Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten przewodnik stanowi wprowadzenie do tworzenia usługi Azure Functions przy użyciu języka Python. W tym artykule założono, że znasz już przewodnik deweloperów usługi Azure Functions.
Ważne
Ten artykuł obsługuje zarówno model programowania w wersji 1, jak i w wersji 2 dla języka Python w usłudze Azure Functions. Model języka Python w wersji 1 używa pliku functions.json do definiowania funkcji, a nowy model w wersji 2 umożliwia zamiast tego użycie podejścia opartego na dekoratorze. To nowe podejście powoduje prostszą strukturę plików i jest bardziej skoncentrowane na kodzie. Wybierz selektor w wersji 2 w górnej części artykułu, aby dowiedzieć się więcej o tym nowym modelu programowania.
Jako deweloper języka Python możesz również zainteresować się następującymi artykułami:
- Visual Studio Code: utwórz pierwszą aplikację w języku Python przy użyciu programu Visual Studio Code.
- Terminal lub wiersz polecenia: Utwórz pierwszą aplikację w języku Python w wierszu polecenia przy użyciu Azure Functions Core Tools.
- Przykłady: Przejrzyj niektóre istniejące aplikacje języka Python w przeglądarce przykładów platformy Learn.
- Visual Studio Code: utwórz pierwszą aplikację w języku Python przy użyciu programu Visual Studio Code.
- Terminal lub wiersz polecenia: Utwórz pierwszą aplikację w języku Python w wierszu polecenia przy użyciu Azure Functions Core Tools.
- Przykłady: Przejrzyj niektóre istniejące aplikacje języka Python w przeglądarce przykładów platformy Learn.
Opcje programowania
Oba modele programowania usługi Python Functions obsługują programowanie lokalne w jednym z następujących środowisk:
Model programowania w języku Python w wersji 2:
Model programowania w języku Python w wersji 1:
Funkcje języka Python można również tworzyć w witrynie Azure Portal.
Napiwek
Mimo że można opracowywać funkcje platformy Azure oparte na języku Python lokalnie w systemie Windows, język Python jest obsługiwany tylko w planie hostingu opartym na systemie Linux, gdy jest uruchomiony na platformie Azure. Aby uzyskać więcej informacji, zobacz listę obsługiwanych kombinacji systemu operacyjnego/środowiska uruchomieniowego.
Model programowania
Usługa Azure Functions oczekuje, że funkcja będzie metodą bezstanową w skrycie języka Python, która przetwarza dane wejściowe i generuje dane wyjściowe. Domyślnie środowisko uruchomieniowe oczekuje, że metoda zostanie zaimplementowana jako metoda globalna wywoływana main() w pliku __init__.py . Można również określić alternatywny punkt wejścia.
Dane są łączone z funkcją poprzez wyzwalacze i powiązania za pomocą atrybutów metody, które korzystają z właściwości name zdefiniowanej w pliku function.json. Na przykład poniższy plik function.json opisuje prostą funkcję wyzwalaną przez żądanie HTTP o nazwie req:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Na podstawie tej definicji plik __init__.py zawierający kod funkcji może wyglądać podobnie do następującego przykładu:
def main(req):
user = req.params.get('user')
return f'Hello, {user}!'
Można również jawnie zadeklarować typy atrybutów i zwracać typ w funkcji przy użyciu adnotacji typu języka Python. Dzięki temu można korzystać z funkcji IntelliSense i funkcji autouzupełniania, które są udostępniane przez wiele edytorów kodu języka Python.
import azure.functions
def main(req: azure.functions.HttpRequest) -> str:
user = req.params.get('user')
return f'Hello, {user}!'
Użyj adnotacji języka Python zawartych w pakiecie azure.functions.* w celu powiązania danych wejściowych i wyjściowych z metodami.
Usługa Azure Functions oczekuje, że funkcja będzie metodą bezstanową w skrycie języka Python, która przetwarza dane wejściowe i generuje dane wyjściowe. Domyślnie środowisko uruchomieniowe oczekuje zaimplementowania metody jako metody globalnej w pliku function_app.py .
Wyzwalacze i powiązania można zadeklarować i używać w funkcji w podejściu opartym na dekoratorze. Są one definiowane w tym samym pliku, function_app.py, co funkcje. Na przykład poniższy plik function_app.py reprezentuje wyzwalacz funkcji przez żądanie HTTP.
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req):
user = req.params.get("user")
return f"Hello, {user}!"
Można również jawnie zadeklarować typy atrybutów i zwracać typ w funkcji przy użyciu adnotacji typu języka Python. Ułatwia to korzystanie z funkcji IntelliSense i funkcji autouzupełniania, które są udostępniane przez wiele edytorów kodu języka Python.
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> str:
user = req.params.get("user")
return f"Hello, {user}!"
Aby dowiedzieć się więcej o znanych ograniczeniach dotyczących modelu w wersji 2 i ich obejściach, zobacz Rozwiązywanie problemów z błędami języka Python w usłudze Azure Functions.
Alternatywny punkt wejścia
Domyślne działanie funkcji można zmienić, opcjonalnie określając właściwości scriptFile i entryPoint w pliku function.json. Na przykład poniższy function.json informuje środowisko uruchomieniowe o użyciu customentry() metody w pliku main.py jako punktu wejścia dla funkcji platformy Azure.
{
"scriptFile": "main.py",
"entryPoint": "customentry",
"bindings": [
...
]
}
Punkt wejścia znajduje się tylko w pliku function_app.py . Można jednak odwoływać się do funkcji w projekcie w function_app.py przy użyciu strategii lub przez zaimportowanie.
Struktura folderów
Zalecana struktura folderów dla projektu funkcji języka Python wygląda następująco:
<project_root>/
| - .venv/
| - .vscode/
| - my_first_function/
| | - __init__.py
| | - function.json
| | - example.py
| - my_second_function/
| | - __init__.py
| | - function.json
| - shared_code/
| | - __init__.py
| | - my_first_helper_function.py
| | - my_second_helper_function.py
| - tests/
| | - test_my_second_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
Główny folder projektu, <project_root>, może zawierać następujące pliki:
- local.settings.json: służy do przechowywania ustawień aplikacji i parametry połączenia podczas uruchamiania lokalnego. Ten plik nie jest publikowany na platformie Azure. Aby dowiedzieć się więcej, zobacz local.settings.file.
- requirements.txt: zawiera listę pakietów języka Python instalowanych przez system podczas publikowania na platformie Azure.
- host.json: zawiera opcje konfiguracji, które mają wpływ na wszystkie funkcje w wystąpieniu aplikacji funkcji. Ten plik jest publikowany na platformie Azure. Nie wszystkie opcje są obsługiwane w przypadku uruchamiania lokalnego. Aby dowiedzieć się więcej, zobacz host.json.
- .vscode/: (Opcjonalnie) Zawiera przechowywaną konfigurację programu Visual Studio Code. Aby dowiedzieć się więcej, zobacz Ustawienia programu Visual Studio Code.
- .venv/: (Opcjonalnie) Zawiera środowisko wirtualne języka Python używane przez programowanie lokalne.
- Plik Dockerfile: (opcjonalnie) Używany podczas publikowania projektu w kontenerze niestandardowym.
- tests/: (Opcjonalnie) Zawiera przypadki testowe aplikacji funkcji.
- .funcignore: (Opcjonalnie) Deklaruje pliki, które nie powinny być publikowane na platformie Azure. Zazwyczaj ten plik zawiera plik vscode/ , aby zignorować ustawienie edytora, plik venv/ w celu zignorowania lokalnego środowiska wirtualnego języka Python, testów/ ignorowania przypadków testowych i local.settings.json , aby zapobiec publikowaniu ustawień aplikacji lokalnych.
Każda funkcja ma własny plik kodu i plik konfiguracji powiązania, function.json.
Zalecana struktura folderów dla projektu funkcji języka Python wygląda następująco:
<project_root>/
| - .venv/
| - .vscode/
| - function_app.py
| - additional_functions.py
| - tests/
| | - test_my_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
Główny folder projektu, <project_root>, może zawierać następujące pliki:
- .venv/: (Opcjonalnie) Zawiera środowisko wirtualne języka Python, które jest używane przez programowanie lokalne.
