Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Ta funkcja jest dostępna w publicznej wersji testowej.
Na tej stronie opisano sposób używania Databricks Data Classification w Unity Catalog do automatycznego klasyfikowania i oznaczania poufnych danych.
Wykazy danych mogą mieć ogromną ilość danych, często zawierających znane i nieznane dane poufne. Kluczowe jest, aby zespoły ds. danych rozumiały, jaki rodzaj wrażliwych danych znajduje się w każdej tabeli, aby mogły zarówno zarządzać, jak i demokratyzować dostęp do tych danych.
Aby rozwiązać ten problem, klasyfikacja danych usługi Databricks używa agenta sztucznej inteligencji do automatycznego klasyfikowania i tagowania tabel w katalogu. Dzięki temu można odkrywać poufne dane i stosować mechanizmy kontroli zarządzania nad wynikami przy użyciu narzędzi, takich jak kontrola dostępu oparta na atrybutach (ABAC) katalogu Unity. Aby uzyskać listę obsługiwanych tagów, zobacz Obsługiwane tagi klasyfikacji.
Korzystając z tej funkcji, możesz:
- Klasyfikowanie danych: Silnik używa systemu agentowej sztucznej inteligencji do automatycznego klasyfikowania i oznaczania dowolnych tabel w katalogu Unity.
- Optymalizowanie kosztów dzięki inteligentnemu skanowaniu: System inteligentnie określa, kiedy skanować dane, wykorzystując katalog Unity i silnik analizy danych. Oznacza to, że skanowanie jest przyrostowe i zoptymalizowane, aby zapewnić klasyfikację wszystkich nowych danych bez potrzeby ręcznej konfiguracji.
- Przeglądanie i ochrona poufnych danych: wyświetlane wyniki ułatwiają wyświetlanie wyników klasyfikacji i ochronę poufnych danych przez tagowanie i tworzenie zasad kontroli dostępu dla każdej klasy.
Ważne
Klasyfikacja danych usługi Databricks używa domyślnego magazynu do przechowywania wyników klasyfikacji. Nie są naliczane opłaty za magazyn.
Klasyfikacja danych usługi Databricks używa dużego modelu językowego (LLM), aby pomóc w klasyfikacji.
Wymagania
Uwaga / Notatka
Klasyfikacja danych jest funkcją wersji zapoznawczej na poziomie obszaru roboczego i może być zarządzana tylko przez administratora obszaru roboczego lub konta. Aby uzyskać instrukcje, zobacz Zarządzanie wersjami zapoznawczami usługi Azure Databricks.
- Obszar roboczy musi mieć włączone zasoby obliczeniowe bezserwerowe (domyślnie włączone w obszarach roboczych z Unity Catalog).
- Aby włączyć klasyfikację danych, musisz posiadać wykaz lub mieć na nim uprawnienia
USE CATALOGiMANAGE. - Aby włączyć automatyczne tagowanie dla wykazu, musisz mieć
USE CATALOGw wykazie,APPLY TAGw wykazie iASSIGNw zastosowanym tagu. - Aby wyświetlić wyniki klasyfikacji w interfejsie użytkownika, musisz mieć
USE CATALOGiMANAGElub (SELECT+USE SCHEMA) w wykazie. Aby wyświetlić przykładowe wartości skojarzone z wykrywaniami, musisz miećSELECTw tabeli System wyników.
Uwaga / Notatka
Domyślnie tylko administratorzy kont mają uprawnienia MANAGE i ASSIGN do tagów zarządzanych przez system klasyfikacji danych. Administratorzy konta mogą udzielać MANAGE i ASSIGN dla poszczególnych tagów podlegających innym użytkownikom, jednostkom usługi lub grupom. Zobacz Zarządzanie uprawnieniami do zarządzanych tagów.
Używanie klasyfikacji danych
Klasyfikację danych dla wielu katalogów można włączyć jednocześnie na stronie wyników lub skonfigurować poszczególne wykazy z bardziej szczegółową kontrolą na poziomie schematu.
Włączanie wielu wykazów
- Na stronie Wyniki klasyfikacji danych kliknij pozycję Konfiguruj.
- Wybierz wykazy, które chcesz włączyć, lub wybierz wszystkie dostępne wykazy w obszarze roboczym.
- Kliknij przycisk Włącz.
Włączenie wszystkich dostępnych wykazów nie powoduje automatycznego włączenia przyszłych katalogów. Aby sklasyfikować nowy wykaz, wróć do okna dialogowego Konfigurowanie i włącz go.
Włącz pojedynczy katalog z wyborem schematu
Aby wybrać określone schematy w wykazie:
Przejdź do katalogu i kliknij kartę Szczegóły .
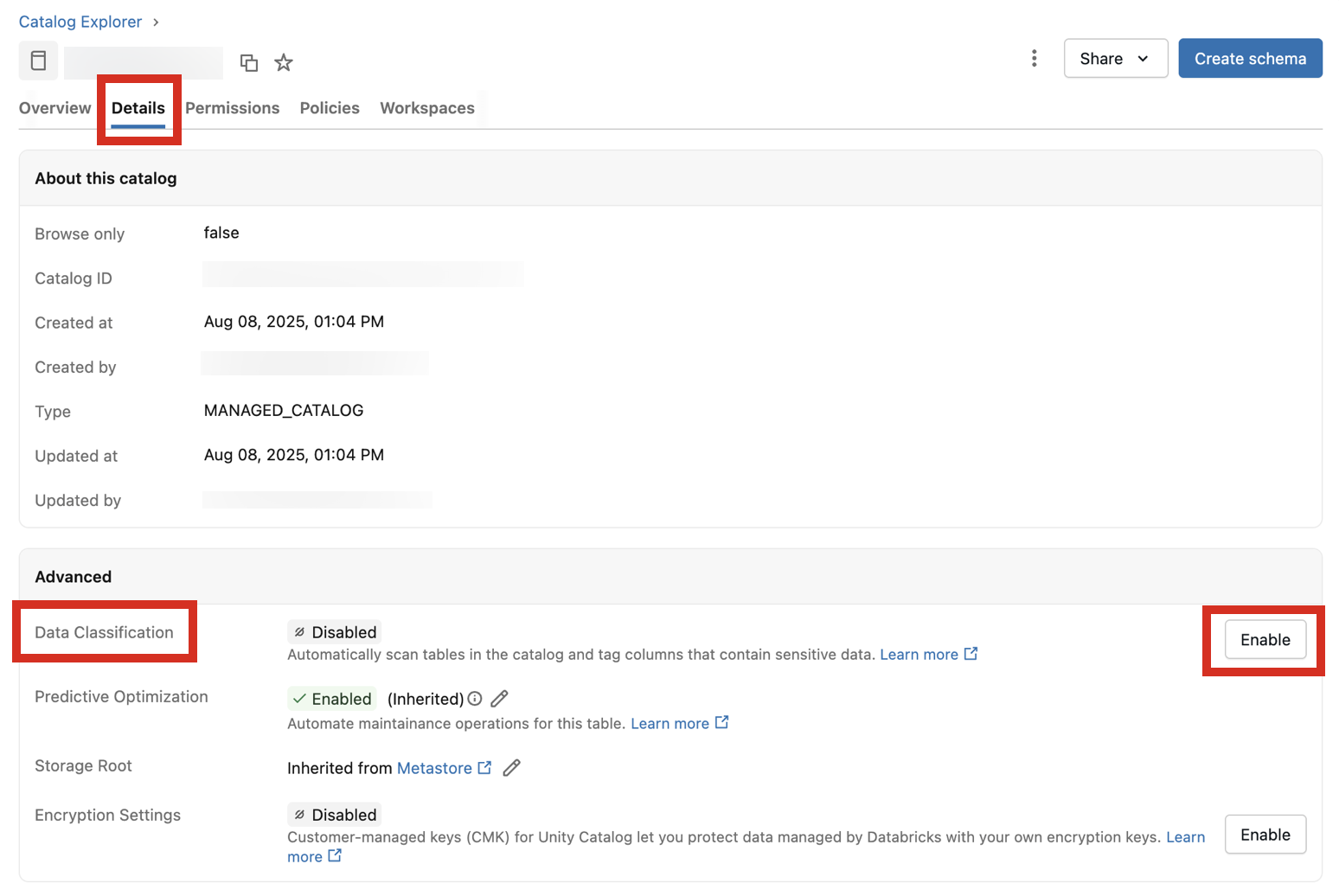
Obok pozycji Klasyfikacja danych kliknij przycisk Włącz .
