Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Inżynierowie danych często muszą replikować dane ze źródeł nadrzędnych usługi Azure Databricks — takich jak relacyjne bazy danych (Oracle, Postgres, SQL Server) — do usługi Azure Databricks na potrzeby analizy, raportowania i uczenia maszynowego. W miarę zmiany systemów operacyjnych tabele analityczne muszą być zsynchronizowane z tymi zmianami.
Niektóre zespoły muszą odzwierciedlać bieżący stan operacyjnych baz danych na potrzeby raportowania i analizy. Inni muszą zachować pełną historię zmian na potrzeby inspekcji, wymagań prawnych lub analizy klientów.
Przechwytywanie zmian danych (CDC) traktuje bazę danych jako zestaw zmian, a nie jako kompletną statyczną bazę danych. Na poniższym diagramie pokazano, że gdy wiersz w tabeli źródłowej zawierającej dane pracownika zostanie zaktualizowany, wygeneruje nowy zestaw wierszy w kanale informacyjnym CDC zawierającym tylko zmiany. Każdy wiersz kanału informacyjnego CDC zazwyczaj zawiera dodatkowe metadane, w tym operację, taką jak UPDATE i kolumnę, która może służyć do określania kolejności każdego wiersza w kanale informacyjnym CDC, dzięki czemu można obsługiwać aktualizacje poza kolejnością. Na przykład kolumna w poniższym diagramie sequenceNum określa kolejność wierszy w strumieniu danych CDC.
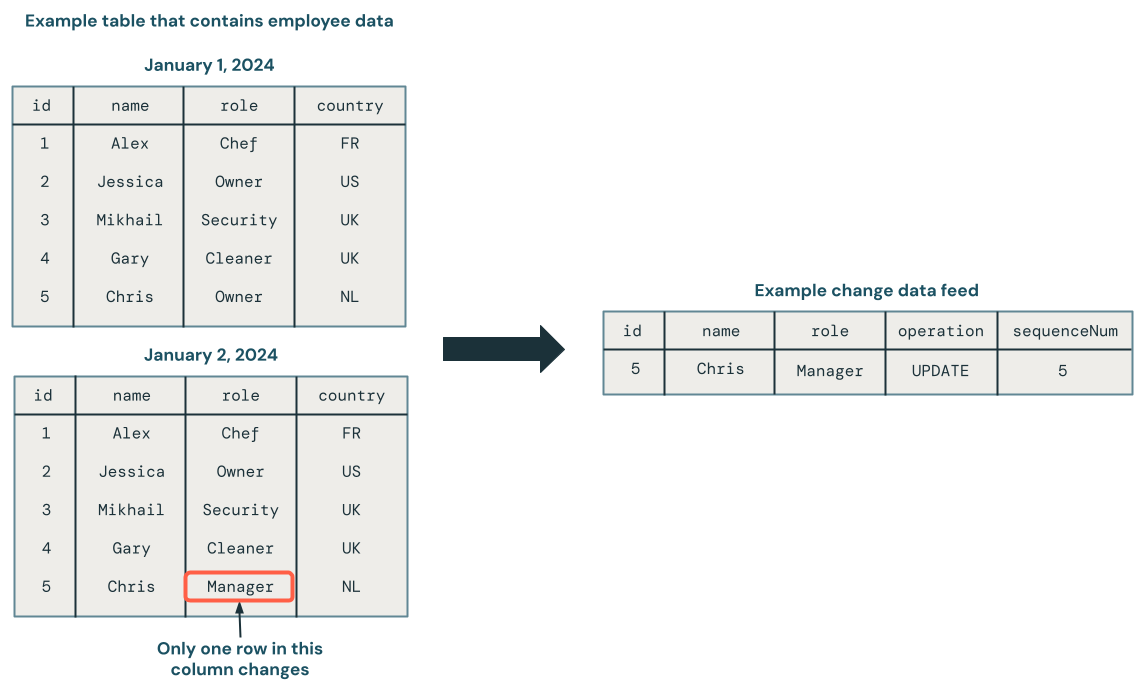
Usługa CDC umożliwia tylko wyświetlanie zmian danych dla prostszych transakcji podczas aktualizowania bazy danych w systemie podrzędnym. Może również umożliwiać wyświetlanie historii bazy danych, jeśli jest to wymagane.
