Dodawanie woluminów dla systemu SAP HANA jako systemu odzyskiwania po awarii przy użyciu replikacji między regionami
W tym artykule opisano używanie grupy woluminów aplikacji do dodawania woluminów dla systemu SAP HANA jako systemu odzyskiwania po awarii (DR). Ta konfiguracja korzysta z funkcji replikacji między regionami (CRR) usługi Azure NetApp Files.
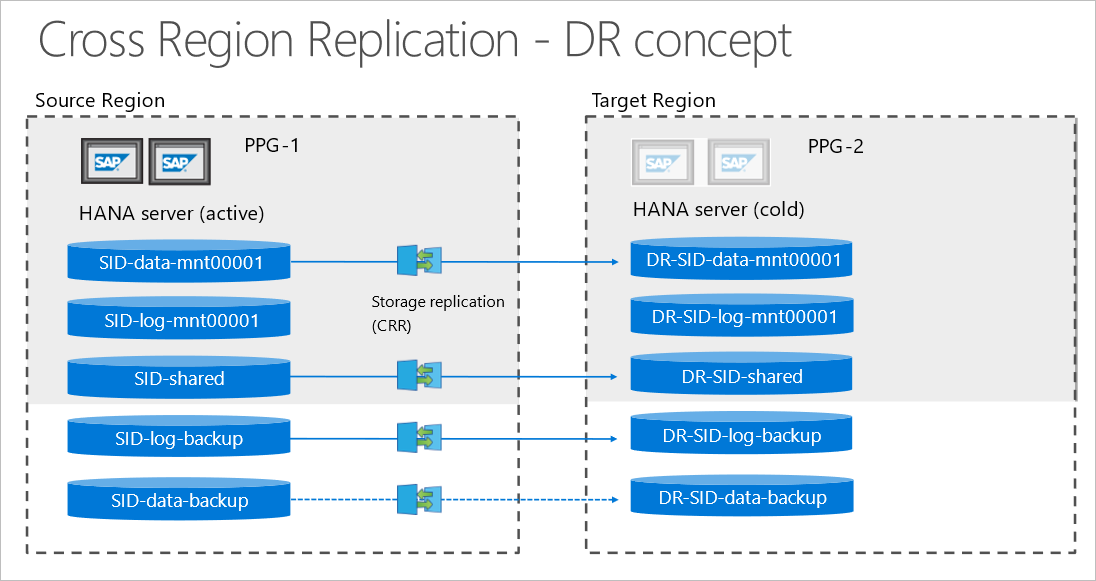
CRR między źródłowymi i docelowymi serwerami HANA
Funkcja replikacji między regionami usługi Azure NetApp Files umożliwia replikowanie woluminów między obsługiwanymi parami replikacji między regionami. Ta funkcja umożliwia replikowanie woluminu z regionu źródłowego do woluminu w regionie docelowym na potrzeby odzyskiwania po awarii.
Zamiast korzystać z replikacji systemu HANA (HSR), można użyć replikacji między regionami, aby chronić bazę danych bez konieczności korzystania z serwera bazy danych HANA, który jest uruchamiany przez cały czas. Należy utworzyć woluminy docelowe replikacji w regionie obsługiwanym na potrzeby replikacji między regionami. Grupa woluminów aplikacji dla platformy SAP HANA zapewnia, że woluminy docelowe są tworzone przy użyciu odpowiedniego typu woluminu spełniającego wszystkie wymagania specyficzne dla oprogramowania SAP HANA.
Na poniższym diagramie przedstawiono replikację między regionami między źródłowymi i docelowymi serwerami HANA. Replikacja między regionami jest asynchroniczna. W związku z tym nie wszystkie woluminy muszą być replikowane.
Uwaga
Jeśli używasz wdrożenia wysokiej dostępności z modułem HSR po stronie podstawowej, możesz wybrać replikację nie tylko podstawowego systemu HANA, jak opisano w tej sekcji, ale także systemu pomocniczego HANA przy użyciu replikacji między regionami. Aby automatycznie dostosować konwencję nazewnictwa, należy wybrać opcje miejsca docelowego odzyskiwania po awarii i pomocniczego modułu HSR na ekranie Tworzenie grupy woluminów. Następnie prefiks zmienia się na DR2-.
