Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważna
Ta funkcja jest dostępna w publicznej wersji zapoznawczej i jest zgodna ze standardem HIPAA.
Klasyfikację można użyć do klasyfikowania dokumentów w wstępnie zdefiniowanych kategorii za pomocą sztucznej inteligencji.
Przykłady klasyfikacji obejmują:
- Klasyfikowanie transkrypcji wywołań klienta według intencji
- Klasyfikowanie dokumentów według typu zawartości
- Klasyfikowanie recenzji produktów według tonacji
Klasyfikacja jest oparta na funkcji sztucznej inteligencji. ai_classify Strona Agenci udostępnia interfejs użytkownika umożliwiający szybkie klasyfikowanie dokumentów i tekstu bez struktury oraz iterowanie pól klasyfikacji w celu uzyskania lepszych wyników.
Wymagania
- Obszar roboczy zawierający następujące elementy:
- Włączono klasyfikację sztucznej inteligencji w publicznej wersji zapoznawczej. Zobacz Zarządzanie wersjami zapoznawczami usługi Azure Databricks.
- Włączono bezserwerowe obliczenia. Zobacz Wymagania dotyczące obliczeń bezserwerowych.
- Katalog Unity jest włączony. Zobacz Umożliwienie obszaru roboczego dla Unity Catalog.
- Dostęp do zasad budżetu bezserwerowego z budżetem niezerowym.
- Ta funkcja jest dostępna tylko w niektórych regionach. Zobacz Dostępność funkcji sztucznej inteligencji.
- Możliwość korzystania z
ai_classifyfunkcji SQL. - Dane bez struktury, które chcesz sklasyfikować. Dane muszą być w woluminie lub tabeli Unity Catalogu.
- Aby zbudować agenta, potrzebujesz co najmniej 1 nieoznaczonego dokumentu w woluminie Unity Catalog lub 1 wiersza w tabeli.
Tworzenie agenta klasyfikacji
Przejdź do ![]() Agenci w okienku nawigacji po lewej stronie obszaru roboczego. Kliknij pozycję Utwórz agenta i wybierz pozycję Klasyfikacja tekstu.
Agenci w okienku nawigacji po lewej stronie obszaru roboczego. Kliknij pozycję Utwórz agenta i wybierz pozycję Klasyfikacja tekstu.
Krok 1. Wybieranie danych źródłowych
Klasyfikacja służy do klasyfikowania dokumentów.
Wybierz dane źródłowe. Wolumin można wybrać z dokumentami lub tabelą z danymi tekstowymi.
Kliknij pozycję Utwórz agenta.
Krok 2. Konfigurowanie etykiet klasyfikacji
Po przetworzeniu danych przez klasyfikację, skonfiguruj i uściślij etykiety klasyfikacyjne.
Aby ręcznie dodać etykiety klasyfikacji:
- Kliknij pozycję + Dodaj etykietę , aby dodać etykietę klasyfikacji.
- Wprowadź nazwę etykiety i opcjonalny opis, a następnie kliknij pozycję Dodaj etykietę.
- Powtórz 1–2 dla każdej etykiety, którą chcesz dodać.
- (Opcjonalnie) Włącz wiele etykiet , jeśli agent ma zwrócić więcej niż jedną etykietę.
Aby zaimportować etykiety z tabeli:
- Kliknij Importuj z tabeli.
- Wybierz tabelę i kliknij przycisk Dalej.
- Wybierz kolumnę etykiety, kolumnę opisu i usługę SQL Warehouse.
- Kliknij pozycję Podgląd , aby wyświetlić zaimportowane etykiety.
- Jeśli jesteś zadowolony z etykiet, kliknij Importuj i zastąp etykiety.
Aby uruchomić klasyfikację, musisz mieć co najmniej dwie etykiety zdefiniowane. Po zakończeniu dodawania etykiet kliknij pozycję Zapisz i uruchom klasyfikację.
Klasyfikacja klasyfikuje maksymalnie 5 dokumentów i wierszy i wyświetla wyniki. Możesz również dodać więcej.
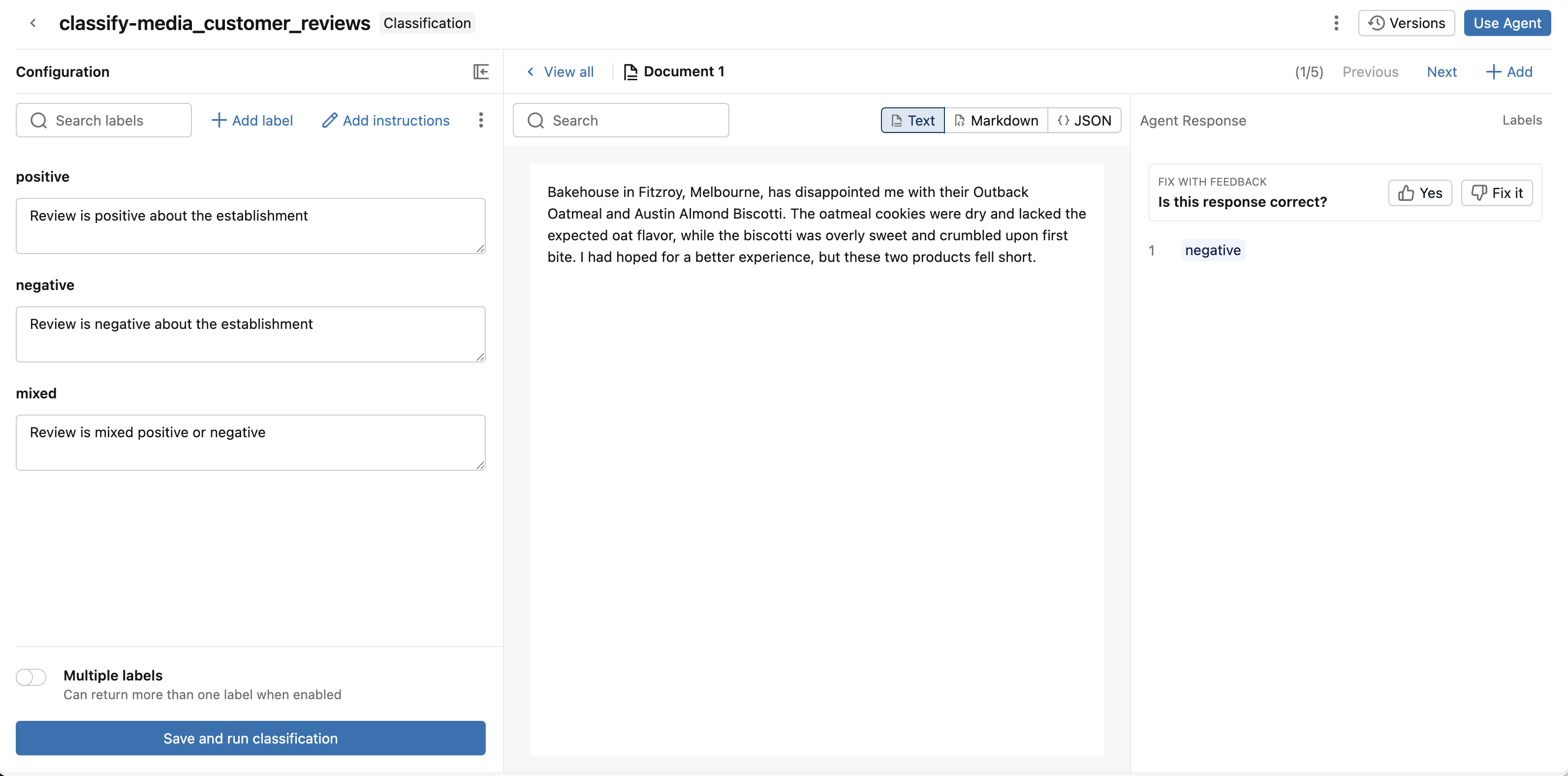
Krok 3. Przegląd i ulepszenie wyników klasyfikacji
Przeanalizuj odpowiedzi klasyfikacji i prześlij opinię, aby udoskonalić agenta.
Przejrzyj dokument oraz odpowiedź dotyczącą klasyfikacji.
- Jeśli odpowiedź jest poprawna, daj mu kciuk w górę.
- Jeśli odpowiedź jest niepoprawna, podaj kciuk w dół. Pomóż klasyfikacji naprawić odpowiedź, wybierając poprawną etykietę. Kliknij Zapisz.
Aby poprawić odpowiedzi agenta, dostosuj opisy etykiet klasyfikacyjnych.
Porównaj wersje, aby zoptymalizować wydajność agenta. Kliknij pozycję Wersje. Obok poprzedniej wersji kliknij przycisk Porównaj , aby porównać opisy etykiet klasyfikacji poprzedniej wersji z bieżącą wersją. Kliknij przycisk Przywróć, aby przywrócić poprzednią wersję.
Krok 4. Korzystanie z agenta klasyfikacji
Jeśli jesteś zadowolony z odpowiedzi, zacznij używać agenta do klasyfikacji na dużą skalę.
Kliknij pozycję Użyj agenta w prawym górnym rogu. Możesz wybrać jedną z następujących opcji:
-
Uruchom polecenie w języku SQL, aby użyć agenta do klasyfikowania całego woluminu lub tabeli. Spowoduje to otwarcie zapytania SQL, które używa
ai_classifyetykiet klasyfikacji, które zdefiniowałeś. Aby uzyskać więcej informacji na temat używaniaai_classifyzapytań SQL, zobaczai_classifyfunkcja. - Utwórz potok deklaratywny platformy Spark , aby wdrożyć potok ETL uruchamiany w zaplanowanych odstępach czasu w celu wywołania agenta na nowych danych. Spowoduje to utworzenie potoków deklaratywnych platformy Spark w usłudze Lakeflow, które aktualizują tabelę przesyłania strumieniowego przy użyciu danych sklasyfikowanych. Można skonfigurować harmonogram potoku, aby uruchamiał się po nadejściu nowych danych. Aby uzyskać więcej informacji na temat potoków deklaratywnych platformy Spark w usłudze Lakeflow, zobacz Lakeflow Spark Deklaratywne potoki.
Ograniczenia
Zobacz Ograniczenia