Co to jest usługa Azure HDInsight?
Azure HDInsight jest zarządzaną usługą analityczną typu „open source” w chmurze o szerokim zakresie, z przeznaczeniem dla przedsiębiorstw. Usługa HDInsight umożliwia korzystanie z platform typu open source, takich jak Apache Spark, Apache Hive, LLAP, Apache Kafka, Hadoop i inne, w środowisku platformy Azure.
Co to jest usługa HDInsight oraz stos technologii Hadoop?
Azure HDInsight to zarządzana platforma klastra, która ułatwia uruchamianie struktur danych big data, takich jak Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Hadoop i inne w środowisku platformy Azure. Jest ona przeznaczona do obsługi dużych ilości danych z dużą szybkością i wydajnością.
Dlaczego warto używać usługi Azure HDInsight?
| Możliwość | opis |
|---|---|
| Natywna usługa w chmurze | Usługa Azure HDInsight umożliwia tworzenie zoptymalizowanych klastrów dla platformy Spark, interakcyjnego zapytania (LLAP), Kafka, HBase i Hadoop na platformie Azure. Usługa HDInsight zapewnia również kompleksową umowę dotyczącą poziomu usług dla wszystkich obciążeń produkcyjnych. |
| Niskie koszty i skalowalność | Usługa HDInsight umożliwia skalowanie obciążeń w górę lub w dół. Możesz zmniejszyć koszty, tworząc klastry na żądanie i płacąc tylko za używane kwestie. Możesz także tworzyć potoki danych w celu operacjonalizacji zadań. Rozdzielenie obliczeń i magazynu zapewnia większą wydajność i elastyczność. |
| Bezpieczeństwo i zgodność | Usługa HDInsight umożliwia ochronę zasobów danych przedsiębiorstwa za pomocą usługi Azure Virtual Network, szyfrowania i integracji z identyfikatorem Entra firmy Microsoft. Usługa HDInsight spełnia również najpopularniejsze branżowe i rządowe normy zgodności. |
| Monitorowanie | Usługa Azure HDInsight jest zintegrowana z dziennikami usługi Azure Monitor, zapewniając jeden interfejs, za pomocą którego można monitorować wszystkie swoje klastry. |
| Globalna dostępność | Usługa HDInsight jest dostępna w większej regionie niż jakakolwiek inna oferta analizy danych big data . Usługa Azure HDInsight jest również dostępna w ramach chmur Azure Government, Azure (Chiny) i Azure (Niemcy), dzięki czemu odpowiada na potrzeby Twojego przedsiębiorstwa w najważniejszych obszarach suwerenności. |
| Produktywność | Usługa Azure HDInsight umożliwia korzystanie z zaawansowanych narzędzi zapewniających produktywność w usłudze Hadoop i na platformie Spark w ramach preferowanego środowiska deweloperskiego. Te środowiska programistyczne obejmują programy Visual Studio, VS Code, Eclipse i IntelliJ dla języków Scala, Python, Java i .NET. |
| Rozszerzalność | Klastry usługi HDInsight można rozszerzyć za pomocą zainstalowanych składników (Hue, Presto itd.), używając akcji skryptu, dodając węzły brzegowe lub integrując je z innymi certyfikowanymi aplikacjami danych big data . Usługa HDInsight umożliwia bezproblemową integrację z najpopularniejszymi rozwiązaniami danych big data oraz wdrażanie za pomocą jednego kliknięcia. |
What is big data?
Dane big data są gromadzone szybciej, w większych ilościach i bardziej różnorodnych formatach niż kiedykolwiek wcześniej. Mogą to być dane historyczne (czyli przechowywane) lub dane czasu rzeczywistego (przesyłane strumieniowo ze źródła). Zobacz Scenariusze użycia usługi HDInsight, aby zapoznać się z najpopularniejszymi przypadkami użycia danych big data.
Typy klastrów w usłudze HDInsight
Usługa HDInsight zawiera określone typy klastrów i oferuje możliwości dostosowywania klastra, takie jak dodawanie składników, narzędzi i języków. W usłudze HDInsight dostępne są następujące typy klastrów:
| Typ klastra | opis | Rozpocznij |
|---|---|---|
| Apache Hadoop | platforma korzystająca z systemu HDFS, zarządzania zasobami YARN i prostego modelu programowania MapReduce do celów równoległego przetwarzania i analizowania danych partii. | Tworzenie klastra Apache Hadoop |
| Apache Spark | platforma przetwarzania równoległego typu „open source”, która obsługuje przetwarzanie w pamięci umożliwiające zwiększenie wydajności aplikacji do analizy danych big data. Zobacz temat Co to jest platforma Apache Spark w usłudze HDInsight? | Tworzenie klastra Apache Spark |
| Apache HBase | baza danych NoSQL oparta na platformie Hadoop, która zapewnia dostęp losowy i wysoki poziom spójności w przypadku dużych ilości nieustrukturyzowanych i częściowo ustrukturyzowanych danych — potencjalnie miliardów wierszy pomnożonych przez miliony kolumn. Zobacz temat Co to jest usługa HBase w usłudze HDInsight? | Tworzenie klastra Apache HBase |
| Zapytanie interakcyjne Apache | pamięć podręczna w pamięci do interaktywnego i szybszego wykonywania zapytań programu Hive. Zobacz temat Use Interactive Query in HDInsight (Używanie zapytań interakcyjnych w usłudze HDInsight). | Tworzenie klastra zapytań interakcyjnych |
| Apache Kafka | Platforma typu open source służy do tworzenia potoków danych przesyłania strumieniowego i aplikacji. Platforma Kafka obejmuje również funkcję kolejki komunikatów, która umożliwia publikowanie i subskrybowanie strumieni danych. Zobacz temat Introduction to Apache Kafka on HDInsight (Wprowadzenie do platformy Apache Kafka w usłudze HDInsight). | Tworzenie klastra platformy Apache Kafka |
Scenariusze użycia usługi HDInsight
Usługi Azure HDInsight można używać w różnych scenariuszach przetwarzania danych big data . Mogą to być dane historyczne (dane, które są już zbierane i przechowywane) lub dane w czasie rzeczywistym (dane przesyłane bezpośrednio ze źródła). Scenariusze związane z przetwarzaniem takich danych można podzielić na następujące kategorie:
Przetwarzanie wsadowe (ETL)
Wyodrębnianie, transformacja, ładowanie (ETL, extraction, transformation, and loading) to proces wyodrębniania danych ze strukturą lub bez struktury z heterogenicznych źródeł danych. Dane te są następnie przekształcane do formatu strukturalnego i ładowane do magazynu danych. Przekształcone dane mogą być używane do analizy lub magazynowania danych.
Magazynowanie danych
Przy użyciu usługi HDInsight można wykonywać interakcyjne zapytania w skali petabajtów względem danych ze strukturą lub bez struktury w dowolnym formacie. Można także tworzyć modele łączące je z narzędziami analizy biznesowej.
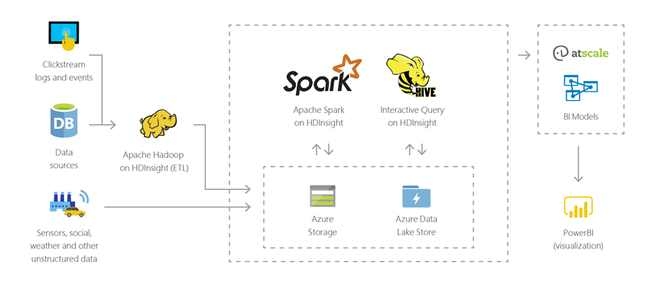
Internet rzeczy (IoT)
Za pomocą usługi HDInsight można przetwarzać dane przesyłane strumieniowo odbierane w czasie rzeczywistym z różnych rodzajów urządzeń. Aby uzyskać więcej informacji, przeczytaj ten wpis w blogu platformy Azure, w którym zapowiadana jest publiczna wersja zapoznawcza platformy Apache Kafka w usłudze HDInsight z funkcją Dyski zarządzane platformy Azure.

Połączenie hybrydowe
Za pomocą usługi HDInsight można rozszerzyć istniejącą lokalną infrastrukturę danych big data na platformę Azure, aby zastosować zaawansowane możliwości analizy chmury.

Składniki typu open source w usłudze HDInsight
Usługa Azure HDInsight umożliwia tworzenie klastrów z platformami typu open source, takimi jak Spark, Hive, LLAP, Kafka, Hadoop i HBase. Domyślnie te klastry obejmują różne składniki typu open source, takie jak Apache Ambari, Avro, Apache Hive 3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie i Apache ZooKeeper.
Języki programowania w usłudze HDInsight
Klastry HDInsight, takie jak Spark, HBase, Kafka, Hadoop i inne, obsługują wiele języków programowania. Niektóre z nich nie są instalowane domyślnie. W przypadku bibliotek, modułów lub pakietów, które nie są instalowane domyślnie, użyj akcji skryptu, aby zainstalować składnik.
| Język programowania | Informacja |
|---|---|
| Domyślna obsługa języka programowania | Domyślnie klastry usługi HDInsight obsługują języki:
|
| Języki maszyny wirtualnej Java (JVM) | Wiele języków innych niż Java można uruchamiać za pomocą maszyny wirtualnej Java (JVM). Jeśli jednak uruchomisz niektóre z tych języków, może być konieczne zainstalowanie większej liczby składników w klastrze. Następujące języki oparte na maszynie JVM są obsługiwane w klastrach usługi HDInsight:
|
| Języki specyficzne dla platformy Hadoop | Klastry usługi HDInsight obsługują następujące języki specyficzne dla stosu technologii Hadoop:
|
Narzędzia programistyczne dla usługi HDInsight
Narzędzia programistyczne usługi HDInsight, takie jak IntelliJ, Eclipse, Visual Studio Code i Visual Studio, umożliwiają tworzenie i przesyłanie zapytań o dane i zadania usługi HDInsight, wykorzystując bezproblemową integrację z platformą Azure.
- Zestaw narzędzi platformy Azure dla środowiska IntelliJ 10
- Zestaw narzędzi platformy Azure dla środowiska Eclipse 6
- Narzędzia usługi Azure HDInsight dla programu VS Code 13
- Narzędzia usługi Azure Data Lake tools for Visual Studio 9
Analiza biznesowa w usłudze HDInsight
Znane narzędzia do analizy biznesowej (BI, business intelligence) pobierają, analizują i raportują dane zintegrowane z usługą HDInsight przy użyciu dodatku Power Query lub sterownika Microsoft Hive ODBC:
Łączenie programu Excel z usługą Apache Hadoop za pomocą funkcji Power Query (wymaga systemu Windows)
Łączenie programu Excel z usługą Apache Hadoop przy użyciu sterownika Microsoft Hive ODBC (wymaga systemu Windows)
Miejsce przechowywania danych w regionie
Platformy Spark, Hadoop i LLAP nie przechowują danych klientów, więc te usługi automatycznie spełniają wymagania dotyczące rezydencji danych w regionie określone w Centrum zaufania.
Platforma Kafka i baza HBase przechowują dane klientów. Te dane są automatycznie przechowywane przez platformy Kafka i bazę danych HBase w jednym regionie, więc ta usługa spełnia wymagania dotyczące przechowywania danych w regionie określone w Centrum zaufania.
Znane narzędzia do analizy biznesowej (BI) pobierają, analizują i raportuje dane zintegrowane z usługą HDInsight przy użyciu dodatku Power Query lub Sterownik Microsoft Hive ODBC.