Ważne
- Odzyskanie bazy danych HANA w regionie docelowym wymaga użycia migawek magazynu spójnych na poziomie aplikacji na potrzeby kopii zapasowej platformy HANA. Takie migawki można tworzyć przy użyciu rozwiązań ochrony danych, takich jak narzędzie aplikacja systemu Azure Spójne migawki (AzAcSnap).
- Należy replikować co najmniej wolumin danych i wolumin kopii zapasowej dziennika.
- Opcjonalnie można replikować wolumin kopii zapasowej danych i udostępniony wolumin.
- Nigdy nie należy replikować woluminu dziennika. Grupa woluminów aplikacji utworzy wolumin dziennika jako wolumin standardowy.
Harmonogramy replikacji, cel czasu odzyskiwania i cel punktu odzyskiwania
Poniższa tabela zawiera podsumowanie opcji harmonogramu replikacji. Opisuje również ustawienia domyślne proponowane przez grupę woluminów aplikacji:
| Volume type | Domyślny harmonogram replikacji | Dostępne opcje | Uwagi |
|---|---|---|---|
| Data | Codziennie | Codziennie, co godzinę | Wybór ma wpływ na cel odzyskiwania czasu (RTO) i ilość przesyłanych danych. |
| Dziennik | - | - | Woluminy dziennika nie są replikowane. |
| Udostępnione oprogramowanie SAP | Co 10 minut | Co 10 minut, co godzinę, codziennie | Należy wybrać harmonogram na podstawie wymagań umowy SLA i danych przechowywanych w udostępnionym woluminie. |
| Kopia zapasowa danych | Codziennie | Codziennie, co tydzień | Replikowanie woluminów kopii zapasowych danych jest opcjonalne. |
| Kopia zapasowa dziennika | Co 10 minut | Co 10 minut | To ustawienie ma wpływ na cel punktu odzyskiwania (RPO). |
Harmonogram częstotliwości replikacji ma wpływ na umowy SLA:
- Cel czasu odzyskiwania (RTO):
Minimalny czas odzyskiwania trwa.
Aby odzyskać dane przy użyciu najnowszej dostępnej migawki spójnej z aplikacją, należy odtworzyć wszystkie dostępne kopie zapasowe dziennika. Cel czasu odzyskiwania zależy od częstotliwości tworzenia kopii zapasowych i częstotliwości replikacji woluminu danych. Jeśli na przykład częstotliwość tworzenia kopii zapasowych wynosi co 6 godzin, a harmonogram replikacji to "Codziennie", najstarsza kopia zapasowa może wynosić 30 godzin (24 godziny + 6 godzin). W tym scenariuszu wymagane będzie ponowne utworzenie do 30 godzin kopii zapasowych dziennika. - Cel punktu odzyskiwania (RPO):
Minimalna utrata danych, która może wystąpić.
Częstotliwość tworzenia kopii zapasowych dzienników sap HANA wynosi zwykle 15 minut, ale to ustawienie można skonfigurować inaczej. Zakładając, że 10-minutowy harmonogram replikacji kopii zapasowych dziennika, maksymalna utrata transakcji to[15+10+transfer_time]minuty.
Dodawanie woluminów
Poniższy przykład dodaje woluminy do systemu SAP HANA. System służy jako system docelowy odzyskiwania po awarii przy użyciu replikacji między regionami.
Ważne
Opcje tej procedury różnią się w przypadku zarejestrowania grupy woluminów aplikacji dla wersji zapoznawczej rozszerzenia SAP HANA 1. Wybierz odpowiednią kartę dla konfiguracji. Aby skorzystać z tej funkcji, musisz zarejestrować się w celu uzyskania rozszerzenia 1.
Na koncie usługi NetApp wybierz pozycję Grupy woluminów aplikacji, a następnie pozycję +Dodaj grupę.