Wyzwaniem jest to, że systemy źródłowe zapewniają dane w różnych formatach. Niektóre źródła zmian emitują dane przechwytujące poszczególne zmiany (wstawki, aktualizacje, usuwanie). Inne udostępniają tylko okresowe migawki całej tabeli. Każdy format wymaga różnych metod przetwarzania, aby zachować dokładne i aktualne tabele podrzędne.
W przeszłości zespoły oparły się na logice niestandardowej MERGE INTO , aby zastosować te zmiany — niezależnie od tego, czy pochodzą ze źródeł zmian, czy przez porównanie migawek. Takie podejście jest złożone i podatne na błędy, wymagając tabel przejściowych, funkcji okien i założeń sekwencjonowania, które są trudne do poznania i utrzymania w miarę rozwoju potoków.
Na tej stronie opisano dwa formaty CDC (SCD Type 1 i Type 2), czym jest CDC w szczegółach, i jak uzyskać korzyści z CDC, nawet gdy dane źródłowe nie obsługują CDC, korzystając z migawek.
Jakie są zalety usługi CDC?
Przechwytywanie zmian danych zapewnia kilka korzyści w twoich procesach.
- Zmiany danych są zwykle mniejsze niż pełny zestaw danych, a zmiany mogą być przetwarzane przez zapytania podrzędne jako przyrostowe aktualizacje danych.
- Zmienione dane mogą być przechowywane w sposób umożliwiający odtworzenie rekordów tak, jak wyglądały w określonym czasie, co zapewnia pełną historię dla audytu, raportowanie w punkcie czasowym lub analizę trendów.
- Zmiana danych umożliwia uzyskanie stabilnych kluczy zastępczych w czasie.
Sposób stosowania zmian: bieżący stan lub pełna historia zmian
Powolne zmienianie wymiarów (SCD) definiuje sposób stosowania i modelowania zmian nadrzędnych po ich przejściu do tabel analitycznych. Organizacje mogą używać różnych podejść w zależności od potrzeb dotyczących danych. Typ SCD 1 umożliwia zapisanie tylko bieżącego stanu zestawu danych. Typ SCD 2 zapisuje pełną historię zmian w zestawie danych. W tej sekcji opisano je bardziej szczegółowo.
Typ SCD 1: tylko bieżący stan
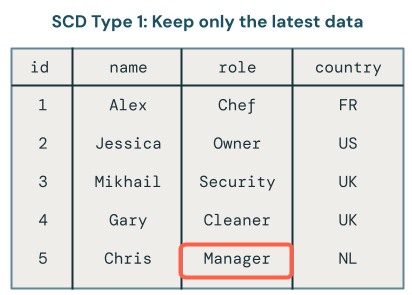
Typ SCD 1 zastępuje stare dane nowymi danymi za każdym razem, gdy wystąpią zmiany, zachowując tylko najnowszą wersję każdego rekordu. Historia nie jest zachowywana.
Użyj typu SCD 1, gdy:
- Potrzebny jest tylko bieżący stan danych.
- Chcesz, aby podrzędne zmaterializowane widoki odświeżały się przyrostowo zamiast pełnego przeliczenia.
- Potrzebujesz stabilnych kluczy zastępczych do sprzężeń.
