby zapewnić bezproblemową obsługę modeli, przejdź do usługi Azure AI Custom Vision, która jest teraz ogólnie dostępna. Usługa Custom Vision oferuje podobne funkcje do tych funkcji wycofywania.
Usługa Image Analysis 4.0 umożliwia trenowanie modelu niestandardowego przy użyciu własnych obrazów szkoleniowych. Ręcznie oznaczając obrazy, możesz wytrenować model, aby zastosować tagi niestandardowe do obrazów (klasyfikacja obrazów) lub wykryć obiekty niestandardowe (wykrywanie obiektów). Modele analizy obrazów 4.0 są szczególnie skuteczne w przypadku uczenia przy użyciu kilku strzałów , dzięki czemu można uzyskać dokładne modele z mniejszymi danymi treningowymi.
W tym przewodniku pokazano, jak utworzyć i wytrenować niestandardowy model klasyfikacji obrazów. Zanotowano kilka różnic między trenowaniem modelu klasyfikacji obrazów a modelem wykrywania obiektów.
Uwaga
Dostosowywanie modelu jest dostępne za pośrednictwem interfejsu API REST i programu Vision Studio, ale nie za pośrednictwem zestawów SDK języka klienta.
Wymagania wstępne
- Subskrypcja platformy Azure. Możesz utworzyć go bezpłatnie.
- Po utworzeniu subskrypcji platformy Azure utwórz zasób usługi Vision w witrynie Azure Portal, aby uzyskać klucz i punkt końcowy. Jeśli korzystasz z tego przewodnika przy użyciu programu Vision Studio, musisz utworzyć zasób w regionie Wschodnie stany USA. Po wdrożeniu wybierz pozycję Przejdź do zasobu. Skopiuj klucz i punkt końcowy do lokalizacji tymczasowej do późniejszego użycia.
- Zasób usługi Azure Storage. Utwórz zasób magazynu.
- Zestaw obrazów do trenowania modelu klasyfikacji. Możesz użyć zestawu przykładowych obrazów w usłudze GitHub. Możesz też użyć własnych obrazów. Potrzebujesz tylko około 3–5 obrazów na klasę.
Uwaga
Nie zalecamy używania modeli niestandardowych w środowiskach krytycznych dla działania firmy ze względu na potencjalne duże opóźnienie. Gdy klienci szkolą modele niestandardowe w programie Vision Studio, te modele niestandardowe należą do zasobu przetwarzania obrazów, w ramach którego zostali przeszkoleni, a klient może wykonywać wywołania tych modeli przy użyciu interfejsu API analizowania obrazów . Podczas wykonywania tych wywołań model niestandardowy jest ładowany do pamięci, a infrastruktura przewidywania jest inicjowana. W takim przypadku klienci mogą doświadczać dłuższych niż oczekiwano opóźnień, aby otrzymywać wyniki przewidywania.
Tworzenie nowego modelu niestandardowego
Zacznij od wybrania karty Analiza obrazów w programie Vision Studio. Następnie wybierz kafelek Dostosuj modele.
Następnie zaloguj się przy użyciu konta platformy Azure i wybierz zasób usługi Vision. Jeśli go nie masz, możesz go utworzyć na tym ekranie.

Przygotowywanie obrazów treningowych
Musisz przekazać obrazy szkoleniowe do kontenera usługi Azure Blob Storage. Przejdź do zasobu magazynu w witrynie Azure Portal i przejdź do karty Przeglądarka magazynu. W tym miejscu możesz utworzyć kontener obiektów blob i przekazać obrazy. Umieść je wszystkie w katalogu głównym kontenera.
Dodawanie zestawu danych
Aby wytrenować model niestandardowy, musisz skojarzyć go z zestawem danych , w którym podajesz obrazy i ich informacje o etykiecie jako dane szkoleniowe. W programie Vision Studio wybierz kartę Zestawy danych, aby wyświetlić zestawy danych.
Aby utworzyć nowy zestaw danych, wybierz pozycję Dodaj nowy zestaw danych. W oknie podręcznym wprowadź nazwę i wybierz typ zestawu danych dla danego przypadku użycia. Modele klasyfikacji obrazów stosują etykiety zawartości do całego obrazu, a modele wykrywania obiektów stosują etykiety obiektów do określonych lokalizacji na obrazie. Modele rozpoznawania produktów to podkategoria modeli wykrywania obiektów zoptymalizowanych pod kątem wykrywania produktów detalicznych.

Następnie wybierz kontener z konta usługi Azure Blob Storage, na którym są przechowywane obrazy szkoleniowe. Zaznacz pole wyboru, aby umożliwić programowi Vision Studio odczytywanie i zapisywanie w kontenerze magazynu obiektów blob. Jest to krok niezbędny do zaimportowania danych oznaczonych etykietami. Utwórz zestaw danych.
Tworzenie projektu etykietowania usługi Azure Machine Learning
Potrzebujesz pliku COCO, aby przekazać informacje o etykietowaniu. Łatwym sposobem wygenerowania pliku COCO jest utworzenie projektu usługi Azure Machine Learning, który jest dostarczany z przepływem pracy etykietowania danych.
Na stronie szczegółów zestawu danych wybierz pozycję Dodaj nowy projekt etykietowania danych. Nadaj mu nazwę i wybierz pozycję Utwórz nowy obszar roboczy. Spowoduje to otwarcie nowej karty witryny Azure Portal, na której można utworzyć projekt usługi Azure Machine Learning.

Po utworzeniu projektu usługi Azure Machine Learning wróć do karty Vision Studio i wybierz go w obszarze Obszar roboczy. Portal usługi Azure Machine Learning zostanie otwarty na nowej karcie przeglądarki.
Tworzenie etykiet
Aby rozpocząć etykietowanie, postępuj zgodnie z monitem Dodaj klasy etykiet, aby dodać klasy etykiet.


Po dodaniu wszystkich etykiet klas zapisz je, wybierz pozycję Rozpocznij w projekcie, a następnie wybierz pozycję Etykieta danych u góry.

Ręczne etykietowanie danych treningowych
Wybierz pozycję Rozpocznij etykietowanie i postępuj zgodnie z monitami, aby oznaczyć wszystkie obrazy. Po zakończeniu wróć do karty Vision Studio w przeglądarce.
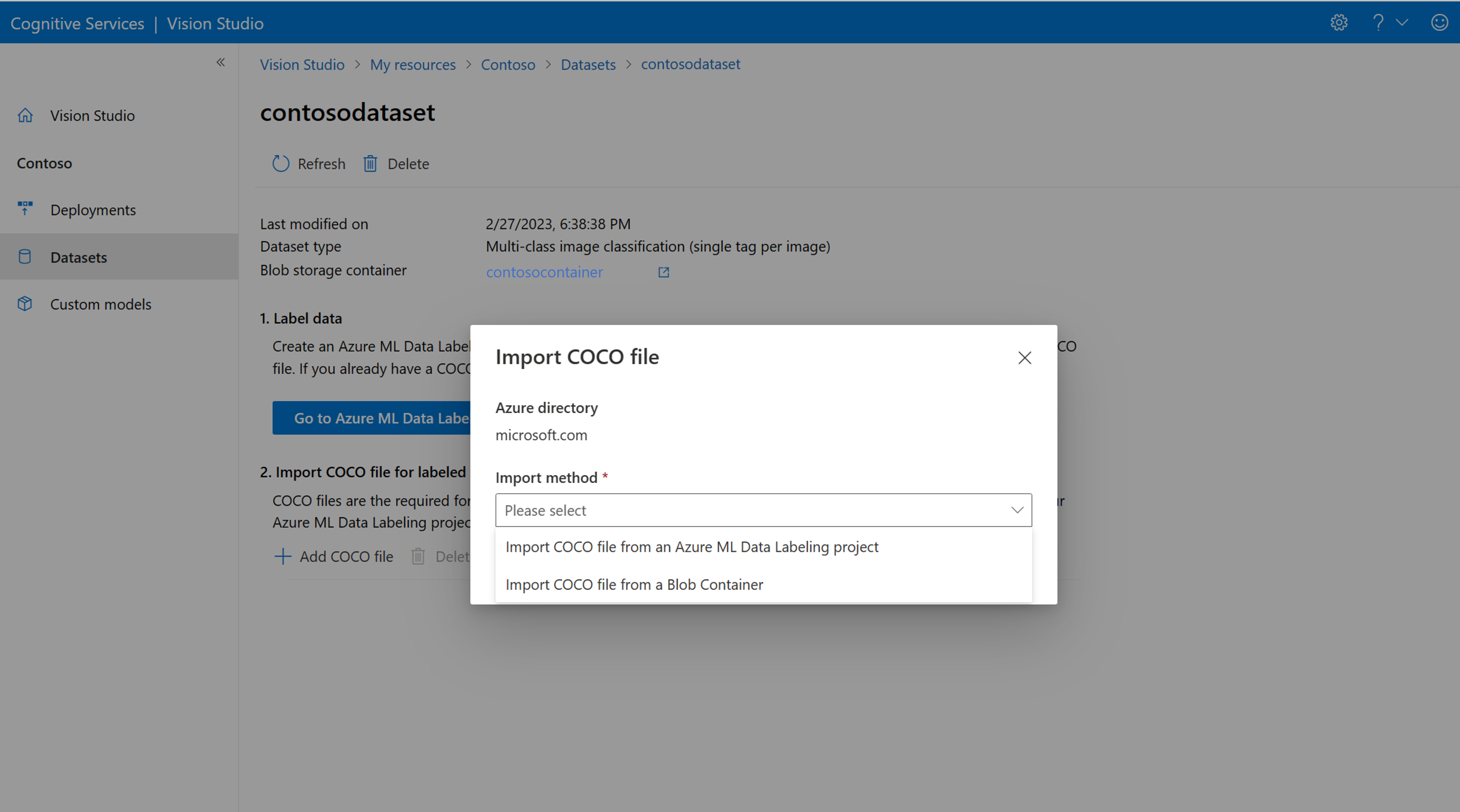
Teraz wybierz pozycję Dodaj plik COCO, a następnie wybierz pozycję Importuj plik COCO z projektu etykietowania danych usługi Azure ML. Spowoduje to zaimportowanie danych oznaczonych etykietą z usługi Azure Machine Learning.
Utworzony plik COCO jest teraz przechowywany w kontenerze usługi Azure Storage połączonym z tym projektem. Teraz możesz zaimportować go do przepływu pracy dostosowywania modelu. Wybierz ją z listy rozwijanej. Po zaimportowaniu pliku COCO do zestawu danych zestaw danych może służyć do trenowania modelu.
Uwaga
Jeśli masz gotowy plik COCO, który chcesz zaimportować, przejdź do karty Zestawy danych i wybierz pozycję Dodaj pliki COCO do tego zestawu danych. Możesz dodać określony plik COCO z konta magazynu obiektów blob lub zaimportować go z projektu etykietowania usługi Azure Machine Learning.
Obecnie firma Microsoft rozwiązała problem powodujący niepowodzenie importowania plików COCO z dużymi zestawami danych podczas inicjowania w programie Vision Studio. Aby wytrenować przy użyciu dużego zestawu danych, zaleca się użycie interfejsu API REST.
Informacje o plikach COCO
Pliki COCO to pliki JSON z określonymi wymaganymi polami: "images", "annotations"i "categories". Przykładowy plik COCO będzie wyglądać następująco:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Dokumentacja pola pliku COCO
Jeśli generujesz własny plik COCO od podstaw, upewnij się, że wszystkie wymagane pola są wypełnione prawidłowymi szczegółami. W poniższych tabelach opisano każde pole w pliku COCO:
"obrazy"
| Klucz | Type | Opis | Wymagane? |
|---|---|---|---|
id |
integer | Unikatowy identyfikator obrazu, począwszy od 1 | Tak |
width |
integer | Szerokość obrazu w pikselach | Tak |
height |
integer | Wysokość obrazu w pikselach | Tak |
file_name |
string | Unikatowa nazwa obrazu | Tak |
absolute_url lub coco_url |
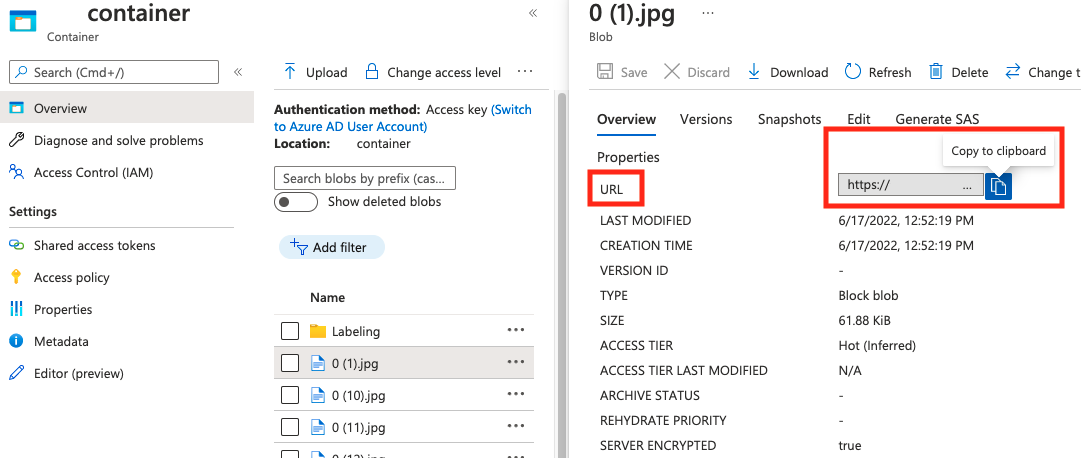
string | Ścieżka obrazu jako bezwzględny identyfikator URI do obiektu blob w kontenerze obiektów blob. Zasób przetwarzania obrazów musi mieć uprawnienia do odczytywania plików adnotacji i wszystkich plików obrazów, do których się odwołujesz. | Tak |
Wartość parametru absolute_url można znaleźć we właściwościach kontenera obiektów blob:
"Adnotacje"
| Klucz | Type | Opis | Wymagane? |
|---|---|---|---|
id |
integer | Identyfikator adnotacji | Tak |
category_id |
integer | Identyfikator kategorii zdefiniowanej categories w sekcji |
Tak |
image_id |
integer | Identyfikator obrazu | Tak |
area |
integer | Wartość wartości "Width" x "Height" (trzecie i czwarte wartości bbox) |
Nie. |
bbox |
list[float] | Współrzędne względne pola ograniczenia (od 0 do 1) w kolejności od "Lewa", "Góra", "Szerokość", "Wysokość" | Tak |
"kategorie"
| Klucz | Type | Opis | Wymagane? |
|---|---|---|---|
id |
integer | Unikatowy identyfikator dla każdej kategorii (klasa etykiety). Powinny one znajdować się w annotations sekcji . |
Tak |
name |
string | Nazwa kategorii (klasa etykiety) | Tak |
Weryfikacja pliku COCO
Możesz użyć naszego przykładowego kodu w języku Python, aby sprawdzić format pliku COCO.
Trenowanie modelu niestandardowego
Aby rozpocząć trenowanie modelu przy użyciu pliku COCO, przejdź do karty Modele niestandardowe i wybierz pozycję Dodaj nowy model. Wprowadź nazwę modelu i wybierz Image classification lub Object detection jako typ modelu.

Wybierz zestaw danych, który jest teraz skojarzony z plikiem COCO zawierającym informacje o etykietowaniu.
Następnie wybierz budżet czasu i wytrenuj model. W przypadku małych przykładów można użyć 1 hour budżetu.

Ukończenie szkolenia może zająć trochę czasu. Modele analizy obrazów 4.0 mogą być dokładne tylko przy użyciu tylko małego zestawu danych treningowych, ale trenowanie niż w poprzednich modelach trwa dłużej.
Ocena wytrenowanego modelu
Po zakończeniu trenowania można wyświetlić ocenę wydajności modelu. Używane są następujące metryki:
- Klasyfikacja obrazów: średnia precyzja, dokładność top 1, dokładność top 5
- Wykrywanie obiektów: średnia precyzja @ 30, średnia precyzja @ 50, średnia precyzja @ 75
Jeśli zestaw oceny nie zostanie podany podczas trenowania modelu, zgłoszona wydajność jest szacowana na podstawie części zestawu treningowego. Zdecydowanie zalecamy użycie zestawu danych oceny (przy użyciu tego samego procesu, co powyżej), aby uzyskać wiarygodne oszacowanie wydajności modelu.

Testowanie modelu niestandardowego w programie Vision Studio
Po utworzeniu modelu niestandardowego możesz przetestować, wybierając przycisk Wypróbuj na ekranie oceny modelu.

Spowoduje to przejście do strony Wyodrębnianie typowych tagów z obrazów . Wybierz model niestandardowy z menu rozwijanego i przekaż obraz testowy.

Wyniki przewidywania są wyświetlane w prawej kolumnie.
Powiązana zawartość
W tym przewodniku utworzono i wytrenujesz niestandardowy model klasyfikacji obrazów przy użyciu analizy obrazów. Następnie dowiedz się więcej na temat interfejsu API analizowania obrazu 4.0, aby można było wywołać model niestandardowy z aplikacji przy użyciu interfejsu REST.
- Pojęcia dotyczące dostosowywania modelu
- Wywoływanie interfejsu API analizowania obrazu