Szybki start: przepływ pracy orkiestracji
Skorzystaj z tego artykułu, aby rozpocząć pracę z projektami przepływu pracy orkiestracji przy użyciu programu Language Studio i interfejsu API REST. Wykonaj następujące kroki, aby wypróbować przykład.
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz jedną bezpłatnie.
- Projekt interpretacji języka konwersacyjnego.
Zaloguj się do programu Language Studio
Przejdź do programu Language Studio i zaloguj się przy użyciu konta platformy Azure.
W wyświetlonym oknie Wybierz zasób języka znajdź subskrypcję platformy Azure i wybierz zasób Język. Jeśli nie masz zasobu, możesz utworzyć nowy.
Szczegóły wystąpienia Wartość wymagana Subskrypcja platformy Azure Swoją subskrypcję platformy Azure. Grupa zasobów platformy Azure Grupa zasobów platformy Azure. Nazwa zasobu platformy Azure Nazwa zasobu platformy Azure. Lokalizacja Prawidłowa lokalizacja zasobu platformy Azure. Na przykład "Zachodnie stany USA 2". Warstwa cenowa Obsługiwana warstwa cenowa dla zasobu platformy Azure. Aby wypróbować usługę, możesz użyć warstwy Bezpłatna (F0). 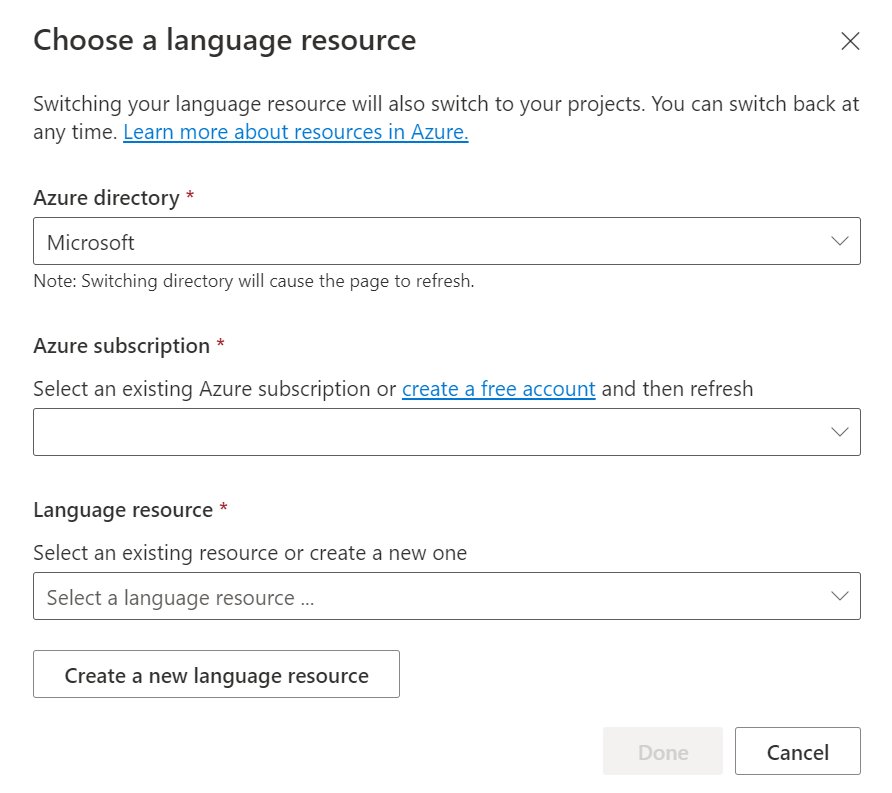

Tworzenie projektu przepływu pracy orkiestracji
Po utworzeniu zasobu Language utwórz projekt przepływu pracy aranżacji. Projekt to obszar roboczy umożliwiający tworzenie niestandardowych modeli uczenia maszynowego na podstawie danych. Dostęp do projektu można uzyskać tylko do Ciebie i innych osób, które mają dostęp do używanego zasobu Language.
W tym przewodniku Szybki start ukończ przewodnik Szybki start dotyczący interpretacji języka konwersacyjnego, aby utworzyć projekt interpretacji języka konwersacji, który będzie używany później.
W usłudze Language Studio znajdź sekcję z etykietą Understand questions and conversational language (Informacje o pytaniach i języku konwersacyjnym), a następnie wybierz pozycję Orchestration Workflow (Przepływ pracy orkiestracji).
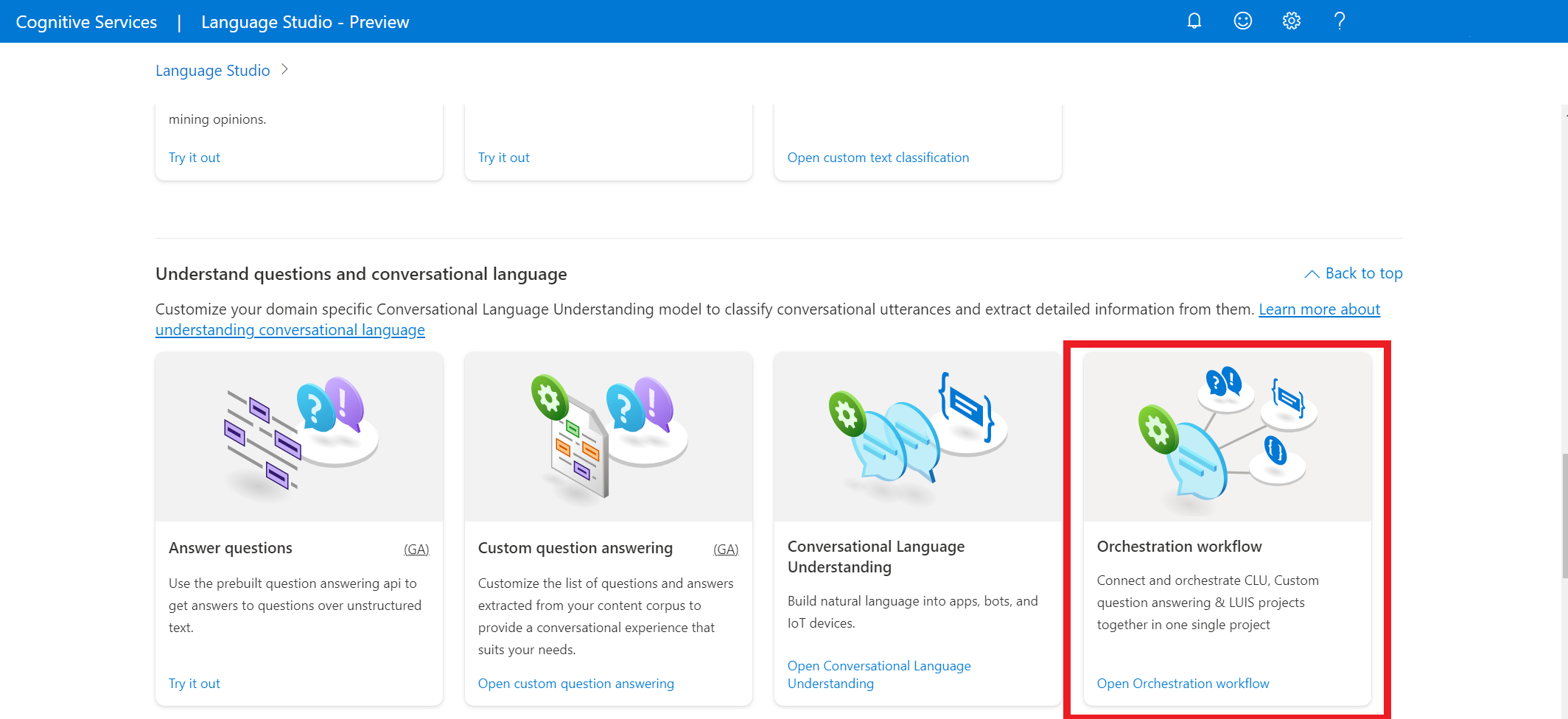
Spowoduje to wyświetlenie strony projektu przepływu pracy orkiestracji. Wybierz pozycję Utwórz nowy projekt. Aby utworzyć projekt, należy podać następujące szczegóły:

| Wartość | Opis |
|---|---|
| Nazwa/nazwisko | Nazwa projektu. |
| opis | Opcjonalny opis projektu. |
| Wypowiedź języka podstawowego | Podstawowy język projektu. Dane szkoleniowe powinny znajdować się głównie w tym języku. |
Po zakończeniu wybierz pozycję Dalej i przejrzyj szczegóły. Wybierz pozycję Utwórz projekt , aby ukończyć proces. W projekcie powinien zostać wyświetlony ekran Build Schema (Schemat kompilacji).
Schemat kompilacji
Po ukończeniu przewodnika Szybki start dotyczącego interpretacji języka konwersacyjnego i utworzeniu projektu orkiestracji następnym krokiem jest dodanie intencji.
Aby nawiązać połączenie z wcześniej utworzonym projektem interpretacji języka konwersacyjnego:
- Na stronie schematu kompilacji w projekcie aranżacji wybierz pozycję Dodaj, aby dodać intencję.
- W wyświetlonym oknie nadaj intencji nazwę.
- Wybierz pozycję Tak, chcę połączyć go z istniejącym projektem.
- Z listy rozwijanej połączonych usług wybierz pozycję Conversational Language Understanding.
- Z listy rozwijanej nazwa projektu wybierz projekt interpretacji języka konwersacji.
- Wybierz pozycję Dodaj intencję , aby utworzyć intencję.
Szkolenie modelu
Aby wytrenować model, musisz rozpocząć zadanie szkoleniowe. Dane wyjściowe pomyślnego zadania szkoleniowego to wytrenowany model.
Aby rozpocząć trenowanie modelu z poziomu programu Language Studio:
Wybierz pozycję Zadania trenowania z menu po lewej stronie.
Wybierz pozycję Start a training job (Rozpocznij zadanie szkoleniowe) z górnego menu.
Wybierz pozycję Train a new model (Trenowanie nowego modelu ) i wpisz nazwę modelu w polu tekstowym. Możesz również zastąpić istniejący model , wybierając tę opcję i wybierając model, który chcesz zastąpić z menu rozwijanego. Zastępowanie wytrenowanego modelu jest nieodwracalne, ale nie wpłynie to na wdrożone modele do momentu wdrożenia nowego modelu.
Jeśli projekt został włączony do ręcznego dzielenia danych podczas tagowania wypowiedzi, zobaczysz dwie opcje dzielenia danych:
- Automatyczne dzielenie zestawu testów na podstawie danych treningowych: wypowiedź oznakowana zostanie losowo podzielona między zestawy treningowe i testowe zgodnie z wybranymi wartościami procentowymi. Domyślny podział procentowy wynosi 80% na potrzeby trenowania i 20% na potrzeby testowania. Aby zmienić te wartości, wybierz zestaw, który chcesz zmienić, i wpisz nową wartość.
Uwaga
Jeśli wybierzesz opcję Automatycznie rozdzielając zestaw testów z danych treningowych, tylko wypowiedzi w zestawie treningowym zostaną podzielone zgodnie z podanymi wartościami procentowymi.
- Użyj ręcznego podziału danych treningowych i testowych: przypisz każdą wypowiedź do zestawu treningowego lub testowego podczas kroku tagowania projektu.
Uwaga
Ręczne dzielenie danych treningowych i testowych będzie włączone tylko w przypadku dodawania wypowiedzi do zestawu testów na stronie danych tagu. W przeciwnym razie zostanie ona wyłączona.
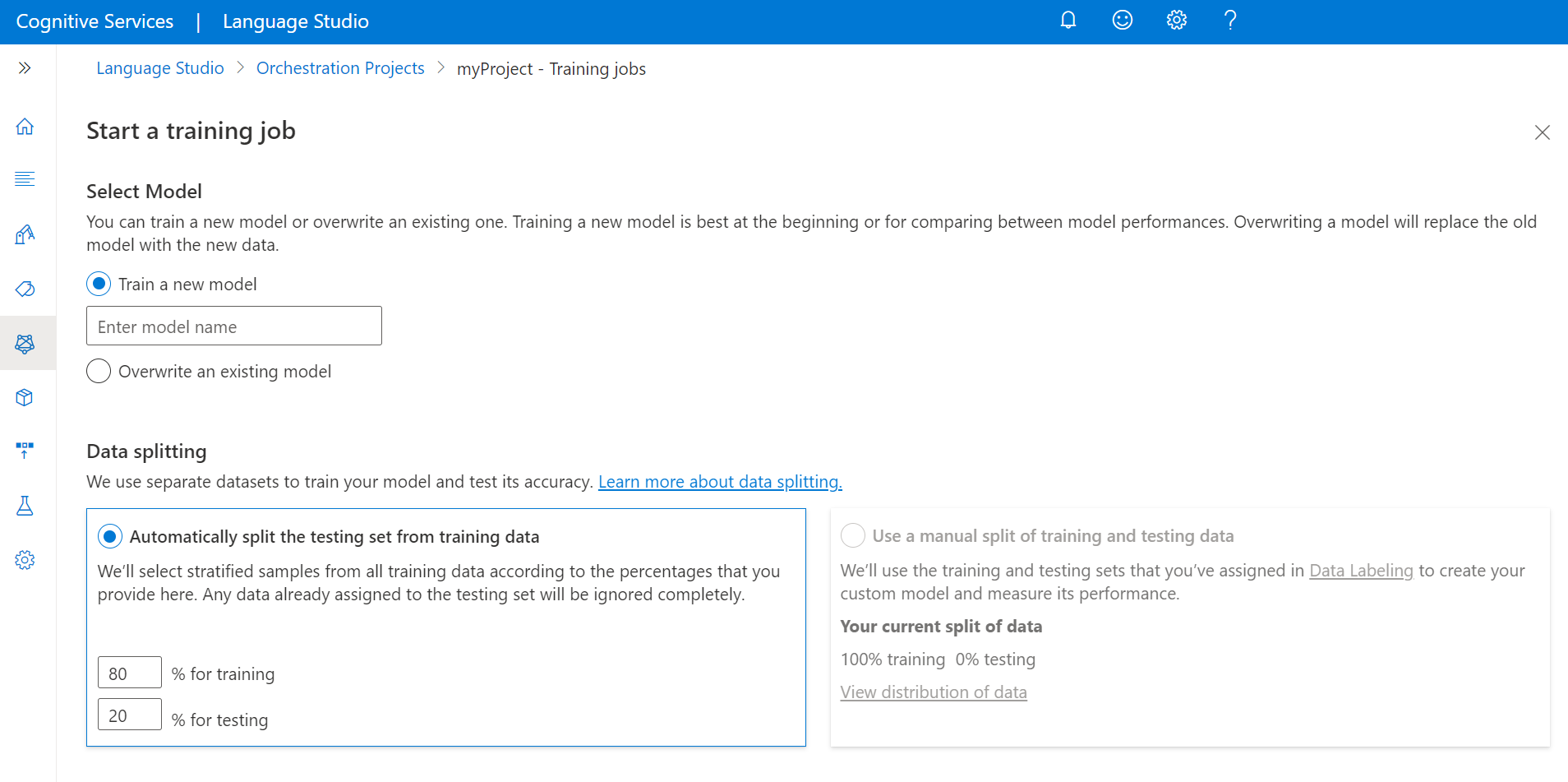
Wybierz przycisk Train (Trenuj).

Uwaga
- Tylko pomyślnie ukończone zadania szkoleniowe będą generować modele.
- Trenowanie może potrwać od kilku minut do kilku godzin na podstawie rozmiaru oznakowanych danych.
- Jednocześnie może być uruchomione tylko jedno zadanie trenowania. Nie można uruchomić innego zadania szkoleniowego wihtin tego samego projektu do momentu ukończenia uruchomionego zadania.
Wdrażanie modelu
Zazwyczaj po trenowaniu modelu należy przejrzeć jego szczegóły oceny. W tym przewodniku Szybki start wdrożysz model i udostępnisz go do wypróbowania w programie Language Studio lub możesz wywołać interfejs API przewidywania.
Aby wdrożyć model z poziomu programu Language Studio:
Wybierz pozycję Deploying a model (Wdrażanie modelu ) z menu po lewej stronie.
Wybierz pozycję Dodaj wdrożenie , aby rozpocząć nowe zadanie wdrażania.
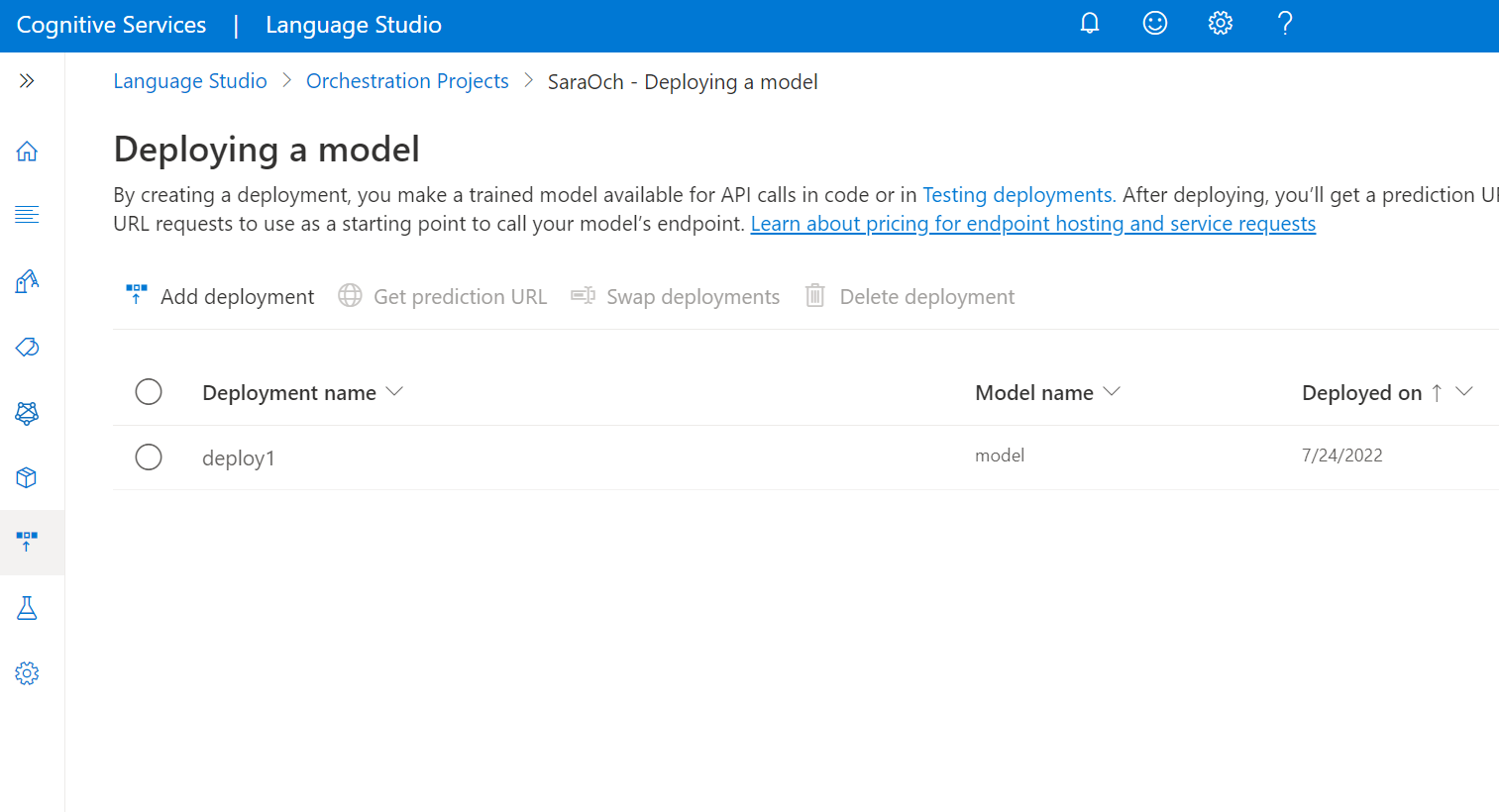
Wybierz pozycję Utwórz nowe wdrożenie, aby utworzyć nowe wdrożenie i przypisać wytrenowany model z poniższej listy rozwijanej. Możesz również zastąpić istniejące wdrożenie , wybierając tę opcję i wybierając wytrenowany model, który chcesz przypisać do niego z listy rozwijanej poniżej.
Uwaga
Zastępowanie istniejącego wdrożenia nie wymaga zmian wywołania interfejsu API przewidywania, ale uzyskane wyniki będą oparte na nowo przypisanym modelu.

Jeśli łączysz co najmniej jedną aplikację usługi LUIS lub projekty interpretacji języka konwersacyjnego, musisz określić nazwę wdrożenia.
W przypadku niestandardowych intencji odpowiedzi na pytania lub bez połączenia nie są wymagane żadne konfiguracje.
Projekty usługi LUIS muszą być publikowane w miejscu skonfigurowanym podczas wdrażania orkiestracji, a niestandardowe odpowiedzi na pytania muszą być również publikowane w miejscach produkcyjnych.
Wybierz pozycję Wdróż , aby przesłać zadanie wdrożenia
Po pomyślnym wdrożeniu obok zostanie wyświetlona data wygaśnięcia. Wygaśnięcie wdrożenia jest wtedy, gdy wdrożony model będzie niedostępny do przewidywania, co zwykle występuje dwanaście miesięcy po wygaśnięciu konfiguracji trenowania.


Model testowy
Po wdrożeniu modelu można rozpocząć korzystanie z niego w celu przewidywania za pomocą interfejsu API przewidywania. W tym przewodniku Szybki start użyjesz programu Language Studio , aby przesłać wypowiedź, uzyskać przewidywania i zwizualizować wyniki.
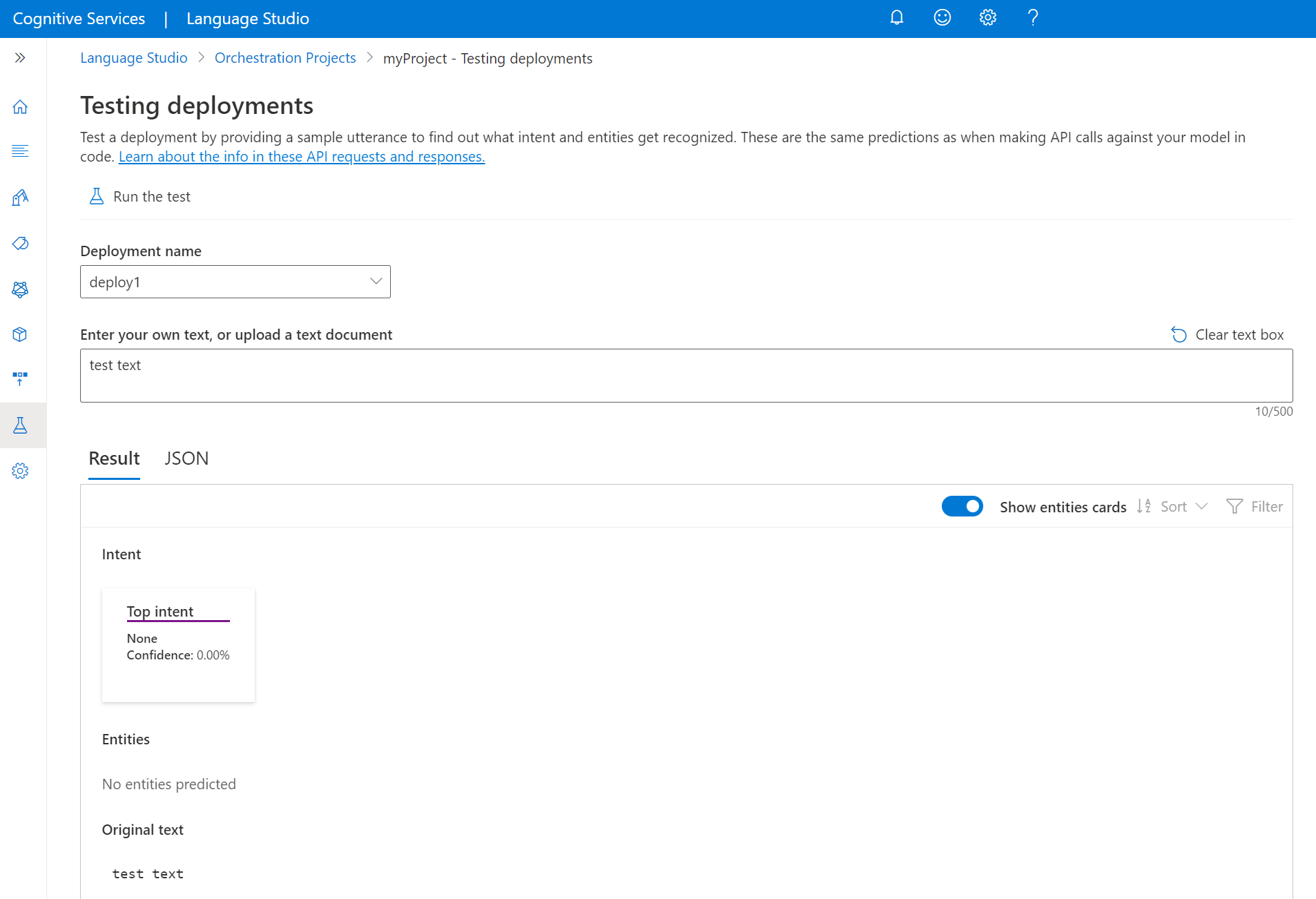
Aby przetestować model w programie Language Studio
Wybierz pozycję Testowanie wdrożeń z menu po lewej stronie.
Wybierz model, który chcesz przetestować. Można testować tylko modele przypisane do wdrożeń.
Z listy rozwijanej Nazwa wdrożenia wybierz nazwę wdrożenia.
W polu tekstowym wprowadź wypowiedź do przetestowania.
W górnym menu wybierz pozycję Uruchom test.
Po uruchomieniu testu w wyniku powinna zostać wyświetlona odpowiedź modelu. Wyniki można wyświetlić w widoku kart jednostek lub wyświetlić w formacie JSON.

Czyszczenie zasobów
Jeśli projekt nie jest już potrzebny, możesz usunąć projekt przy użyciu programu Language Studio. Wybierz pozycję Projekty z menu nawigacji po lewej stronie, wybierz projekt, który chcesz usunąć, a następnie wybierz pozycję Usuń z górnego menu.
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz jedną bezpłatnie.
Tworzenie zasobu języka w witrynie Azure Portal
Tworzenie nowego zasobu w witrynie Azure Portal
Przejdź do witryny Azure Portal, aby utworzyć nowy zasób języka sztucznej inteligencji platformy Azure.
Wybierz pozycję Kontynuuj, aby utworzyć zasób
Utwórz zasób języka, postępując zgodnie z poniższymi szczegółami.
Szczegóły wystąpienia Wartość wymagana Region (Region) Jeden z obsługiwanych regionów. Nazwisko Nazwa zasobu Language. Warstwa cenowa Jedna z obsługiwanych warstw cenowych.
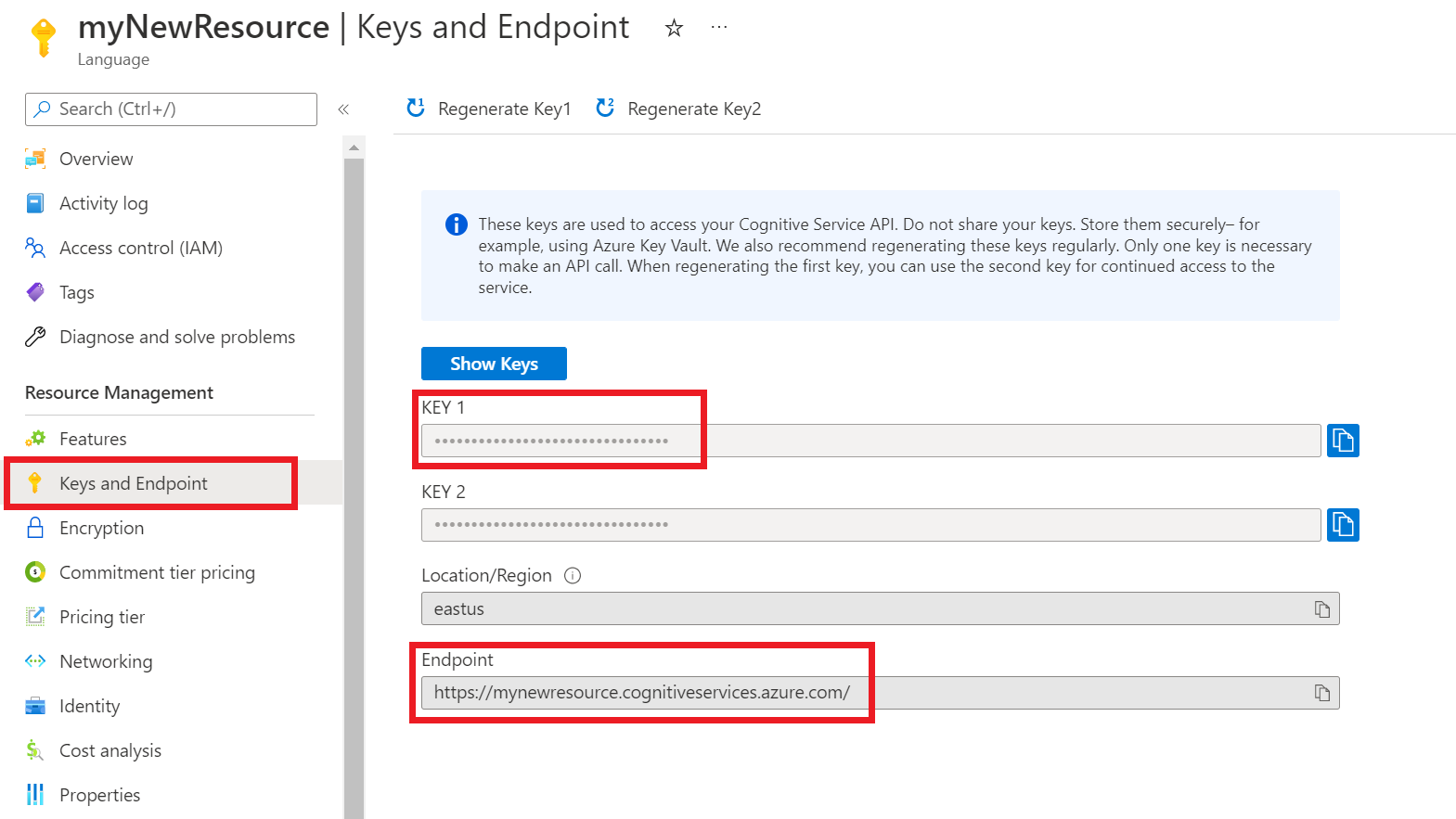
Pobieranie kluczy zasobów i punktu końcowego
Przejdź do strony przeglądu zasobu w witrynie Azure Portal.
Z menu po lewej stronie wybierz pozycję Klucze i punkt końcowy. Użyjesz punktu końcowego i klucza dla żądań interfejsu API

Tworzenie projektu przepływu pracy orkiestracji
Po utworzeniu zasobu Language utwórz projekt przepływu pracy aranżacji. Projekt to obszar roboczy umożliwiający tworzenie niestandardowych modeli uczenia maszynowego na podstawie danych. Dostęp do projektu można uzyskać tylko do Ciebie i innych osób, które mają dostęp do używanego zasobu Language.
W tym przewodniku Szybki start ukończ przewodnik Szybki start CLU, aby utworzyć projekt CLU , który ma być używany w przepływie pracy aranżacji.
Prześlij żądanie PATCH przy użyciu następującego adresu URL, nagłówków i treści JSON, aby utworzyć nowy projekt.
Adres URL żądania
Podczas tworzenia żądania interfejsu API użyj następującego adresu URL. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść
Użyj następującego przykładowego kodu JSON jako treści.
{
"projectName": "{PROJECT-NAME}",
"language": "{LANGUAGE-CODE}",
"projectKind": "Orchestration",
"description": "Project description"
}
| Klucz | Symbol zastępczy | Wartość | Przykład |
|---|---|---|---|
projectName |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. | EmailApp |
language |
{LANGUAGE-CODE} |
Ciąg określający kod języka wypowiedzi używanych w projekcie. Jeśli projekt jest projektem wielojęzycznym, wybierz kod języka większości wypowiedzi. | en-us |
Schemat kompilacji
Po ukończeniu przewodnika Szybki start clu i utworzeniu projektu orkiestracji następnym krokiem jest dodanie intencji.
Prześlij żądanie POST przy użyciu następującego adresu URL, nagłówków i treści JSON, aby zaimportować projekt.
Adres URL żądania
Podczas tworzenia żądania interfejsu API użyj następującego adresu URL. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:import?api-version={API-VERSION}
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść
Uwaga
Każda intencja powinna być tylko z jednego typu (CLU, LUIS i qna)
Użyj następującego przykładowego kodu JSON jako treści.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "Orchestration",
"settings": {
"confidenceThreshold": 0
},
"projectName": "{PROJECT-NAME}",
"description": "Project description",
"language": "{LANGUAGE-CODE}"
},
"assets": {
"projectKind": "Orchestration",
"intents": [
{
"category": "string",
"orchestration": {
"kind": "luis",
"luisOrchestration": {
"appId": "00001111-aaaa-2222-bbbb-3333cccc4444",
"appVersion": "string",
"slotName": "string"
},
"cluOrchestration": {
"projectName": "string",
"deploymentName": "string"
},
"qnaOrchestration": {
"projectName": "string"
}
}
}
],
"utterances": [
{
"text": "Trying orchestration",
"language": "{LANGUAGE-CODE}",
"intent": "string"
}
]
}
}
| Klucz | Symbol zastępczy | Wartość | Przykład |
|---|---|---|---|
api-version |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Używana tutaj wersja musi być tą samą wersją interfejsu API w adresie URL. | 2022-03-01-preview |
projectName |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. | EmailApp |
language |
{LANGUAGE-CODE} |
Ciąg określający kod języka wypowiedzi używanych w projekcie. Jeśli projekt jest projektem wielojęzycznym, wybierz kod języka większości wypowiedzi. | en-us |
Szkolenie modelu
Aby wytrenować model, musisz rozpocząć zadanie szkoleniowe. Dane wyjściowe pomyślnego zadania szkoleniowego to wytrenowany model.
Utwórz żądanie POST przy użyciu następującego adresu URL, nagłówków i treści JSON w celu przesłania zadania szkoleniowego.
Adres URL żądania
Podczas tworzenia żądania interfejsu API użyj następującego adresu URL. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść żądania
Użyj następującego obiektu w żądaniu. Model zostanie nazwany MyModel po zakończeniu trenowania.
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "standard",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| Klucz | Symbol zastępczy | Wartość | Przykład |
|---|---|---|---|
modelLabel |
{MODEL-NAME} |
Nazwa modelu. | Model1 |
trainingMode |
standard |
Tryb trenowania. Tylko jeden tryb trenowania jest dostępny w aranżacji, czyli standard. |
standard |
trainingConfigVersion |
{CONFIG-VERSION} |
Wersja modelu konfiguracji trenowania. Domyślnie jest używana najnowsza wersja modelu. | 2022-05-01 |
kind |
percentage |
Metody podzielone. Możliwe wartości to percentage lub manual. Aby uzyskać więcej informacji, zobacz , jak wytrenować model . |
percentage |
trainingSplitPercentage |
80 |
Procent oznakowanych danych, które mają zostać uwzględnione w zestawie treningowym. Zalecana wartość to 80. |
80 |
testingSplitPercentage |
20 |
Procent oznakowanych danych, które mają zostać uwzględnione w zestawie testów. Zalecana wartość to 20. |
20 |
Uwaga
Wartości trainingSplitPercentage i testingSplitPercentage są wymagane tylko wtedy, gdy Kind jest ustawiona wartość percentage , a suma obu wartości procentowych powinna być równa 100.
Po wysłaniu żądania interfejsu API otrzymasz odpowiedź wskazującą 202 powodzenie. W nagłówkach odpowiedzi wyodrębnij operation-location wartość. Zostanie on sformatowany w następujący sposób:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
Możesz użyć tego adresu URL, aby uzyskać stan zadania szkoleniowego.
Pobieranie stanu szkolenia
Trenowanie może potrwać od 10 do 30 minut. Następujące żądanie umożliwia kontynuowanie sondowania stanu zadania szkoleniowego do momentu pomyślnego ukończenia zadania.
Użyj następującego żądania GET , aby uzyskać stan postępu trenowania modelu. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
Adres URL żądania
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść odpowiedzi
Po wysłaniu żądania otrzymasz następującą odpowiedź. Nie sonduj tego punktu końcowego , dopóki parametr stanu nie zmieni się na "powodzenie".
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxxx-xxxxx-xxxxxx-xxxxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| Key | Wartość | Przykład |
|---|---|---|
modelLabel |
Nazwa modelu | Model1 |
trainingConfigVersion |
Wersja konfiguracji trenowania. Domyślnie jest używana najnowsza wersja . | 2022-05-01 |
startDateTime |
Czas rozpoczęcia szkolenia | 2022-04-14T10:23:04.2598544Z |
status |
Stan zadania szkoleniowego | running |
estimatedEndDateTime |
Szacowany czas zakończenia zadania szkoleniowego | 2022-04-14T10:29:38.2598544Z |
jobId |
Identyfikator zadania szkoleniowego | xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
Data i godzina utworzenia zadania trenowania | 2022-04-14T10:22:42Z |
lastUpdatedDateTime |
Data i godzina ostatniego zaktualizowania zadania szkoleniowego | 2022-04-14T10:23:45Z |
expirationDateTime |
Data i godzina wygaśnięcia zadania trenowania | 2022-04-14T10:22:42Z |
Wdrażanie modelu
Zazwyczaj po trenowaniu modelu należy przejrzeć jego szczegóły oceny. W tym przewodniku Szybki start wdrożysz model i wywołasz interfejs API przewidywania, aby wykonać zapytanie dotyczące wyników.
Przesyłanie zadania wdrożenia
Utwórz żądanie PUT przy użyciu następującego adresu URL, nagłówków i treści JSON, aby rozpocząć wdrażanie modelu przepływu pracy aranżacji.
Adres URL żądania
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}?api-version={API-VERSION}
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść żądania
{
"trainedModelLabel": "{MODEL-NAME}",
}
| Klucz | Symbol zastępczy | Wartość | Przykład |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Nazwa modelu, która zostanie przypisana do wdrożenia. Można przypisywać tylko pomyślnie wytrenowane modele. Ta wartość jest uwzględniana w wielkości liter. | myModel |
Po wysłaniu żądania interfejsu API otrzymasz odpowiedź wskazującą 202 powodzenie. W nagłówkach odpowiedzi wyodrębnij operation-location wartość. Zostanie on sformatowany w następujący sposób:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
Możesz użyć tego adresu URL, aby uzyskać stan zadania wdrożenia.
Pobieranie stanu zadania wdrożenia
Użyj następującego żądania GET , aby uzyskać stan zadania wdrożenia. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
Adres URL żądania
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść odpowiedzi
Po wysłaniu żądania otrzymasz następującą odpowiedź. Nie sonduj tego punktu końcowego , dopóki parametr stanu nie zmieni się na "powodzenie".
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Model zapytań
Po wdrożeniu modelu można rozpocząć korzystanie z niego w celu przewidywania za pomocą interfejsu API przewidywania.
Po pomyślnym wdrożeniu można rozpocząć wykonywanie zapytań względem wdrożonego modelu pod kątem przewidywań.
Utwórz żądanie POST przy użyciu następującego adresu URL, nagłówków i treści JSON, aby rozpocząć testowanie modelu przepływu pracy aranżacji.
Adres URL żądania
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść żądania
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"text": "Text1",
"participantId": "1",
"id": "1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"directTarget": "qnaProject",
"targetProjectParameters": {
"qnaProject": {
"targetProjectKind": "QuestionAnswering",
"callingOptions": {
"context": {
"previousUserQuery": "Meet Surface Pro 4",
"previousQnaId": 4
},
"top": 1,
"question": "App Service overview"
}
}
}
}
}
Treść odpowiedzi
Po wysłaniu żądania otrzymasz następującą odpowiedź na przewidywanie!
{
"kind": "ConversationResult",
"result": {
"query": "App Service overview",
"prediction": {
"projectKind": "Orchestration",
"topIntent": "qnaTargetApp",
"intents": {
"qnaTargetApp": {
"targetProjectKind": "QuestionAnswering",
"confidenceScore": 1,
"result": {
"answers": [
{
"questions": [
"App Service overview"
],
"answer": "The compute resources you use are determined by the *App Service plan* that you run your apps on.",
"confidenceScore": 0.7384000000000001,
"id": 1,
"source": "https://learn.microsoft.com/azure/app-service/overview",
"metadata": {},
"dialog": {
"isContextOnly": false,
"prompts": []
}
}
]
}
}
}
}
}
}
Czyszczenie zasobów
Jeśli projekt nie jest już potrzebny, możesz usunąć projekt przy użyciu interfejsów API.
Utwórz żądanie DELETE przy użyciu następującego adresu URL, nagłówków i treści JSON, aby usunąć projekt interpretacji języka konwersacji.
Adres URL żądania
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key | Wartość |
|---|---|
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Po wysłaniu żądania interfejsu API otrzymasz odpowiedź wskazującą 202 powodzenie, co oznacza, że projekt został usunięty.