Zostanie wyświetlone okno dialogowe Klasyfikacja danych . Domyślnie wszystkie schematy są uwzględniane. Aby uwzględnić tylko niektóre schematy, wybierz je w menu rozwijanym Do uwzględnienia. Możesz również wybrać zasady użycia
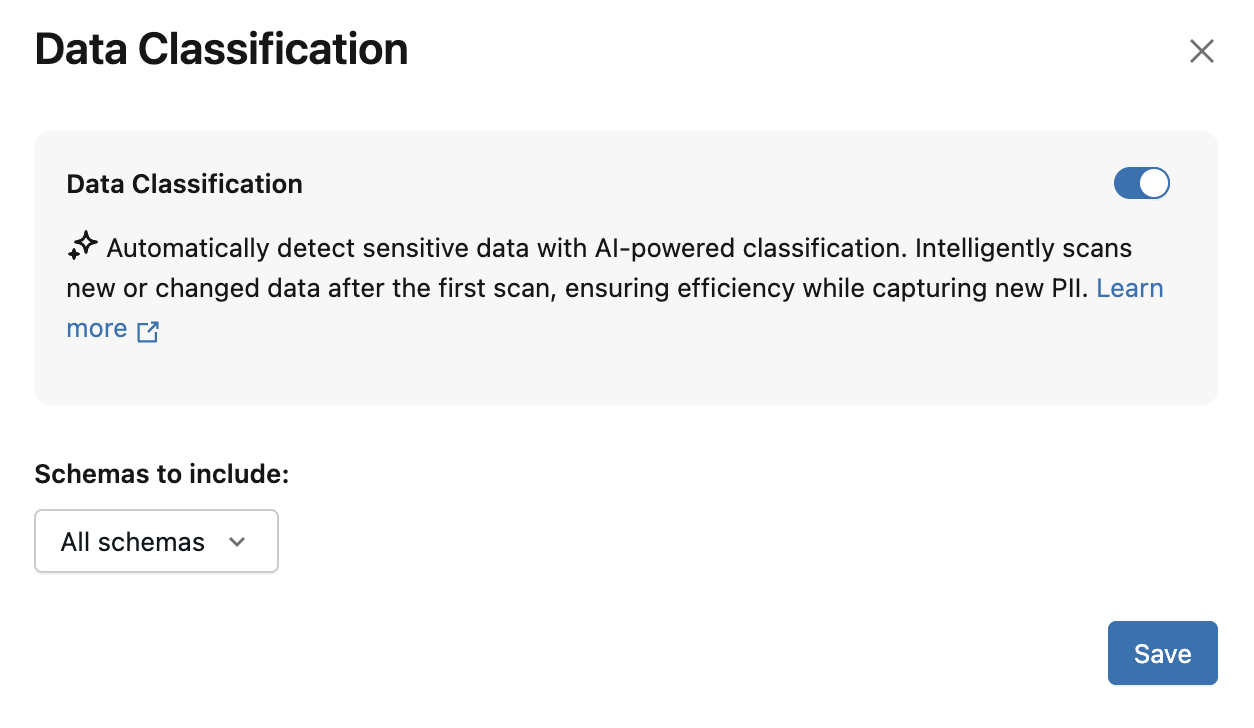
Kliknij Zapisz.
Spowoduje to utworzenie zadania w tle, które przyrostowo skanuje wszystkie tabele w wykazie lub wybranych schematach.
Aparat klasyfikacji opiera się na inteligentnym skanowaniu w celu określenia, kiedy należy skanować tabelę. Nowe tabele i kolumny w wykazie są zwykle skanowane w ciągu 24 godzin od utworzenia.
Wyświetlanie wyników klasyfikacji
Aby wyświetlić wyniki klasyfikacji, kliknij pozycję Wyświetl wyniki obok ustawienia Klasyfikacja danych .
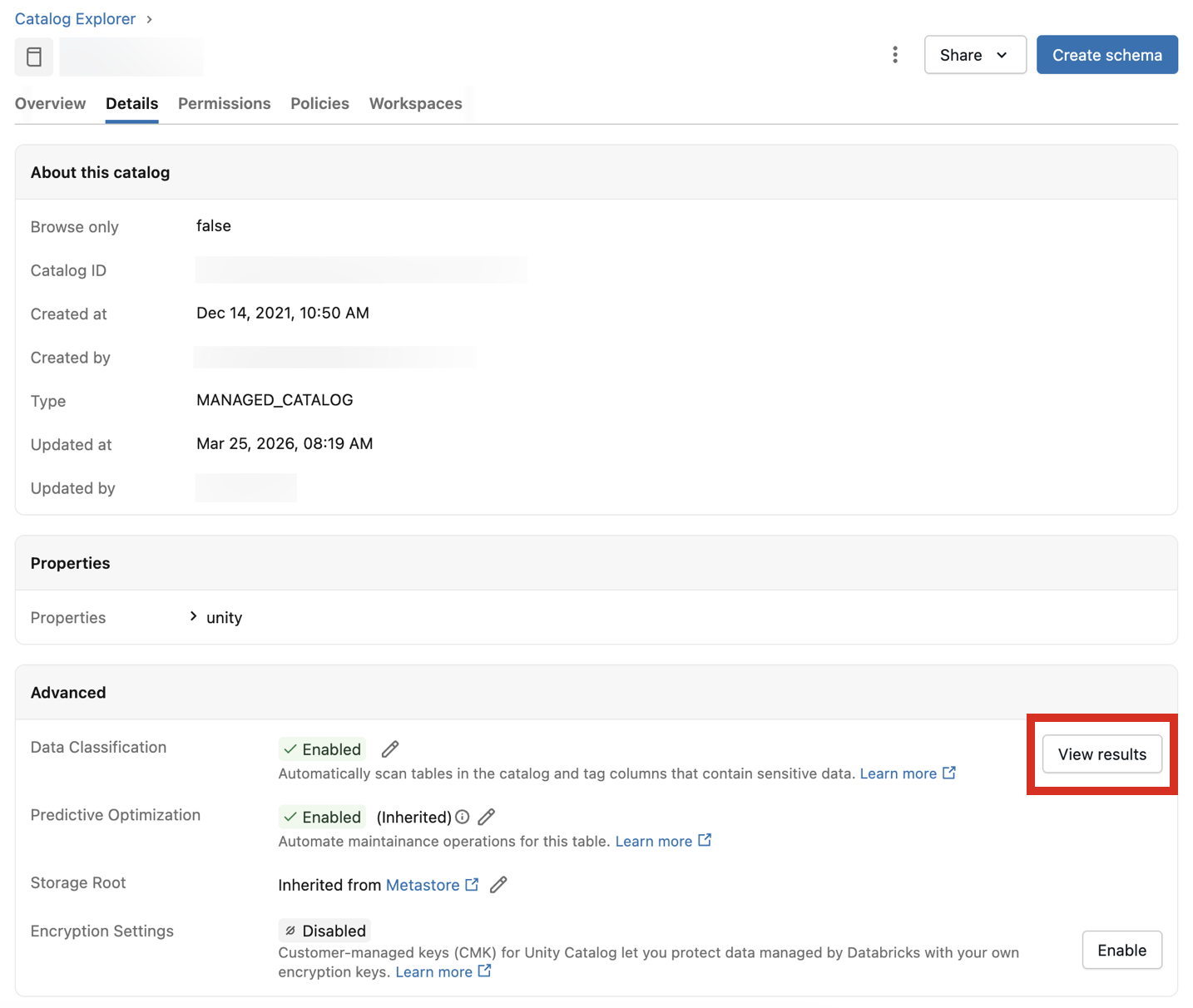
Spowoduje to otwarcie interfejsu użytkownika klasyfikacji danych dla katalogu. Aby wyświetlić wyniki klasyfikacji, wymagany jest bezserwerowy magazyn SQL Warehouse.
Zagregowane wyniki można również wyświetlić we wszystkich sklasyfikowanych katalogach w magazynie metadanych przy użyciu selektora wykazu w lewym górnym rogu. Wybierz pozycję Wszystkie wykazy z menu rozwijanego.
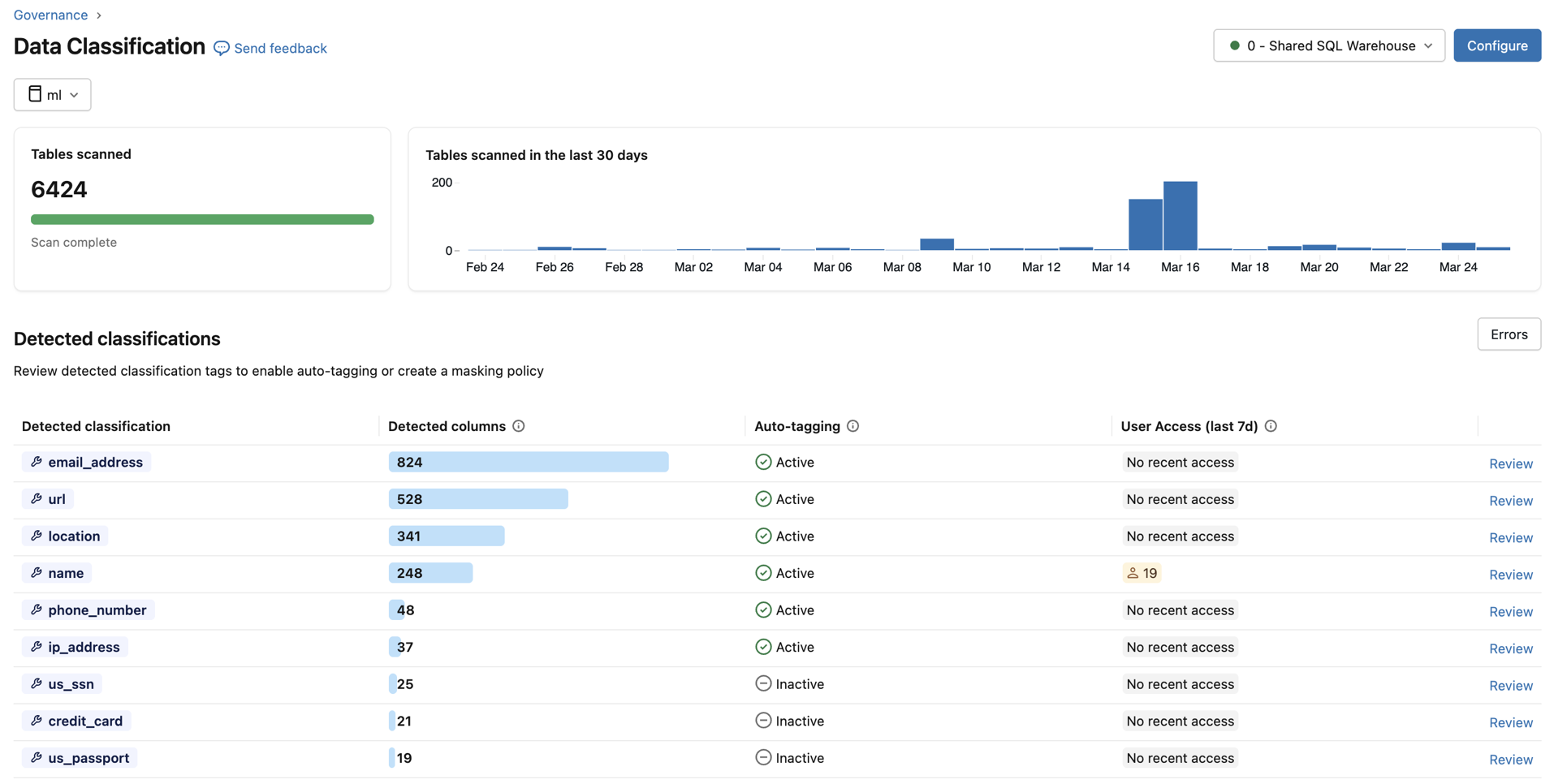
Dla każdego typu klasyfikacji tabela zawiera następujące elementy:
- Wykryte kolumny: liczba kolumn, w których wykryto klasyfikację.
- Automatyczne tagowanie: stan tagowania dla tej klasyfikacji — aktywny lub nieaktywny. W widoku magazynu metadanych stan Częściowo aktywne wskazuje, że tagowanie jest włączone w niektórych, ale nie we wszystkich katalogach.
- Dostęp użytkowników (ostatnie 7d): liczba unikatowych użytkowników, którzy uzyskiwali dostęp do niemaskowanych, a zamaskowanych danych tej klasyfikacji w ciągu ostatnich 7 dni. Umożliwia to ocenę ujawnienia poufnych danych w całej organizacji.
Przejrzyj wykrycia
Aby przejrzeć wyniki dla określonego typu klasyfikacji, kliknij pozycję Przejrzyj w najbardziej prawej kolumnie. Pojawi się panel z dwiema zakładkami:
- Wykryte kolumny: wyświetla kolumny, w których wykryto tag klasyfikacji z dużą ufnością, uporządkowane według najnowszego wykrywania. Zawiera również wykres Wykrywanie w czasie i listę wykrytych kolumn z przykładowymi wartościami. Kliknij dowolny słupek na wykresie, aby wyświetlić określone wykrycia dla tej daty. Przykładowe wartości są wyświetlane tylko wtedy, gdy masz wymagane uprawnienia do wyświetlania wyników klasyfikacji.
- Dostęp użytkowników: wyświetla listę wszystkich użytkowników, którzy uzyskiwali dostęp do kolumn za pomocą tego tagu klasyfikacji, pokazując ich adres e-mail i nazwę użytkownika oraz informację o tym, czy mają zamaskowany, czy niemaskowany dostęp. Pokazuje również wszystkie zasady kontroli dostępu opartej na atrybutach (ABAC) przypisane do tego tagu klasyfikacji. Podczas wyświetlania wyników dla pojedynczego wykazu można utworzyć nową politykę ABAC bezpośrednio w panelu.
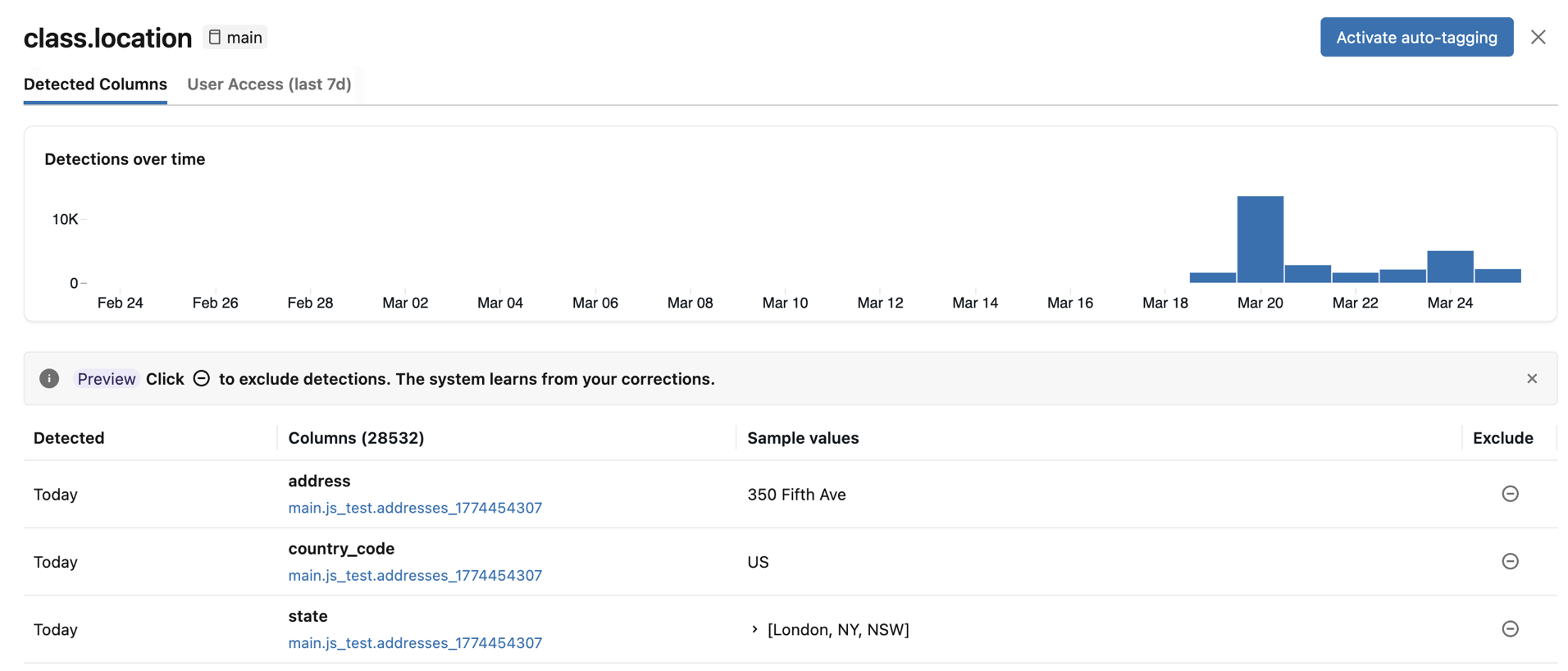
Jeśli jakiekolwiek wykryte kolumny są nieprawidłowe, możesz kliknąć ikonę Wyklucz po prawej stronie wpisu. Zobacz Wyklucz wykrycia.
Włączanie automatycznego tagowania
Jeśli zidentyfikowane kolumny są zgodne z oczekiwaniami, możesz włączyć automatyczne tagowanie dla tagu klasyfikacji. Po włączeniu automatycznego tagowania wszystkie istniejące i przyszłe wykrycia tej klasyfikacji są oznaczane.
Automatyczne tagowanie można skonfigurować na dwóch poziomach:
- Poziom magazynu metadanych: Można włączyć lub wyłączyć we wszystkich katalogach jednocześnie. Musisz być administratorem magazynu metadanych i mieć uprawnienia do stosowania tagu, który jest stosowany.
-
Poziom katalogu: Włącz lub wyłącz tylko dla bieżącego katalogu. Ustawienia na poziomie wykazu mają pierwszeństwo przed ustawieniem na poziomie magazynu metadanych. Musisz mieć
USE CATALOGorazAPPLY TAGw katalogu, aASSIGNna tagu, który jest stosowany.
Na poziomie wykazu automatyczne tagowanie ma trzy stany:
- Ustawienie domyślne (dziedziczone): katalog dziedziczy ustawienie tagowania z poziomu magazynu metadanych.
- Aktywne: tagowanie jest jawnie włączone dla tego wykazu, niezależnie od ustawienia na poziomie magazynu metadanych.
- Nieaktywne: Oznaczanie jest wyraźnie wyłączone dla tego katalogu, niezależnie od ustawienia na poziomie metaskładnicy.
Po wyłączeniu tagowania nie są stosowane żadne przyszłe tagi, ale istniejące tagi nie są usuwane.
Uwaga / Notatka
Po włączeniu automatycznego tagowania, tagi nie są natychmiast uzupełniane. Zostaną one wypełnione w następnym skanowaniu, co powinno nastąpić w ciągu 24 godzin. Kolejne klasyfikacje zostaną oznaczone natychmiast.
Wyklucz wykrycia
Ważne
Wykluczenia wykrywania i ich użycie w celu zwiększenia dokładności przyszłej klasyfikacji są w wersji beta.
Na panelu przeglądu można wykluczyć poszczególne wykrycia kolumn. Pomijanie wykrycia
- Usuwa z tej kolumny dowolny istniejący tag klasyfikacji.
- Zapobiega przyszłym skanowaniom ponownemu stosowaniu tagu do tej kolumny.
- Zawiera opinie, które zwiększają dokładność przyszłych wyników klasyfikacji.
Aby wykluczyć wykrywanie, kliknij ikonę Wyklucz dla odpowiedniej kolumny w panelu przeglądu. Aby ponownie dołączyć wykrywanie, kliknij ponownie ikonę.
Tabela systemu wyników
Klasyfikacja danych tworzy tabelę systemową o nazwie system.data_classification.results do przechowywania wyników, które domyślnie są dostępne tylko dla administratora konta. Administrator konta może udostępnić tę tabelę. Tabela jest dostępna tylko wtedy, gdy używasz bezserwerowych obliczeń. Aby uzyskać szczegółowe informacje na temat tej tabeli, zobacz Dokumentacja tabeli systemu klasyfikacji danych.
Ważne
Tabela system.data_classification.results wyników zawiera wszystkie wyniki klasyfikacji w całym magazynie metadanych i zawiera przykładowe wartości z tabel w każdym wykazie. Tę tabelę należy udostępnić tylko użytkownikom uprzywilejowanym, aby wyświetlić wyniki klasyfikacji dla całego magazynu metadanych, w tym przykładowe wartości.
Użytkownicy z dostępem SELECT do tej tabeli mogą również zobaczyć przykładowe wartości skojarzone z wykryciami na stronie wyników klasyfikacji danych.
Skonfiguruj kontrole zarządzania na podstawie wyników klasyfikacji danych
Maskuj poufne dane przy użyciu zasad ABAC
Databricks zaleca używanie atrybutowej kontroli dostępu (ABAC) w Unity Catalog w celu tworzenia mechanizmów kontroli ładu na podstawie wyników klasyfikacji danych.
Aby utworzyć zasady na stronie wyników klasyfikacji danych, kliknij pozycję Przejrzyj tag klasyfikacji, otwórz kartę Dostęp użytkowników i kliknij pozycję Nowe zasady. Formularz zasad jest wstępnie wypełniony w celu maskowania kolumn z przeglądanym tagiem klasyfikacji. Aby zamaskować dane, określ dowolną funkcję maskowania zarejestrowaną w katalogu Unity i kliknij przycisk Zapisz.
Można również utworzyć zasady, które obejmują wiele tagów klasyfikacji, zmieniając kolumnę Whenna spełnia warunek i podając wiele tagów.
Aby na przykład utworzyć politykę o nazwie "Poufne", która maskuje każdą nazwę, adres e-mail lub numer telefonu, ustaw warunek spełnia wartośćhas_tag("class.name") OR has_tag("class.email_address") OR has_tag("class.phone_number").
Odnajdywanie i usuwanie danych zgodnie z RODO
W tym przykładzie notesie pokazano, jak można użyć klasyfikacji danych, aby ułatwić odnajdywanie i usuwanie danych w celu zapewnienia zgodności z RODO.
Odnajdywanie i usuwanie RODO przy użyciu notesu klasyfikacji danych
Jak obsługiwać niepoprawne tagi
Jeśli klasyfikacja jest nieprawidłowa, wyklucz detekcję z panelu przeglądowego. Wykluczenie wykrywania powoduje usunięcie tagu, uniemożliwia jego ponowne zastosowania i poprawia dokładność przyszłych skanowań. Zobacz Wyklucz wykrycia.
Błędy skanowania
Jeśli podczas skanowania wystąpią jakiekolwiek błędy, w prawym górnym rogu tabeli wyników pojawi się przycisk Błędy .
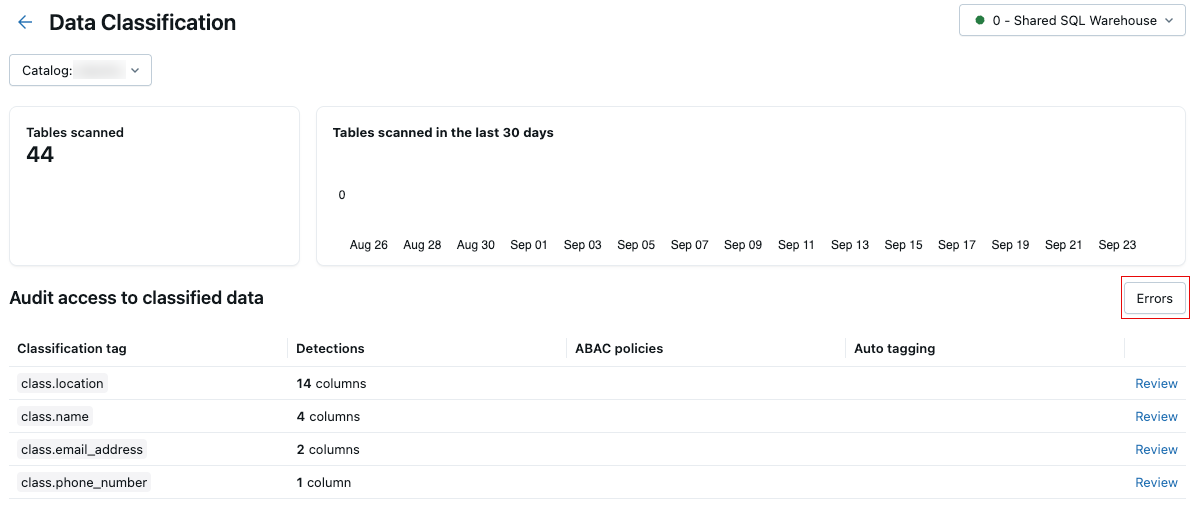
Kliknij przycisk, aby wyświetlić tabele, które zakończyły się niepowodzeniem skanowania i skojarzonymi komunikatami o błędach.

Domyślnie błędy, które wystąpiły dla poszczególnych tabel, są pomijane i ponawiane następnego dnia.
Wyświetlanie wydatków dotyczących klasyfikacji danych
Aby dowiedzieć się, jak jest rozliczana klasyfikacja danych, zobacz stronę cennika. Możesz wyświetlić wydatki związane z klasyfikacją danych, uruchamiając zapytanie lub wyświetlając pulpit nawigacyjny użycia.
Uwaga / Notatka
Początkowe skanowanie jest bardziej kosztowne niż kolejne skanowania w tym samym wykazie, ponieważ te skanowania są przyrostowe i zwykle wiążą się z niższymi kosztami.
Wyświetl użycie z tabeli systemowej system.billing.usage
Możesz wykonać zapytanie dotyczące wydatków na klasyfikację danych z witryny system.billing.usage. Pola created_by i catalog_id mogą służyć opcjonalnie do podziału kosztów:
-
created_by: Uwzględnij, aby zobaczyć koszty poniesione przez użytkownika, który zainicjował użycie. -
catalog_id: Uwzględnij, aby wyświetlić koszty według katalogu. Identyfikator katalogu jest wyświetlany w tabelisystem.data_classification.results.
Przykładowe zapytanie z ostatnich 30 dni:
SELECT
usage_date,
identity_metadata.created_by,
usage_metadata.catalog_id,
SUM(usage_quantity) AS dbus
FROM
system.billing.usage
WHERE
usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
created_by,
catalog_id
ORDER BY
usage_date DESC,
created_by;
Aby obliczyć całkowity koszt w dolarach, dokonaj połączenia z system.billing.list_prices. Poniższe przykładowe zapytanie używa nazwanego parametru :add_on_rate jako mnożnika w cenie katalogowej. Ustaw ją na 1, aby użyć ceny katalogowej bezpośrednio, lub wartość mniejszą niż 1 w celu odzwierciedlenia wynegocjowanego rabatu (na przykład 0.9 dla rabatu 10%).
Przykładowe zapytanie dotyczące łącznego kosztu dolara w ciągu ostatnich 30 dni:
SELECT
u.usage_date,
SUM(u.usage_quantity * lp.pricing.effective_list.default) * :add_on_rate
AS `Data Classification Dollar Cost`
FROM system.billing.usage AS u
JOIN system.billing.list_prices AS lp
ON lp.sku_name = u.sku_name
WHERE
u.billing_origin_product = 'DATA_CLASSIFICATION'
AND u.usage_end_time >= lp.price_start_time
AND (lp.price_end_time IS NULL OR u.usage_end_time < lp.price_end_time)
AND u.usage_date >= DATE_ADD(CURRENT_DATE(), -30)
GROUP BY
u.usage_date
ORDER BY
u.usage_date DESC;
Wyświetlanie użycia z pulpitu nawigacyjnego
Jeśli masz już panel kontrolny użycia skonfigurowany w obszarze roboczym, możesz go użyć do filtrowania użycia, wybierając projekt rozliczeniowy oznaczony jako "Klasyfikacja danych". Jeśli nie masz skonfigurowanego pulpitu kontrolnego użycia, możesz go zaimportować i zastosować to samo filtrowanie. Aby uzyskać szczegółowe informacje, zobacz Panele użycia.
Obsługiwane tagi klasyfikacji
Aby uzyskać pełną listę obsługiwanych tagów zorganizowanych według tagów globalnych, tagów regionalnych i struktur zgodności (PII, RODO, HIPAA, DPDPA), zobacz Obsługiwane tagi klasyfikacji.
Ograniczenia
- Widoki i widoki metryk nie są obsługiwane. Jeśli widok jest oparty na istniejących tabelach, usługa Databricks zaleca klasyfikowanie bazowych tabel, aby sprawdzić, czy zawierają poufne dane.