Tylko najnowsza wersja danych jest dostępna w scD1. Jest to proste podejście, które można traktować jako przechowywanie tylko ostatecznej tabeli. Jeśli rekord zmieni się z Owner na Manager, tylko Manager pozostanie w tabeli:
Typ SCD 2: Śledzenie historyczne
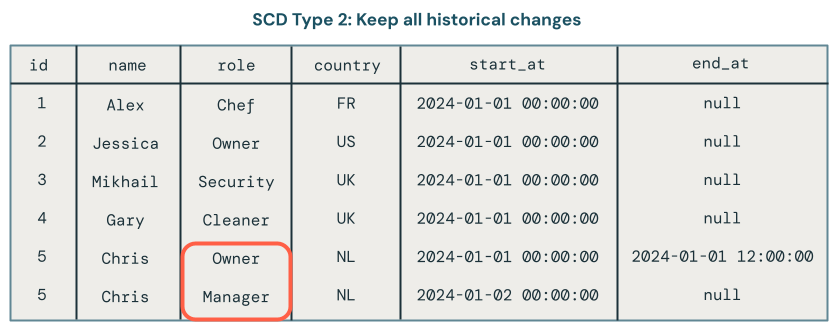
Typ SCD 2 utrzymuje pełny rekord historyczny, tworząc wiele wersji danych w czasie, każdą z oznaczeniem znacznikiem czasowym i metadanymi. Kolumny __START_AT i __END_AT definiują okres ważności dla każdej wersji rekordu. Aktywne rekordy mają __END_AT = NULL. Stan zestawu danych można wyświetlić w dowolnym momencie.
Użyj typu SCD 2, gdy:
- Możliwość inspekcji lub wymagania prawne wymagają śledzenia historycznego.
- Analiza klientów wymaga zrozumienia, w jaki sposób jednostki ewoluowały w czasie.
- Logika biznesowa wymaga raportowania chwilowego.
- Musisz przeanalizować trendy lub porównać stany historyczne.
Przetwarzanie typu 2 protokołu SCD utrzymuje historyczny rekord zmian danych. Jeśli na przykład rekord obecnie ma pole roli ustawione na Managerwartość , możesz również zobaczyć, że rola została wcześniej ustawiona na Ownerwartość . Na poniższej ilustracji dokładnie tak się stało z rekordem dla elementu Chris. Bieżący rekord można określić, ponieważ ma null wartość pola end_at :
Co to jest źródło danych CDC?
Przechwytywanie zmian danych (CDC) to wzorzec integracji danych, który przechwytuje zmiany wprowadzone w systemie źródłowym — wstawia, aktualizuje i usuwa. Zamiast przetwarzać całe zestawy danych, usługa CDC generuje źródła danych zawierające tylko zmodyfikowane rekordy.
Jeśli na przykład masz tabelę pracowników w programie Oracle z 50 wierszami, a jeden pracownik zmieni stanowisko, kanał informacyjny CDC zawiera jeden UPDATE rekord dla tego pracownika. Dzięki temu usługa Azure Databricks może przetwarzać tylko zmienione rekordy, a nie odczytywać całej tabeli źródłowej na każdym uruchomieniu.
Każdy rekord CDC ze źródłowej bazy danych obejmuje:
- Typ operacji (
INSERT,UPDATE,DELETE) - Wartości danych rekordu
- Numer sekwencji lub znacznik czasu na potrzeby określania kolejności deterministycznej
Numer kolejności gwarantuje, że opóźnienia lub przyloty poza kolejnością są prawidłowo stosowane. Transakcyjne bazy danych, takie jak SQL Server, MySQL i Oracle, generują natywnie źródła danych CDC. Tabele Delta generują również własne źródło danych CDC, znane jako zestawienie danych zmian (CDF), co znacznie ułatwia przetwarzanie zmian ze źródeł Delta.
Co to jest migawka?
Migawka reprezentuje pełny stan tabeli w określonym punkcie w czasie. W przeciwieństwie do źródeł danych CDC, które przechwytują tylko zmiany, migawki zawierają każdy wiersz w tabeli źródłowej.
Zespoły nie zawsze włączają źródła danych CDC w operacyjnych bazach danych z rozmaitych powodów.
- Koszt (CDC może zwiększyć obciążenie produkcyjnych baz danych)
- Problemy z wydajnością źródłowej bazy danych
- Starsze systemy, które nie obsługują usługi CDC
- Ograniczenia organizacyjne (zespoły zarządzające pozyskiwaniem danych nie są właścicielami nadrzędnych baz danych)
Gdy strumień zmian jest niedostępny, pozyskiwanie danych oparte na migawkach jest jedyną opcją. Migawki mogą pochodzić z:
- Okresowe eksporty z relacyjnych baz danych (Oracle, Postgres, SQL Server)
- Zrzuty plików przechowywania w chmurze z systemów nadrzędnych
- Tabele Delta (każda wersja tabeli stanowi de facto migawkę)
- Delta Sharing z nadrzędnymi dzierżawcami
Ponieważ migawki nie rejestrują zmian na poziomie rekordów, aby zidentyfikować, co zostało zmienione, trzeba porównać rekordy między migawkami, aby określić, które rekordy zostały wstawione, zaktualizowane lub usunięte.
Automatyczne przetwarzanie kanałów danych CDC
Usługa Azure Databricks upraszcza przetwarzanie CDC za pośrednictwem interfejsu AUTO CDC API w ramach potoków deklaratywnych Spark Lakeflow. Ten interfejs API jest przeznaczony do przetwarzania zmian z kanałów CDC na źródłowych bazach danych lub tabelach Delta z włączonym kanałem zmian danych.
Użyj AUTO CDC , gdy dowolny z tych elementów ma wartość true:
- System źródłowy generuje strumień danych o zmianach (CDF)
- Czytasz z tabeli Delta z włączonym Kanałem Zmian Danych
- Masz źródło danych CDC z relacyjnej bazy danych (za pośrednictwem narzędzi, takich jak Debezium lub Oracle GoldenGate)
AUTO CDC automatycznie obsługuje rekordy niezgodne z sekwencją, przetwarzając zdarzenia w kolejności określonej przez kolumnę sekwencjonowania. Kolumna sekwencjonowania musi być monotonicznie rosnącą reprezentacją prawidłowej kolejności zdarzeń, z jedną odrębną aktualizacją dla każdego klucza przy każdej wartości sekwencjonowania.
NULL wartości sekwencjonowania nie są obsługiwane. W przypadku typu SCD 2, potoki deklaratywne Lakeflow Spark propagują wartości sekwencjonowania do kolumn __START_AT i __END_AT tabeli docelowej.
Początkowe nawodnienie: Podczas replikowania istniejącej tabeli operacyjnej bazy danych do usługi Azure Databricks należy najpierw załadować wszystkie dane historyczne przed przetworzeniem bieżących zmian.
AUTO CDC obsługuje to poprzez jednorazowe przepływy, to tryb, który przetwarza wszystkie dostępne dane jednorazowo i wtedy się zatrzymuje. Po zakończeniu początkowego ładowania użyj wyzwalanego lub ciągłego przepływu do ciągłego przetwarzania CDC. Zapewnia to spójną logikę zarówno dla obciążeń zbiorczych, jak i przyrostowych.
Automatyczne przetwarzanie migawek
Gdy źródła danych CDC nie są dostępne, Azure Databricks udostępnia interfejs API AUTO CDC FROM SNAPSHOT. Ten interfejs API jest przeznaczony do pozyskiwania migawek; porównuje kolejne migawki, generuje syntetyczne zestawienie zmian i stosuje logikę SCD Type 1 lub Type 2 do tabeli docelowej. Tabela docelowa może dostarczyć źródło danych CDC (nazywane źródłem danych zmian (CDF) w tabelach delty typu SCD 1 lub typ 2 dla zapytań podrzędnych.
AUTO CDC FROM SNAPSHOT program jest obsługiwany tylko w interfejsie potoku języka Python. Migawki muszą być przetwarzane w kolejności rosnącej według wersji; jeśli zostanie wykryta migawka poza kolejnością, zostanie ona zignorowana. Przetwarzanie danych dla etapu końcowego, takie jak zmaterializowany widok, który wykonuje zapytania do danych wyjściowych AUTO CDC FROM SNAPSHOT zestawu danych, uzyskuje korzyści z technologii CDC, takie jak możliwość przyrostowego przetwarzania danych i stabilne klucze zastępcze.
Uwaga / Notatka
AUTO CDC FROM SNAPSHOT nie dotyczy tylko początkowych obciążeń. Jest przeznaczony do ciągłego przetwarzania, gdy migawki są jedynym dostępnym formatem. Za każdym razem, gdy pojawia się nowa migawka, interfejs API porównuje go z poprzednią migawką w celu uzyskania zmian i zestawienia danych zmian.
Użyj AUTO CDC FROM SNAPSHOT, gdy:
- Usługa CDC nie jest włączona w źródłowej bazie danych
- Masz dostęp tylko do okresowych migawek (zrzuty tabeli)
- Chcesz korzystać z usługi CDC w przypadku przetwarzania przyrostowego lub mieć pełną historię zmian.
AUTO CDC FROM SNAPSHOT automatycznie obsługuje następujące elementy:
- Porównuje kolejne migawki, aby zidentyfikować wstawione, zaktualizowane i usunięte rekordy.
- Generuje syntetyczny strumień zmian na podstawie różnic między migawkami.
- Stosuje tę samą logikę SCD co
AUTO CDCdo wyznaczania typu SCD typu 1 lub typu 2.
Uwaga / Notatka
AUTO CDC FROM SNAPSHOT wie tylko o zmianach między jedną migawką a następną i nie uzyskuje zmian pośrednich. Jeśli na przykład otrzymujesz codzienne migawki, a użytkownik zmienia swój adres dwa razy w ciągu jednego dnia (od A do B, a następnie od B do C), kanał zmian może przejść bezpośrednio z A do C, ponieważ otrzymano tylko migawki w tych momentach.
Wzorce przetwarzania migawek
AUTO CDC FROM SNAPSHOT obsługuje dwa wzorce określania wersji migawek.
Przetwarzanie migawek przy użyciu czasu pozyskiwania potoku
Migawka jest odczytywana w momencie uruchomienia potoku, a czas pozyskiwania jest używany jako wersja migawki. Nowa migawka jest pozyskiwana wraz z każdą aktualizacją potoku. Gdy potok działa w trybie ciągłym, wiele migawek jest pozyskiwanych na podstawie ustawienia interwału wyzwalacza dla przepływu.
Tego wzorca należy używać, gdy migawki są regularnie dostarczane i uporządkowane oraz można polegać na znaczniku czasu uruchomienia potoku do wersjonowania.
Przetwarzanie migawek przy użyciu funkcjonalności wersji
Udostępniasz funkcję, która określa wersję migawki do przetworzenia podczas uruchamiania potoku. Funkcja zwraca krotkę: (DataFrame, version_number). Interfejs API przetwarza migawki w kolejności zdefiniowanej przez numery wersji. Jeśli zostanie wykryta migawka niezgodna z kolejnością, migawka zostanie zignorowana.
Użyj tego wzorca, gdy:
- Wiele migawek może być jednocześnie dostarczanych i wymaga przetwarzania sekwencyjnego.
- Migawki mogą być dostarczane niechronologicznie.
- Potrzebna jest bezpośrednia kontrola nad kolejnością migawek.
Dodatkowe możliwości usługi CDC
Zmienianie operacji na miejscach docelowych usługi AUTO CDC
W przeciwieństwie do standardowych tabel przesyłania strumieniowego, tabele katalogu Unity, które są AUTO CDC obiektami docelowymi, obsługują INSERT, UPDATE, DELETE i MERGE, nawet wtedy, gdy potok jest uruchomiony. Aby uzyskać szczegółowe informacje i ograniczenia, zobacz Dodawanie, zmienianie lub usuwanie danych w docelowej tabeli przesyłania strumieniowego.
Odczytywanie źródeł danych zmian z miejsc docelowych usługi AUTO CDC
AUTO CDC docelowe tabele przesyłania strumieniowego mogą emitować własny Kanał Zmian Danych (CDF), co umożliwia potokom podrzędnym przetwarzanie zmian z wyjścia AUTO CDC. Aby uzyskać szczegółowe informacje, zobacz Odczytywanie zestawienia danych zmian z tabeli docelowej usługi AUTO CDC.
Metryki i monitorowanie
AUTO CDC automatycznie przechwytuje metryki num_upserted_rows oraz num_deleted_rows w każdym przebiegu potoku. Aby uzyskać szczegółowe informacje, zobacz Zaawansowane tematy usługi AUTO CDC.
Śledzenie podzestawów kolumn dla typu SCD 2
Domyślnie typ SCD 2 tworzy nową wersję za każdym razem, gdy każda wartość kolumny ulegnie zmianie.
AUTO CDC Umożliwia określenie kolumn do śledzenia historii, dzięki czemu zmiany w nieśledzonych kolumnach aktualizują bieżącą wersję zamiast tworzyć nowy rekord historyczny. Zmniejsza to koszty magazynu i złożoność zapytań przy jednoczesnym zachowaniu historii atrybutów krytycznych. Aby zapoznać się z przykładem, zobacz Track a column subset with SCD Type 2 (Śledzenie podzestawu kolumn przy użyciu typu SCD 2).
Recommendations
Użyj funkcji przechwytywania zmian danych (CDC), jeśli chcesz pracować tylko ze zmianami danych, na przykład, aby umożliwić przyrostowe aktualizowanie zmaterializowanych widoków podrzędnych. Należy również użyć usługi CDC, jeśli chcesz zachować historię zmian danych, na przykład, aby wiedzieć, kto miał jaką rolę w określonym punkcie w czasie.
Użyj interfejsów API AUTO CDC, gdy musisz replikować dane wejściowe do usługi Azure Databricks i zachować je w synchronizacji ze zmianami źródłowymi. Właściwy interfejs API zależy od tego, jak system źródłowy uwidacznia zmiany:
-
Użyj
AUTO CDCgdy źródło emituje zmiany — na przykład relacyjna baza danych z włączoną funkcją CDC (za pośrednictwem narzędzi, takich jak Debezium lub Oracle GoldenGate), tabela Delta z włączonym Change Data Feed lub dowolne źródło, które generuje strumień wstawień, aktualizacji i usuwania z kolumną sekwencjonowania. -
Użyj
AUTO CDC FROM SNAPSHOTjeśli źródło nie obsługuje CDC i zapewnia okresowe pełne zrzuty tabeli. Ten interfejs API wywnioskuje zmiany, porównując kolejne migawki i generują syntetyczne zestawienie zmian, dzięki czemu uzyskujesz te same korzyści z przetwarzania SCD, nawet bez natywnego źródła danych CDC.
W obu przypadkach wybierz typ SCD 1, jeśli potrzebujesz tylko bieżącego stanu każdego rekordu lub typu SCD 2, jeśli chcesz zachować pełną historię zmian na potrzeby inspekcji, raportowania do punktu w czasie lub analizy trendów.
Następne kroki
-
Interfejsy API usługi AUTO CDC: upraszczanie przechwytywania danych zmian za pomocą potoków: Dowiedz się, jak zaimplementować usługę CDC za
AUTO CDCpomocą interfejsów API iAUTO CDC FROM SNAPSHOT. - Zaawansowane tematy usługi AUTO CDC: Dowiedz się więcej o zaawansowanych tematach cdC, takich jak używanie operacji DML, odczytywanie źródeł danych zmian i monitorowanie metryk.