- .vscode/: (Opcjonalnie) Zawiera przechowywaną konfigurację programu Visual Studio Code. Aby dowiedzieć się więcej, zobacz Ustawienia programu Visual Studio Code.
- function_app.py: domyślna lokalizacja wszystkich funkcji i powiązanych wyzwalaczy i powiązań.
- additional_functions.py: (opcjonalnie) Wszystkie inne pliki języka Python zawierające funkcje (zwykle w przypadku grupowania logicznego), do których odwołuje się function_app.py za pośrednictwem blueprints.
- tests/: (Opcjonalnie) Zawiera przypadki testowe aplikacji funkcji.
- .funcignore: (Opcjonalnie) Deklaruje pliki, które nie powinny być publikowane na platformie Azure. Zazwyczaj ten plik zawiera .vscode/ do ignorowania ustawień edytora, .venv/ do ignorowania lokalnego środowiska wirtualnego języka Python, tests/ do ignorowania przypadków testowych oraz local.settings.json, aby zapobiec publikowaniu lokalnych ustawień aplikacji.
- host.json: zawiera opcje konfiguracji, które mają wpływ na wszystkie funkcje w wystąpieniu aplikacji funkcji. Ten plik jest publikowany na platformie Azure. Nie wszystkie opcje są obsługiwane w przypadku uruchamiania lokalnego. Aby dowiedzieć się więcej, zobacz host.json.
- local.settings.json: służy do przechowywania ustawień aplikacji i ciągów połączenia, gdy jest uruchomiona lokalnie. Ten plik nie jest publikowany na platformie Azure. Aby dowiedzieć się więcej, zobacz local.settings.file.
- requirements.txt: zawiera listę pakietów języka Python instalowanych przez system podczas publikowania na platformie Azure.
- Plik Dockerfile: (opcjonalnie) Używany podczas publikowania projektu w kontenerze niestandardowym.
Podczas wdrażania projektu w aplikacji funkcji na platformie Azure cała zawartość głównego folderu projektu, <project_root>, powinna być uwzględniona w pakiecie, ale nie w samym folderze, co oznacza, że host.json powinien znajdować się w katalogu głównym pakietu. Zalecamy konserwację testów w folderze wraz z innymi funkcjami (w tym przykładzie testy/). Aby uzyskać więcej informacji, zobacz Testowanie jednostkowe.
Połącz z bazą danych
Usługa Azure Functions dobrze integruje się z usługą Azure Cosmos DB dla wielu przypadków użycia, w tym IoT, handlu elektronicznego, gier itp.
Na przykład w przypadku przechwytywania źródeł zdarzeń dwie usługi są zintegrowane, aby wspierać architektury oparte na zdarzeniach, wykorzystując funkcję strumienia zmian usługi Azure Cosmos DB. Strumień zmian zapewnia mikrousługom docelowym możliwość niezawodnego i przyrostowego odczytywania wstawień i aktualizacji (na przykład zdarzeń zamówień). Ta funkcja może służyć do zapewnienia trwałego magazynu zdarzeń jako brokera komunikatów dla zdarzeń zmieniających stan i napędzania przepływu pracy przetwarzania zamówień między wieloma mikrousługami (które można zaimplementować jako bezserwerowe usługi Azure Functions).
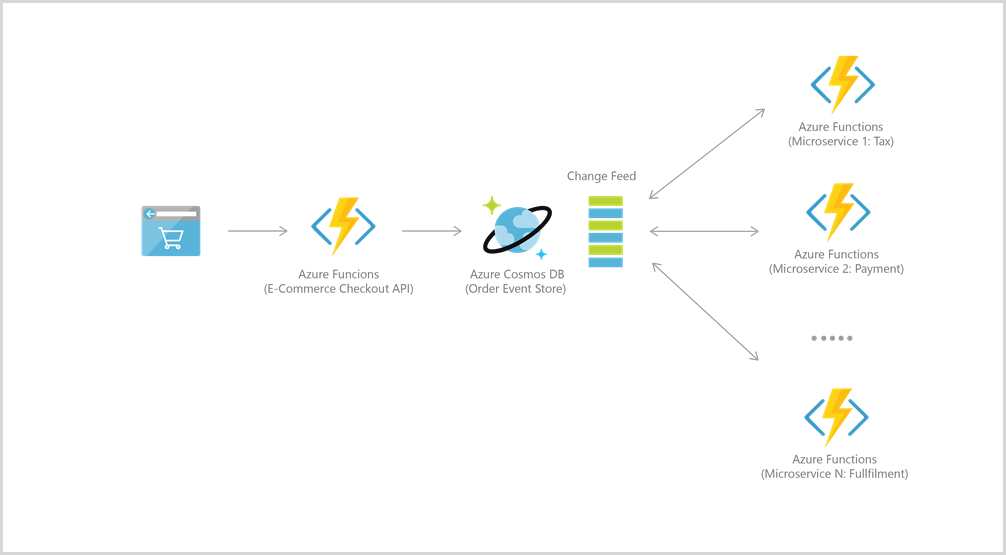
Aby nawiązać połączenie z usługą Azure Cosmos DB, najpierw utwórz konto, bazę danych i kontener. Następnie możesz połączyć kod funkcji z usługą Azure Cosmos DB przy użyciu wyzwalacza i powiązań, jak w tym przykładzie.
Aby zaimplementować bardziej złożoną logikę aplikacji, możesz również użyć biblioteki języka Python dla usługi Cosmos DB. Implementacja asynchronicznego wejścia/wyjścia wygląda następująco:
pip install azure-cosmos
pip install aiohttp
from azure.cosmos.aio import CosmosClient
from azure.cosmos import exceptions
from azure.cosmos.partition_key import PartitionKey
import asyncio
# Replace these values with your Cosmos DB connection information
endpoint = "https://azure-cosmos-nosql.documents.azure.com:443/"
key = "master_key"
database_id = "cosmicwerx"
container_id = "cosmicontainer"
partition_key = "/partition_key"
# Set the total throughput (RU/s) for the database and container
database_throughput = 1000
# Singleton CosmosClient instance
client = CosmosClient(endpoint, credential=key)
# Helper function to get or create database and container
async def get_or_create_container(client, database_id, container_id, partition_key):
database = await client.create_database_if_not_exists(id=database_id)
print(f'Database "{database_id}" created or retrieved successfully.')
container = await database.create_container_if_not_exists(id=container_id, partition_key=PartitionKey(path=partition_key))
print(f'Container with id "{container_id}" created')
return container
async def create_products():
container = await get_or_create_container(client, database_id, container_id, partition_key)
for i in range(10):
await container.upsert_item({
'id': f'item{i}',
'productName': 'Widget',
'productModel': f'Model {i}'
})
async def get_products():
items = []
container = await get_or_create_container(client, database_id, container_id, partition_key)
async for item in container.read_all_items():
items.append(item)
return items
async def query_products(product_name):
container = await get_or_create_container(client, database_id, container_id, partition_key)
query = f"SELECT * FROM c WHERE c.productName = '{product_name}'"
items = []
async for item in container.query_items(query=query, enable_cross_partition_query=True):
items.append(item)
return items
async def main():
await create_products()
all_products = await get_products()
print('All Products:', all_products)
queried_products = await query_products('Widget')
print('Queried Products:', queried_products)
if __name__ == "__main__":
asyncio.run(main())
Plany architektoniczne
Model programowania w języku Python w wersji 2 wprowadza koncepcję strategii. Szablon to nowa klasa, która jest instancjonowana w celu rejestrowania funkcji poza podstawową aplikacją funkcji. Funkcje zarejestrowane w wystąpieniach blueprintów nie są indeksowane bezpośrednio przez środowisko uruchomieniowe. Aby te funkcje wzorca zostały zaindeksowane, aplikacja funkcji musi zarejestrować funkcje z wystąpień wzorca.
Korzystanie z strategii zapewnia następujące korzyści:
- Umożliwia podzielenie aplikacji funkcji na składniki modułowe, co umożliwia definiowanie funkcji w wielu plikach języka Python i dzielenie ich na różne składniki na plik.
- Udostępnia rozszerzalne interfejsy aplikacji funkcji publicznej do kompilowania i ponownego używania własnych interfejsów API.
W poniższym przykładzie pokazano, jak używać schematów:
Najpierw w pliku http_blueprint.py funkcja wyzwalana przez protokół HTTP jest najpierw definiowana i dodawana do obiektu strategii.
import logging
import azure.functions as func
bp = func.Blueprint()
@bp.route(route="default_template")
def default_template(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(
f"Hello, {name}. This HTTP-triggered function "
f"executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. "
"Pass a name in the query string or in the request body for a"
" personalized response.",
status_code=200
)
Następnie w pliku function_app.py obiekt blueprint jest importowany, a jego funkcje są rejestrowane w aplikacji.
import azure.functions as func
from http_blueprint import bp
app = func.FunctionApp()
app.register_functions(bp)
Uwaga
Rozszerzenie Durable Functions obsługuje również strategie. Aby utworzyć schematy dla aplikacji Durable Functions, zarejestruj orkiestrację, działania i wyzwalacze encji oraz powiązania klienta przy użyciu klasy azure-functions-durableBlueprint, jak pokazano tutaj. Wynikowa strategia może być następnie zarejestrowana normalnie. Zobacz nasz przykład .
Zachowanie importowania
Moduły w kodzie funkcji można importować przy użyciu odwołań bezwzględnych i względnych. Na podstawie wcześniej opisanej struktury folderów następujące operacje importowania działają z pliku <funkcji project_root>\my_first_function\__init__.py:
from shared_code import my_first_helper_function #(absolute)
import shared_code.my_second_helper_function #(absolute)
from . import example #(relative)
Uwaga
Jeśli używasz składni importu bezwzględnego, folder shared_code/ musi zawierać plik __init__.py , aby oznaczyć go jako pakiet języka Python.
Następujące __app__ importowania i poza importem względnym najwyższego poziomu są przestarzałe, ponieważ nie są obsługiwane przez moduł sprawdzania typów statycznych i nie są obsługiwane przez struktury testowe języka Python:
from __app__.shared_code import my_first_helper_function #(deprecated __app__ import)
from ..shared_code import my_first_helper_function #(deprecated beyond top-level relative import)
Wyzwalacze i dane wejściowe
Dane wejściowe są podzielone na dwie kategorie w usłudze Azure Functions: wyzwalanie danych wejściowych i innych danych wejściowych. Chociaż różnią się one w pliku function.json , ich użycie jest identyczne w kodzie języka Python. Parametry połączenia lub wpisy tajne dla źródeł wyzwalaczy i wejściowych są mapowane na wartości w pliku local.settings.json podczas uruchamiania lokalnie, a na ustawienia aplikacji, gdy są uruchomione na platformie Azure.
Na przykład poniższy kod demonstruje różnicę między dwoma danymi wejściowymi:
// function.json
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous",
"route": "items/{id}"
},
{
"name": "obj",
"direction": "in",
"type": "blob",
"path": "samples/{id}",
"connection": "STORAGE_CONNECTION_STRING"
}
]
}
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# __init__.py
import azure.functions as func
import logging
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
Po wywołaniu funkcji żądanie HTTP jest przekazywane do funkcji jako req. Wpis jest pobierany z konta usługi Azure Blob Storage na podstawie identyfikatora w adresie URL trasy i udostępniany jako obj w treści funkcji. W tym miejscu określone konto magazynu to parametry połączenia znalezione w ustawieniu <*_CONNECTION_STRING> aplikacji. Aby uzyskać więcej informacji, zobacz Połączenia.
Dane wejściowe są podzielone na dwie kategorie w usłudze Azure Functions: wyzwalanie danych wejściowych i innych danych wejściowych. Chociaż są one definiowane przy użyciu różnych dekoratorów, ich użycie jest podobne w kodzie języka Python. Parametry połączenia lub wpisy tajne dla źródeł wyzwalaczy i wejściowych są mapowane na wartości w pliku local.settings.json podczas uruchamiania lokalnie, a na ustawienia aplikacji, gdy są uruchomione na platformie Azure.
Na przykład poniższy kod pokazuje, jak zdefiniować powiązanie wejściowe usługi Blob Storage:
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# function_app.py
import azure.functions as func
import logging
app = func.FunctionApp()
@app.route(route="req")
@app.blob_input(arg_name="obj", path="samples/{id}",
connection="STORAGE_CONNECTION_STRING")
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
Po wywołaniu funkcji żądanie HTTP jest przekazywane do funkcji jako req. Wpis jest pobierany z konta usługi Azure Blob Storage na podstawie identyfikatora w adresie URL trasy i udostępniany jako obj w treści funkcji. Tutaj, określone konto magazynu to ciąg połączenia znaleziony w ustawieniu aplikacji <*_CONNECTION_STRING>. Aby uzyskać więcej informacji, zobacz Połączenia.
W przypadku operacji wiązania przetwarzających duże ilości danych możesz użyć oddzielnego konta magazynowego. Aby uzyskać więcej informacji, zobacz Wskazówki dotyczące konta magazynowego.
Wiązania typu SDK
W przypadku wybranych wyzwalaczy i powiązań można pracować z typami danych zaimplementowanymi przez podstawowe zestawy SDK i struktury platformy Azure. Te powiązania typu SDK umożliwiają pracę z danymi powiązań tak, jakbyś korzystał z bazowego SDK usługi.
'> [! WAŻNE]
Korzystanie z powiązań typu zestawu SDK wymaga modelu programowania w języku Python w wersji 2.
Ważne
Obsługa powiązań typów zestawu SDK dla języka Python jest obsługiwana tylko w modelu programowania w języku Python w wersji 2.
Wymagania wstępne
- Środowisko uruchomieniowe usługi Azure Functions w wersji 4.34 lub nowszej.
- Język Python w wersji 3.10 lub nowszej obsługiwanej wersji.
Typy zestawów SDK
| Usługa | Wyzwalacz | Powiązanie wejściowe | Powiązanie wyjściowe | Przykłady |
|---|---|---|---|---|
| Bloby Azure | Ogólnie dostępne | Ogólnie dostępne | Typy zestawów SDK nie są zalecane. 1 |
Szybki start,BlobClient,ContainerClient,StorageStreamDownloader |
| Azure Cosmos DB | Typy zestawów SDK nie są używane2 | Prapremiera | Typy zestawów SDK nie są zalecane. 1 |
Szybki start, ContainerProxy,CosmosClient,DatabaseProxy |
| Azure Event Hubs | Prapremiera | Powiązanie wejściowe nie istnieje | Typy zestawów SDK nie są zalecane. 1 |
Szybki start, EventData |
| Azure Service Bus | Prapremiera | Powiązanie wejściowe nie istnieje | Typy zestawów SDK nie są zalecane. 1 |
Szybki start, ServiceBusReceivedMessage |
1 W przypadku scenariuszy wyjściowych, w których należy użyć typu zestawu SDK, należy utworzyć klientów zestawu SDK i pracować z nimi bezpośrednio zamiast używać powiązania wyjściowego. 2 Wyzwalacz usługi Cosmos DB używa zestawienia zmian usługi Azure Cosmos DB i uwidacznia elementy zestawienia zmian jako typy serializowalne w formacie JSON. Brak typów zestawów SDK jest zamierzony w tym scenariuszu.
Strumienie HTTP
Strumienie HTTP to funkcja umożliwiająca akceptowanie i zwracanie danych z punktów końcowych HTTP przy użyciu interfejsów API żądań i odpowiedzi FastAPI obsługiwanych w twoich funkcjach. Te interfejsy API umożliwiają hostowi przetwarzanie dużych danych w komunikatach HTTP jako fragmentów zamiast odczytywania całego komunikatu do pamięci.
Ta funkcja umożliwia obsługę dużych strumieni danych, integracji openAI, dostarczania zawartości dynamicznej i obsługi innych podstawowych scenariuszy HTTP wymagających interakcji w czasie rzeczywistym za pośrednictwem protokołu HTTP. Można również użyć typów odpowiedzi FastAPI ze strumieniami HTTP. Bez strumieni HTTP rozmiar żądań HTTP i odpowiedzi jest ograniczony przez ograniczenia pamięci, które mogą wystąpić podczas przetwarzania całych ładunków komunikatów w pamięci.
Aby dowiedzieć się więcej, w tym jak włączyć strumienie HTTP w projekcie, zobacz Strumienie HTTP.
Ważne
Obsługa strumieni HTTP wymaga modelu programowania w języku Python w wersji 2.
Ważne
Obsługa strumieni HTTP dla języka Python jest ogólnie dostępna i wymaga użycia modelu programowania w języku Python w wersji 2.
Dane wyjściowe
Dane wyjściowe można wyrazić zarówno w parametrach zwracanych, jak i wyjściowych. Jeśli istnieje tylko jedno dane wyjściowe, zalecamy użycie wartości zwracanej. W przypadku wielu danych wyjściowych należy użyć parametrów wyjściowych.
Aby użyć wartości zwracanej przez funkcję jako wartości powiązania wyjściowego, właściwość powiązania name powinna być ustawiona na $return w pliku function.json.
Aby utworzyć wiele danych wyjściowych, użyj metody set() udostępnionej przez interfejs azure.functions.Out, aby przypisać wartość do wiązania. Na przykład następująca funkcja może wypchnąć komunikat do kolejki, a także zwrócić odpowiedź HTTP.
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous"
},
{
"name": "msg",
"direction": "out",
"type": "queue",
"queueName": "outqueue",
"connection": "STORAGE_CONNECTION_STRING"
},
{
"name": "$return",
"direction": "out",
"type": "http"
}
]
}
import azure.functions as func
def main(req: func.HttpRequest,
msg: func.Out[func.QueueMessage]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Dane wyjściowe można wyrazić zarówno w parametrach zwracanych, jak i wyjściowych. Jeśli istnieje tylko jedno dane wyjściowe, zalecamy użycie wartości zwracanej. W przypadku wielu danych wyjściowych należy użyć parametrów wyjściowych.
Aby utworzyć wiele danych wyjściowych, użyj metody set() udostępnionej przez interfejs azure.functions.Out, aby przypisać wartość do wiązania. Na przykład następująca funkcja może wypchnąć komunikat do kolejki, a także zwrócić odpowiedź HTTP.
# function_app.py
import azure.functions as func
app = func.FunctionApp()
@app.write_blob(arg_name="msg", path="output-container/{name}",
connection="CONNECTION_STRING")
def test_function(req: func.HttpRequest,
msg: func.Out[str]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Rejestrowanie
Dostęp do rejestratora środowiska uruchomieniowego usługi Azure Functions jest dostępny za pośrednictwem głównego obsługującego logging w aplikacji Function. Ten rejestrator jest powiązany z usługą Application Insights i umożliwia oznaczanie ostrzeżeń oraz błędów występujących w trakcie wykonania funkcji.
Poniższy przykład rejestruje komunikat informacyjny, gdy funkcja jest wywoływana za pośrednictwem wyzwalacza HTTP.
import logging
def main(req):
logging.info('Python HTTP trigger function processed a request.')
Dostępnych jest więcej metod rejestrowania, które umożliwiają zapisywanie w konsoli na różnych poziomach śledzenia:
| Metoda | opis |
|---|---|
critical(_message_) |
Zapisuje komunikat o poziomie KRYTYCZNYM na rejestratorze głównym. |
error(_message_) |
Zapisuje komunikat z poziomem ERROR w głównym rejestratorze. |
warning(_message_) |
Zapisuje komunikat z poziomem OSTRZEŻENIE w loggerze głównym. |
info(_message_) |
Zapisuje komunikat z poziomem INFO w loggerze głównym. |
debug(_message_) |
Zapisuje komunikat z poziomem DEBUG w głównym rejestratorze. |
Aby dowiedzieć się więcej na temat rejestrowania, zobacz Monitorowanie usługi Azure Functions.
Rejestrowanie z utworzonych wątków
Aby wyświetlić dzienniki pochodzące z utworzonych wątków, uwzględnij context argument w podpisie funkcji. Ten argument zawiera atrybut thread_local_storage, który przechowuje lokalny invocation_id. Można to ustawić na invocation_id bieżącej funkcji, aby upewnić się, że kontekst zostanie zmieniony.
import azure.functions as func
import logging
import threading
def main(req, context):
logging.info('Python HTTP trigger function processed a request.')
t = threading.Thread(target=log_function, args=(context,))
t.start()
def log_function(context):
context.thread_local_storage.invocation_id = context.invocation_id
logging.info('Logging from thread.')
Rejestrowanie telemetrii niestandardowej
Domyślnie środowisko uruchomieniowe usługi Functions zbiera dzienniki i inne dane telemetryczne generowane przez funkcje. Ta telemetria kończy się jako ślady w usłudze Application Insights. Dane telemetryczne żądań i zależności dla niektórych usług platformy Azure są również zbierane domyślnie przez wyzwalacze i powiązania.
Aby zbierać niestandardowe żądania i niestandardowe dane telemetryczne zależności poza powiązaniami, możesz użyć rozszerzenia OpenCensus dla języka Python. To rozszerzenie wysyła niestandardowe dane telemetryczne do wystąpienia usługi Application Insights. Listę obsługiwanych rozszerzeń można znaleźć w repozytorium OpenCensus.
Uwaga
Aby użyć rozszerzeń OpenCensus dla języka Python, należy włączyć rozszerzenia robocze języka Python w aplikacji funkcji, ustawiając PYTHON_ENABLE_WORKER_EXTENSIONS na 1. Należy również przełączyć się na korzystanie z parametru połączenia Application Insights, dodając ustawienie APPLICATIONINSIGHTS_CONNECTION_STRING do ustawień aplikacji, jeśli jeszcze go tam nie ma.
// requirements.txt
...
opencensus-extension-azure-functions
opencensus-ext-requests
import json
import logging
import requests
from opencensus.extension.azure.functions import OpenCensusExtension
from opencensus.trace import config_integration
config_integration.trace_integrations(['requests'])
OpenCensusExtension.configure()
def main(req, context):
logging.info('Executing HttpTrigger with OpenCensus extension')
# You must use context.tracer to create spans
with context.tracer.span("parent"):
response = requests.get(url='http://example.com')
return json.dumps({
'method': req.method,
'response': response.status_code,
'ctx_func_name': context.function_name,
'ctx_func_dir': context.function_directory,
'ctx_invocation_id': context.invocation_id,
'ctx_trace_context_Traceparent': context.trace_context.Traceparent,
'ctx_trace_context_Tracestate': context.trace_context.Tracestate,
'ctx_retry_context_RetryCount': context.retry_context.retry_count,
'ctx_retry_context_MaxRetryCount': context.retry_context.max_retry_count,
})
Wyzwalacz HTTP
Wyzwalacz HTTP jest zdefiniowany w pliku function.json . Powiązanie name musi być zgodne z nazwanym parametrem w funkcji.
W poprzednich przykładach używana jest nazwa powiązania req. Ten parametr jest obiektem HttpRequest , a zwracany jest obiekt HttpResponse .
Z obiektu HttpRequest można uzyskać nagłówki żądań, parametry zapytania, parametry trasy i treść komunikatu.
Poniższy przykład pochodzi z szablonu wyzwalacza HTTP dla języka Python.
def main(req: func.HttpRequest) -> func.HttpResponse:
headers = {"my-http-header": "some-value"}
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello {name}!", headers=headers)
else:
return func.HttpResponse(
"Please pass a name on the query string or in the request body",
headers=headers, status_code=400
)
W tej funkcji uzyskasz wartość parametru name zapytania z params parametru obiektu HttpRequest . Treść komunikatu zakodowanego w formacie JSON jest odczytywana przy użyciu get_json metody .
Podobnie można ustawić status_code i headers dla komunikatu odpowiedzi w obiekcie HttpResponse zwróconym.
Wyzwalacz HTTP jest definiowany jako metoda, która przyjmuje nazwany parametr powiązania, który jest obiektem HttpRequest i zwraca obiekt HttpResponse. Stosujesz dekorator function_name do metody, aby zdefiniować nazwę funkcji, natomiast punkt końcowy HTTP jest ustawiany przez zastosowanie dekoratora route.
Ten przykład pochodzi z szablonu wyzwalacza HTTP dla modelu programowania języka Python w wersji 2, gdzie nazwa parametru powiązania to req. Jest to przykładowy kod udostępniany podczas tworzenia funkcji przy użyciu narzędzi Azure Functions Core Tools lub Visual Studio Code.
@app.function_name(name="HttpTrigger1")
@app.route(route="hello")
def test_function(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello, {name}. This HTTP-triggered function executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.",
status_code=200
)
Z obiektu HttpRequest można uzyskać nagłówki żądań, parametry zapytania, parametry trasy i treść komunikatu. W tej funkcji uzyskasz wartość parametru name zapytania z params parametru obiektu HttpRequest . Treść komunikatu zakodowanego w formacie JSON jest odczytywana przy użyciu get_json metody .
Podobnie można ustawić status_code i headers dla komunikatu odpowiedzi w obiekcie HttpResponse zwróconym.
Aby przekazać nazwę w tym przykładzie, wklej adres URL podany podczas uruchamiania funkcji, a następnie dołącz do niego "?name={name}".
Struktury sieci Web
Można użyć platform zgodnych z interfejsem bramy serwera sieci Web (WSGI) i asynchronicznych platform zgodnych z bramą serwera (ASGI), takich jak Flask i FastAPI, z funkcjami języka Python wyzwalanymi przez protokół HTTP. W tej sekcji pokazano, jak zmodyfikować funkcje tak, aby obsługiwały te struktury.
Najpierw należy zaktualizować plik function.json, aby uwzględnić element route w wyzwalaczu HTTP, jak pokazano w poniższym przykładzie:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
],
"route": "{*route}"
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Plik host.json musi również zostać zaktualizowany w celu uwzględnienia protokołu HTTP routePrefix, jak pokazano w poniższym przykładzie:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[4.*, 5.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Zaktualizuj plik kodu języka Python init.py w zależności od interfejsu używanego przez platformę. W poniższym przykładzie przedstawiono podejście obsługi ASGI lub podejście otoki WSGI dla platformy Flask:
Możesz używać frameworków zgodnych z interfejsem ASGI i WSGI, takich jak Flask i FastAPI, z funkcjami Pythona wywoływanymi przez protokół HTTP. Najpierw należy zaktualizować plik host.json w celu uwzględnienia protokołu HTTP routePrefix, jak pokazano w poniższym przykładzie:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[4.*, 5.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Kod struktury wygląda podobnie do następującego przykładu:
AsgiFunctionApp to klasa aplikacji funkcji najwyższego poziomu do konstruowania funkcji HTTP ASGI.
# function_app.py
import azure.functions as func
from fastapi import FastAPI, Request, Response
fast_app = FastAPI()
@fast_app.get("/return_http_no_body")
async def return_http_no_body():
return Response(content="", media_type="text/plain")
app = func.AsgiFunctionApp(app=fast_app,
http_auth_level=func.AuthLevel.ANONYMOUS)
Skalowanie i wydajność
Aby uzyskać najlepsze rozwiązania dotyczące skalowania i wydajności aplikacji funkcji języka Python, zobacz artykuł Skalowanie i wydajność języka Python.
Kontekst
Aby uzyskać kontekst wywołania funkcji po jej uruchomieniu, dołącz context argument w podpisie.
Na przykład:
import azure.functions
def main(req: azure.functions.HttpRequest,
context: azure.functions.Context) -> str:
return f'{context.invocation_id}'
Klasa Context ma następujące atrybuty ciągu:
| Atrybut | opis |
|---|---|
function_directory |
Katalog, w którym jest uruchomiona funkcja. |
function_name |
Nazwa funkcji. |
invocation_id |
Identyfikator wywołania bieżącej funkcji. |
thread_local_storage |
Lokalna pamięć wątku funkcji. Zawiera lokalne invocation_id miejsce rejestrowania z utworzonych wątków. |
trace_context |
Kontekst śledzenia rozproszonego. Aby uzyskać więcej informacji, zobacz Trace Context. |
retry_context |
Kontekst ponownego wywoływania funkcji. Aby uzyskać więcej informacji, zobacz retry-policies. |
Zmienne globalne
Nie ma gwarancji, że stan aplikacji zostanie zachowany na potrzeby przyszłych wykonań. Jednak środowisko uruchomieniowe usługi Azure Functions często używa tego samego procesu w przypadku wielu wykonań tej samej aplikacji. Aby buforować wyniki kosztownych obliczeń, zadeklaruj ją jako zmienną globalną.
CACHED_DATA = None
def main(req):
global CACHED_DATA
if CACHED_DATA is None:
CACHED_DATA = load_json()
# ... use CACHED_DATA in code
Zmienne środowiskowe
W usłudze Azure Functions ustawienia aplikacji, takie jak parametry połączenia usług, są widoczne jako zmienne środowiskowe podczas ich uruchamiania. Istnieją dwa główne sposoby uzyskiwania dostępu do tych ustawień w kodzie.
| Metoda | opis |
|---|---|
os.environ["myAppSetting"] |
Próbuje pobrać ustawienie aplikacji według nazwy klucza i zgłasza błąd, jeśli operacja się nie powiedzie. |
os.getenv("myAppSetting") |
Próbuje pobrać ustawienie aplikacji według nazwy klucza i zwraca None, gdy próba się nie powiedzie. |
Oba te sposoby wymagają zadeklarowania wartości import os.
W poniższym przykładzie użyto os.environ["myAppSetting"] do pobrania ustawienia aplikacji z kluczem o nazwie myAppSetting.
import logging
import os
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
W przypadku programowania lokalnego ustawienia aplikacji są przechowywane w pliku local.settings.json.
W usłudze Azure Functions ustawienia aplikacji, takie jak parametry połączenia usług, są widoczne jako zmienne środowiskowe podczas ich uruchamiania. Istnieją dwa główne sposoby uzyskiwania dostępu do tych ustawień w kodzie.
| Metoda | opis |
|---|---|
os.environ["myAppSetting"] |
Próbuje pobrać ustawienie aplikacji według nazwy klucza i zgłasza błąd, jeśli operacja się nie powiedzie. |
os.getenv("myAppSetting") |
Próbuje pobrać ustawienie aplikacji według nazwy klucza i zwraca None, gdy próba się nie powiedzie. |
Oba te sposoby wymagają zadeklarowania wartości import os.
W poniższym przykładzie użyto os.environ["myAppSetting"] do pobrania ustawienia aplikacji z kluczem o nazwie myAppSetting.
import logging
import os
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
W przypadku programowania lokalnego ustawienia aplikacji są przechowywane w pliku local.settings.json.
Wersja języka Python
Usługa Azure Functions obsługuje następujące wersje języka Python:
| Wersje języka Python1 | Poziom pomocy technicznej |
|---|---|
| 3.13 | Ogólnie dostępna (GA)2 |
| 3,12 | ogólna dostępność |
| 3.11 | ogólna dostępność |
| 3,10 | ogólna dostępność |
- Oficjalne dystrybucje języka Python
- Język Python 3.13 nie jest obsługiwany, gdy aplikacja działa w planie Zużycie.
Ważne
Obsługa języka Python 3.13 wprowadza pewne ulepszenia i kilka zmian powodujących niezgodność. Aby uzyskać więcej informacji, zobacz Python 3.13+ w usłudze Azure Functions.
Aby zażądać określonej wersji języka Python podczas tworzenia aplikacji funkcji na platformie Azure, użyj --runtime-version opcji az functionapp create polecenia . Wersja środowiska uruchomieniowego usługi Functions jest ustawiana przez opcję --functions-version. Wersja języka Python jest ustawiana podczas tworzenia aplikacji funkcji i nie można jej zmienić dla aplikacji uruchomionych w planie Zużycie.
Środowisko uruchomieniowe używa dostępnej wersji języka Python podczas lokalnego uruchamiania.
Zmiana wersji języka Python
Aby ustawić aplikację funkcji języka Python na określoną wersję języka, należy określić język i wersję języka w LinuxFxVersion polu w konfiguracji lokacji. Aby na przykład zmienić aplikację Python na wersję Python 3.12, zmień linuxFxVersion na python|3.12.
Aby dowiedzieć się, jak wyświetlać i zmieniać linuxFxVersion ustawienie witryny, zobacz Jak zarządzać wersjami środowiska uruchomieniowego Azure Functions.
Aby uzyskać więcej ogólnych informacji, zobacz zasady obsługi środowiska uruchomieniowego usługi Azure Functions i Obsługiwane języki w usłudze Azure Functions.
Zarządzanie pakietami
Podczas tworzenia aplikacji lokalnie przy użyciu narzędzi Core Tools lub Visual Studio Code dodaj nazwy i wersje wymaganych pakietów do pliku requirements.txt , a następnie zainstaluj je przy użyciu polecenia pip.
Na przykład możesz użyć następującego pliku requirements.txt i pip polecenia, aby zainstalować requests pakiet z PyPI.
requests==2.19.1
pip install -r requirements.txt
Podczas uruchamiania funkcji w planie usługi App Service zależności zdefiniowane w requirements.txt mają pierwszeństwo przed wbudowanymi modułami języka Python, takimi jak logging. Pierwszeństwo to może powodować konflikty, gdy wbudowane moduły mają takie same nazwy jak katalogi w kodzie. Podczas pracy w planie Zasobów lub planie Elastic Premium, konflikty są mniej prawdopodobne, ponieważ zależności nie są domyślnie priorytetowo traktowane.
Aby zapobiec problemom uruchomionym w planie usługi App Service, nie nazwij katalogów tak samo jak w przypadku modułów natywnych języka Python i nie dołączaj bibliotek natywnych języka Python do pliku requirements.txt projektu.
Publikowanie na platformie Azure
Gdy wszystko będzie gotowe do opublikowania, upewnij się, że wszystkie publicznie dostępne zależności są wymienione w pliku requirements.txt . Plik można znaleźć w katalogu głównym projektu.
Pliki i foldery projektu, które są wykluczone z publikowania, w tym folder środowiska wirtualnego, można znaleźć w katalogu głównym projektu.
Istnieją trzy akcje kompilacji obsługiwane do publikowania projektu w języku Python na platformie Azure: kompilacja zdalna, kompilacja lokalna i kompilacje przy użyciu niestandardowych zależności.
Za pomocą usługi Azure Pipelines można również tworzyć zależności i publikować przy użyciu ciągłego dostarczania (CD). Aby dowiedzieć się więcej, zobacz Ciągłe dostarczanie za pomocą usługi Azure Pipelines.
Kompilacja zdalna
W przypadku korzystania z kompilacji zdalnej zależności przywracane na serwerze i zależności natywne są zgodne ze środowiskiem produkcyjnym. Spowoduje to utworzenie mniejszego pakietu wdrożeniowego do przesłania. Użyj kompilacji zdalnej podczas tworzenia aplikacji języka Python w systemie Windows. Jeśli Twój projekt ma niestandardowe zależności, możesz użyć zdalnego budowania z dodatkowymi adresami URL indeksu.
Zależności są uzyskiwane zdalnie na podstawie zawartości pliku requirements.txt .
Kompilacja zdalna to zalecana metoda kompilacji. Domyślnie narzędzia Core Tools żądają kompilacji zdalnej, gdy użyjesz następującego func azure functionapp publish polecenia, aby opublikować projekt w języku Python na platformie Azure.
func azure functionapp publish <APP_NAME>
Pamiętaj, aby zastąpić <APP_NAME> ciąg nazwą aplikacji funkcji na platformie Azure.
Rozszerzenie usługi Azure Functions dla programu Visual Studio Code domyślnie żąda również kompilacji zdalnej.
Kompilacja lokalna
Zależności są uzyskiwane lokalnie na podstawie zawartości pliku requirements.txt . Możesz uniemożliwić wykonywanie kompilacji zdalnej przy użyciu następującego func azure functionapp publish polecenia w celu opublikowania przy użyciu kompilacji lokalnej:
func azure functionapp publish <APP_NAME> --build local
Pamiętaj, aby zastąpić <APP_NAME> ciąg nazwą aplikacji funkcji na platformie Azure.
W przypadku korzystania z --build local tej opcji zależności projektu są odczytywane z pliku requirements.txt , a te pakiety zależne są pobierane i instalowane lokalnie. Pliki i zależności projektu są wdrażane z komputera lokalnego na platformie Azure. Spowoduje to przekazanie większego pakietu wdrożeniowego na platformę Azure. Jeśli z jakiegoś powodu nie można pobrać pliku requirements.txt przy użyciu narzędzi Core Tools, musisz użyć opcji zależności niestandardowych do publikowania.
Nie zalecamy używania kompilacji lokalnych podczas tworzenia lokalnie w systemie Windows.
Zależności niestandardowe
Jeśli projekt ma zależności, które nie znajdują się w indeksie pakietów języka Python, istnieją dwa sposoby kompilowania projektu. Pierwszy sposób, metoda kompilacji , zależy od sposobu kompilowania projektu.
Zdalna kompilacja z dodatkowym adresem URL indeksu
Jeśli pakiety są dostępne z dostępnego niestandardowego indeksu pakietów, użyj kompilacji zdalnej. Przed opublikowaniem pamiętaj o utworzeniu ustawienia aplikacji o nazwie PIP_EXTRA_INDEX_URL. Wartość tego ustawienia to adres URL niestandardowego indeksu pakietu. Użycie tego ustawienia powoduje, że kompilacja zdalna zostanie uruchomiona pip install--extra-index-url przy użyciu opcji . Aby dowiedzieć się więcej, zobacz dokumentacjępip installPython.
Możesz również używać podstawowych poświadczeń uwierzytelniania z dodatkowymi adresami URL indeksów pakietów. Aby dowiedzieć się więcej, zobacz Podstawowe poświadczenia uwierzytelniania w dokumentacji języka Python.
Instalowanie pakietów lokalnych
Jeśli projekt używa pakietów, które nie są publicznie dostępne dla naszych narzędzi, możesz udostępnić je aplikacji, umieszczając je w katalogu __app__/.python_packages . Przed opublikowaniem uruchom następujące polecenie, aby zainstalować zależności lokalnie:
pip install --target="<PROJECT_DIR>/.python_packages/lib/site-packages" -r requirements.txt
W przypadku używania zależności niestandardowych należy użyć --no-build opcji publikowania, ponieważ zależności zostały już zainstalowane w folderze projektu.
func azure functionapp publish <APP_NAME> --no-build
Pamiętaj, aby zastąpić <APP_NAME> ciąg nazwą aplikacji funkcji na platformie Azure.
Testowanie jednostek
Testowanie jednostkowe za pomocą narzędzia pytest
Funkcje napisane w języku Python mogą być testowane jak inny kod języka Python przy użyciu standardowych struktur testowania. W przypadku większości powiązań można utworzyć pozorny obiekt wejściowy, tworząc wystąpienie odpowiedniej klasy z azure.functions pakietu.
azure.functions Ponieważ pakiet nie jest natychmiast dostępny, pamiętaj, aby zainstalować go za pośrednictwem pliku requirements.txt zgodnie z opisem w powyższej sekcji zarządzania pakietami.
W przypadku my_second_function na przykład poniżej przedstawiono pozorny test funkcji wyzwalanej przez protokół HTTP:
Najpierw utwórz <plik project_root>/my_second_function/function.json , a następnie zdefiniuj tę funkcję jako wyzwalacz HTTP.
{
"scriptFile": "__init__.py",
"entryPoint": "main",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Następnie możesz zaimplementować elementy my_second_function i shared_code.my_second_helper_function.
# <project_root>/my_second_function/__init__.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
# Define an HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Możesz rozpocząć pisanie przypadków testowych dla wyzwalacza HTTP.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from my_second_function import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
resp = main(req)
# Check the output.
self.assertEqual(resp.get_body(), b'21 * 2 = 42',)
.venv W folderze środowiska wirtualnego języka Python zainstaluj ulubioną strukturę testową języka Python, taką jak pip install pytest. Następnie uruchom polecenie pytest tests , aby sprawdzić wynik testu.
Najpierw utwórz <plik project_root>/function_app.py i zaimplementuj my_second_function funkcję jako wyzwalacz HTTP i shared_code.my_second_helper_function.
# <project_root>/function_app.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
app = func.FunctionApp()
# Define the HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
@app.function_name(name="my_second_function")
@app.route(route="hello")
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Możesz rozpocząć pisanie przypadków testowych dla wyzwalacza HTTP.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from function_app import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
func_call = main.build().get_user_function()
resp = func_call(req)
# Check the output.
self.assertEqual(
resp.get_body(),
b'21 * 2 = 42',
)
W folderze środowiska wirtualnego .venv Python zainstaluj ulubioną strukturę testową języka Python, taką jak pip install pytest. Następnie uruchom polecenie pytest tests , aby sprawdzić wynik testu.
Testowanie jednostkowe przez bezpośrednie wywołanie funkcji
Za pomocą azure-functions >= 1.21.0funkcji można również wywoływać bezpośrednio przy użyciu interpretera języka Python. W tym przykładzie pokazano, jak przetestować wyzwalacz HTTP przy użyciu modelu programowania w wersji 2:
# <project_root>/function_app.py
import azure.functions as func
import logging
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
@app.route(route="http_trigger")
def http_trigger(req: func.HttpRequest) -> func.HttpResponse:
return "Hello, World!"
print(http_trigger(None))
W przypadku tego podejścia dodatkowe pakiety i konfiguracja nie są wymagane. Funkcję można przetestować, wywołując python function_app.py, co skutkuje wyjściem Hello, World! w terminalu.
Uwaga
Durable Functions wymagają specjalnej składni do testowania jednostkowego. Aby uzyskać więcej informacji, zapoznaj się z artykułem Unit Testing Durable Functions in Python (Testowanie jednostkowe rozszerzenia Durable Functions w języku Python)
Pliki tymczasowe
Metoda tempfile.gettempdir() zwraca folder tymczasowy, który w systemie Linux to /tmp. Aplikacja może używać tego katalogu do przechowywania plików tymczasowych, które są generowane i używane przez funkcje podczas ich uruchamiania.
Ważne
Pliki zapisane w katalogu tymczasowym nie mają gwarancji, że będą utrwalane w wywołaniach. Podczas skalowania w poziomie pliki tymczasowe nie są udostępniane między wystąpieniami.
Poniższy przykład tworzy nazwany plik tymczasowy w katalogu tymczasowym (/tmp):
import logging
import azure.functions as func
import tempfile
from os import listdir
#---
tempFilePath = tempfile.gettempdir()
fp = tempfile.NamedTemporaryFile()
fp.write(b'Hello world!')
filesDirListInTemp = listdir(tempFilePath)
Zalecamy zachowanie testów w folderze, który jest oddzielony od folderu projektu. Ta akcja uniemożliwia wdrażanie kodu testowego za pomocą aplikacji.
Wstępnie zainstalowane biblioteki
Kilka bibliotek jest dostarczanych ze środowiskiem uruchomieniowym funkcji języka Python.
Standardowa biblioteka języka Python
Biblioteka standardowa języka Python zawiera listę wbudowanych modułów języka Python dostarczanych z każdą dystrybucją języka Python. Większość tych bibliotek umożliwia dostęp do funkcjonalności systemowych, takich jak wejście/wyjście plików (I/O). W systemach Windows te biblioteki są instalowane z językiem Python. W systemach opartych na systemie Unix są one dostarczane przez kolekcje pakietów.
Aby wyświetlić bibliotekę dla używanej wersji języka Python, przejdź do:
- Standardowa biblioteka języka Python 3.10
- Standardowa biblioteka języka Python 3.11
- Standardowa biblioteka języka Python 3.12
- Standardowa biblioteka języka Python 3.13
Zależności procesu roboczego języka Python usługi Azure Functions
Proces roboczy języka Python usługi Azure Functions wymaga określonego zestawu bibliotek. Możesz również używać tych bibliotek w funkcjach, ale nie są one częścią standardu języka Python. Jeśli funkcje korzystają z dowolnej z tych bibliotek, mogą być niedostępne dla kodu, gdy działa poza usługą Azure Functions.
Uwaga
Jeśli plik requirements.txt aplikacji funkcji zawiera azure-functions-worker wpis, usuń go. Proces roboczy funkcji jest automatycznie zarządzany przez platformę Azure Functions i regularnie aktualizujemy go przy użyciu nowych funkcji i poprawek błędów. Ręczne zainstalowanie starej wersji modułu worker w pliku requirements.txt może spowodować nieoczekiwane problemy.
Uwaga
Jeśli pakiet zawiera pewne biblioteki, które mogą kolidować z zależnościami zadania roboczego (np. protobuf, TensorFlow lub grpcio), skonfiguruj PYTHON_ISOLATE_WORKER_DEPENDENCIES do 1 w ustawieniach aplikacji, aby uniemożliwić aplikacji odwoływanie się do zależności zadania roboczego.
Biblioteka języka Python usługi Azure Functions
Każda aktualizacja procesu roboczego języka Python obejmuje nową wersję biblioteki języka Python usługi Azure Functions (azure.functions). Takie podejście ułatwia ciągłe aktualizowanie aplikacji funkcji języka Python, ponieważ każda aktualizacja jest zgodna z poprzednimi wersjami. Aby uzyskać listę wydań tej biblioteki, przejdź do azure-functions PyPi.
Wersja biblioteki środowiska uruchomieniowego jest ustawiana przez platformę Azure i nie można jej zastąpić przez requirements.txt.
azure-functions Wpis w requirements.txt służy tylko do lintingu i informowania klientów.
Użyj następującego kodu, aby śledzić rzeczywistą wersję biblioteki funkcji języka Python w środowisku uruchomieniowym:
getattr(azure.functions, '__version__', '< 1.2.1')
Biblioteki systemowe środowiska uruchomieniowego
Aby uzyskać listę wstępnie zainstalowanych bibliotek systemowych w obrazach Docker dla pracowników Pythona, zobacz poniżej:
| Środowisko uruchomieniowe usługi Functions | Wersja debiana | Wersje języka Python |
|---|---|---|
| Wersja 3.x | Buster | Python 3.7 Python 3.8 Python 3.9 |
Rozszerzenia procesu roboczego języka Python
Proces roboczy języka Python uruchamiany w usłudze Azure Functions umożliwia integrację bibliotek innych firm z aplikacją funkcji. Te biblioteki rozszerzeń działają jako oprogramowanie pośredniczące, które może wprowadzać określone operacje podczas cyklu życia wykonywania funkcji.
Rozszerzenia są importowane w kodzie funkcji podobnie jak standardowy moduł biblioteki języka Python. Rozszerzenia są uruchamiane w oparciu o następujące zakresy:
| Scope | opis |
|---|---|
| Poziom aplikacji | Po zaimportowaniu do dowolnego wyzwalacza funkcji rozszerzenie ma zastosowanie do każdego wykonania funkcji w aplikacji. |
| Poziom funkcji | Wykonywanie jest ograniczone do konkretnego wyzwalacza funkcji, do którego ją zaimportowano. |
Przejrzyj informacje dotyczące każdego rozszerzenia, aby dowiedzieć się więcej o zakresie, w którym działa rozszerzenie.
Rozszerzenia implementują interfejs rozszerzenia procesu roboczego języka Python. Ta akcja umożliwia procesowi roboczego języka Python wywołanie kodu rozszerzenia podczas cyklu życia wykonywania funkcji. Aby dowiedzieć się więcej, zobacz Tworzenie rozszerzeń.
Korzystanie z rozszerzeń
Bibliotekę rozszerzenia procesu roboczego języka Python można używać w funkcjach języka Python, wykonując następujące czynności:
- Dodaj pakiet rozszerzenia w pliku requirements.txt dla projektu.
- Zainstaluj bibliotekę w aplikacji.
- Dodaj następujące ustawienia aplikacji:
- Lokalnie: wprowadź
"PYTHON_ENABLE_WORKER_EXTENSIONS": "1"wValuessekcji pliku local.settings.json. - Azure: wprowadź
PYTHON_ENABLE_WORKER_EXTENSIONS=1w ustawieniach aplikacji.
- Lokalnie: wprowadź
- Zaimportuj moduł rozszerzenia do wyzwalacza funkcji.
- W razie potrzeby skonfiguruj wystąpienie rozszerzenia. Wymagania dotyczące konfiguracji należy określić w dokumentacji rozszerzenia.
Ważne
Biblioteki rozszerzeń procesów roboczych języka Python innych firm nie są obsługiwane ani uzasadnione przez firmę Microsoft. Upewnij się, że wszystkie rozszerzenia używane w aplikacji funkcji są wiarygodne i ponosisz pełne ryzyko użycia złośliwego lub źle napisanego rozszerzenia.
Inne firmy powinny podać konkretną dokumentację dotyczącą sposobu instalowania i korzystania ze swoich rozszerzeń w aplikacji funkcyjnej. Aby zapoznać się z podstawowym przykładem korzystania z rozszerzenia, zobacz Korzystanie z rozszerzenia.
Oto przykłady używania rozszerzeń w aplikacji funkcji według zakresu:
# <project_root>/requirements.txt
application-level-extension==1.0.0
# <project_root>/Trigger/__init__.py
from application_level_extension import AppExtension
AppExtension.configure(key=value)
def main(req, context):
# Use context.app_ext_attributes here
Tworzenie rozszerzeń
Rozszerzenia są tworzone przez deweloperów bibliotek innych firm, którzy utworzyli funkcje, które można zintegrować z usługą Azure Functions. Rozszerzenie projektuje, implementuje i zwalnia pakiety języka Python zawierające logikę niestandardową zaprojektowaną specjalnie do uruchamiania w kontekście wykonywania funkcji. Te rozszerzenia można publikować w rejestrze PyPI lub w repozytoriach GitHub.
Aby dowiedzieć się, jak tworzyć, pakować, publikować i korzystać z pakietu rozszerzenia procesu roboczego języka Python, zobacz Tworzenie rozszerzeń procesów roboczych języka Python dla usługi Azure Functions.
Rozszerzenia na poziomie aplikacji
Rozszerzenie dziedziczone z AppExtensionBase przebiegów w zakresie aplikacji .
AppExtensionBase Uwidacznia następujące metody klasy abstrakcyjnej do zaimplementowania:
| Metoda | opis |
|---|---|
init |
Wywoływana po zaimportowaniu rozszerzenia. |
configure |
Wywoływane z kodu funkcji, gdy jest potrzebne do skonfigurowania rozszerzenia. |
post_function_load_app_level |
Wywoływana bezpośrednio po załadowaniu funkcji. Nazwa funkcji i katalog funkcji są przekazywane do rozszerzenia. Należy pamiętać, że katalog funkcji jest tylko do odczytu, a każda próba zapisu w lokalnym pliku w tym katalogu kończy się niepowodzeniem. |
pre_invocation_app_level |
Wywoływana bezpośrednio przed wyzwoleniem funkcji. Argumenty wywołania funkcji i kontekstu funkcji są przekazywane do rozszerzenia. Zazwyczaj można przekazać inne atrybuty w obiekcie kontekstu, aby kod funkcji mógł je wykorzystać. |
post_invocation_app_level |
Wywołana bezpośrednio po zakończeniu wykonywania funkcji. Kontekst funkcji, argumenty wywołania funkcji oraz obiekt zwrotny wywołania są przekazywane do rozszerzenia. Ta implementacja to dobre miejsce na weryfikację, czy wykonanie haków cyklu życia powiodło się. |
Rozszerzenia na poziomie funkcji
Rozszerzenie dziedziczone z bazy danych FuncExtensionBase jest uruchamiane w określonym wyzwalaczu funkcji.
FuncExtensionBase Uwidacznia następujące metody klasy abstrakcyjnej dla implementacji:
| Metoda | opis |
|---|---|
__init__ |
Konstruktor rozszerzenia. Wywoływana jest, gdy instancja rozszerzenia jest inicjowana w konkretnej funkcji. Podczas implementowania tej metody abstrakcyjnej możesz zaakceptować filename parametr i przekazać go do metody super().__init__(filename) nadrzędnej w celu odpowiedniej rejestracji rozszerzenia. |
post_function_load |
Wywoływana bezpośrednio po załadowaniu funkcji. Nazwa funkcji i katalog funkcji są przekazywane do rozszerzenia. Należy pamiętać, że katalog funkcji jest tylko do odczytu, a każda próba zapisu w lokalnym pliku w tym katalogu kończy się niepowodzeniem. |
pre_invocation |
Wywoływana bezpośrednio przed wyzwoleniem funkcji. Argumenty wywołania funkcji i kontekstu funkcji są przekazywane do rozszerzenia. Zazwyczaj można przekazać inne atrybuty w obiekcie kontekstu, aby kod funkcji mógł je wykorzystać. |
post_invocation |
Wywołana bezpośrednio po zakończeniu wykonywania funkcji. Kontekst funkcji, argumenty wywołania funkcji oraz obiekt zwrotny wywołania są przekazywane do rozszerzenia. Ta implementacja to dobre miejsce na weryfikację, czy wykonanie haków cyklu życia powiodło się. |
Współużytkowanie zasobów między źródłami
Usługa Azure Functions obsługuje współużytkowanie zasobów między źródłami (CORS). Mechanizm CORS jest skonfigurowany w portalu i za pośrednictwem interfejsu wiersza polecenia platformy Azure. Lista dozwolonych źródeł mechanizmu CORS ma zastosowanie na poziomie aplikacji funkcji. Po włączeniu Access-Control-Allow-Origin mechanizmu CORS odpowiedzi zawierają nagłówek. Aby uzyskać więcej informacji, zobacz temat Współużytkowanie zasobów między źródłami.
Współużytkowanie zasobów między źródłami (CORS) jest w pełni obsługiwane w przypadku aplikacji funkcji języka Python.
Async
Domyślnie wystąpienie hosta dla języka Python może przetwarzać tylko jedno wywołanie funkcji naraz. Dzieje się tak, ponieważ język Python jest środowiskiem uruchomieniowym jednowątkowym. W przypadku aplikacji funkcjonalnej, która przetwarza dużą liczbę zdarzeń we/wy lub ma ograniczenia związane z we/wy, można znacznie zwiększyć wydajność poprzez asynchroniczne uruchamianie funkcji. Aby uzyskać więcej informacji, zobacz Zwiększanie wydajności aplikacji języka Python w usłudze Azure Functions.
Pamięć udostępniona (wersja zapoznawcza)
Aby zwiększyć przepływność, usługa Azure Functions umożliwia zewnętrznemu procesowi roboczemu języka Python udostępnianie pamięci procesowi hosta funkcji. Gdy aplikacja funkcji osiąga wąskie gardła, możesz włączyć pamięć udostępnioną, dodając ustawienie aplikacji o nazwie FUNCTIONS_WORKER_SHARED_MEMORY_DATA_TRANSFER_ENABLED z wartością 1. Po włączeniu pamięci współdzielonej, można użyć ustawienia DOCKER_SHM_SIZE, aby ustawić pamięć współdzieloną na wartość podobną do 268435456, która jest równoważna 256 MB.
Na przykład możesz włączyć pamięć udostępnioną, aby zmniejszyć wąskie gardła, gdy używasz powiązań usługi Blob Storage do przenoszenia ładunków większych niż 1 MB.
Ta funkcja jest dostępna tylko dla aplikacji funkcji działających w planach Premium i Dedykowanych (Azure App Service). Aby dowiedzieć się więcej, zobacz Pamięć współdzielona.
Znane problemy i często zadawane pytania
Poniżej przedstawiono dwa przewodniki rozwiązywania problemów dotyczące typowych problemów:
Poniżej przedstawiono dwa przewodniki rozwiązywania problemów dotyczące znanych problemów z modelem programowania w wersji 2:
- Nie można załadować pliku lub zestawu
- Nie można rozpoznać połączenia usługi Azure Storage o nazwie Storage
Wszystkie znane problemy i żądania funkcji są śledzone na liście problemów z usługą GitHub. Jeśli napotkasz problem i nie możesz znaleźć problemu w usłudze GitHub, otwórz nowy problem i dołącz szczegółowy opis problemu.
Następne kroki
Aby uzyskać więcej informacji, zobacz następujące zasoby:
- Dokumentacja interfejsu API pakietu usługi Azure Functions
- Najlepsze rozwiązania dotyczące usługi Azure Functions
- Wyzwalacze i powiązania usługi Azure Functions
- Powiązania usługi Blob Storage
- Powiązania protokołu HTTP i elementu webhook
- Powiązania usługi "Queue Storage"
- Wyzwalacze czasowe
Masz problemy z używaniem języka Python? Powiedz nam, co się dzieje.