W obszarze Typ wdrożenia wybierz pozycję SAP HANA , a następnie pozycję Dalej.
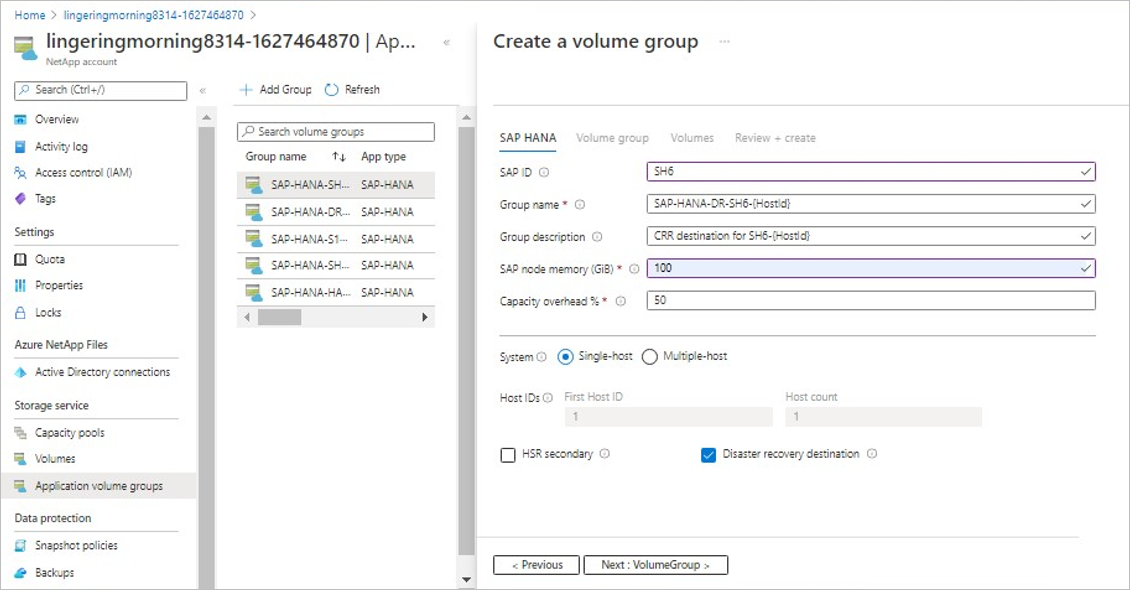
Na karcie SAP HANA podaj informacje specyficzne dla platformy HANA .
Ważne
Pamiętaj, aby wybrać opcję docelową odzyskiwania po awarii, aby wskazać, że tworzysz system HANA jako miejsce docelowe replikacji między regionami.
IDENTYFIKATOR SAP (SID):
Trzy alfanumeryczne-znakowe identyfikator systemu SAP HANA.Nazwa grupy:
Nazwa grupy woluminów.Pamięć węzła SAP:
Ta wartość definiuje rozmiar bazy danych SAP HANA na hoście. Służy do obliczania wymaganego rozmiaru woluminu i przepływności.Obciążenie pojemnością (%):
W przypadku używania migawek do ochrony danych należy zaplanować dodatkową pojemność. To pole spowoduje dodanie dodatkowego rozmiaru (%) dla woluminu danych.
Tę wartość można oszacować przy użyciu polecenia"change rate per day" X "number of days retention".Jeden host:
Wybierz tę opcję dla systemu jedno hosta SAP HANA lub pierwszego hosta dla systemu wielu hostów. Tylko udostępnione, kopii zapasowej dzienników i woluminy kopii zapasowej danych zostaną utworzone przy użyciu pierwszego hosta.Wiele hostów:
Wybierz tę opcję, jeśli dodasz dodatkowe hosty do systemu HANA z wieloma hostami.Miejsce docelowe odzyskiwania po awarii:
Wybierz tę opcję, aby utworzyć woluminy dla systemu HANA jako lokacji odzyskiwania po awarii przy użyciu replikacji między regionami.Wybranie miejsca docelowego odzyskiwania po awarii powoduje wyzwolenie konwencji nazewnictwa nazwy grupy woluminów, która ma być uwzględnina
"-DR-"w celu wskazania konfiguracji odzyskiwania po awarii.
