Szybki start: niestandardowa klasyfikacja tekstu
Skorzystaj z tego artykułu, aby rozpocząć tworzenie niestandardowego projektu klasyfikacji tekstu, w którym można trenować modele niestandardowe na potrzeby klasyfikacji tekstu. Model to oprogramowanie sztucznej inteligencji, które jest szkolone w celu wykonania określonego zadania. W przypadku tego systemu modele klasyfikują tekst i są szkolone przez uczenie się na podstawie oznakowanych danych.
Niestandardowa klasyfikacja tekstu obsługuje dwa typy projektów:
- Klasyfikacja pojedynczej etykiety — można przypisać pojedynczą klasę dla każdego dokumentu w zestawie danych. Na przykład skrypt filmowy można sklasyfikować tylko jako "Romans" lub "Komedia".
- Klasyfikacja wielu etykiet — można przypisać wiele klas dla każdego dokumentu w zestawie danych. Na przykład skrypt filmowy można sklasyfikować jako "Komedia" lub "Romans" i "Komedia".
W tym przewodniku Szybki start możesz użyć przykładowych zestawów danych udostępnionych do utworzenia klasyfikacji wieloeznakowej, w której można sklasyfikować skrypty filmów w co najmniej jednej kategorii lub użyć zestawu danych klasyfikacji pojedynczej etykiety, w którym można sklasyfikować abstrakcję artykułów naukowych w jednej ze zdefiniowanych domen.
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz jedną bezpłatnie.
Tworzenie nowego zasobu języka sztucznej inteligencji platformy Azure i konta usługi Azure Storage
Przed użyciem niestandardowej klasyfikacji tekstu należy utworzyć zasób języka sztucznej inteligencji platformy Azure, który zapewni poświadczenia potrzebne do utworzenia projektu i rozpoczęcia trenowania modelu. Potrzebne będzie również konto usługi Azure Storage, na którym można przekazać zestaw danych, który będzie używany do kompilowania modelu.
Ważne
Aby szybko rozpocząć pracę, zalecamy utworzenie nowego zasobu języka sztucznej inteligencji platformy Azure, wykonując kroki opisane w tym artykule. Wykonanie kroków opisanych w tym artykule pozwoli jednocześnie utworzyć zasób języka i konto magazynu, co jest łatwiejsze niż później.
Jeśli masz wcześniej istniejący zasób , którego chcesz użyć, musisz połączyć go z kontem magazynu.
Tworzenie nowego zasobu w witrynie Azure Portal
Przejdź do witryny Azure Portal, aby utworzyć nowy zasób języka sztucznej inteligencji platformy Azure.
W wyświetlonym oknie wybierz pozycję Niestandardowa klasyfikacja tekstu i niestandardowe rozpoznawanie nazwanych jednostek z funkcji niestandardowych. Wybierz pozycję Kontynuuj, aby utworzyć zasób w dolnej części ekranu.
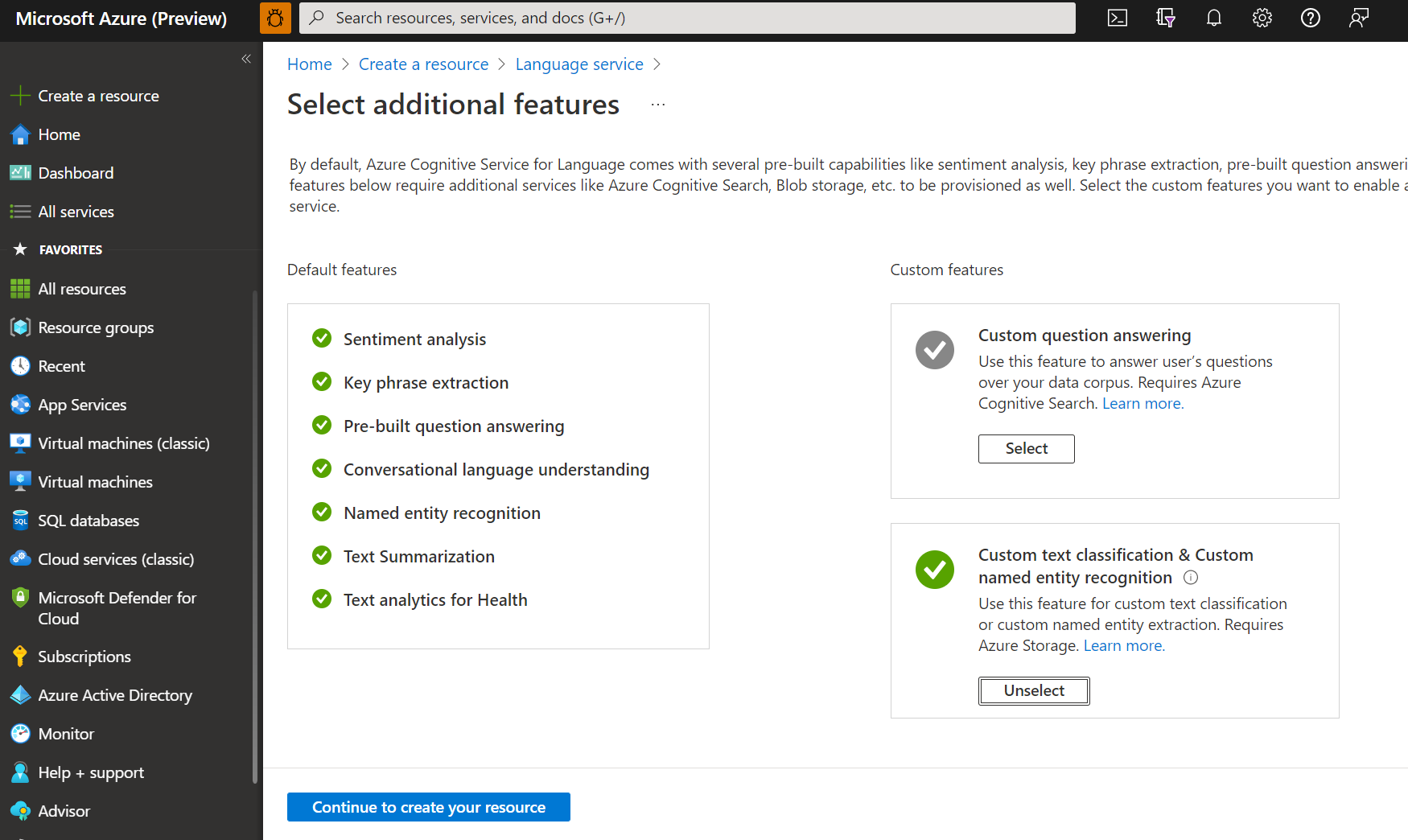
Utwórz zasób języka, postępując zgodnie z poniższymi szczegółami.
Nazwisko Wartość wymagana Subskrypcja Swoją subskrypcję platformy Azure. Grupa zasobów Grupa zasobów, która będzie zawierać zasób. Możesz użyć istniejącej lub utworzyć nową. Region (Region) Jeden z obsługiwanych regionów. Na przykład "Zachodnie stany USA 2". Nazwisko Nazwa zasobu. Warstwa cenowa Jedna z obsługiwanych warstw cenowych. Aby wypróbować usługę, możesz użyć warstwy Bezpłatna (F0). Jeśli zostanie wyświetlony komunikat "Twoje konto logowania nie jest właścicielem wybranej grupy zasobów konta magazynu", twoje konto musi mieć przypisaną rolę właściciela w grupie zasobów, zanim będzie można utworzyć zasób językowy. Skontaktuj się z właścicielem subskrypcji platformy Azure, aby uzyskać pomoc.
Możesz określić właściciela subskrypcji platformy Azure, wyszukując grupę zasobów i korzystając z linku do skojarzonej subskrypcji. Następnie:
- Wybierz kartę Kontrola dostępu (Zarządzanie dostępem i tożsamościami)
- Wybieranie przypisań ról
- Filtruj według roli:właściciel.
W sekcji Niestandardowa klasyfikacja tekstu i niestandardowe rozpoznawanie nazwanych jednostek wybierz istniejące konto magazynu lub wybierz pozycję Nowe konto magazynu. Należy pamiętać, że te wartości ułatwiają rozpoczęcie pracy, a niekoniecznie wartości konta magazynu, których chcesz użyć w środowiskach produkcyjnych. Aby uniknąć opóźnień podczas kompilowania projektu, połącz się z kontami magazynu w tym samym regionie co zasób języka.
