Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Na tej stronie opisano sposób odzyskiwania potoku w deklaratywnych potokach Lakeflow Spark, gdy punkt kontrolny przesyłania strumieniowego staje się nieprawidłowy lub uszkodzony.
Co to jest punkt kontrolny przesyłania strumieniowego?
W Streamingu z ustrukturyzowanymi danymi Apache Spark punkt kontrolny jest mechanizmem służącym do utrwalania stanu zapytania strumieniowego. Ten stan obejmuje:
- Informacje o postępie: które offsety ze źródła zostały przetworzone.
-
Stan pośredni: dane, które muszą być przechowywane w mikrosadach na potrzeby operacji stanowych (na przykład agregacji,
mapGroupsWithState). - Metadane: Informacje o wykonywaniu zapytania strumieniowego.
Punkty kontrolne są niezbędne do zapewnienia odporności na uszkodzenia i spójności danych w aplikacjach przesyłania strumieniowego:
- Odporność na uszkodzenia: jeśli aplikacja przesyłania strumieniowego zakończy się niepowodzeniem (na przykład z powodu awarii węzła, awarii aplikacji), punkt kontrolny umożliwia aplikacji ponowne uruchomienie z ostatniego pomyślnego stanu punktu kontrolnego zamiast ponownego przetwarzania wszystkich danych od początku. Zapobiega to utracie danych i zapewnia przetwarzanie przyrostowe.
- Przetwarzanie dokładnie jednokrotne: W przypadku wielu źródeł przesyłania strumieniowego punkty kontrolne w połączeniu z ujściami idempotentnymi umożliwiają gwarancję, że każdy rekord jest przetwarzany dokładnie raz, nawet w przypadku awarii, zapobiegając duplikatom lub pominięciom.
- Zarządzanie stanem: w przypadku przekształceń stanowych punkty kontrolne utrzymują stan wewnętrzny tych operacji, co umożliwia prawidłowe kontynuowanie przetwarzania nowych danych na podstawie skumulowanego stanu historycznego.
Punkty kontrolne potoku
Potoki bazują na Structured Streaming i upraszczają podstawowe zarządzanie punktami kontrolnymi, oferując podejście deklaratywne. Podczas definiowania tabeli przesyłania strumieniowego w potoku, dla każdego przepływu, który zapisuje do tabeli przesyłania strumieniowego, istnieje stan punktu kontrolnego. Te lokalizacje punktów kontrolnych są wewnętrzne dla potoku i nie są dostępne dla użytkowników.
Zwykle nie trzeba zarządzać lub rozumieć podstawowych punktów kontrolnych dla tabel przesyłania strumieniowego, z wyjątkiem następujących przypadków:
- Przewijanie i odtwarzanie: Jeśli chcesz ponownie przetworzyć dane z określonego punktu w czasie, zachowując bieżący stan tabeli, musisz zresetować punkt kontrolny tabeli strumieniowej.
- pl-PL: Odzyskiwanie po niepowodzeniu lub uszkodzeniu punktu kontrolnego: jeśli zapytanie zapisujące do tabeli strumieniowej nie powiodło się z powodu błędów związanych z punktem kontrolnym, powoduje to poważną awarię, a zapytanie nie może kontynuować. Istnieją trzy podejścia, których można użyć do odzyskania po tej klasie awarii:
- Odświeżanie pełnej tabeli: spowoduje zresetowanie tabeli i wyczyszczenie istniejących danych.
- Pełne odświeżanie tabeli za pomocą kopii zapasowej i wypełniania kopii zapasowej: należy utworzyć kopię zapasową tabeli przed wykonaniem pełnego odświeżania tabeli i wypełniania starych danych, ale jest to bardzo kosztowne i powinno być ostatnią metodą.
- Zresetuj punkt kontrolny i kontynuuj przyrostowo: jeśli nie możesz sobie pozwolić na utratę istniejących danych, musisz przeprowadzić selektywne resetowanie punktu kontrolnego dla przepływów przesyłania strumieniowego, których dotyczy problem.
Przykład: Awaria pipeline'u z powodu zmiany kodu
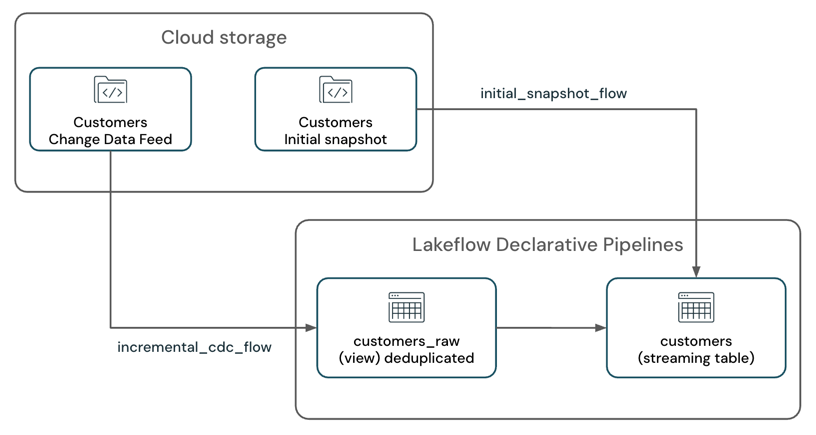
Rozważmy scenariusz, w którym masz potok, który przetwarza strumień danych zmian wraz z początkową migawką tabeli z systemu przechowywania danych w chmurze, takim jak Amazon S3, i zapisuje w tabeli przesyłania strumieniowego SCD-1.
Potok ma dwa przepływy przesyłania strumieniowego:
-
customers_incremental_flow: przyrostowo odczytuje dane CDC z tabeli źródłowejcustomer, filtruje zduplikowane rekordy i aktualizuje oraz wstawia je do tabeli docelowej. -
customers_snapshot_flow: Jednorazowo odczytaj początkową migawkę tabeli źródłowejcustomersi wstawia/zastępuje rekordy do tabeli docelowej.
@dp.temporary_view(name="customers_incremental_view")
def query():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.includeExistingFiles", "true")
.load(customers_incremental_path)
.dropDuplicates(["customer_id"])
)
@dp.temporary_view(name="customers_snapshot_view")
def full_orders_snapshot():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.includeExistingFiles", "true")
.option("cloudFiles.inferColumnTypes", "true")
.load(customers_snapshot_path)
.select("*")
)
dp.create_streaming_table("customers")
dp.create_auto_cdc_flow(
flow_name = "customers_incremental_flow",
target = "customers",
source = "customers_incremental_view",
keys = ["customer_id"],
sequence_by = col("sequenceNum"),
apply_as_deletes = expr("operation = 'DELETE'"),
apply_as_truncates = expr("operation = 'TRUNCATE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 1
)
dp.create_auto_cdc_flow(
flow_name = "customers_snapshot_flow",
target = "customers",
source = "customers_snapshot_view",
keys = ["customer_id"],
sequence_by = lit(0),
stored_as_scd_type = 1,
once = True
)
Po wdrożeniu tego potoku działa pomyślnie i rozpoczyna przetwarzanie strumienia zmian danych oraz migawki początkowej.
Później zdajesz sobie sprawę, że logika deduplikacji w zapytaniu customers_incremental_view jest zbędna oraz powoduje wąskie gardło wydajności. Usuń dropDuplicates(), aby zwiększyć wydajność.
@dp.temporary_view(name="customers_raw_view")
def query():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.includeExistingFiles", "true")
.load()
# .dropDuplicates()
)
Po usunięciu interfejsu API i ponownym uruchomieniu dropDuplicates() potoku aktualizacja kończy się niepowodzeniem z powodu następującego błędu:
Streaming stateful operator name does not match with the operator in state metadata.
This is likely to happen when a user adds/removes/changes stateful operators of existing streaming query.
Stateful operators in the metadata: [(OperatorId: 0 -> OperatorName: dedupe)];
Stateful operators in current batch: []. SQLSTATE: 42K03 SQLSTATE: XXKST
Ten błąd wskazuje, że zmiana jest niedozwolona z powodu niezgodności między stanem punktu kontrolnego a bieżącą definicją zapytania, powodując zatrzymanie dalszego rozwoju potoku.
Błędy związane z punktem kontrolnym mogą wystąpić z różnych powodów, nie tylko z powodu usunięcia funkcji dropDuplicates API. Typowe scenariusze obejmują:
- Dodawanie lub usuwanie operatorów stanowych (na przykład wprowadzenie lub upuszczanie
dropDuplicates()lub agregacje) w istniejącym zapytaniu przesyłanym strumieniowo. - Dodawanie, usuwanie lub łączenie źródeł przesyłania strumieniowego w wcześniej określonym zapytaniu kontrolnym (na przykład łączenie istniejącego zapytania przesyłania strumieniowego z nowym lub dodawanie/usuwanie źródeł z istniejącej operacji unii).
- Modyfikowanie schematu stanu stanowych operacji przesyłania strumieniowego (takich jak zmiana kolumn używanych do deduplikacji lub agregacji).
Aby uzyskać pełną listę obsługiwanych i nieobsługiwanych zmian, zobacz Przewodnik przesyłania strumieniowego ze strukturą platformy Spark i typy zmian w zapytaniach przesyłania strumieniowego ze strukturą.
Opcje odzyskiwania
Istnieją trzy strategie odzyskiwania, w zależności od wymagań dotyczących trwałości danych i ograniczeń zasobów:
| Methods | Złożoność | Koszt | Potencjalna utrata danych | Potencjalne duplikowanie danych | Wymaga początkowej migawki | Resetowanie pełnej tabeli |
|---|---|---|---|---|---|---|
| Odświeżanie pełnej tabeli | Low | Średni | Tak (jeśli nie jest dostępna żadna początkowa migawka lub jeśli nieprzetworzone pliki zostały usunięte ze źródła). | Nie (Aby zastosować zmiany w tabeli docelowej). | Tak | Tak |
| Odświeżanie pełnej tabeli z kopią zapasową i uzupełnianiem danych | Średni | High | Nie. | Nie (w przypadku ujściów idempotentnych. Na przykład auto CDC). | Nie. | Nie. |
| Resetuj punkt kontrolny tabeli | Średnio-Wysoki (Średni dla źródeł tylko do dołączania, które zapewniają niezmienne przesunięcia). | Low | Nie (wymaga starannego rozważenia). | Nie (dla idempotentnych zapisów. Na przykład automatyczne CDC tylko do tabeli docelowej.) | Nie. | Nie. |
Złożoność od średniej do wysokiej zależy od typu źródła przesyłania strumieniowego i złożoności zapytania.
Rekomendacje
- Użyj odświeżania pełnej tabeli, jeśli nie chcesz zajmować się złożonością resetowania punktu kontrolnego i możesz ponownie skompilować całą tabelę. Umożliwi to również wprowadzanie zmian w kodzie.
- Użyj pełnego odświeżania tabeli z kopią zapasową i uzupełnianiem danych, jeśli nie chcesz zajmować się złożonością resetowania punktów kontrolnych i akceptujesz dodatkowy koszt tworzenia kopii zapasowej oraz uzupełniania danych historycznych.
- Użyj punktu kontrolnego resetowania tabeli, jeśli musisz zachować istniejące dane w tabeli i kontynuować przetwarzanie nowych danych w sposób przyrostowy. Jednak takie podejście wymaga starannej obsługi resetowania punktu kontrolnego w celu sprawdzenia, czy nie zostaną utracone istniejące dane w tabeli oraz że potok może kontynuować przetwarzanie nowych danych.
Resetowanie punktu kontrolnego i kontynuowanie krok po kroku
Aby zresetować punkt kontrolny i kontynuować przetwarzanie przyrostowo, wykonaj następujące kroki:
Zatrzymaj przepływ: upewnij się, że pipeline nie ma uruchomionych aktywnych aktualizacji.
Określ pozycję początkową dla nowego punktu kontrolnego: zidentyfikuj ostatnie pomyślne przesunięcie lub znacznik czasu, od którego ma być kontynuowane przetwarzanie. Zazwyczaj jest to ostatnie przesunięcie przetworzone z powodzeniem przed wystąpieniem błędu.
Ponieważ odczytujesz pliki JSON przy użyciu modułu automatycznego ładowania w poprzednim przykładzie, możesz użyć
modifiedAfteropcji , aby ustawić znacznik czasu, gdy moduł ładujący automatycznie rozpocznie przetwarzanie nowych plików.W przypadku źródeł platformy Kafka można użyć opcji
startingOffsets, aby określić przesunięcia, od których zapytanie przesyłane strumieniowo powinno rozpocząć przetwarzanie nowych danych.W przypadku źródeł usługi Delta Lake można użyć
startingVersionopcji , aby określić wersję, z której zapytanie przesyłane strumieniowo powinno rozpocząć przetwarzanie nowych danych.Wprowadź zmiany w kodzie: możesz zmodyfikować zapytanie strumieniowe, aby usunąć
dropDuplicates()interfejs API lub wprowadzić inne zmiany. Sprawdź również, czy dodałeś opcjęmodifiedAfterdo ścieżki odczytu Auto Loader.@dp.temporary_view(name="customers_incremental_view") def query(): return ( spark.readStream.format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.inferColumnTypes", "true") .option("cloudFiles.includeExistingFiles", "true") .option("modifiedAfter", "2025-04-09T06:15:00") .load(customers_incremental_path) # .dropDuplicates(["customer_id"]) )Uwaga / Notatka
Podanie nieprawidłowego
modifiedAfterznacznika czasu może prowadzić do utraty lub duplikowania danych. Sprawdź, czy znacznik czasu jest poprawnie ustawiony, aby uniknąć ponownego przetwarzania starych danych lub brakujących nowych danych.Jeśli zapytanie obejmuje połączenie strumień-strumień lub sumę strumień-strumień, należy zastosować powyższą strategię dla wszystkich uczestniczących źródeł strumieniowych. Przykład:
cdc_1 = spark.readStream.format("cloudFiles")... cdc_2 = spark.readStream.format("cloudFiles")... cdc_source = cdc_1..union(cdc_2)Zidentyfikuj nazwę lub nazwy przepływu skojarzone z tabelą strumieniową, dla których chcesz zresetować punkt kontrolny. W tym przykładzie jest
customers_incremental_flowto spowodowane tym, że przepływ został utworzony za pomocą jawnegoflow_nameparametru. Jeśli nie ustawiono jawnej nazwy przepływu, domyślna nazwa przepływu to w pełni kwalifikowana nazwa tabeli wcatalog.schema.tableformacie (na przykładmy_catalog.my_schema.customers). Nazwy przepływów można znaleźć w kodzie potoku, interfejsie użytkownika potoku lub dziennikach zdarzeń potoku.Zresetuj punkt kontrolny: utwórz notes języka Python i dołącz go do klastra usługi Azure Databricks.
Aby zresetować punkt kontrolny, potrzebne będą następujące informacje:
- Adres URL obszaru roboczego usługi Azure Databricks
- Identyfikator potoku
- Nazwy przepływów, dla których resetujesz punkt kontrolny
import requests import json # Define your Databricks instance and pipeline ID databricks_instance = "<DATABRICKS_URL>" token = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get() pipeline_id = "<YOUR_PIPELINE_ID>" flows_to_reset = ["<YOUR_FLOW_NAME>"] # Set up the API endpoint endpoint = f"{databricks_instance}/api/2.0/pipelines/{pipeline_id}/updates" # Set up the request headers headers = { "Authorization": f"Bearer {token}", "Content-Type": "application/json" } # Define the payload payload = { "reset_checkpoint_selection": flows_to_reset } # Make the POST request response = requests.post(endpoint, headers=headers, data=json.dumps(payload)) # Check the response if response.status_code == 200: print("Pipeline update started successfully.") else: print(f"Error: {response.status_code}, {response.text}")Uruchom potok przetwarzania: Potok przetwarzania rozpoczyna analizowanie nowych danych z określonej pozycji startowej przy użyciu nowego punktu kontrolnego, zachowując istniejące dane tabeli i jednocześnie kontynuując przetwarzanie przyrostowe.
Najlepsze rozwiązania
- Unikaj używania prywatnych funkcji w wersji zapoznawczej w środowisku produkcyjnym.
- Przetestuj zmiany przed wprowadzeniem zmian w środowisku produkcyjnym.
- Utwórz potok testowy, najlepiej w niższym środowisku. Jeśli nie jest to możliwe, spróbuj użyć innego katalogu i schematu dla testu.
- Odtwórz błąd.
- Zastosuj wprowadzone zmiany.
- Zweryfikuj wyniki i podejmij decyzję o kontynuacji lub przerwaniu.
- Wprowadź zmiany w pipeline'ach produkcyjnych.