Wybierz pozycję Dalej: grupa woluminów.
Na karcie Grupa woluminów podaj informacje dotyczące tworzenia grupy woluminów:
- Grupa umieszczania w pobliżu (PPG)::
Określa, że dane i udostępnione woluminy mają zostać utworzone w pobliżu maszyn wirtualnych odzyskiwania po awarii.
Nawet jeśli nie potrzebujesz maszyn wirtualnych do replikacji, musisz uruchomić co najmniej jedną maszynę wirtualną, aby zakotwiczyć grupę PPG podczas aprowizowania woluminów. - Pula pojemności:
Wszystkie woluminy są umieszczane w pojedynczej ręcznej puli pojemności QoS.
Jeśli chcesz utworzyć woluminy kopii zapasowej dziennika i kopii zapasowej danych w oddzielnej puli pojemności, możesz nie dodać tych woluminów do grupy woluminów. - Sieć wirtualna:
Określ istniejącą sieć wirtualną, w której są umieszczane maszyny wirtualne. - Podsieć:
Określ podsieć delegowana, w której mają zostać utworzone adresy IP eksportu systemu plików NFS. Upewnij się, że masz podsieć delegowana z wystarczającą ilością bezpłatnych adresów IP.
Wybierz pozycję Dalej: Protokoły.
- Grupa umieszczania w pobliżu (PPG)::
W sekcji Protokoły na karcie Grupa woluminów można zmodyfikować zasady eksportu, które powinny być wspólne dla wszystkich woluminów.
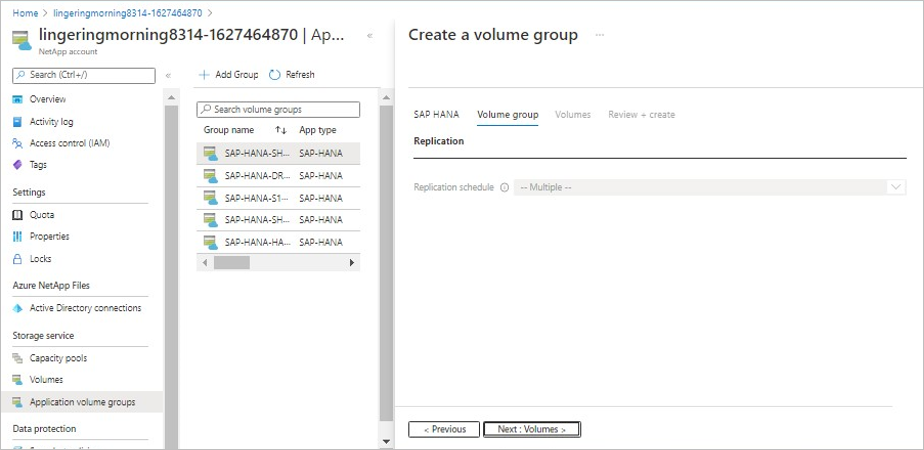
Wybierz pozycję Dalej: Replikacja.
W sekcji Replikacja na karcie Grupa woluminów pole Harmonogram replikacji domyślnie ma wartość "Wiele" (wyłączone). Domyślne harmonogramy replikacji są różne dla replikowanych woluminów. W związku z tym można modyfikować harmonogramy replikacji tylko dla każdego woluminu indywidualnie na karcie Woluminy, a nie globalnie dla całej grupy woluminów.
Wybierz pozycję Dalej: tagi.
W sekcji Tagi na karcie Grupa woluminów można dodawać tagi zgodnie z potrzebami dla woluminów.
Wybierz pozycję Dalej: woluminy.
