Ładowanie danych do usługi Azure Data Lake Storage Gen2 za pomocą usługi Azure Data Factory
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Azure Data Lake Storage Gen2 to zestaw funkcji przeznaczonych do analizy danych big data wbudowanych w usługę Azure Blob Storage. Umożliwia ona interfejs z danymi przy użyciu zarówno paradygmatów systemu plików, jak i magazynu obiektów.
Azure Data Factory (ADF) to w pełni zarządzana usługa integracji danych w chmurze. Za pomocą usługi można wypełnić je danymi z bogatego zestawu lokalnych i opartych na chmurze magazynów danych oraz zaoszczędzić czas podczas tworzenia rozwiązań analitycznych. Aby uzyskać szczegółową listę obsługiwanych łączników, zobacz tabelę Obsługiwanych magazynów danych.
Usługa Azure Data Factory oferuje skalowane w poziomie rozwiązanie do przenoszenia danych zarządzanych. Ze względu na architekturę skalowania w poziomie usługi ADF może pozyskiwać dane przy wysokiej przepływności. Aby uzyskać szczegółowe informacje, zobacz działanie Kopiuj wydajność.
W tym artykule pokazano, jak za pomocą narzędzia do kopiowania danych usługi Data Factory załadować dane z usługi Amazon Web Services S3 do usługi Azure Data Lake Storage Gen2. Możesz wykonać podobne kroki, aby skopiować dane z innych typów magazynów danych.
Napiwek
Aby skopiować dane z usługi Azure Data Lake Storage Gen1 do usługi Gen2, zapoznaj się z tym konkretnym przewodnikiem.
Wymagania wstępne
- Subskrypcja platformy Azure: jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto .
- Konto usługi Azure Storage z włączoną usługą Data Lake Storage Gen2: jeśli nie masz konta magazynu, utwórz konto.
- Konto platformy AWS z zasobnikiem S3 zawierającym dane: w tym artykule pokazano, jak skopiować dane z usługi Amazon S3. Możesz użyć innych magazynów danych, wykonując podobne kroki.
Tworzenie fabryki danych
Jeśli fabryka danych nie została jeszcze utworzona, wykonaj kroki opisane w przewodniku Szybki start: Tworzenie fabryki danych przy użyciu witryny Azure Portal i programu Azure Data Factory Studio , aby je utworzyć. Po utworzeniu przejdź do fabryki danych w witrynie Azure Portal.
Wybierz pozycję Otwórz na kafelku Otwórz usługę Azure Data Factory Studio, aby uruchomić aplikację Integracja danych na osobnej karcie.
Ładowanie danych do usługi Azure Data Lake Storage Gen2
Na stronie głównej usługi Azure Data Factory wybierz kafelek Pozyskiwanie , aby uruchomić narzędzie do kopiowania danych.
Na stronie Właściwości wybierz pozycję Wbudowane zadanie kopiowania w obszarze Typ zadania, a następnie wybierz pozycję Uruchom raz w obszarze Harmonogram zadań lub harmonogram zadań, a następnie wybierz przycisk Dalej.

Na stronie Źródłowy magazyn danych wykonaj następujące kroki:
Wybierz + Nowe połączenie. Wybierz pozycję Amazon S3 z galerii łączników i wybierz pozycję Kontynuuj.

Na stronie Nowe połączenie (Amazon S3) wykonaj następujące czynności:
- Określ wartość Identyfikator klucza dostępu.
- Określ wartość Klucza dostępu tajnego.
- Wybierz pozycję Testuj połączenie , aby zweryfikować ustawienia, a następnie wybierz pozycję Utwórz.

Na stronie Źródłowy magazyn danych upewnij się, że nowo utworzone połączenie Amazon S3 zostało wybrane w bloku Połączenie.
W sekcji Plik lub folder przejdź do folderu i pliku, który chcesz skopiować. Wybierz folder/plik, a następnie wybierz przycisk OK.
Określ zachowanie kopiowania, sprawdzając opcje cyklicznie i kopiowania binarnego. Wybierz Dalej.

Na stronie Docelowy magazyn danych wykonaj następujące kroki.
Wybierz pozycję + Nowe połączenie, a następnie wybierz pozycję Azure Data Lake Storage Gen2, a następnie wybierz pozycję Kontynuuj.

Na stronie Nowe połączenie (Azure Data Lake Storage Gen2) wybierz swoje konto obsługujące usługę Data Lake Storage Gen2 z listy rozwijanej "Nazwa konta magazynu", a następnie wybierz pozycję Utwórz, aby utworzyć połączenie.

Na stronie Docelowy magazyn danych wybierz nowo utworzone połączenie w bloku Połączenie. Następnie w obszarze Ścieżka folderu wprowadź wartość copyfroms3 jako nazwę folderu wyjściowego, a następnie wybierz pozycję Dalej. Usługa ADF utworzy odpowiedni system plików usługi ADLS Gen2 i podfoldery podczas kopiowania, jeśli nie istnieje.

Na stronie Ustawienia określ wartość CopyFromAmazonS3ToADLS dla pola Nazwa zadania, a następnie wybierz przycisk Dalej, aby użyć ustawień domyślnych.

Na stronie Podsumowanie przejrzyj ustawienia i wybierz pozycję Dalej.

Na stronie Wdrażanie wybierz pozycję Monitorowanie, aby monitorować potok (zadanie).
Po pomyślnym zakończeniu przebiegu potoku zostanie wyświetlony przebieg potoku wyzwalany przez wyzwalacz ręczny. Możesz użyć linków w kolumnie Nazwa potoku, aby wyświetlić szczegóły działania i ponownie uruchomić potok.
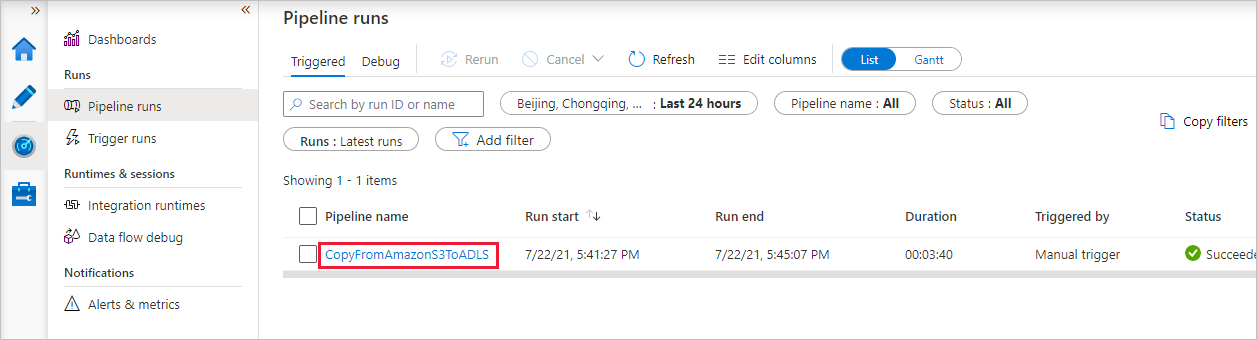
Aby wyświetlić uruchomienia działań skojarzone z uruchomieniem potoku, wybierz link CopyFromAmazonS3ToADLS w kolumnie Nazwa potoku. Aby uzyskać szczegółowe informacje na temat operacji kopiowania, wybierz link Szczegóły (ikona okularów) w kolumnie Nazwa działania. Możesz monitorować szczegóły, takie jak ilość danych skopiowanych ze źródła do ujścia, przepływność danych, kroki wykonywania z odpowiednim czasem trwania i użytą konfiguracją.


Aby odświeżyć widok, wybierz pozycję Odśwież. Wybierz pozycję Wszystkie uruchomienia potoku u góry, aby wrócić do widoku "Uruchomienia potoku".
Sprawdź, czy dane są kopiowane na konto usługi Data Lake Storage Gen2.