Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule wyjaśniono, jak używać tagów do przypisywanie użycia zasobów obliczeniowych do określonych obszarów roboczych, zespołów, projektów lub użytkowników w celu obsługi śledzenia kosztów i budżetowania.
Istnieją dwa typy tagów:
- Tagi domyślne: automatycznie stosowane przez usługę Databricks do zasobów wdrożonych w chmurze. Zapewniają one podstawowe metadane, takie jak dostawca, identyfikator klastra i twórca.
- Tagi niestandardowe: tagi zdefiniowane przez użytkownika, które można dodać do zasobów obliczeniowych i obciążeń bezserwerowych. Umożliwiają one szczegółowe śledzenie, raportowanie i budżetowanie.
Ostrzeżenie
Dane tagów są przechowywane jako zwykły tekst i mogą być replikowane globalnie. Nie używaj nazw tagów, wartości ani deskryptorów, które mogą naruszyć bezpieczeństwo zasobów. Na przykład nie należy używać nazw tagów, wartości ani deskryptorów zawierających informacje osobiste lub poufne.
Tagi domyślne
Azure Databricks automatycznie dodaje tagi domyślne do zasobów obliczeniowych wdrażanych na koncie chmury. Tagi te przypiszeją użycie do usługi Databricks i udostępniają podstawowe informacje o zasobie, takie jak jego nazwa, identyfikator i twórca.
Tagi domyślne są automatycznie propagowane do szczegółowych raportów analizy kosztów , do których można uzyskać dostęp w portalu Azure.
Oto raport szczegółowy dotyczący analizy kosztów z faktury w portalu Azure, zawierający informacje o kosztach według tagu clusterid, w ciągu miesiąca.
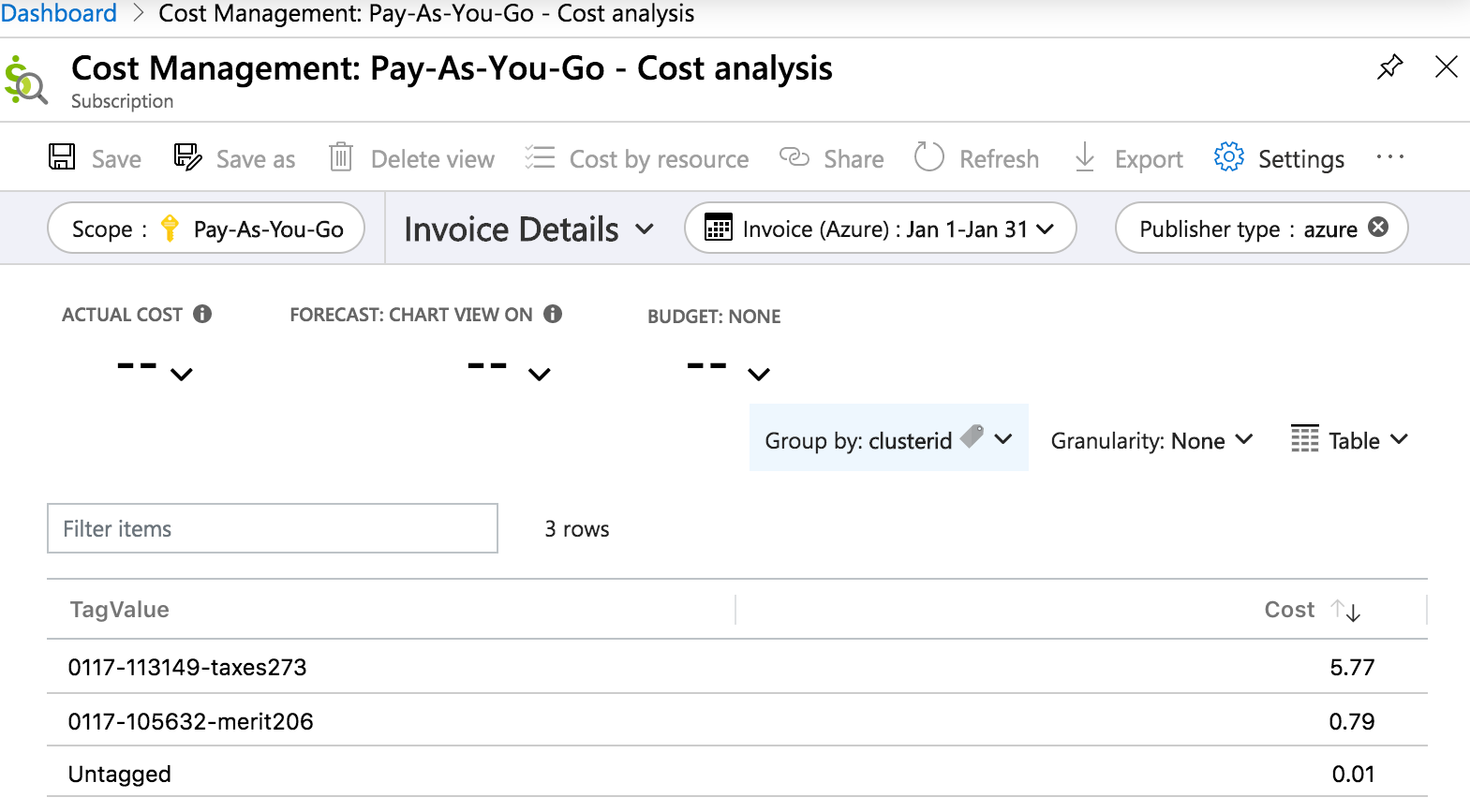
Domyślne klucze i wartości tagów
Azure Databricks dodaje następujące tagi domyślne do zasobów obliczeniowych:
| Klucz tagu | Wartość |
|---|---|
Vendor |
Stała wartość: Databricks |
ClusterId |
Azure Databricks identyfikator wewnętrzny klastra |
ClusterName |
Nazwa klastra |
Creator |
Nazwa użytkownika (adres e-mail) użytkownika, który utworzył klaster |
RunName |
Nazwa zadania (propaguje się tylko w obliczeniach zadań). Jeśli używasz interfejsu API zadań w wersji 2.0, jest to równoważne z run_name. W API zadań 2.1 jest to task_key. |
JobId |
Identyfikator zadania (propaguje się tylko w obliczeniach zadań) |
Obliczenia używane przez profilowanie danych obejmują następujące dodatkowe tagi:
| Klucz tagu | Wartość |
|---|---|
LakehouseMonitoring |
prawda |
LakehouseMonitoringTableId |
Identyfikator monitorowanej tabeli |
LakehouseMonitoringWorkspaceId |
Identyfikator obszaru roboczego, w którym utworzono monitor |
LakehouseMonitoringMetastoreId |
Identyfikator magazynu metadanych, w którym istnieje monitorowana tabela |
Azure Databricks dodaje następujące tagi domyślne do pul i zasobów obliczeniowych utworzonych przez pule.
| Klucz tagu | Wartość |
|---|---|
Vendor |
Stała wartość: Databricks |
DatabricksInstancePoolCreatorId |
Identyfikator wewnętrzny użytkownika Azure Databricks, który utworzył pulę |
DatabricksInstancePoolId |
Identyfikator wewnętrzny puli na platformie Azure Databricks |
Tagi niestandardowe
Tagi niestandardowe umożliwiają przypisywanie użycia zasobów obliczeniowych do określonych zespołów, projektów lub centrów kosztów z większą szczegółowością niż tagi domyślne. Te tagi są stosowane przez użytkowników lub administratorów i propagowane zarówno do dzienników użycia konta, jak i odpowiednich zasobów w chmurze. Te tagi są również używane do tworzenia i monitorowania budżetów na koncie Azure Databricks.
Obsługiwane zasoby dla tagów niestandardowych
| Objekt | Interfejs znakowania (UI) | Interfejs tagowania (API) |
|---|---|---|
| Obszar roboczy | Azure Portal | interfejs API zasobów Azure |
| Pula | Interfejs użytkownika pul w obszarze roboczym Azure Databricks | API puli wystąpień |
| Wielozadaniowe i wszechstronne obliczenia | Interfejs użytkownika obliczeń w obszarze roboczym Azure Databricks | Interfejs API klastrów |
| SQL Warehouse | Interfejs użytkownika usługi SQL Warehouse w obszarze roboczym Azure Databricks | Interfejs API magazynów |
| Instancja bazy danych | Interfejs użytkownika instancji bazy danych w środowisku pracy Azure Databricks | Interfejs API wystąpień bazy danych |
| Projekt skalowania automatycznego w usłudze Lakebase | Aplikacja Lakebase w obszarze roboczym Azure Databricks | Postgres API |
Ostrzeżenie
Nie przypisuj tagu niestandardowego z kluczem Name do klastra. Każdy klaster ma tag Name, którego wartość jest ustawiana przez Azure Databricks. Jeśli zmienisz wartość skojarzona z kluczem Name, klaster nie może być już śledzony przez Azure Databricks. W związku z tym klaster może nie zostać przerwany po stanie bezczynności i będzie nadal ponosić koszty użycia.
Tagowanie bezserwerowych obciążeń obliczeniowych
Aby przypisywać bezserwerowe użycie zasobów obliczeniowych użytkownikom, grupom lub projektom, można użyć zasad użycia bezserwerowego. Gdy użytkownik ma przypisane zasady użycia bezserwerowego, jego użycie bezserwerowe jest automatycznie oznaczane niestandardowymi tagami tych zasad. Zasady użycia bezserwerowego można stosować do notesów bezserwerowych, zadań, potoków i punktów końcowych obsługujących model.
Uwaga / Notatka
Użycie zasobów obliczeniowych w modelu bezserwerowym jest rejestrowane w tabeli systemowej rozliczalnego użycia na koncie. Starsze raporty użycia jednostek DBU nie zawierają tagów zasad użycia bezserwerowego ani bezserwerowego użycia.
Zobacz Użycie atrybutów z zasadami użycia bezserwerowymi.
Propagacja tagów
Tagi obszarów roboczych, puli i klastra są agregowane przez Azure Databricks i propagowane do maszyn wirtualnych Azure w celu raportowania analizy kosztów. Jednak tagi puli i klastra są propagowane w różny sposób.
Tagi obszaru roboczego i puli są agregowane i przypisywane jako tagi zasobów maszyn wirtualnych Azure hostujących pule.
Tagi obszaru roboczego i klastra są agregowane i przypisywane jako tagi zasobów maszyn wirtualnych Azure hostujących klastry.
Gdy klastry są tworzone na podstawie pul, tylko tagi obszaru roboczego i tagi puli są propagowane do maszyn wirtualnych. Tagi klastra nie są propagowane, aby zachować wydajność uruchamiania klastrów w puli.
Rozwiązywanie konfliktów związanych z tagami
Gdy tag niestandardowy (obszar roboczy, klaster lub tag puli) ma taką samą nazwę klucza jak tag domyślny Azure Databricks, tag niestandardowy jest automatycznie poprzedzony x_ podczas propagacji. Domyślny tag Azure Databricks zachowuje oryginalną nazwę klucza.
Na przykład Azure Databricks stosuje domyślny tag klastra vendor = Databricks do wszystkich klastrów. Jeśli dodasz niestandardowy tag obszaru roboczego vendor = Azure Databricks, powoduje to konflikt z domyślnym tagiem vendor. Po propagacji do Azure niestandardowy tag obszaru roboczego staje się x_vendor = Azure Databricks, podczas gdy domyślny tag Azure Databricks pozostaje vendor = Databricks.
Ostrzeżenie
Konflikt tagów niestandardowych dodanych za pomocą zasad obliczeniowych nie jest rozwiązywany, co powoduje niepowodzenie klastra lub puli z powodu nieprawidłowego błędu ustawień. Upewnij się, że zasady obliczeniowe nie dodają żadnych nazw tagów powodujących konflikt.
Egzekwowanie tagów
Aby wymusić użycie określonych tagów niestandardowych, można użyć zasad obliczeniowych. Zobacz Wymuszanie niestandardowych tagów. Aby wymusić tagi niestandardowe na bezserwerowych obciążeniach obliczeniowych, użyj zasad użycia bezserwerowego.
Ograniczenia
- Propagacja niestandardowych tagów obszaru roboczego do Azure Databricks po każdej zmianie może potrwać do jednej godziny.
- Do zasobu Azure nie można przypisać więcej niż 50 tagów. Jeśli ogólna liczba zagregowanych tagów przekroczy ten limit,
x_-prefiksowane tagi są oceniane w kolejności alfabetycznej, a te, które przekraczają limit, są ignorowane. Jeśli wszystkie tagi z prefiksemx_są ignorowane, a liczba nadal przekracza limit, pozostałe tagi są oceniane w kolejności alfabetycznej, a te, które przekraczają limit, są ignorowane. - Klucze tagów i wartości mogą zawierać tylko litery, spacje, cyfry lub znaki
+,-,=,.,_,:,/,@. Tagi zawierające inne znaki są nieprawidłowe. Te ograniczenia znaków są ustawiane przez Azure Resource Manager. - Jeśli zmienisz nazwy lub wartości klucza tagu, te zmiany będą stosowane tylko po ponownym uruchomieniu klastra lub rozszerzeniu puli.
- Gdy tagi niestandardowe klastra konfliktują z tagami niestandardowymi puli, nie można utworzyć klastra.
- Nowo dodane, zmodyfikowane lub usunięte tagi obszaru roboczego nie są automatycznie propagowane do istniejących zasobów obliczeniowych. Aby uzyskać nowe tagi do propagacji, otwórz stronę szczegółów zasobu obliczeniowego, kliknij przycisk Edytuj, a następnie potwierdź i uruchom ponownie.