Wartość konta magazynu Zalecana wartość Nazwa konta magazynu Dowolna nazwa Storage account type Standardowa LRS Upewnij się, że zaznaczono powiadomienie o odpowiedzialnej sztucznej inteligencji . Wybierz pozycję Przejrzyj i utwórz w dolnej części strony.

Przekazywanie przykładowych danych do kontenera obiektów blob
Po utworzeniu konta usługi Azure Storage i połączeniu go z zasobem Language należy przekazać dokumenty z przykładowego zestawu danych do katalogu głównego kontenera. Te dokumenty będą później używane do trenowania modelu.
Pobierz przykładowy zestaw danych dla projektów klasyfikacji z wieloma etykietami.
Otwórz plik .zip i wyodrębnij folder zawierający dokumenty.
Podany przykładowy zestaw danych zawiera około 200 dokumentów, z których każdy jest podsumowaniem filmu. Każdy dokument należy do co najmniej jednej z następujących klas:
- "Tajemnica"
- "Dramat"
- "Thriller"
- "Komedia"
- "Akcja"
W witrynie Azure Portal przejdź do utworzonego konta magazynu i wybierz je. Możesz to zrobić, klikając pozycję Konta magazynu i wpisując nazwę konta magazynu w polu Filtruj dla dowolnego pola.
Jeśli grupa zasobów nie jest wyświetlana, upewnij się, że filtr Subskrypcja równa się jest ustawiony na Wartość Wszystkie.
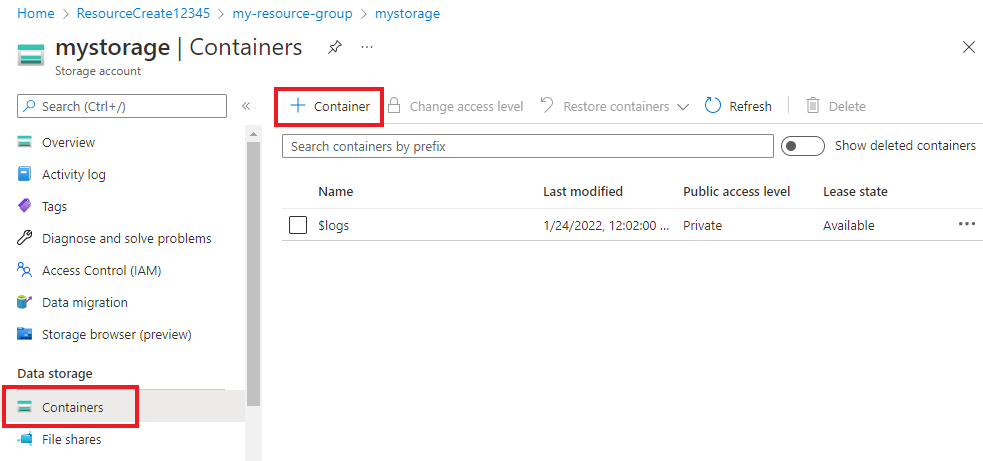
Na koncie magazynu wybierz pozycję Kontenery z menu po lewej stronie, znajdującym się poniżej obszaru Magazyn danych. Na wyświetlonym ekranie wybierz pozycję + Kontener. Nadaj kontenerowi nazwę example-data i pozostaw domyślny poziom dostępu publicznego.
Po utworzeniu kontenera wybierz go. Następnie wybierz przycisk Przekaż , aby wybrać
.txtpobrane wcześniej pliki i.json.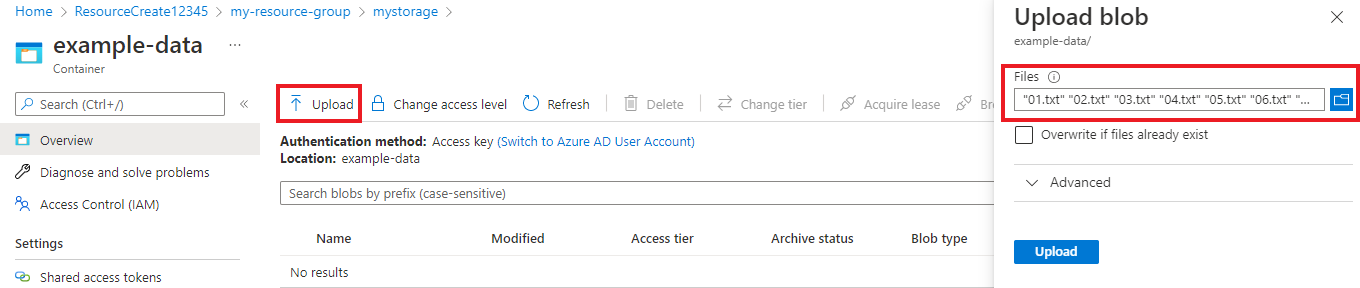


Tworzenie niestandardowego projektu klasyfikacji tekstu
Po skonfigurowaniu zasobu i kontenera magazynu utwórz nowy niestandardowy projekt klasyfikacji tekstu. Projekt to obszar roboczy umożliwiający tworzenie niestandardowych modeli uczenia maszynowego na podstawie danych. Dostęp do projektu można uzyskać tylko do Ciebie i innych osób, które mają dostęp do używanego zasobu Language.
Zaloguj się do programu Language Studio. Zostanie wyświetlone okno umożliwiające wybranie subskrypcji i zasobu językowego. Wybierz zasób języka.
W sekcji Klasyfikowanie tekstu w programie Language Studio wybierz pozycję Klasyfikacja tekstu niestandardowego.
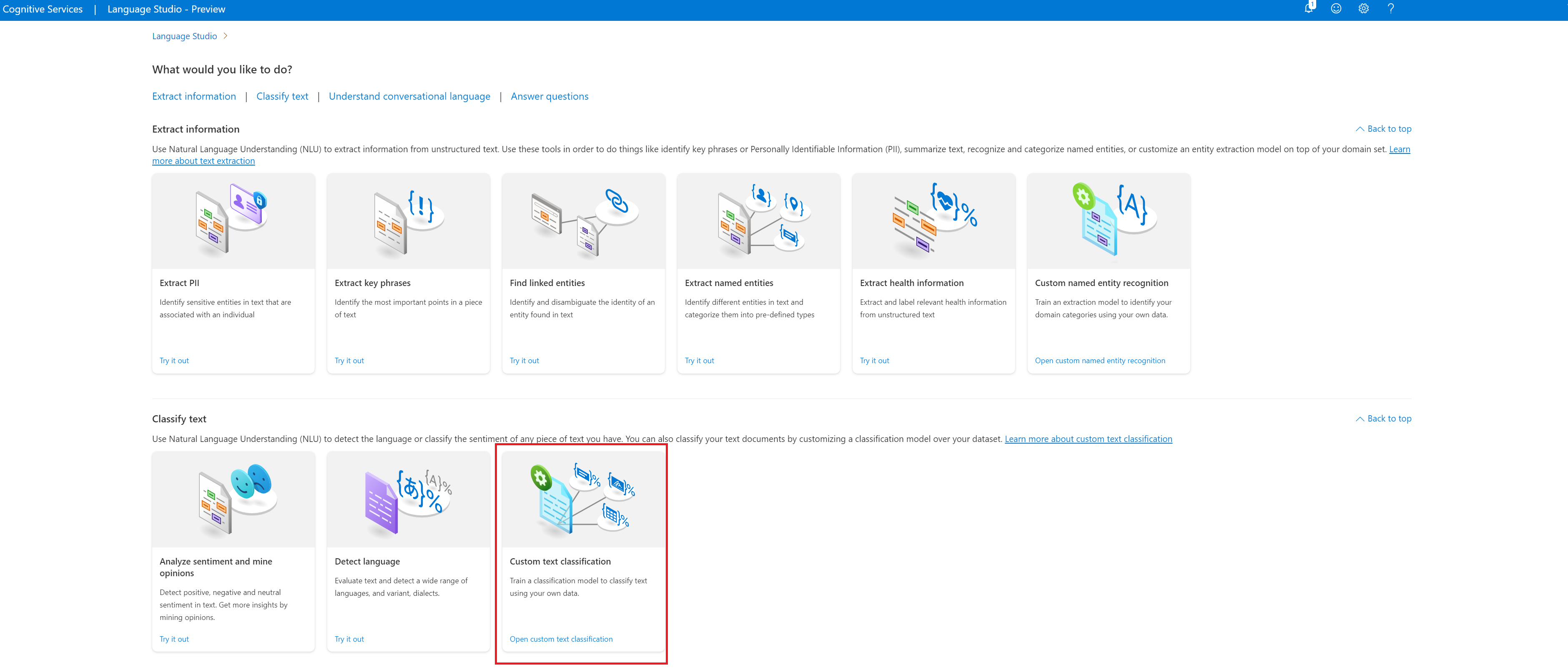
Wybierz pozycję Utwórz nowy projekt z górnego menu na stronie projektów. Utworzenie projektu umożliwi etykietowanie danych, trenowanie, ocenianie, ulepszanie i wdrażanie modeli.
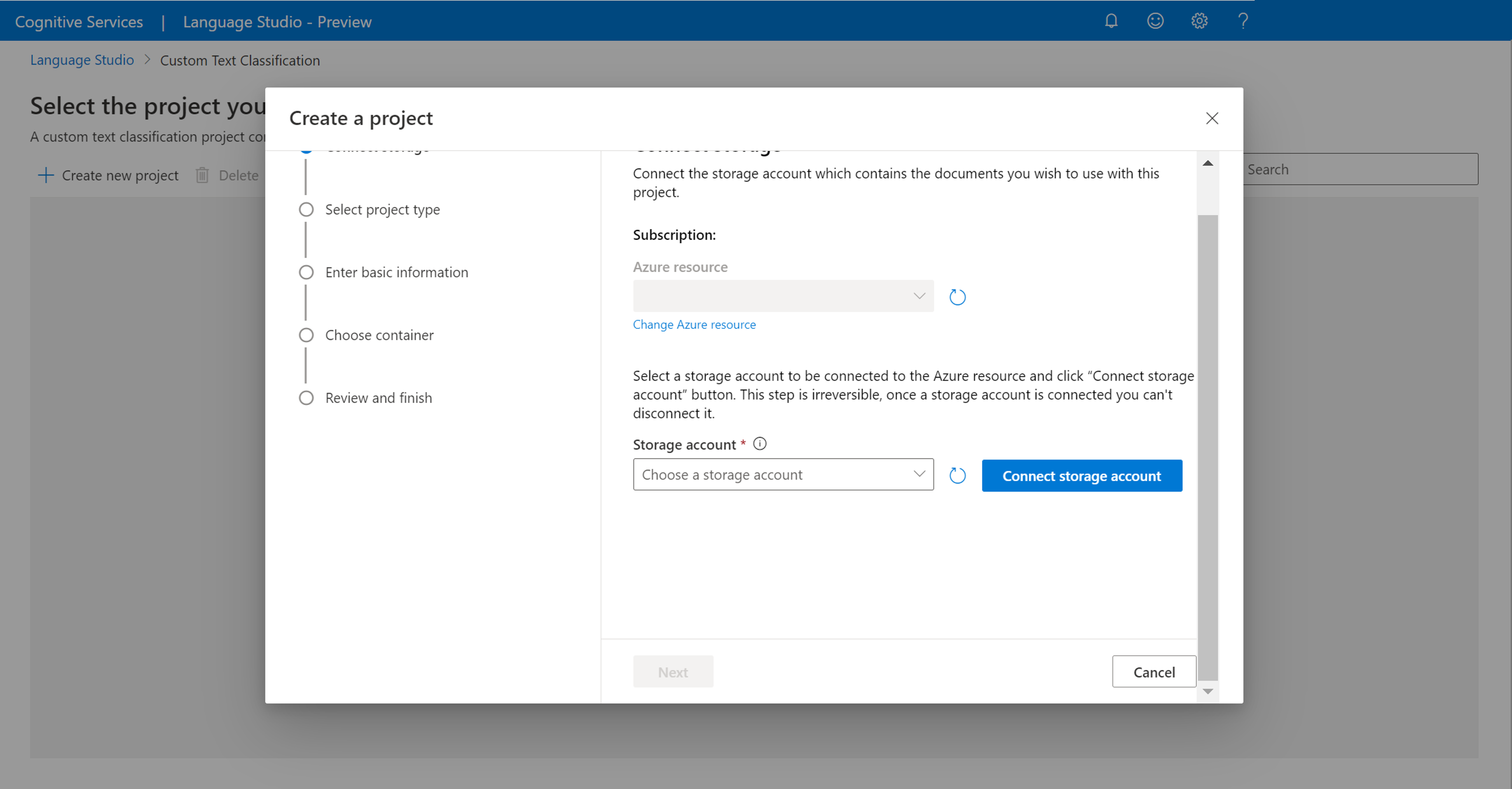
Po kliknięciu pozycji Utwórz nowy projekt zostanie wyświetlone okno umożliwiające nawiązanie połączenia z kontem magazynu. Jeśli masz już połączone konto magazynu, zobaczysz połączone konto magazynu. Jeśli nie, wybierz konto magazynu z wyświetlonej listy rozwijanej i wybierz pozycję Połącz konto magazynu. Spowoduje to ustawienie wymaganych ról dla konta magazynu. Ten krok może spowodować zwrócenie błędu, jeśli nie masz przypisanego jako właściciel konta magazynu.
Uwaga
- Ten krok należy wykonać tylko raz dla każdego nowego zasobu językowego, którego używasz.
- Ten proces jest nieodwracalny, jeśli połączysz konto magazynu z zasobem języka, nie możesz go odłączyć później.
- Zasób języka można połączyć tylko z jednym kontem magazynu.
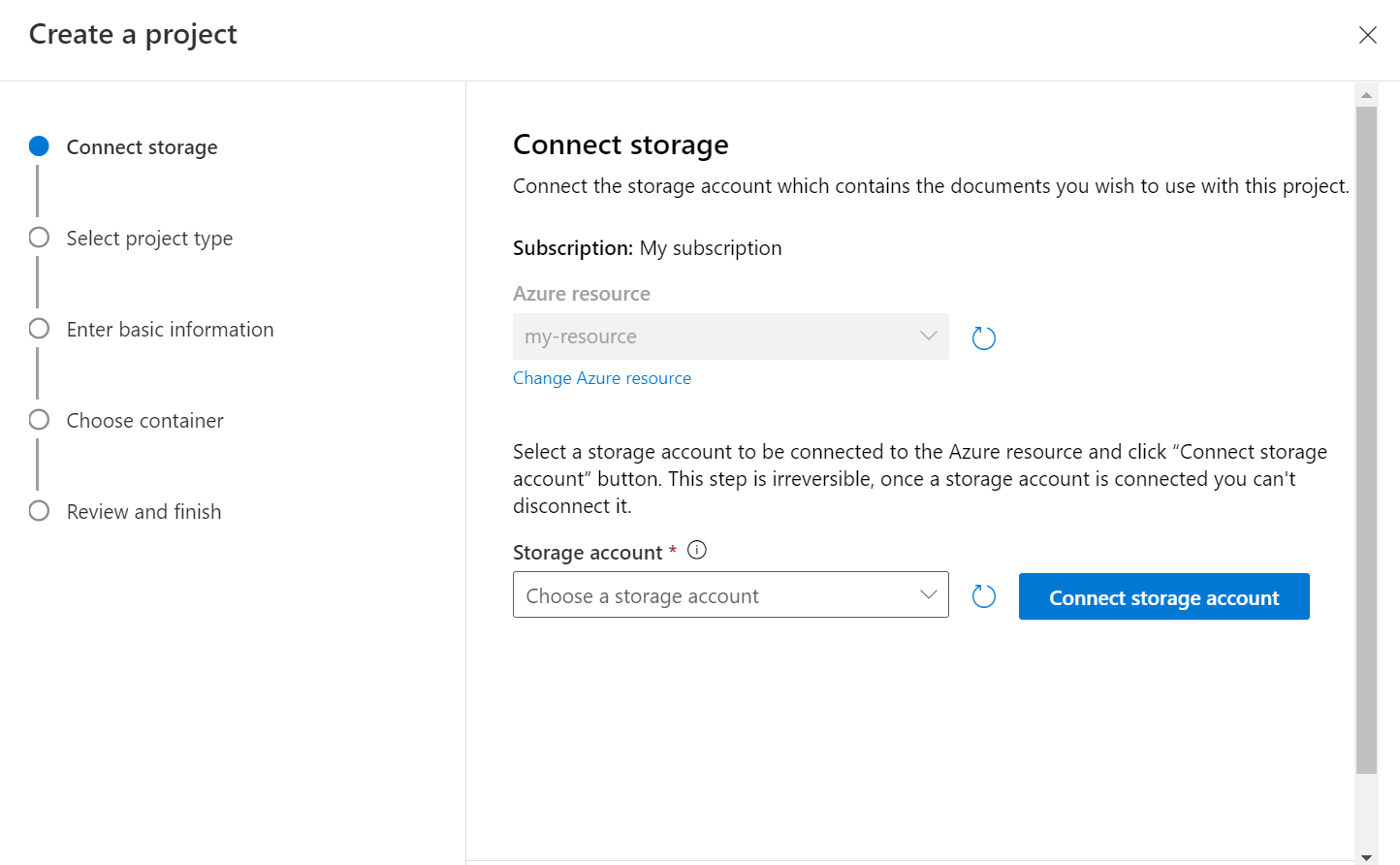
Wybierz typ projektu. Można utworzyć projekt klasyfikacji wielu etykiet, w którym każdy dokument może należeć do co najmniej jednej klasy lub projektu klasyfikacji pojedynczej etykiety, w którym każdy dokument może należeć tylko do jednej klasy. Nie można później zmienić wybranego typu. Dowiedz się więcej o typach projektów
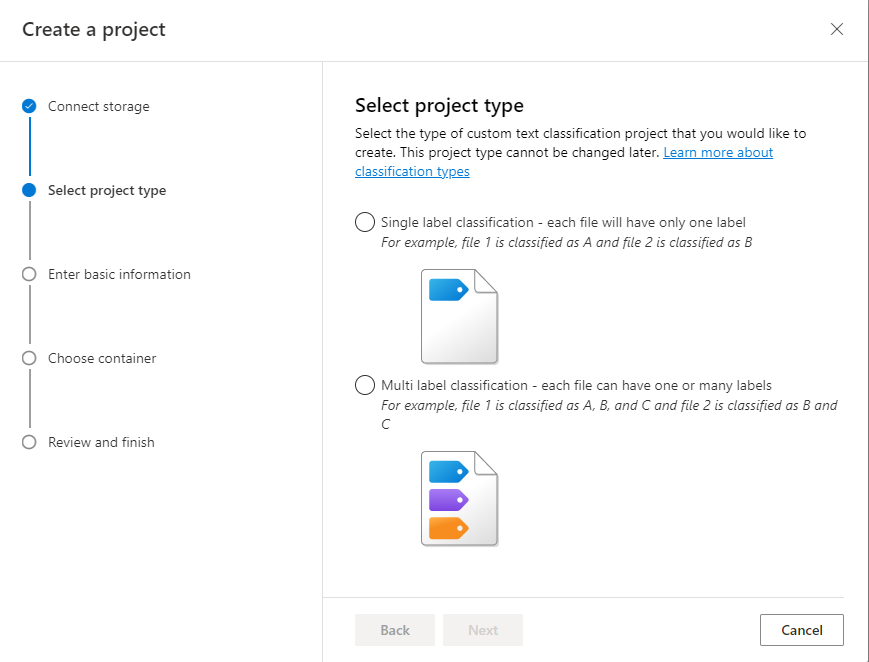
Wprowadź informacje o projekcie, w tym nazwę, opis i język dokumentów w projekcie. Jeśli używasz przykładowego zestawu danych, wybierz pozycję Angielski. Nie będzie można później zmienić nazwy projektu. Wybierz Dalej.
Napiwek
Zestaw danych nie musi być całkowicie w tym samym języku. Można mieć wiele dokumentów, z których każda ma różne obsługiwane języki. Jeśli zestaw danych zawiera dokumenty różnych języków lub jeśli oczekujesz tekstu z różnych języków w czasie wykonywania, wybierz opcję Włącz zestaw danych wielojęzyczny po wprowadzeniu podstawowych informacji dla projektu. Tę opcję można włączyć później na stronie Ustawienia projektu.
Wybierz kontener, w którym został przekazany zestaw danych.
Uwaga
Jeśli dane zostały już oznaczone etykietą, upewnij się, że jest on zgodny z obsługiwanym formatem i wybierz pozycję Tak, moje dokumenty są już oznaczone etykietami i sformatowane pliki etykiet JSON i wybierz plik etykiet z menu rozwijanego poniżej.
Jeśli używasz jednego z przykładowych zestawów danych, użyj dołączonego
webOfScience_labelsFilepliku lubmovieLabelsjson. Następnie kliknij przycisk Dalej.Przejrzyj wprowadzone dane i wybierz pozycję Utwórz projekt.




Szkolenie modelu
Zazwyczaj po utworzeniu projektu rozpoczynasz etykietowanie dokumentów , które masz w kontenerze połączonym z projektem. Na potrzeby tego przewodnika Szybki start zaimportowano przykładowy zestaw danych z etykietą i zainicjowano projekt przy użyciu przykładowego pliku etykiet JSON.
Aby rozpocząć trenowanie modelu z poziomu programu Language Studio:
Wybierz pozycję Zadania trenowania z menu po lewej stronie.
Wybierz pozycję Start a training job (Rozpocznij zadanie szkoleniowe) z górnego menu.
Wybierz pozycję Train a new model (Trenowanie nowego modelu ) i wpisz nazwę modelu w polu tekstowym. Możesz również zastąpić istniejący model , wybierając tę opcję i wybierając model, który chcesz zastąpić z menu rozwijanego. Zastępowanie wytrenowanego modelu jest nieodwracalne, ale nie wpłynie to na wdrożone modele do momentu wdrożenia nowego modelu.
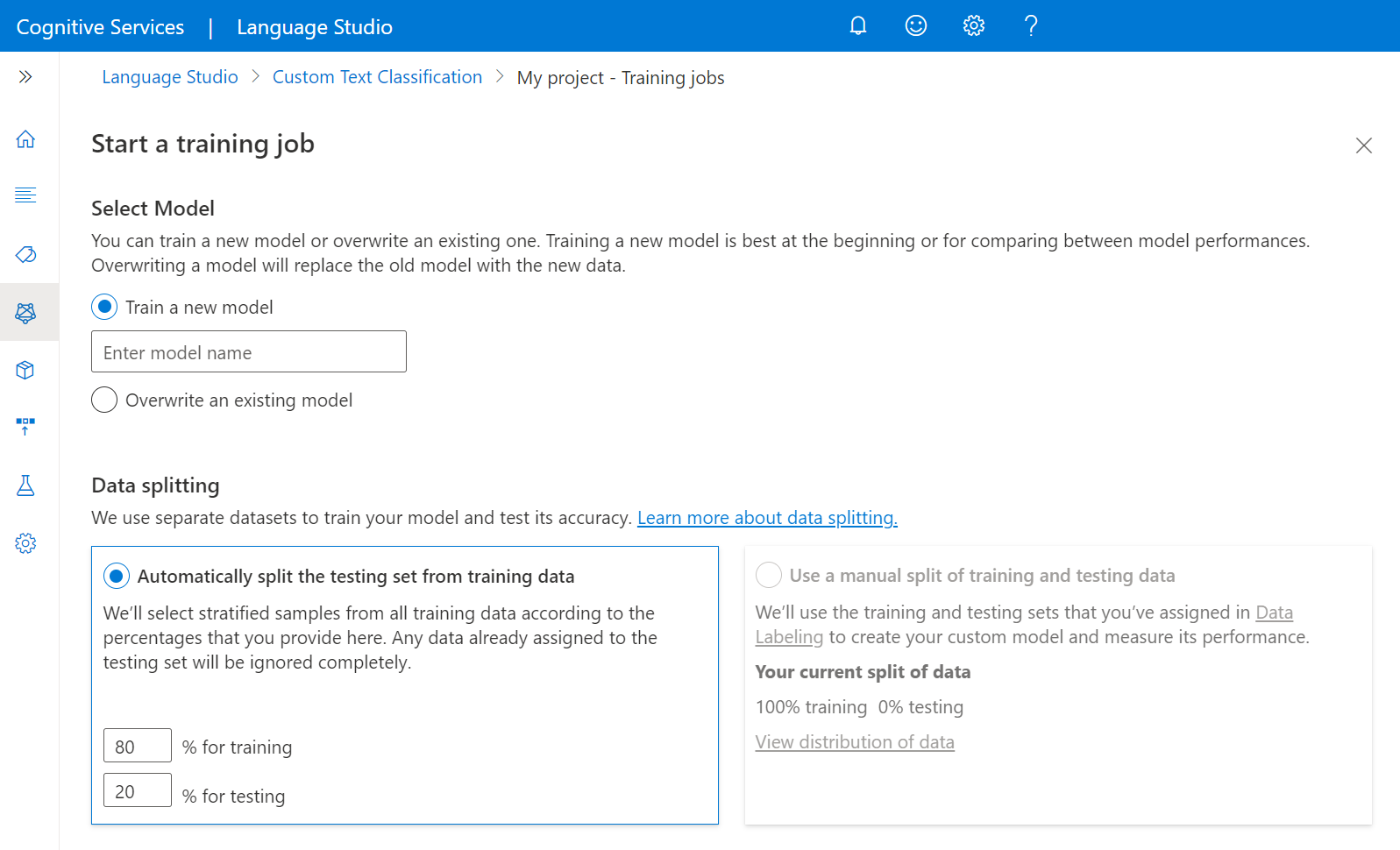
Wybierz metodę dzielenia danych. Możesz wybrać opcję Automatyczne dzielenie zestawu testów z danych treningowych, w których system podzieli dane oznaczone etykietami między zestawy treningowe i testowe, zgodnie z określonymi wartościami procentowymi. Możesz też użyć ręcznego podziału danych treningowych i testowych. Ta opcja jest włączona tylko w przypadku dodania dokumentów do zestawu testów podczas etykietowania danych. Aby uzyskać więcej informacji na temat dzielenia danych, zobacz Jak wytrenować model .