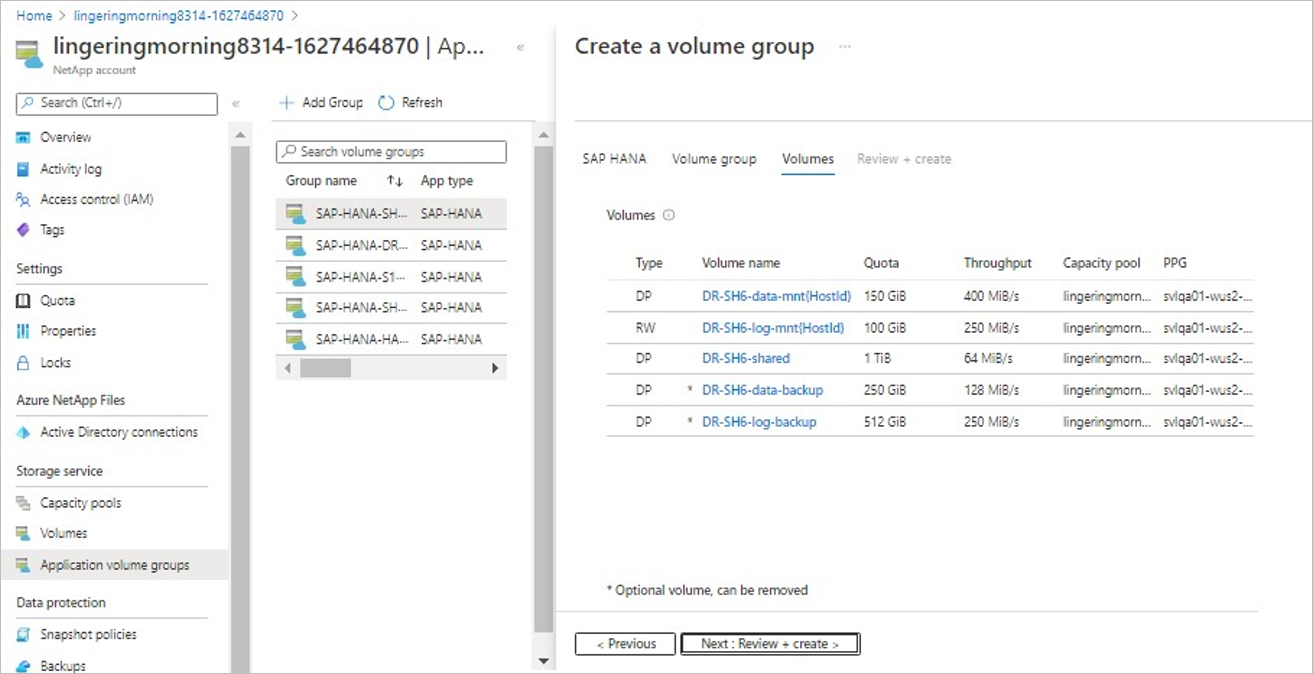
Na karcie Woluminy zostanie wyświetlona lista woluminów.
Konwencja nazewnictwa woluminów zawiera
"DR-"prefiks wskazujący, że woluminy należą do strony odzyskiwania po awarii (miejsca docelowego) konfiguracji.Na karcie Woluminy jest również wyświetlany typ woluminu:
- DP — wskazuje miejsce docelowe w ustawieniu replikacji między regionami. Woluminy tego typu nie są w trybie online, ale w trybie replikacji.
- RW — wskazuje, że odczyty i zapisy są dozwolone.
Domyślnym typem woluminu dziennika jest
RW, a ustawienie nie można zmienić.Domyślnym typem woluminów danych, udostępnionych i kopii zapasowych dziennika jest
DP, a ustawienie nie można zmienić.Domyślnym typem woluminu kopii zapasowej danych jest DP, ale to ustawienie można zmienić na RW.
Wybierz każdy wolumin z typem dp, aby określić identyfikator woluminu źródłowego. Aby uzyskać więcej informacji, zobacz Lokalizowanie identyfikatora zasobu woluminu źródłowego.
Opcjonalnie można zmienić domyślny harmonogram replikacji woluminu. Zobacz Harmonogramy replikacji, cel czasu odzyskiwania i cel punktu odzyskiwania, aby uzyskać opcje harmonogramu replikacji.
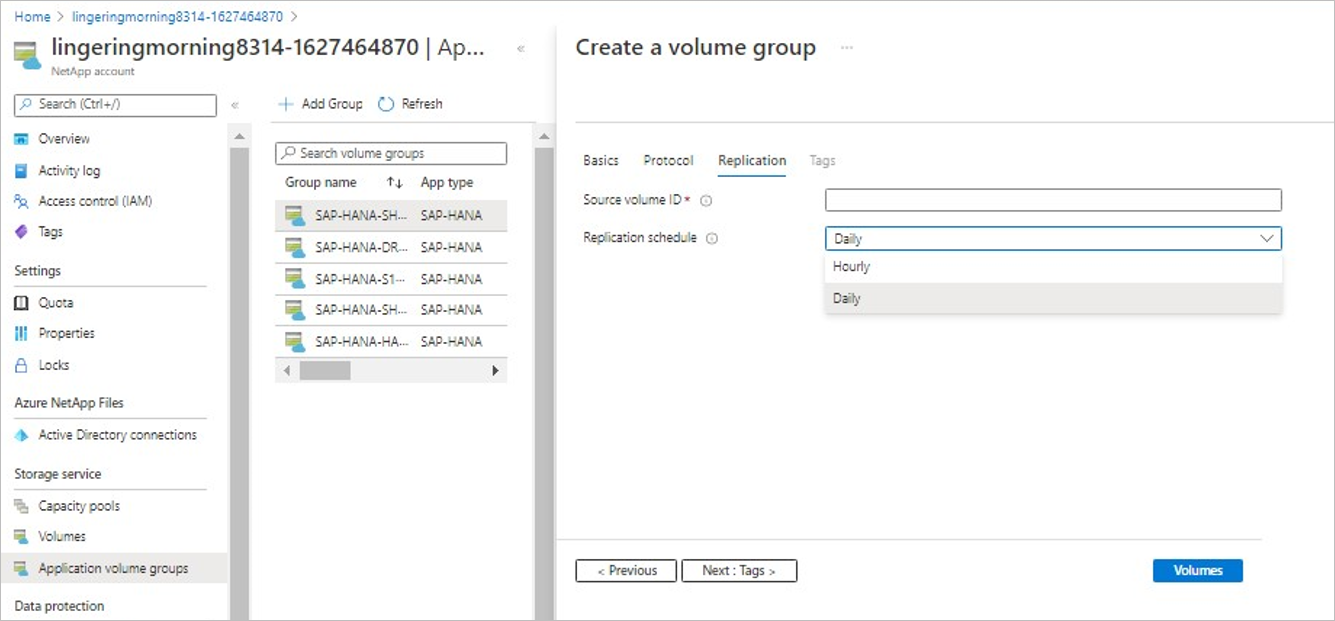
Po utworzeniu grupy woluminów skonfiguruj replikację, postępując zgodnie z instrukcjami w temacie Autoryzowanie replikacji z woluminu źródłowego.
Dla każdego utworzonego woluminu dp skopiuj identyfikator zasobu woluminu.
Dla każdego woluminu źródłowego wybierz pozycję Replikacja, a następnie pozycję Autoryzuj. Wklej identyfikator zasobu każdego odpowiadającego woluminu docelowego.






Opcje instalacji replikowania bazy danych SAP HANA przy użyciu replikacji systemu HANA na potrzeby wysokiej dostępności
W niektórych sytuacjach warto połączyć konfigurację wysokiej dostępności replikacji systemu HANA z konfiguracją odzyskiwania po awarii (DR) przy użyciu replikacji między regionami. W zależności od określonego wzorca użycia i umowy dotyczącej poziomu usług (SLA) możliwe są dwie opcje konfiguracji replikacji. W tej sekcji opisano opcje.
Replikowanie tylko podstawowych woluminów bazy danych HANA
W tym scenariuszu zazwyczaj nie zmieniasz ról dla systemów podstawowych i pomocniczych. Przejęcie odbywa się tylko w nagłych wypadkach. W związku z tym kopie zapasowe migawek spójne na poziomie aplikacji wymagane do replikacji między regionami są wykonywane głównie na hoście podstawowym. Dzieje się tak, ponieważ tylko podstawowa baza danych HANA może służyć do tworzenia kopii zapasowej.
Na poniższym diagramie opisano ten scenariusz:

W tym scenariuszu konfiguracja odzyskiwania po awarii musi zawierać tylko woluminy podstawowego systemu HANA. Dzięki codziennej replikacji woluminu danych podstawowych i kopii zapasowych dziennika systemów podstawowych i pomocniczych system można odzyskać w lokacji odzyskiwania po awarii. Na diagramie pojedynczy wolumin jest używany do tworzenia kopii zapasowych dziennika systemów podstawowych i pomocniczych.
W przypadku przejęcia przez pomocniczego hosta HSR kopie zapasowe wykonywane w systemie pomocniczym nie są replikowane, ale kopie zapasowe dziennika pomocniczego nadal są replikowane. Jeśli wystąpi awaria, system w lokacji odzyskiwania po awarii nadal można odzyskać przy użyciu starej kopii zapasowej migawki z poprzedniego podstawowego i replikowanych kopii zapasowych dziennika z obu hostów. Cel czasu odzyskiwania zwiększa się, ponieważ należy odzyskać więcej dzienników, w zależności od tego, jak długo para HSR działa w trybie przejęcia. Jeśli tryb przejęcia jest znacznie dłuższy, a cel czasu odzyskiwania staje się problemem, należy skonfigurować nową replikację między regionami, w tym ilość danych systemu pomocniczego.
Przepływ pracy dla tego scenariusza jest identyczny z przepływem pracy Dodawanie woluminów .
Replikowanie woluminów podstawowej i pomocniczej bazy danych HANA
Ze względów innych niż wysoka dostępność można okresowo przełączać role między podstawowymi i pomocniczymi systemami HANA. W tym scenariuszu kopie zapasowe spójne na poziomie aplikacji muszą być tworzone na obu hostach HANA.
Na poniższym diagramie opisano ten scenariusz:

W tym scenariuszu można replikować oba zestawy woluminów z podstawowych i pomocniczych systemów HANA, jak pokazano na diagramie.
Aby utworzyć woluminy dla obiektu docelowego replikacji pomocniczej, zostanie dostosowana konwencja nazewnictwa. Aby odróżnić replikację podstawowej i pomocniczej bazy danych, prefiks zmienia się z DR na DR2 dla pomocniczego systemu HANA. Z wyjątkiem tej zmiany nazwy przepływ pracy jest identyczny z przepływem pracy Dodawanie woluminów .
Uwaga
Aby zapoznać się ze szczegółowym omówieniem rozwiązania odzyskiwania po awarii dla platformy HANA z usługą Azure NetApp Files, zobacz Raport techniczny netApp TR-4891: odzyskiwanie po awarii platformy SAP HANA za pomocą usługi Azure NetApp Files. Raport techniczny zawiera szczegółowe informacje i przykłady dotyczące używania replikacji między regionami dla platformy SAP HANA w usłudze Azure NetApp Files.
Następne kroki
- Omówienie grupy woluminów aplikacji usługi Azure NetApp Files dla platformy SAP HANA
- Wymagania i zagadnienia dotyczące grupy woluminów aplikacji dla platformy SAP HANA
- Wdrażanie pierwszego hosta SAP HANA przy użyciu grupy woluminów aplikacji dla platformy SAP HANA
- Dodawanie hostów do systemu SAP HANA z wieloma hostami przy użyciu grupy woluminów aplikacji dla platformy SAP HANA
- Dodawanie woluminów dla systemu SAP HANA jako pomocniczej bazy danych w module HSR
- Zarządzanie woluminami w grupie woluminów aplikacji
- Usuwanie grupy woluminów aplikacji
- Często zadawane pytania dotyczące grupy woluminów aplikacji
- Rozwiązywanie problemów z błędami grupy woluminów aplikacji
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla