Automatyczne skalowanie usługi HDInsight w klastrach usługi AKS
Uwaga
Wycofamy usługę Azure HDInsight w usłudze AKS 31 stycznia 2025 r. Przed 31 stycznia 2025 r. należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure, aby uniknąć nagłego zakończenia obciążeń. Pozostałe klastry w ramach subskrypcji zostaną zatrzymane i usunięte z hosta.
Tylko podstawowa pomoc techniczna będzie dostępna do daty wycofania.
Ważne
Ta funkcja jest aktualnie dostępna jako funkcja podglądu. Dodatkowe warunki użytkowania dla wersji zapoznawczych platformy Microsoft Azure obejmują więcej warunków prawnych, które dotyczą funkcji platformy Azure, które znajdują się w wersji beta, w wersji zapoznawczej lub w inny sposób nie zostały jeszcze wydane w wersji ogólnodostępnej. Aby uzyskać informacje o tej konkretnej wersji zapoznawczej, zobacz Informacje o wersji zapoznawczej usługi Azure HDInsight w usłudze AKS. W przypadku pytań lub sugestii dotyczących funkcji prześlij żądanie w usłudze AskHDInsight , aby uzyskać szczegółowe informacje i postępuj zgodnie z nami, aby uzyskać więcej aktualizacji w społeczności usługi Azure HDInsight.
Ustalanie rozmiaru dowolnego klastra w celu spełnienia wydajności zadań i zarządzania kosztami przed upływem czasu jest zawsze trudne i trudne do określenia! Jedną z lukratywnych zalet tworzenia magazynu typu data lake over Cloud jest jego elastyczność, co oznacza użycie funkcji autoskalowania w celu zmaksymalizowania wykorzystania zasobów. Automatyczne skalowanie za pomocą platformy Kubernetes jest jednym z kluczy do ustanowienia ekosystemu zoptymalizowanego pod kątem kosztów. W przypadku różnych wzorców użycia w dowolnym przedsiębiorstwie mogą występować różnice w obciążeniach klastrów w czasie, które mogą prowadzić do niedostatecznej aprowizacji klastrów (nieobsadzonej wydajności) lub nadmiernej aprowizacji (niepotrzebne koszty spowodowane bezczynnymi zasobami).
Funkcja automatycznego skalowania oferowana w usłudze HDInsight w usłudze AKS może automatycznie zwiększyć lub zmniejszyć liczbę węzłów roboczych w klastrze. Skalowanie automatyczne używa metryk klastra i zasad skalowania używanych przez klientów.
Ta funkcja jest odpowiednia dla obciążeń o znaczeniu krytycznym, które mogą mieć
- Zmienne lub nieprzewidywalne wzorce ruchu i wymagają umów SLA w wysokiej wydajności i skali lub
- Wstępnie określony harmonogram wymagany dla węzłów roboczych, które mają być dostępne do pomyślnego wykonania zadań w klastrze.
Automatyczne skalowanie za pomocą usługi HDInsight w klastrach usługi AKS sprawia, że klastry są ekonomiczne i elastyczne na platformie Azure.
Dzięki automatycznej skalowaniu klienci mogą skalować klastry w dół bez wpływu na obciążenia. Jest ona włączona z zaawansowanymi funkcjami, takimi jak bezproblemowe likwidowanie i okres chłodzenia. Te możliwości umożliwiają użytkownikom podejmowanie świadomych wyborów dotyczących dodawania i usuwania węzłów na podstawie bieżącego obciążenia klastra.
Jak to działa
Ta funkcja działa przez skalowanie liczby węzłów w ramach wstępnie ustawionych limitów na podstawie metryk klastra lub zdefiniowanego harmonogramu operacji skalowania w górę i w dół. Istnieją dwa typy warunków wyzwalania zdarzeń skalowania automatycznego: wyzwalacze oparte na progach dla różnych metryk wydajności klastra (nazywane skalowaniem opartym na obciążeniu) i wyzwalaczy opartych na czasie (nazywanych skalowaniem opartym na harmonogramie).
Skalowanie oparte na obciążeniu zmienia liczbę węzłów w klastrze w określonym zakresie, aby zapewnić optymalne użycie procesora CPU i zminimalizować koszty działania.
Skalowanie oparte na harmonogramie zmienia liczbę węzłów w klastrze na podstawie harmonogramu operacji skalowania w górę i skalowania w dół.
Uwaga
Skalowanie automatyczne nie obsługuje zmiany typu jednostki SKU istniejącego klastra.
Zgodność klastra
W poniższej tabeli opisano typy klastrów, które są zgodne z funkcją skalowania automatycznego oraz jakie są dostępne lub planowane.
| Obciążenie | Oparte na obciążeniu | Na podstawie harmonogramu |
|---|---|---|
| Planowane | Tak | |
| Trino | Tak** | Tak** |
| platforma Spark | Tak** | Tak** |
**Możliwe jest skonfigurowanie likwidowania w sposób graceful.
Metody skalowania
Skalowanie oparte na harmonogramie:
Gdy zadania będą uruchamiane zgodnie z ustalonymi harmonogramami i przewidywalnym czasem trwania lub gdy przewidujesz niskie użycie w określonych porach dnia, na przykład środowiska testowe i deweloperskie w godzinach pracy po pracy, zadania zakończenia dnia.

Skala oparta na obciążeniu:
Gdy wzorce obciążenia zmieniają się znacząco i nieprzewidywalnie w ciągu dnia, na przykład porządkowaj przetwarzanie danych z losowymi wahaniami wzorców obciążenia na podstawie różnych czynników.

Po wybraniu nowej opcji skonfiguruj regułę skalowania możesz teraz dostosować reguły skalowania.
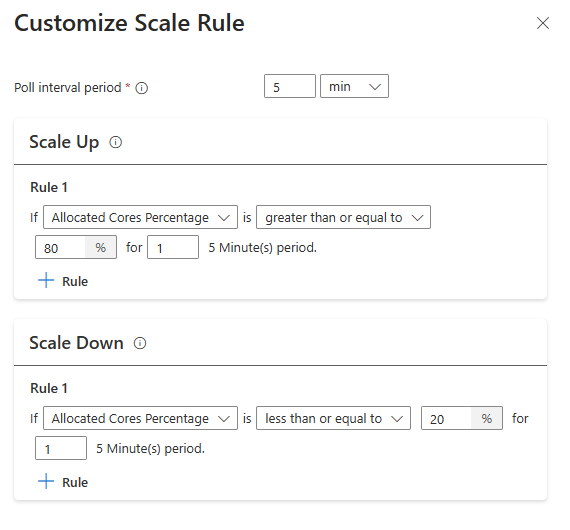

Napiwek
- Reguły skalowania w górę mają pierwszeństwo po wyzwoleniu co najmniej jednej reguły. Nawet jeśli tylko jedna z reguł skalowania w górę sugeruje, że klaster jest w niepełnej aprowizacji, klaster spróbuje skalować w górę. Aby skalowanie w dół miało miejsce, nie należy wyzwalać reguły skalowania w górę.


Warunki skalowania oparte na obciążeniu
Po wykryciu następujących warunków automatyczne skalowanie zgłasza żądanie skalowania
| Skalowanie w górę | Skalowanie w dół |
|---|---|
| Przydzielone rdzenie są większe niż 80% dla 5-minutowego interwału sondowania (1-minutowy okres sprawdzania) | Przydzielone rdzenie są mniejsze lub równe 20% dla interwału sondowania 5 minut (1-minutowy okres sprawdzania) |
W przypadku skalowania w górę automatyczne skalowanie wysyła żądanie skalowania w górę, aby dodać wymaganą liczbę węzłów. Skalowanie w górę zależy od liczby nowych węzłów roboczych wymaganych do spełnienia bieżących wymagań dotyczących procesora CPU i pamięci. Ta wartość jest ograniczona do maksymalnej liczby ustawionych węzłów roboczych.
W przypadku skalowania w dół automatyczne skalowanie wysyła żądanie usunięcia niektórych węzłów. Zagadnienia dotyczące skalowania w dół obejmują liczbę zasobników na węzeł, bieżące wymagania dotyczące procesora CPU i pamięci oraz węzły robocze, które są kandydatami do usunięcia na podstawie bieżącego wykonywania zadania. Operacja skalowania w dół najpierw likwiduje węzły, a następnie usuwa je z klastra.
Ważne
Aparat reguł automatycznego skalowania aktywnie opróżnia stare zdarzenia co 30 minut w celu zoptymalizowania pamięci systemowej. W związku z tym istnieje górny limit granic wynoszący 30 minut w interwale reguły skalowania. Aby zapewnić spójne i niezawodne wyzwalanie akcji skalowania, należy ustawić interwał reguły skalowania na wartość mniejszą niż limit. Stosując się do tych wytycznych, można zagwarantować bezproblemowy i wydajny proces skalowania przy jednoczesnym efektywnym zarządzaniu zasobami systemowymi.
Metryki klastra
Automatyczne skalowanie stale monitoruje klaster i zbiera następujące metryki dla autoskalowania opartego na obciążeniu:
Metryki klastra dostępne dla celów skalowania
| Metryczne | opis |
|---|---|
| Procent dostępnych rdzeni | Całkowita liczba rdzeni dostępnych w klastrze w porównaniu z całkowitą liczbą rdzeni w klastrze. |
| Procent dostępnej pamięci | Łączna ilość pamięci (w MB) dostępna w klastrze w porównaniu z całkowitą ilością pamięci w klastrze. |
| Procent przydzielonych rdzeni | Całkowita liczba rdzeni przydzielonych w klastrze w porównaniu z całkowitą liczbą rdzeni w klastrze. |
| Procent przydzielonej pamięci | Ilość pamięci przydzielonej w klastrze w porównaniu z całkowitą ilością pamięci w klastrze. |
Domyślnie powyższe metryki są sprawdzane co 300 sekund, można ją również konfigurować podczas dostosowywania interwału sondowania przy użyciu opcji dostosowywania autoskalowania. Automatyczne skalowanie sprawia, że decyzje dotyczące skalowania w górę lub w dół są podejmowane na podstawie tych metryk.
Uwaga
Domyślnie automatyczne skalowanie używa domyślnego kalkulatora zasobów dla usługi YARN dla platformy Apache Spark. Skalowanie oparte na obciążeniu jest dostępne dla klastrów Apache Spark.
Bezproblemowe likwidowanie
Przedsiębiorstwa potrzebują sposobów osiągnięcia skali petabajtów za pomocą skalowania automatycznego i bezproblemowego zlikwidowania zasobów, gdy nie są już potrzebne. W takim scenariuszu przydaje się bezproblemowa funkcja likwidowania.
Bezproblemowe likwidowanie umożliwia wykonywanie zadań nawet po wyzwoleniu automatycznego skalowania wyzwolonych likwidacji węzłów procesu roboczego. Ta funkcja umożliwia kontynuowanie aprowizacji węzłów do czasu ukończenia zadań.
Trino : Pracownicy mają domyślnie włączoną funkcję Graceful Likwiduj. Koordynator umożliwia zakończenie zadań procesu roboczego przez skonfigurowany czas przed usunięciem procesu roboczego z klastra. Limit czasu można skonfigurować przy użyciu natywnego parametru
shutdown.grace-periodTrino lub na stronie konfiguracji usługi Azure Portal.Apache Spark : skalowanie w dół może mieć wpływ na/zatrzymanie wszystkich uruchomionych zadań w klastrze. Jeśli włączysz ustawienia Graceful Likwidowanie w witrynie Azure Portal, obejmuje ona graceful likwidowanie węzłów usługi YARN i gwarantuje, że wszystkie prace w toku w węźle roboczym zostaną ukończone przed usunięciem węzła z usługi HDInsight w klastrze usługi AKS.
Okres schładzania
Aby uniknąć operacji ciągłego skalowania w górę, aparat autoskalowania czeka na konfigurowalny interwał przed zainicjowaniem innego zestawu operacji skalowania w górę. Wartość domyślna jest ustawiona na 180 sekund
Uwaga
- W niestandardowych regułach skalowania żaden wyzwalacz reguły nie może mieć interwału wyzwalacza większego niż 30 minut. Po wystąpieniu zdarzenia automatycznego skalowania czas oczekiwania przed wymusiniem innej zasady skalowania.
- Okres schładzania powinien być większy niż interwał zasad, więc metryki klastra mogą zostać zresetowane.
Rozpocznij
Aby funkcja autoskalowania działała, musisz przypisać uprawnienia właściciela lub współautora do tożsamości usługi zarządzanej (używanej podczas tworzenia klastra) na poziomie klastra przy użyciu funkcji Zarządzanie dostępem i tożsamościami w okienku po lewej stronie.
Zapoznaj się z poniższą ilustracją i krokami wymienionymi na temat dodawania przypisania roli

Wybierz pozycję Dodaj przypisanie roli,
- Typ przypisania: Role administratora uprzywilejowanego
- Rola: Właściciel lub Współautor
- Członkowie: wybierz pozycję Tożsamość zarządzana i wybierz tożsamość zarządzaną przypisaną przez użytkownika, która została podana podczas fazy tworzenia klastra.
- Przypisz rolę.

Tworzenie klastra z automatycznym skalowaniem opartym na harmonogramie
Po utworzeniu puli klastrów utwórz nowy klaster z żądanym obciążeniem (w typie klastra) i wykonaj inne kroki w ramach normalnego procesu tworzenia klastra.
Na karcie Konfiguracja włącz przełącznik Skalowanie automatyczne.
Wybieranie opcji Automatyczne skalowanie oparte na harmonogramie
Wybierz strefę czasową, a następnie kliknij pozycję + Dodaj regułę
Wybierz dni tygodnia, do których ma mieć zastosowanie nowy warunek.
Edytuj czas, w jakim warunek powinien obowiązywać, oraz liczbę węzłów, do których ma zostać przeskalowany klaster.

Uwaga
- Użytkownik powinien mieć rolę "właściciel" lub "współautor" w tożsamości usługi zarządzanej klastra, aby autoskalować do pracy.
- Wartość domyślna definiuje początkowy rozmiar klastra podczas jego tworzenia.
- Różnica między dwoma harmonogramami jest domyślnie ustawiona na 30 minut.
- Wartość godziny jest zgodna z formatem 24-godzinnym
- W przypadku okna ciągłego przekraczającego 24 godziny w ciągu kilku dni wymagane jest ustawienie harmonogramu skalowania automatycznego na przestrzeni dni, a skalowanie automatyczne zakłada godzinę 23:59 jako 00:00 (z tą samą liczbą węzłów) obejmujące dwa dni od 22:00 do 23:59, 00:00 do 02:00 jako 22:00 do 02:00.
- Harmonogramy są domyślnie ustawiane w uniwersalnym czasie koordynowanym (UTC). Zawsze możesz zaktualizować strefę czasową odpowiednio do lokalnej strefy czasowej, używając dostępnej listy rozwijanej. Jeśli korzystasz ze strefy czasowej, która obserwuje letnie oszczędności, harmonogram nie dostosowuje się automatycznie, musisz odpowiednio zarządzać aktualizacjami harmonogramu.

Tworzenie klastra z automatycznym skalowaniem opartym na obciążeniu
Po utworzeniu puli klastrów utwórz nowy klaster z żądanym obciążeniem (w typie klastra) i wykonaj inne kroki w ramach normalnego procesu tworzenia klastra.
Na karcie Konfiguracja włącz przełącznik Skalowanie automatyczne.
Wybieranie opcji Skalowanie automatyczne oparte na obciążeniu
Na podstawie typu obciążenia masz opcje dodawania bezproblemowego limitu czasu likwidowania, ochładzania okresu
Wybierz minimalną i maksymalną liczbę węzłów, a w razie potrzeby skonfiguruj reguły skalowania, aby dostosować skalowanie automatyczne do własnych potrzeb.

Napiwek
- Twoja subskrypcja ma limit przydziału pojemności dla każdego regionu. Całkowita liczba rdzeni węzłów głównych i maksymalna liczba węzłów roboczych nie może przekroczyć limitu przydziału pojemności. Jednak ten limit przydziału jest miękkim limitem; Zawsze możesz utworzyć bilet pomocy technicznej, aby łatwo go zwiększyć.
- Jeśli przekroczysz łączny limit przydziału rdzeni, zostanie wyświetlony komunikat o błędzie z informacją
The maximum node count you can select is {maxCount} due to the remaining quota in the selected subscription ({remaining} cores). - Reguły skalowania w górę mają pierwszeństwo po wyzwoleniu co najmniej jednej reguły. Nawet jeśli tylko jedna z reguł skalowania w górę sugeruje, że klaster jest w niepełnej aprowizacji, klaster spróbuje skalować w górę. Aby skalowanie w dół miało miejsce, nie należy wyzwalać reguły skalowania w górę.
- W publicznej wersji zapoznawczej usługa HDInsight w usłudze AKS obsługuje maksymalnie 500 węzłów w klastrze.

Tworzenie klastra przy użyciu szablonu usługi Resource Manager
Automatyczne skalowanie oparte na harmonogramie
Usługę HDInsight w klastrze usługi AKS można utworzyć przy użyciu skalowania automatycznego opartego na harmonogramie przy użyciu szablonu usługi Azure Resource Manager, dodając autoskalowanie do sekcji clusterProfile —> autoscaleProfile.
Węzeł skalowania automatycznego zawiera cykl zawierający strefę czasową i harmonogram, który opisuje, kiedy następuje zmiana. Aby uzyskać pełny szablon usługi Resource Manager, zobacz przykładowy kod JSON
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "ScheduleBased",
"gracefulDecommissionTimeout": 60,
"scheduleBasedConfig": {
"schedules": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday"
],
"startTime": "09:00",
"endTime": "10:00",
"count": 2
},
{
"days": [
"Sunday",
"Saturday"
],
"startTime": "12:00",
"endTime": "22:00",
"count": 5
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "22:00",
"endTime": "23:59",
"count": 6
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "00:00",
"endTime": "05:00",
"count": 6
}
],
"timeZone": "UTC",
"defaultCount": 110
}
}
}
Napiwek
- Aby uniknąć błędów operacji skalowania, musisz ustawić harmonogramy niezwiązane z konfliktami przy użyciu wdrożeń usługi ARM.
Automatyczne skalowanie oparte na obciążeniu
Usługę HDInsight w klastrze usługi AKS można utworzyć przy użyciu skalowania automatycznego opartego na obciążeniu przy użyciu szablonu usługi Azure Resource Manager, dodając autoskalowanie do sekcji clusterProfile —> autoscaleProfile.
Węzeł skalowania automatycznego zawiera
- interwał sondowania, okres ochładzania,
- graceful likwiduj,
- węzły minimalne i maksymalne,
- standardowe reguły progowe,
- skalowanie metryk opisujących, kiedy następuje zmiana.
Aby uzyskać pełny szablon usługi Resource Manager, zobacz przykładowy kod JSON w następujący sposób
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "LoadBased",
"gracefulDecommissionTimeout": 60,
"loadBasedConfig": {
"minNodes": 2,
"maxNodes": 157,
"pollInterval": 300,
"cooldownPeriod": 180,
"scalingRules": [
{
"actionType": "scaleup",
"comparisonRule": {
"threshold": 80,
"operator": " greaterThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
},
{
"actionType": "scaledown",
"comparisonRule": {
"threshold": 20,
"operator": " lessThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
}
]
}
}
}
Korzystanie z interfejsu API REST
Aby włączyć lub wyłączyć automatyczne skalowanie w uruchomionym klastrze przy użyciu interfejsu API REST, utwórz żądanie PATCH do punktu końcowego skalowania automatycznego: https://management.azure.com/subscriptions/{{USER_SUB}}/resourceGroups/{{USER_RG}}/providers/Microsoft.HDInsight/clusterpools/{{CLUSTER_POOL_NAME}}/clusters/{{CLUSTER_NAME}}?api-version={{HILO_API_VERSION}}
- Użyj odpowiednich parametrów w ładunku żądania. Ładunek json może służyć do włączania skalowania automatycznego.
- Użyj ładunku (autoskalowanieProfile: null) lub użyj flagi (włączonej, false), aby wyłączyć automatyczne skalowanie.
- Zapoznaj się z przykładami JSON wymienionymi w powyższym kroku, aby uzyskać informacje.
Wstrzymywanie automatycznego skalowania dla uruchomionego klastra
Wprowadziliśmy funkcję wstrzymywania w skalowaniu automatycznym. Teraz przy użyciu witryny Azure Portal możesz wstrzymać automatyczne skalowanie w uruchomionym klastrze. Na poniższym diagramie pokazano, jak wybrać wstrzymywanie i wznawianie skalowania automatycznego

Możesz wznowić działanie po wznowieniu operacji autoskalowania.

Napiwek
Podczas konfigurowania wielu harmonogramów i wstrzymania skalowania automatycznego nie powoduje wyzwolenia następnego harmonogramu. Liczba węzłów pozostaje taka sama, nawet jeśli węzły są w stanie zlikwidowania.
Kopiowanie konfiguracji skalowania automatycznego
Za pomocą witryny Azure Portal możesz teraz skopiować te same konfiguracje skalowania automatycznego dla tego samego kształtu klastra w puli klastrów. Możesz użyć tej funkcji i wyeksportować lub zaimportować te same konfiguracje.

Monitorowanie działań automatycznego skalowania
Stan klastra
Stan klastra wymieniony w witrynie Azure Portal może ułatwić monitorowanie działań skalowania automatycznego. Wszystkie komunikaty o stanie klastra, które mogą zostać wyświetlone, zostały wyjaśnione na liście.
| Stan klastra | opis |
|---|---|
| Powodzenie | Klaster działa normalnie. Wszystkie poprzednie działania skalowania automatycznego zostały ukończone pomyślnie. |
| Zaakceptowano | Operacja klastra (na przykład: skalowanie w górę) jest akceptowana, czekając na zakończenie operacji. |
| Niepowodzenie | Oznacza to, że bieżąca operacja nie powiodła się z jakiegoś powodu, klaster może nie działać. |
| Anulowany | Bieżąca operacja jest anulowana. |

Aby wyświetlić bieżącą liczbę węzłów w klastrze, przejdź do wykresu Rozmiar klastra na stronie Przegląd klastra.

Historia operacji
Możesz wyświetlić historię skalowania klastra w górę i w dół w ramach metryk klastra. Możesz również wyświetlić listę wszystkich akcji skalowania w ciągu ostatniego dnia, tygodnia lub innego okresu.

Dodatkowe zasoby