Wybierz przycisk Train (Trenuj).
Jeśli wybierzesz identyfikator zadania szkoleniowego z listy, zostanie wyświetlone okienko boczne, w którym można sprawdzić postęp trenowania, stan zadania i inne szczegóły dotyczące tego zadania.
Uwaga
- Tylko pomyślnie ukończone zadania szkoleniowe będą generować modele.
- Czas trenowania modelu może potrwać od kilku minut do kilku godzin na podstawie rozmiaru oznaczonych danych.
- Jednocześnie może być uruchomione tylko jedno zadanie trenowania. Nie można uruchomić innego zadania trenowania w tym samym projekcie, dopóki uruchomione zadanie nie zostanie ukończone.

Wdrażanie modelu
Zazwyczaj po trenowaniu modelu należy przejrzeć jego szczegóły oceny i wprowadzić ulepszenia w razie potrzeby. W tym przewodniku Szybki start wdrożysz model i udostępnisz go do wypróbowania w programie Language Studio lub możesz wywołać interfejs API przewidywania.
Aby wdrożyć model z poziomu programu Language Studio:
Wybierz pozycję Deploying a model (Wdrażanie modelu ) z menu po lewej stronie.
Wybierz pozycję Dodaj wdrożenie , aby rozpocząć nowe zadanie wdrażania.

Wybierz pozycję Utwórz nowe wdrożenie, aby utworzyć nowe wdrożenie i przypisać wytrenowany model z poniższej listy rozwijanej. Możesz również zastąpić istniejące wdrożenie , wybierając tę opcję i wybierając wytrenowany model, który chcesz przypisać do niego z listy rozwijanej poniżej.
Uwaga
Zastępowanie istniejącego wdrożenia nie wymaga zmian wywołania interfejsu API przewidywania, ale uzyskane wyniki będą oparte na nowo przypisanym modelu.
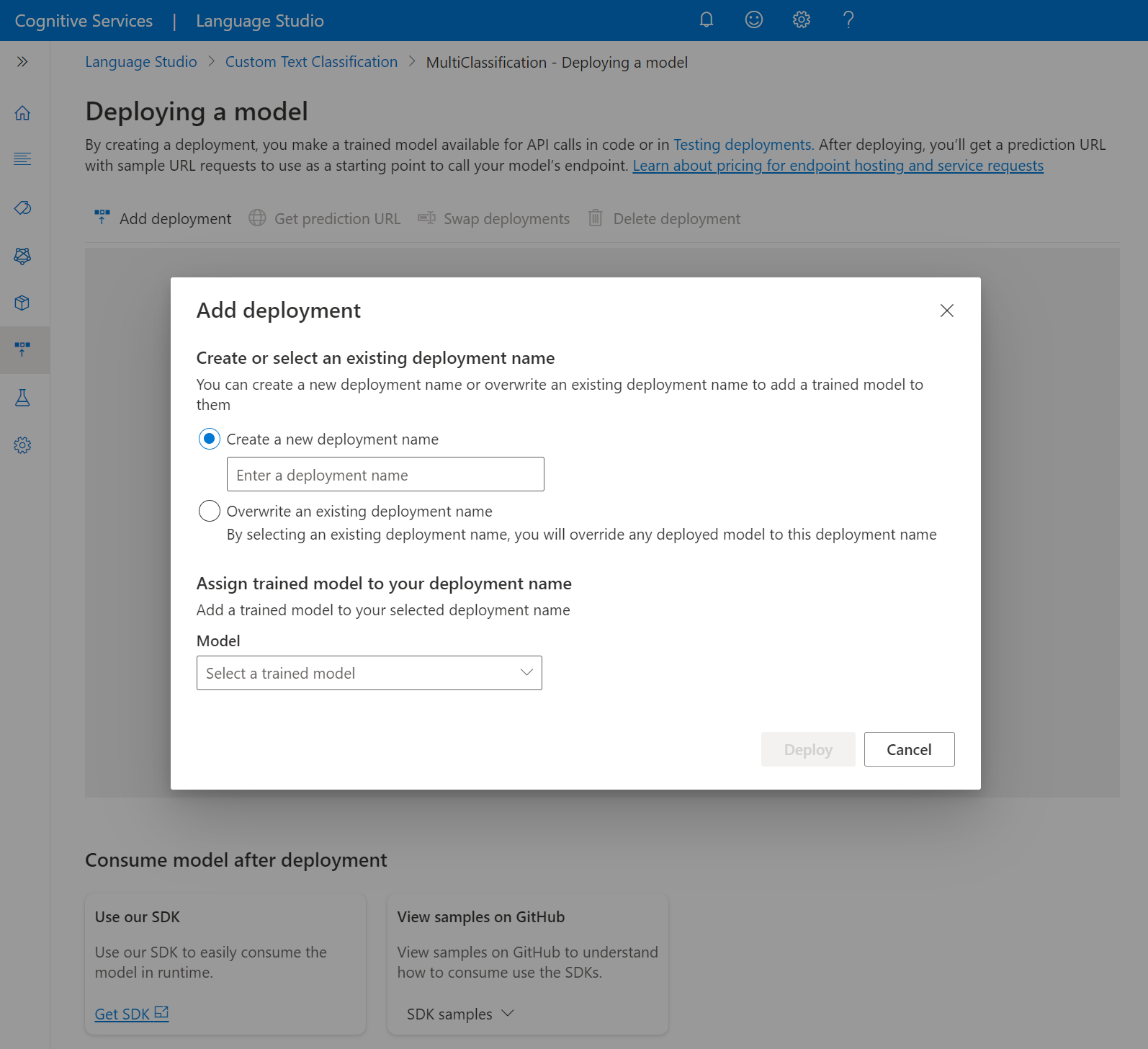
wybierz pozycję Wdróż , aby uruchomić zadanie wdrożenia.
Po pomyślnym wdrożeniu obok zostanie wyświetlona data wygaśnięcia. Wygaśnięcie wdrożenia jest wtedy, gdy wdrożony model będzie niedostępny do przewidywania, co zwykle występuje dwanaście miesięcy po wygaśnięciu konfiguracji trenowania.


Testowanie modelu
Po wdrożeniu modelu możesz zacząć używać go do klasyfikowania tekstu za pomocą interfejsu API przewidywania. W tym przewodniku Szybki start użyjesz programu Language Studio do przesłania niestandardowego zadania klasyfikacji tekstu i wizualizacji wyników. W pobranym wcześniej przykładowym zestawie danych można znaleźć niektóre dokumenty testowe, których można użyć w tym kroku.
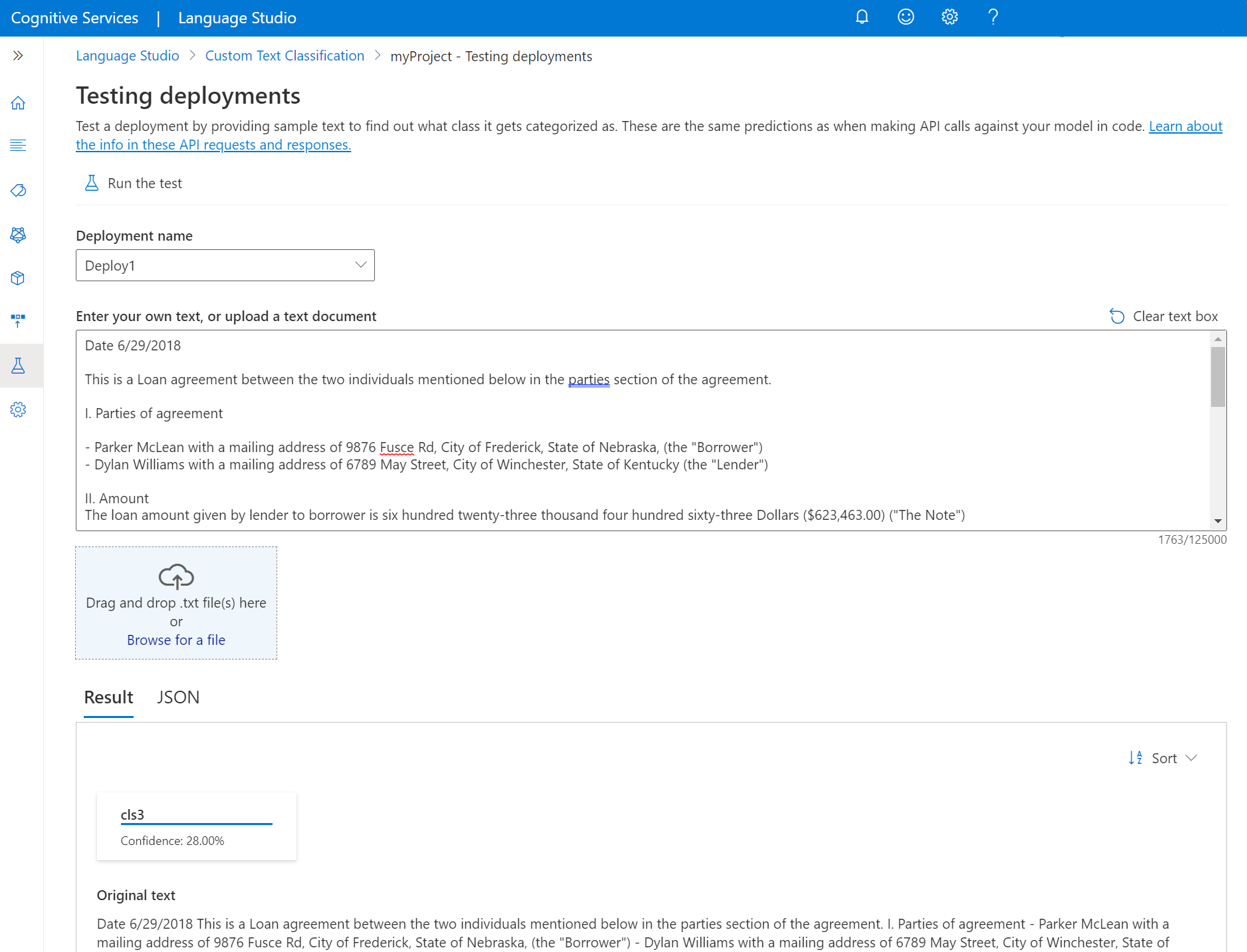
Aby przetestować wdrożone modele w programie Language Studio:
Wybierz pozycję Testowanie wdrożeń z menu po lewej stronie ekranu.
Wybierz wdrożenie, które chcesz przetestować. Można testować tylko modele przypisane do wdrożeń.
W przypadku projektów wielojęzycznych wybierz język tekstu, który testujesz przy użyciu listy rozwijanej języka.
Wybierz wdrożenie, które chcesz wykonać zapytanie/testowanie z listy rozwijanej.
Wprowadź tekst, który chcesz przesłać w żądaniu, lub przekaż
.txtdokument do użycia. Jeśli używasz jednego z przykładowych zestawów danych, możesz użyć jednego z dołączonych plików .txt.Wybierz pozycję Uruchom test z górnego menu.
Na karcie Wynik zobaczysz przewidywane klasy tekstu. Odpowiedź JSON można również wyświetlić na karcie JSON . Poniższy przykład dotyczy projektu klasyfikacji pojedynczej etykiety. Projekt klasyfikacji z wieloma etykietami może zwrócić więcej niż jedną klasę w wyniku.

Czyszczenie projektów
Jeśli projekt nie jest już potrzebny, możesz usunąć projekt przy użyciu programu Language Studio. Wybierz pozycję Niestandardowa klasyfikacja tekstu u góry , a następnie wybierz projekt, który chcesz usunąć. Wybierz pozycję Usuń z górnego menu, aby usunąć projekt.
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz jedną bezpłatnie.
Tworzenie nowego zasobu języka sztucznej inteligencji platformy Azure i konta usługi Azure Storage
Przed użyciem niestandardowej klasyfikacji tekstu należy utworzyć zasób języka sztucznej inteligencji platformy Azure, który zapewni poświadczenia potrzebne do utworzenia projektu i rozpoczęcia trenowania modelu. Potrzebne będzie również konto usługi Azure Storage, na którym można przekazać zestaw danych, który będzie używany podczas tworzenia modelu.
Ważne
Aby szybko rozpocząć pracę, zalecamy utworzenie nowego zasobu języka sztucznej inteligencji platformy Azure, wykonując kroki opisane w tym artykule, które umożliwią utworzenie zasobu języka oraz utworzenie i/lub połączenie konta magazynu w tym samym czasie, co jest łatwiejsze niż późniejsze.
Jeśli masz wcześniej istniejący zasób , którego chcesz użyć, musisz połączyć go z kontem magazynu.
Tworzenie nowego zasobu w witrynie Azure Portal
Przejdź do witryny Azure Portal, aby utworzyć nowy zasób języka sztucznej inteligencji platformy Azure.
W wyświetlonym oknie wybierz pozycję Niestandardowa klasyfikacja tekstu i niestandardowe rozpoznawanie nazwanych jednostek z funkcji niestandardowych. Wybierz pozycję Kontynuuj, aby utworzyć zasób w dolnej części ekranu.
Utwórz zasób języka, postępując zgodnie z poniższymi szczegółami.
Nazwisko Wartość wymagana Subskrypcja Swoją subskrypcję platformy Azure. Grupa zasobów Grupa zasobów, która będzie zawierać zasób. Możesz użyć istniejącej lub utworzyć nową. Region (Region) Jeden z obsługiwanych regionów. Na przykład "Zachodnie stany USA 2". Nazwisko Nazwa zasobu. Warstwa cenowa Jedna z obsługiwanych warstw cenowych. Aby wypróbować usługę, możesz użyć warstwy Bezpłatna (F0). Jeśli zostanie wyświetlony komunikat "Twoje konto logowania nie jest właścicielem wybranej grupy zasobów konta magazynu", twoje konto musi mieć przypisaną rolę właściciela w grupie zasobów, zanim będzie można utworzyć zasób językowy. Skontaktuj się z właścicielem subskrypcji platformy Azure, aby uzyskać pomoc.
Możesz określić właściciela subskrypcji platformy Azure, wyszukując grupę zasobów i korzystając z linku do skojarzonej subskrypcji. Następnie:
- Wybierz kartę Kontrola dostępu (Zarządzanie dostępem i tożsamościami)
- Wybieranie przypisań ról
- Filtruj według roli:właściciel.
W sekcji Niestandardowa klasyfikacja tekstu i niestandardowe rozpoznawanie nazwanych jednostek wybierz istniejące konto magazynu lub wybierz pozycję Nowe konto magazynu. Należy pamiętać, że te wartości ułatwiają rozpoczęcie pracy, a niekoniecznie wartości konta magazynu, których chcesz użyć w środowiskach produkcyjnych. Aby uniknąć opóźnień podczas kompilowania projektu, połącz się z kontami magazynu w tym samym regionie co zasób języka.
Wartość konta magazynu Zalecana wartość Nazwa konta magazynu Dowolna nazwa Storage account type Standardowa LRS Upewnij się, że zaznaczono powiadomienie o odpowiedzialnej sztucznej inteligencji . Wybierz pozycję Przejrzyj i utwórz w dolnej części strony.
Przekazywanie przykładowych danych do kontenera obiektów blob
Po utworzeniu konta usługi Azure Storage i połączeniu go z zasobem Language należy przekazać dokumenty z przykładowego zestawu danych do katalogu głównego kontenera. Te dokumenty będą później używane do trenowania modelu.
Pobierz przykładowy zestaw danych dla projektów klasyfikacji z wieloma etykietami.
Otwórz plik .zip i wyodrębnij folder zawierający dokumenty.
Podany przykładowy zestaw danych zawiera około 200 dokumentów, z których każdy jest podsumowaniem filmu. Każdy dokument należy do co najmniej jednej z następujących klas:
- "Tajemnica"
- "Dramat"
- "Thriller"
- "Komedia"
- "Akcja"
W witrynie Azure Portal przejdź do utworzonego konta magazynu i wybierz je. Możesz to zrobić, klikając pozycję Konta magazynu i wpisując nazwę konta magazynu w polu Filtruj dla dowolnego pola.
Jeśli grupa zasobów nie jest wyświetlana, upewnij się, że filtr Subskrypcja równa się jest ustawiony na Wartość Wszystkie.
Na koncie magazynu wybierz pozycję Kontenery z menu po lewej stronie, znajdującym się poniżej obszaru Magazyn danych. Na wyświetlonym ekranie wybierz pozycję + Kontener. Nadaj kontenerowi nazwę example-data i pozostaw domyślny poziom dostępu publicznego.
Po utworzeniu kontenera wybierz go. Następnie wybierz przycisk Przekaż , aby wybrać
.txtpobrane wcześniej pliki i.json.
Pobieranie kluczy zasobów i punktu końcowego
Przejdź do strony przeglądu zasobu w witrynie Azure Portal
Z menu po lewej stronie wybierz pozycję Klucze i punkt końcowy. Użyjesz punktu końcowego i klucza dla żądań interfejsu API

Tworzenie niestandardowego projektu klasyfikacji tekstu
Po skonfigurowaniu zasobu i kontenera magazynu utwórz nowy niestandardowy projekt klasyfikacji tekstu. Projekt to obszar roboczy umożliwiający tworzenie niestandardowych modeli uczenia maszynowego na podstawie danych. Dostęp do projektu można uzyskać tylko do Ciebie i innych osób, które mają dostęp do używanego zasobu Language.
Wyzwalanie zadania importowania projektu
Prześlij żądanie POST przy użyciu następującego adresu URL, nagłówków i treści JSON, aby zaimportować plik etykiet. Upewnij się, że plik etykiet jest zgodne z akceptowanym formatem.
Jeśli projekt o tej samej nazwie już istnieje, dane tego projektu zostaną zastąpione.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Symbol zastępczy | Wartość | Przykład |
|---|---|---|
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. | myProject |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Dowiedz się więcej o innych dostępnych wersjach interfejsu API | 2022-05-01 |
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść
Użyj następującego kodu JSON w żądaniu. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Klucz | Symbol zastępczy | Wartość | Przykład |
|---|---|---|---|
| api-version | {API-VERSION} |
Wersja wywoływanego interfejsu API. Używana tutaj wersja musi być tą samą wersją interfejsu API w adresie URL. Dowiedz się więcej o innych dostępnych wersjach interfejsu API | 2022-05-01 |
| projectName | {PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. | myProject |
| projectKind | customMultiLabelClassification |
Rodzaj projektu. | customMultiLabelClassification |
| język | {LANGUAGE-CODE} |
Ciąg określający kod języka dokumentów używanych w projekcie. Jeśli projekt jest projektem wielojęzycznym, wybierz kod języka większości dokumentów. Zobacz Obsługa języków, aby dowiedzieć się więcej o obsłudze wielojęzycznej. | en-us |
| wielojęzyczny | true |
Wartość logiczna, która umożliwia posiadanie dokumentów w wielu językach w zestawie danych, a po wdrożeniu modelu można wykonywać zapytania względem modelu w dowolnym obsługiwanym języku (niekoniecznie zawarte w dokumentach szkoleniowych. Zobacz Obsługa języków, aby dowiedzieć się więcej o obsłudze wielojęzycznej. | true |
| storageInputContainerName | {CONTAINER-NAME} |
Nazwa kontenera usługi Azure Storage, w którym zostały przekazane dokumenty. | myContainer |
| obiektów | [] | Tablica zawierająca wszystkie klasy, które znajdują się w projekcie. Są to klasy, do których chcesz sklasyfikować dokumenty. | [] |
| documents | [] | Tablica zawierająca wszystkie dokumenty w projekcie i klasy oznaczone dla tego dokumentu. | [] |
| lokalizacja | {DOCUMENT-NAME} |
Lokalizacja dokumentów w kontenerze magazynu. Ponieważ wszystkie dokumenty znajdują się w katalogu głównym kontenera, powinien to być nazwa dokumentu. | doc1.txt |
| zestaw danych | {DATASET} |
Zestaw testowy, do którego ten dokument zostanie podzielony przed rozpoczęciem trenowania. Aby uzyskać więcej informacji na temat dzielenia danych, zobacz Jak wytrenować model . Możliwe wartości dla tego pola to Train i Test. |
Train |
Po wysłaniu żądania interfejsu API otrzymasz odpowiedź wskazującą 202 , że zadanie zostało przesłane poprawnie. W nagłówkach odpowiedzi wyodrębnij operation-location wartość. Zostanie on sformatowany w następujący sposób:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} służy do identyfikowania żądania, ponieważ ta operacja jest asynchroniczna. Użyjesz tego adresu URL, aby uzyskać stan zadania importu.
Możliwe scenariusze błędów dla tego żądania:
- Wybrany zasób nie ma odpowiednich uprawnień dla konta magazynu.
- Określona
storageInputContainerNamewartość nie istnieje. - Jest używany nieprawidłowy kod języka lub jeśli typ kodu języka nie jest ciągiem.
multilingualwartość jest ciągiem, a nie wartością logiczną.
Pobieranie stanu zadania importu
Użyj następującego żądania GET , aby uzyskać stan importowania projektu. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
Adres URL żądania
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Symbol zastępczy | Wartość | Przykład |
|---|---|---|
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. | myProject |
{JOB-ID} |
Identyfikator lokalizowania stanu trenowania modelu. Ta wartość znajduje się w wartości nagłówka location otrzymanej w poprzednim kroku. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Dowiedz się więcej o innych dostępnych wersjach interfejsu API | 2022-05-01 |
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Szkolenie modelu
Zazwyczaj po utworzeniu projektu możesz zacząć oznaczać dokumenty , które masz w kontenerze połączonym z projektem. Na potrzeby tego przewodnika Szybki start zaimportowano przykładowy otagowany zestaw danych i zainicjowano projekt przy użyciu przykładowego pliku tagów JSON.
Rozpoczynanie trenowania modelu
Po zaimportowaniu projektu możesz rozpocząć trenowanie modelu.
Prześlij żądanie POST przy użyciu następującego adresu URL, nagłówków i treści JSON, aby przesłać zadanie szkoleniowe. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Symbol zastępczy | Wartość | Przykład |
|---|---|---|
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. | myProject |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Dowiedz się więcej o innych dostępnych wersjach interfejsu API | 2022-05-01 |
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść żądania
Użyj następującego kodu JSON w treści żądania. Model zostanie podany po zakończeniu {MODEL-NAME} trenowania. Tylko pomyślne zadania szkoleniowe będą tworzyć modele.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Klucz | Symbol zastępczy | Wartość | Przykład |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Nazwa modelu, która zostanie przypisana do modelu po pomyślnym wytrenowanym. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Jest to wersja modelu, która będzie używana do trenowania modelu. | 2022-05-01 |
| evaluationOptions | Opcja dzielenia danych między zestawy trenowania i testowania. | {} |
|
| kind | percentage |
Metody podzielone. Możliwe wartości to percentage lub manual. Aby uzyskać więcej informacji, zobacz Jak wytrenować model . |
percentage |
| trainingSplitPercentage | 80 |
Procent oznakowanych danych, które mają zostać uwzględnione w zestawie treningowym. Zalecana wartość to 80. |
80 |
| testingSplitPercentage | 20 |
Procent oznakowanych danych, które mają zostać uwzględnione w zestawie testów. Zalecana wartość to 20. |
20 |
Uwaga
Wartości trainingSplitPercentage i testingSplitPercentage są wymagane tylko wtedy, gdy Kind jest ustawiona wartość percentage , a suma obu wartości procentowych powinna być równa 100.
Po wysłaniu żądania interfejsu API otrzymasz odpowiedź wskazującą 202 , że zadanie zostało przesłane poprawnie. W nagłówkach odpowiedzi wyodrębnij location wartość. Zostanie on sformatowany w następujący sposób:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
Element {JOB-ID} służy do identyfikowania żądania, ponieważ ta operacja jest asynchroniczna. Możesz użyć tego adresu URL, aby uzyskać stan trenowania.
Uzyskiwanie stanu zadania szkoleniowego
Trenowanie może potrwać od 10 do 30 minut. Następujące żądanie umożliwia kontynuowanie sondowania stanu zadania szkoleniowego do momentu jego pomyślnego ukończenia.
Użyj następującego żądania GET , aby uzyskać stan postępu trenowania modelu. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
Adres URL żądania
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Symbol zastępczy | Wartość | Przykład |
|---|---|---|
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. | myProject |
{JOB-ID} |
Identyfikator lokalizowania stanu trenowania modelu. Ta wartość znajduje się w wartości nagłówka location otrzymanej w poprzednim kroku. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Zobacz cykl życia modelu, aby dowiedzieć się więcej o innych dostępnych wersjach interfejsu API. | 2022-05-01 |
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść odpowiedzi
Po wysłaniu żądania otrzymasz następującą odpowiedź.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Wdrażanie modelu
Zazwyczaj po trenowaniu modelu należy przejrzeć jego szczegóły oceny i w razie potrzeby wprowadzić ulepszenia. W tym przewodniku Szybki start wdrożysz model i udostępnisz go do wypróbowania w programie Language Studio lub możesz wywołać interfejs API przewidywania.
Przesyłanie zadania wdrożenia
Prześlij żądanie PUT przy użyciu następującego adresu URL, nagłówków i treści JSON, aby przesłać zadanie wdrożenia. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Symbol zastępczy | Wartość | Przykład |
|---|---|---|
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. | myProject |
{DEPLOYMENT-NAME} |
Nazwa wdrożenia. Ta wartość jest uwzględniana w wielkości liter. | staging |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Dowiedz się więcej o innych dostępnych wersjach interfejsu API | 2022-05-01 |
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść żądania
Użyj następującego kodu JSON w treści żądania. Użyj nazwy modelu, który chcesz przypisać do wdrożenia.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Klucz | Symbol zastępczy | Wartość | Przykład |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Nazwa modelu, która zostanie przypisana do wdrożenia. Można przypisywać tylko pomyślnie wytrenowane modele. Ta wartość jest uwzględniana w wielkości liter. | myModel |
Po wysłaniu żądania interfejsu API otrzymasz odpowiedź wskazującą 202 , że zadanie zostało przesłane poprawnie. W nagłówkach odpowiedzi wyodrębnij operation-location wartość. Zostanie on sformatowany w następujący sposób:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
Element {JOB-ID} służy do identyfikowania żądania, ponieważ ta operacja jest asynchroniczna. Możesz użyć tego adresu URL, aby uzyskać stan wdrożenia.
Pobieranie stanu zadania wdrożenia
Użyj następującego żądania GET , aby wykonać zapytanie dotyczące stanu zadania wdrożenia. Możesz użyć adresu URL otrzymanego z poprzedniego kroku lub zastąpić poniższe wartości symboli zastępczych własnymi wartościami.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Symbol zastępczy | Wartość | Przykład |
|---|---|---|
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. | myProject |
{DEPLOYMENT-NAME} |
Nazwa wdrożenia. Ta wartość jest uwzględniana w wielkości liter. | staging |
{JOB-ID} |
Identyfikator lokalizowania stanu trenowania modelu. Jest to wartość nagłówka location otrzymana w poprzednim kroku. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Dowiedz się więcej o innych dostępnych wersjach interfejsu API | 2022-05-01 |
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść odpowiedzi
Po wysłaniu żądania otrzymasz następującą odpowiedź. Nie sonduj tego punktu końcowego , dopóki parametr stanu nie zmieni się na "powodzenie". Powinien zostać wyświetlony 200 kod wskazujący powodzenie żądania.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Klasyfikowanie tekstu
Po pomyślnym wdrożeniu modelu możesz zacząć używać go do klasyfikowania tekstu za pomocą interfejsu API przewidywania. W pobranym wcześniej przykładowym zestawie danych można znaleźć niektóre dokumenty testowe, których można użyć w tym kroku.
Przesyłanie niestandardowego zadania klasyfikacji tekstu
Użyj tego żądania POST , aby uruchomić zadanie klasyfikacji tekstu.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Symbol zastępczy | Wartość | Przykład |
|---|---|---|
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Zobacz Cykl życia modelu, aby dowiedzieć się więcej o innych dostępnych wersjach interfejsu API. | 2022-05-01 |
Nagłówki
| Key | Wartość |
|---|---|
| Ocp-Apim-Subscription-Key | Klucz, który zapewnia dostęp do tego interfejsu API. |
Treść
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Klucz | Symbol zastępczy | Wartość | Przykład |
|---|---|---|---|
displayName |
{JOB-NAME} |
Nazwa zadania. | MyJobName |
documents |
[{},{}] | Lista dokumentów do uruchamiania zadań podrzędnych. | [{},{}] |
id |
{DOC-ID} |
Nazwa lub identyfikator dokumentu. | doc1 |
language |
{LANGUAGE-CODE} |
Ciąg określający kod języka dokumentu. Jeśli ten klucz nie zostanie określony, usługa przyjmie domyślny język projektu wybranego podczas tworzenia projektu. Aby uzyskać listę obsługiwanych kodów języków, zobacz Obsługa języków. | en-us |
text |
{DOC-TEXT} |
Dokumentowanie zadania podrzędnego do uruchamiania zadań podrzędnych. | Lorem ipsum dolor sit amet |
tasks |
Lista zadań, które chcemy wykonać. | [] |
|
taskName |
CustomMultiLabelClassification | Nazwa zadania | CustomMultiLabelClassification |
parameters |
Lista parametrów do przekazania do zadania. | ||
project-name |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Nazwa wdrożenia. Ta wartość jest uwzględniana w wielkości liter. | prod |
Response
Otrzymasz odpowiedź z 202 r. wskazującą powodzenie. W nagłówkach odpowiedzi wyodrębnij element operation-location.
operation-location jest sformatowany w następujący sposób:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Możesz użyć tego adresu URL, aby wykonać zapytanie dotyczące stanu ukończenia zadania i uzyskać wyniki po zakończeniu zadania.
Pobieranie wyników zadania
Użyj następującego żądania GET , aby wykonać zapytanie dotyczące stanu/wyników zadania klasyfikacji tekstu.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Symbol zastępczy | Wartość | Przykład |
|---|---|---|
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartością, do których odwołuje się tutaj, jest najnowsza wydana wersja modelu. | 2022-05-01 |
Nagłówki
| Key | Wartość |
|---|---|
| Ocp-Apim-Subscription-Key | Klucz, który zapewnia dostęp do tego interfejsu API. |
Treść odpowiedzi
Odpowiedź będzie dokumentem JSON z następującymi parametrami.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Czyszczenie zasobów
Jeśli projekt nie jest już potrzebny, możesz go usunąć za pomocą następującego żądania DELETE . Zastąp wartości symboli zastępczych własnymi wartościami.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Symbol zastępczy | Wartość | Przykład |
|---|---|---|
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. | myProject |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Dowiedz się więcej o innych dostępnych wersjach interfejsu API | 2022-05-01 |
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
| Ocp-Apim-Subscription-Key | Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Po wysłaniu żądania interfejsu API otrzymasz odpowiedź wskazującą 202 powodzenie, co oznacza, że projekt został usunięty. Wyniki pomyślnego wywołania z nagłówkiem Operation-Location służącym do sprawdzania stanu zadania.
Następne kroki
Po utworzeniu niestandardowego modelu klasyfikacji tekstu możesz:
Gdy zaczniesz tworzyć własne niestandardowe projekty klasyfikacji tekstu, skorzystaj z artykułów z instrukcjami, aby dowiedzieć się więcej na temat tworzenia modelu w bardziej szczegółowy sposób: