Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Wyzwalacz usługi Azure SQL używa funkcji śledzenia zmian SQL do monitorowania tabeli SQL pod kątem zmian i wyzwalania funkcji po utworzeniu, zaktualizowaniu lub usunięciu wiersza. Aby uzyskać szczegółowe informacje o konfiguracji śledzenia zmian do użycia z wyzwalaczem usługi Azure SQL, zobacz Konfigurowanie śledzenia zmian. Aby uzyskać informacje na temat konfigurowania rozszerzenia Azure SQL dla usługi Azure Functions, zobacz omówienie powiązania SQL.
Decyzje dotyczące skalowania wyzwalacza usługi Azure SQL dla planów Zużycie i Premium są wykonywane za pośrednictwem skalowania na podstawie celu. Aby uzyskać więcej informacji, zobacz Skalowanie na podstawie celu i zapoznaj się z opcjami hostingu usługi Azure Functions.
Uwaga
Obsługa planów Zużycie wymaga wydania w wersji 3.1.284 lub nowszejpowiązań usługi Azure SQL dla usługi Azure Functions.
Omówienie funkcji
Powiązanie wyzwalacza usługi Azure SQL używa pętli sondowania w celu sprawdzania zmian, wyzwalania funkcji użytkownika po wykryciu zmian. Na wysokim poziomie pętla wygląda następująco:
while (true) {
1. Get list of changes on table - up to a maximum number controlled by the Sql_Trigger_MaxBatchSize setting
2. Trigger function with list of changes
3. Wait for delay controlled by Sql_Trigger_PollingIntervalMs setting
}
Zmiany są przetwarzane w kolejności, w jaką zostały wprowadzone zmiany, przy czym najstarsze zmiany są najpierw przetwarzane. Kilka notatek dotyczących przetwarzania zmian:
- Jeśli zmiany w wielu wierszach są wprowadzane jednocześnie dokładnie tak, aby były wysyłane do funkcji, jest oparte na kolejności zwracanej przez funkcję CHANGETABLE
- Zmiany są "wsadowe" razem dla wiersza. Jeśli wiele zmian zostanie wprowadzonych do wiersza między każdą iterację pętli, istnieje tylko jeden wpis zmiany dla tego wiersza, który pokaże różnicę między ostatnim przetworzonym stanem a bieżącym stanem
- Jeśli zmiany zostaną wprowadzone w zestawie wierszy, a następnie zostaną wprowadzone kolejne zmiany do połowy tych samych wierszy, wówczas połowa wierszy, które nie zostały zmienione po raz drugi, zostaną przetworzone jako pierwsze. Ta logika przetwarzania wynika z powyższej notatki ze zmianami wsadowymi — wyzwalacz będzie widzieć tylko "ostatnią" zmianę i używać jej dla kolejności przetwarzania ich w
Uwaga
Śledzenie zmian w Azure SQL może wykrywać zmiany na poziomie wiersza w tabelach wykorzystujących technologie szyfrowania, takie jak Always Encrypted lub Transparent Data Encryption (TDE). Jednak wyzwalacz Azure SQL nie odszyfrowuje ani nie ujawnia zaszyfrowanych wartości kolumn w ładunku zmian. Wyzwalacz może wykryć, że nastąpiła zmiana, ale nie może uzyskać dostępu do odszyfrowanych danych dla tych kolumn.
Aby uzyskać więcej informacji na temat śledzenia zmian i sposobu jej użycia przez aplikacje, takie jak wyzwalacze usługi Azure SQL, zobacz Praca ze śledzeniem zmian.
Ważne
Aby uzyskać optymalne zabezpieczenia, należy użyć identyfikatora Entra firmy Microsoft z tożsamościami zarządzanymi na potrzeby połączeń między usługami Functions i Usługą Azure SQL Database. Tożsamości zarządzane sprawiają, że aplikacja jest bezpieczniejsza, eliminując wpisy tajne z wdrożeń aplikacji, takie jak poświadczenia w parametry połączenia, nazwy serwerów i używane porty. W tym samouczku dowiesz się, jak używać tożsamości zarządzanych, połącz aplikację funkcji z usługą Azure SQL przy użyciu tożsamości zarządzanej i powiązań SQL.
Przykładowe użycie
Więcej przykładów wyzwalacza usługi Azure SQL jest dostępnych w repozytorium GitHub.
W przykładzie ToDoItem odwołuje się do klasy i odpowiedniej tabeli bazy danych:
namespace AzureSQL.ToDo
{
public class ToDoItem
{
public Guid Id { get; set; }
public int? order { get; set; }
public string title { get; set; }
public string url { get; set; }
public bool? completed { get; set; }
}
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Śledzenie zmian jest włączone w bazie danych i w tabeli:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Wyzwalacz SQL wiąże się z listą IReadOnlyList<SqlChange<T>>SqlChange obiektów z dwoma właściwościami:
-
Element: element, który został zmieniony. Typ elementu powinien być zgodny ze schematem tabeli, jak pokazano
ToDoItemw klasie. -
Operacja: wartość z
SqlChangeOperationwyliczenia. Możliwe wartości toInsert,UpdateiDelete.
W poniższym przykładzie pokazano funkcję języka C#, która jest wywoływana w przypadku wprowadzenia zmian w ToDo tabeli:
using System;
using System.Collections.Generic;
using Microsoft.Azure.Functions.Worker;
using Microsoft.Azure.Functions.Worker.Extensions.Sql;
using Microsoft.Extensions.Logging;
using Newtonsoft.Json;
namespace AzureSQL.ToDo
{
public static class ToDoTrigger
{
[Function("ToDoTrigger")]
public static void Run(
[SqlTrigger("[dbo].[ToDo]", "SqlConnectionString")]
IReadOnlyList<SqlChange<ToDoItem>> changes,
FunctionContext context)
{
var logger = context.GetLogger("ToDoTrigger");
foreach (SqlChange<ToDoItem> change in changes)
{
ToDoItem toDoItem = change.Item;
logger.LogInformation($"Change operation: {change.Operation}");
logger.LogInformation($"Id: {toDoItem.Id}, Title: {toDoItem.title}, Url: {toDoItem.url}, Completed: {toDoItem.completed}");
}
}
}
}
Przykładowe użycie
Więcej przykładów wyzwalacza usługi Azure SQL jest dostępnych w repozytorium GitHub.
W przykładzie odwołuje się do ToDoItem klasy, SqlChangeToDoItem klasy, SqlChangeOperation wyliczenia i odpowiedniej tabeli bazy danych:
W osobnym pliku ToDoItem.java:
package com.function;
import java.util.UUID;
public class ToDoItem {
public UUID Id;
public int order;
public String title;
public String url;
public boolean completed;
public ToDoItem() {
}
public ToDoItem(UUID Id, int order, String title, String url, boolean completed) {
this.Id = Id;
this.order = order;
this.title = title;
this.url = url;
this.completed = completed;
}
}
W osobnym pliku SqlChangeToDoItem.java:
package com.function;
public class SqlChangeToDoItem {
public ToDoItem item;
public SqlChangeOperation operation;
public SqlChangeToDoItem() {
}
public SqlChangeToDoItem(ToDoItem Item, SqlChangeOperation Operation) {
this.Item = Item;
this.Operation = Operation;
}
}
W osobnym pliku SqlChangeOperation.java:
package com.function;
import com.google.gson.annotations.SerializedName;
public enum SqlChangeOperation {
@SerializedName("0")
Insert,
@SerializedName("1")
Update,
@SerializedName("2")
Delete;
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Śledzenie zmian jest włączone w bazie danych i w tabeli:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Wyzwalacz SQL wiąże się z tablicą SqlChangeToDoItem[]SqlChangeToDoItem obiektów z dwiema właściwościami:
-
element: element, który został zmieniony. Typ elementu powinien być zgodny ze schematem tabeli, jak pokazano
ToDoItemw klasie. -
operation: wartość z
SqlChangeOperationwyliczenia. Możliwe wartości toInsert,UpdateiDelete.
W poniższym przykładzie pokazano funkcję Języka Java wywoływaną w przypadku wprowadzenia zmian w ToDo tabeli:
package com.function;
import com.microsoft.azure.functions.ExecutionContext;
import com.microsoft.azure.functions.annotation.FunctionName;
import com.microsoft.azure.functions.sql.annotation.SQLTrigger;
import com.function.Common.SqlChangeToDoItem;
import com.google.gson.Gson;
import java.util.logging.Level;
public class ProductsTrigger {
@FunctionName("ToDoTrigger")
public void run(
@SQLTrigger(
name = "todoItems",
tableName = "[dbo].[ToDo]",
connectionStringSetting = "SqlConnectionString")
SqlChangeToDoItem[] todoItems,
ExecutionContext context) {
context.getLogger().log(Level.INFO, "SQL Changes: " + new Gson().toJson(changes));
}
}
Przykładowe użycie
Więcej przykładów wyzwalacza usługi Azure SQL jest dostępnych w repozytorium GitHub.
W przykładzie ToDoItem odwołuje się do tabeli bazy danych:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Śledzenie zmian jest włączone w bazie danych i w tabeli:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Wyzwalacz SQL wiąże się z todoChangeslistą obiektów, z których każda ma dwie właściwości:
- element: element, który został zmieniony. Struktura elementu będzie zgodna ze schematem tabeli.
-
operation: możliwe wartości to
Insert,UpdateiDelete.
W poniższym przykładzie przedstawiono funkcję programu PowerShell wywoływaną w przypadku wprowadzenia zmian w ToDo tabeli.
Poniżej przedstawiono powiązanie danych w pliku function.json:
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
W sekcji konfiguracji opisano te właściwości.
Poniżej przedstawiono przykładowy kod programu PowerShell dla funkcji w run.ps1 pliku :
using namespace System.Net
param($todoChanges)
# The output is used to inspect the trigger binding parameter in test methods.
# Use -Compress to remove new lines and spaces for testing purposes.
$changesJson = $todoChanges | ConvertTo-Json -Compress
Write-Host "SQL Changes: $changesJson"
Przykładowe użycie
Więcej przykładów wyzwalacza usługi Azure SQL jest dostępnych w repozytorium GitHub.
W przykładzie ToDoItem odwołuje się do tabeli bazy danych:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Śledzenie zmian jest włączone w bazie danych i w tabeli:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Wyzwalacz SQL wiąże todoChangestablicę obiektów z dwiema właściwościami:
- element: element, który został zmieniony. Struktura elementu będzie zgodna ze schematem tabeli.
-
operation: możliwe wartości to
Insert,UpdateiDelete.
W poniższym przykładzie pokazano funkcję języka JavaScript wywoływaną w przypadku wprowadzenia zmian w ToDo tabeli.
Poniżej przedstawiono powiązanie danych w pliku function.json:
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
W sekcji konfiguracji opisano te właściwości.
Poniżej przedstawiono przykładowy kod JavaScript dla funkcji w index.js pliku:
module.exports = async function (context, todoChanges) {
context.log(`SQL Changes: ${JSON.stringify(todoChanges)}`)
}
Przykładowe użycie
Więcej przykładów wyzwalacza usługi Azure SQL jest dostępnych w repozytorium GitHub.
W przykładzie ToDoItem odwołuje się do tabeli bazy danych:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Śledzenie zmian jest włączone w bazie danych i w tabeli:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Wyzwalacz SQL wiąże się ze zmienną todoChanges, listą obiektów, z których każdy ma dwie właściwości:
- element: element, który został zmieniony. Struktura elementu będzie zgodna ze schematem tabeli.
-
operation: możliwe wartości to
Insert,UpdateiDelete.
W poniższym przykładzie pokazano funkcję języka Python wywoływaną po wprowadzeniu zmian w ToDo tabeli.
Poniżej przedstawiono przykładowy kod języka Python dla pliku function_app.py:
import json
import logging
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="ToDoTrigger")
@app.sql_trigger(arg_name="todo",
table_name="ToDo",
connection_string_setting="SqlConnectionString")
def todo_trigger(todo: str) -> None:
logging.info("SQL Changes: %s", json.loads(todo))
Atrybuty
Biblioteka języka C# używa atrybutu SqlTrigger do deklarowania wyzwalacza SQL w funkcji, która ma następujące właściwości:
| Właściwość atrybutu | opis |
|---|---|
| TableName | Wymagany. Nazwa tabeli monitorowanej przez wyzwalacz. |
| ConnectionStringSetting | Wymagany. Nazwa ustawienia aplikacji zawierającego parametry połączenia dla bazy danych zawierającej tabelę monitorowaną pod kątem zmian. Nazwa ustawienia parametry połączenia odpowiada ustawieniu aplikacji (w local.settings.json programie na potrzeby programowania lokalnego), które zawiera parametry połączenia wystąpienia usługi Azure SQL lub programu SQL Server. |
| LeasesTableName | Opcjonalny. Nazwa tabeli używanej do przechowywania dzierżaw. Jeśli nie zostanie określona, nazwa tabeli dzierżaw będzie Leases_{FunctionId}_{TableId}. Więcej informacji na temat tego, jak to jest generowane, można znaleźć tutaj. |
Adnotacje
W bibliotece (@SQLTrigger) dla parametrów, których wartość pochodzi z usługi Azure SQL. Ta adnotacja obsługuje następujące elementy:
| Składnik | opis |
|---|---|
| nazwa | Wymagany. Nazwa parametru powiązanego z wyzwalaczem. |
| tableName | Wymagany. Nazwa tabeli monitorowanej przez wyzwalacz. |
| connectionStringSetting | Wymagany. Nazwa ustawienia aplikacji zawierającego parametry połączenia dla bazy danych zawierającej tabelę monitorowaną pod kątem zmian. Nazwa ustawienia parametry połączenia odpowiada ustawieniu aplikacji (w local.settings.json programie na potrzeby programowania lokalnego), które zawiera parametry połączenia wystąpienia usługi Azure SQL lub programu SQL Server. |
| LeasesTableName | Opcjonalny. Nazwa tabeli używanej do przechowywania dzierżaw. Jeśli nie zostanie określona, nazwa tabeli dzierżaw będzie Leases_{FunctionId}_{TableId}. Więcej informacji na temat tego, jak to jest generowane, można znaleźć tutaj. |
Konfigurowanie
W poniższej tabeli opisano właściwości konfiguracji powiązania ustawione w pliku function.json.
| właściwość function.json | opis |
|---|---|
| nazwa | Wymagany. Nazwa parametru powiązanego z wyzwalaczem. |
| typ | Wymagany. Musi być ustawiona wartość sqlTrigger. |
| kierunek | Wymagany. Musi być ustawiona wartość in. |
| tableName | Wymagany. Nazwa tabeli monitorowanej przez wyzwalacz. |
| connectionStringSetting | Wymagany. Nazwa ustawienia aplikacji zawierającego parametry połączenia dla bazy danych zawierającej tabelę monitorowaną pod kątem zmian. Nazwa ustawienia parametry połączenia odpowiada ustawieniu aplikacji (w local.settings.json programie na potrzeby programowania lokalnego), które zawiera parametry połączenia wystąpienia usługi Azure SQL lub programu SQL Server. |
| LeasesTableName | Opcjonalny. Nazwa tabeli używanej do przechowywania dzierżaw. Jeśli nie zostanie określona, nazwa tabeli dzierżaw będzie Leases_{FunctionId}_{TableId}. Więcej informacji na temat tego, jak to jest generowane, można znaleźć tutaj. |
Konfiguracja opcjonalna
Następujące opcjonalne ustawienia można skonfigurować dla wyzwalacza SQL na potrzeby lokalnego programowania lub wdrożeń w chmurze.
host.json
W tej sekcji opisano ustawienia konfiguracji dostępne dla tego powiązania w wersji 2.x lub nowszej. Ustawienia w pliku host.json mają zastosowanie do wszystkich funkcji w wystąpieniu aplikacji funkcji. Aby uzyskać więcej informacji na temat ustawień konfiguracji aplikacji funkcji, zobacz host.json dokumentacja usługi Azure Functions.
| Ustawienie | Domyślny | opis |
|---|---|---|
| MaxBatchSize | 100 | Maksymalna liczba zmian przetworzonych przy każdej iteracji pętli wyzwalacza przed wysłaniem do wyzwalanej funkcji. |
| PollingIntervalMs | 1000 | Opóźnienie w milisekundach między przetwarzaniem każdej partii zmian. (1000 ms to 1 sekunda) |
| MaxChangesPerWorker | 1000 | Górny limit liczby oczekujących zmian w tabeli użytkowników dozwolonych dla procesu roboczego aplikacji. Jeśli liczba zmian przekroczy ten limit, może to spowodować zwiększenie skali w poziomie. To ustawienie dotyczy tylko aplikacji funkcji platformy Azure z włączonym skalowaniem opartym na środowisku uruchomieniowym. |
Przykładowy plik host.json
Oto przykładowy plik host.json z opcjonalnymi ustawieniami:
{
"version": "2.0",
"extensions": {
"Sql": {
"MaxBatchSize": 300,
"PollingIntervalMs": 1000,
"MaxChangesPerWorker": 100
}
},
"logging": {
"applicationInsights": {
"samplingSettings": {
"isEnabled": true,
"excludedTypes": "Request"
}
},
"logLevel": {
"default": "Trace"
}
}
}
local.setting.json
Plik local.settings.json przechowuje ustawienia aplikacji i ustawienia używane przez lokalne narzędzia programistyczne. Ustawienia w pliku local.settings.json są używane tylko wtedy, gdy uruchamiasz projekt lokalnie. Podczas publikowania projektu na platformie Azure należy również dodać wszystkie wymagane ustawienia do ustawień aplikacji dla aplikacji funkcji.
Ważne
Ponieważ local.settings.json może zawierać wpisy tajne, takie jak parametry połączenia, nigdy nie należy przechowywać ich w repozytorium zdalnym. Narzędzia obsługujące funkcje zapewniają sposoby synchronizowania ustawień w pliku local.settings.json z ustawieniami aplikacji w aplikacji funkcji, do której wdrożono projekt.
| Ustawienie | Domyślny | opis |
|---|---|---|
| Sql_Trigger_BatchSize | 100 | Maksymalna liczba zmian przetworzonych przy każdej iteracji pętli wyzwalacza przed wysłaniem do wyzwalanej funkcji. |
| Sql_Trigger_PollingIntervalMs | 1000 | Opóźnienie w milisekundach między przetwarzaniem każdej partii zmian. (1000 ms to 1 sekunda) |
| Sql_Trigger_MaxChangesPerWorker | 1000 | Górny limit liczby oczekujących zmian w tabeli użytkowników dozwolonych dla procesu roboczego aplikacji. Jeśli liczba zmian przekroczy ten limit, może to spowodować zwiększenie skali w poziomie. To ustawienie dotyczy tylko aplikacji funkcji platformy Azure z włączonym skalowaniem opartym na środowisku uruchomieniowym. |
Przykładowy plik local.settings.json
Oto przykładowy plik local.settings.json z opcjonalnymi ustawieniami:
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "dotnet",
"SqlConnectionString": "",
"Sql_Trigger_MaxBatchSize": 300,
"Sql_Trigger_PollingIntervalMs": 1000,
"Sql_Trigger_MaxChangesPerWorker": 100
}
}
Konfigurowanie śledzenia zmian (wymagane)
Skonfigurowanie śledzenia zmian do użycia z wyzwalaczem usługi Azure SQL wymaga dwóch kroków. Te kroki można wykonać za pomocą dowolnego narzędzia SQL, które obsługuje uruchamianie zapytań, w tym programu Visual Studio Code, programu Azure Data Studio lub programu SQL Server Management Studio.
Włącz śledzenie zmian w bazie danych SQL, podstawiając
your database namenazwę bazy danych, w której znajduje się monitorowana tabela:ALTER DATABASE [your database name] SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);Opcja
CHANGE_RETENTIONokreśla okres przechowywania informacji o śledzeniu zmian (historia zmian). Przechowywanie historii zmian przez bazę danych SQL może mieć wpływ na funkcjonalność wyzwalacza. Jeśli na przykład funkcja platformy Azure jest wyłączona przez kilka dni, a następnie wznowiona, baza danych będzie zawierać zmiany, które wystąpiły w ciągu ostatnich dwóch dni w powyższym przykładzie konfiguracji.Ta
AUTO_CLEANUPopcja służy do włączania lub wyłączania zadania oczyszczania, które usuwa stare informacje śledzenia zmian. Jeśli tymczasowy problem uniemożliwiający uruchomienie wyzwalacza, wyłączenie automatycznego czyszczenia może być przydatne do wstrzymania usuwania informacji starszych niż okres przechowywania do momentu rozwiązania problemu.Więcej informacji na temat opcji śledzenia zmian znajduje się w dokumentacji programu SQL.
Włącz śledzenie zmian w tabeli, podstawiając
your table namenazwę tabeli do monitorowania (zmiana schematu, jeśli jest to konieczne):ALTER TABLE [dbo].[your table name] ENABLE CHANGE_TRACKING;Wyzwalacz musi mieć dostęp do odczytu w tabeli monitorowanej pod kątem zmian i tabel systemu śledzenia zmian. Każdy wyzwalacz funkcji ma skojarzą tabelę śledzenia zmian i tabelę dzierżaw w schemacie
az_func. Te tabele są tworzone przez wyzwalacz, jeśli jeszcze nie istnieją. Więcej informacji na temat tych struktur danych znajduje się w dokumentacji biblioteki powiązań usługi Azure SQL.
Włączanie skalowania opartego na środowisku uruchomieniowym
Opcjonalnie funkcje mogą być skalowane automatycznie na podstawie liczby zmian oczekujących na przetworzenie w tabeli użytkowników. Aby umożliwić prawidłowe skalowanie funkcji w planie Premium podczas korzystania z wyzwalaczy SQL, należy włączyć monitorowanie skalowania w czasie wykonywania.
W witrynie Azure Portal w aplikacji funkcji wybierz pozycję Konfiguracja.
Na karcie Ustawienia środowiska uruchomieniowego funkcji w obszarze Monitorowanie skalowania środowiska uruchomieniowego wybierz pozycję Włączone.
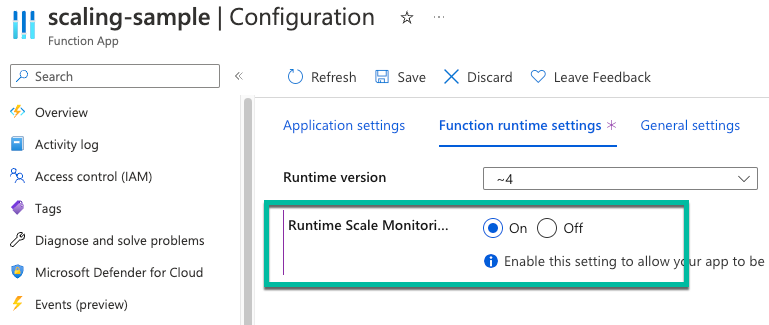
Pomoc techniczna dotycząca ponawiania prób
Więcej informacji na temat obsługi ponawiania prób wyzwalacza SQL i tabel dzierżaw jest dostępnych w repozytorium GitHub.
Ponowne próby uruchamiania
Jeśli podczas uruchamiania wystąpi wyjątek, środowisko uruchomieniowe hosta automatycznie podejmie próbę ponownego uruchomienia odbiornika wyzwalacza przy użyciu strategii wycofywania wykładniczego. Te próby będą kontynuowane do momentu pomyślnego uruchomienia odbiornika lub anulowania uruchamiania.
Przerwane próby nawiązania połączenia
Jeśli funkcja zostanie pomyślnie uruchomiona, ale błąd powoduje przerwanie połączenia (np. serwer przechodzi w tryb offline), funkcja nadal próbuje ponownie otworzyć połączenie, dopóki funkcja nie zostanie zatrzymana lub połączenie zakończy się pomyślnie. Jeśli połączenie zostanie pomyślnie nawiązane ponownie, spowoduje to odebranie zmian przetwarzania, w których zostało to przerwane.
Należy pamiętać, że te ponawianie prób wykracza poza wbudowaną logikę ponawiania bezczynności, którą program SqlClient ma do skonfigurowania za pomocą ConnectRetryCount opcji i ConnectRetryIntervalparametry połączenia. Próby ponownego nawiązania połączenia wbudowanego bezczynności są najpierw podejmowane, a jeśli nie można ponownie nawiązać połączenia, powiązanie wyzwalacza próbuje ponownie ustanowić połączenie.
Ponowne próby wyjątku funkcji
Jeśli wystąpi wyjątek w funkcji użytkownika podczas przetwarzania zmian, partia obecnie przetwarzanych wierszy zostanie ponowiona w ciągu 60 sekund. Inne zmiany są przetwarzane normalnie w tym czasie, ale wiersze w partii, które spowodowały wyjątek, są ignorowane do momentu upływu limitu czasu.
Jeśli wykonanie funkcji zakończy się niepowodzeniem pięć razy w wierszu dla danego wiersza, ten wiersz jest całkowicie ignorowany dla wszystkich przyszłych zmian. Ponieważ wiersze w partii nie są deterministyczne, wiersze w partii zakończone niepowodzeniem mogą skończyć się w różnych partiach w kolejnych wywołaniach. Oznacza to, że nie wszystkie wiersze w partii, które zakończyły się niepowodzeniem, muszą być ignorowane. Jeśli inne wiersze w partii były przyczyną wyjątku, wiersze "dobre" mogą skończyć się w innej partii, która nie zakończy się niepowodzeniem w przyszłych wywołaniach.