Planowanie pojemności dla aplikacji usługi Service Fabric
W tym dokumencie pokazano, jak oszacować ilość zasobów (procesory CPU, pamięć RAM, magazyn dyskowy) potrzebnych do uruchamiania aplikacji usługi Azure Service Fabric. Często wymagania dotyczące zasobów zmieniają się w czasie. Zwykle w miarę opracowywania/testowania usługi wymagane jest kilka zasobów, a następnie wymaganie większej ilości zasobów w miarę przechodzenia do środowiska produkcyjnego, a popularność aplikacji rośnie. Podczas projektowania aplikacji należy zastanowić się nad długoterminowymi wymaganiami i dokonać wyborów, które umożliwiają skalowanie usługi w celu spełnienia wysokiego zapotrzebowania klientów.
Podczas tworzenia klastra usługi Service Fabric decydujesz, jakiego rodzaju maszyny wirtualne tworzą klaster. Każda maszyna wirtualna ma ograniczoną ilość zasobów w postaci procesorów (rdzeni i szybkości), przepustowości sieci, pamięci RAM i magazynu dyskowego. W miarę zwiększania się usługi w miarę upływu czasu można uaktualnić do maszyn wirtualnych, które oferują większe zasoby i/lub dodać więcej maszyn wirtualnych do klastra. Aby wykonać tę drugą czynność, musisz najpierw utworzyć architekturę usługi, aby móc korzystać z nowych maszyn wirtualnych, które są dynamicznie dodawane do klastra.
Niektóre usługi nie zarządzają niewielką ilością danych na samych maszynach wirtualnych. W związku z tym planowanie pojemności dla tych usług powinno koncentrować się głównie na wydajności, co oznacza wybranie odpowiednich procesorów (rdzeni i szybkości) maszyn wirtualnych. Ponadto należy rozważyć przepustowość sieci, w tym częstotliwość transferów sieci i ilość przesyłanych danych. Jeśli usługa wymaga zwiększenia użycia usługi, możesz dodać więcej maszyn wirtualnych do klastra i zrównoważyć obciążenie żądań sieciowych na wszystkich maszynach wirtualnych.
W przypadku usług, które zarządzają dużymi ilościami danych na maszynach wirtualnych, planowanie pojemności powinno skupić się przede wszystkim na rozmiarze. W związku z tym należy dokładnie rozważyć pojemność pamięci RAM i magazynu dyskowego maszyny wirtualnej. System zarządzania pamięcią wirtualną w systemie Windows sprawia, że miejsce na dysku wygląda jak pamięć RAM do kodu aplikacji. Ponadto środowisko uruchomieniowe usługi Service Fabric zapewnia inteligentne stronicowanie, które zachowuje tylko gorące dane w pamięci i przenosi zimne dane na dysk. W związku z tym aplikacje mogą używać większej ilości pamięci niż jest fizycznie dostępna na maszynie wirtualnej. Posiadanie większej ilości pamięci RAM po prostu zwiększa wydajność, ponieważ maszyna wirtualna może zachować więcej miejsca do magazynowania na dysku w pamięci RAM. Wybrana maszyna wirtualna powinna mieć dysk wystarczająco duży, aby przechowywać dane, które chcesz przechowywać na maszynie wirtualnej. Podobnie maszyna wirtualna powinna mieć wystarczającą ilość pamięci RAM, aby zapewnić odpowiednią wydajność. Jeśli dane usługi rosną wraz z upływem czasu, możesz dodać więcej maszyn wirtualnych do klastra i podzielić dane na wszystkie maszyny wirtualne.
Określanie liczby potrzebnych węzłów
Partycjonowanie usługi umożliwia skalowanie danych usługi w poziomie. Aby uzyskać więcej informacji na temat partycjonowania, zobacz Partitioning Service Fabric (Partycjonowanie usługi Service Fabric). Każda partycja musi mieścić się w jednej maszynie wirtualnej, ale na jednej maszynie wirtualnej można umieścić wiele (małych) partycji. Dlatego posiadanie większej liczby małych partycji zapewnia większą elastyczność niż posiadanie kilku większych partycji. Kompromis polega na tym, że posiadanie dużej liczby partycji zwiększa obciążenie usługi Service Fabric i nie można wykonywać operacji transakcyjnych między partycjami. Istnieje również większy potencjalny ruch sieciowy, jeśli kod usługi często musi uzyskiwać dostęp do fragmentów danych, które znajdują się w różnych partycjach. Podczas projektowania usługi należy dokładnie rozważyć te zalety i wady, aby uzyskać efektywną strategię partycjonowania.
Załóżmy, że aplikacja ma jedną usługę stanową, która ma rozmiar sklepu, który ma wzrosnąć do DB_Size GB w ciągu roku. Chcesz dodać więcej aplikacji (i partycji) w miarę wzrostu w tym roku. Współczynnik replikacji (RF), który określa liczbę replik usługi, ma wpływ na łączną DB_Size. Łączna DB_Size we wszystkich replikach to współczynnik replikacji pomnożony przez DB_Size. Node_Size reprezentuje miejsce na dysku/pamięć RAM na węzeł, którego chcesz użyć dla usługi. Aby uzyskać najlepszą wydajność, DB_Size powinna mieścić się w pamięci w klastrze, a należy wybrać Node_Size wokół pamięci RAM maszyny wirtualnej. Przydzielając Node_Size, która jest większa niż pojemność pamięci RAM, polegasz na stronicowaniu udostępnianym przez środowisko uruchomieniowe usługi Service Fabric. W związku z tym wydajność może nie być optymalna, jeśli całe dane są uważane za gorące (od tego czasu dane są stronicowane w/wy). Jednak w przypadku wielu usług, w których tylko część danych jest gorąca, jest bardziej opłacalna.
Liczbę węzłów wymaganych do maksymalnej wydajności można obliczyć w następujący sposób:
Number of Nodes = (DB_Size * RF)/Node_Size
Uwzględnianie wzrostu
Możesz chcieć obliczyć liczbę węzłów na podstawie DB_Size, do której oczekujesz, że usługa wzrośnie, oprócz DB_Size, od którego rozpoczęto. Następnie zwiększ liczbę węzłów w miarę zwiększania się usługi, aby nie aprowizować zbyt wielu węzłów. Jednak liczba partycji powinna być oparta na liczbie węzłów, które są potrzebne podczas uruchamiania usługi przy maksymalnym wzroście.
Warto mieć w dowolnym momencie dostępne dodatkowe maszyny, dzięki czemu można obsłużyć wszelkie nieoczekiwane skoki lub awarie (na przykład w przypadku awarii kilku maszyn wirtualnych). Chociaż dodatkowa pojemność powinna być określana przy użyciu oczekiwanych skoków, punktem wyjścia jest rezerwować kilka dodatkowych maszyn wirtualnych (dodatkowe 5–10 procent).
Powyższe założenie obejmuje pojedynczą usługę stanową. Jeśli masz więcej niż jedną usługę stanową, musisz dodać DB_Size skojarzone z innymi usługami do równania. Alternatywnie można obliczyć liczbę węzłów oddzielnie dla każdej usługi stanowej. Usługa może mieć repliki lub partycje, które nie są zrównoważone. Należy pamiętać, że partycje mogą również mieć więcej danych niż inne. Aby uzyskać więcej informacji na temat partycjonowania, zobacz artykuł dotyczący partycjonowania na temat najlepszych rozwiązań. Jednak powyższe równanie jest niezależne od partycji i repliki, ponieważ usługa Service Fabric zapewnia rozmieszczenie replik między węzłami w zoptymalizowany sposób.
Używanie arkusza kalkulacyjnego do obliczania kosztów
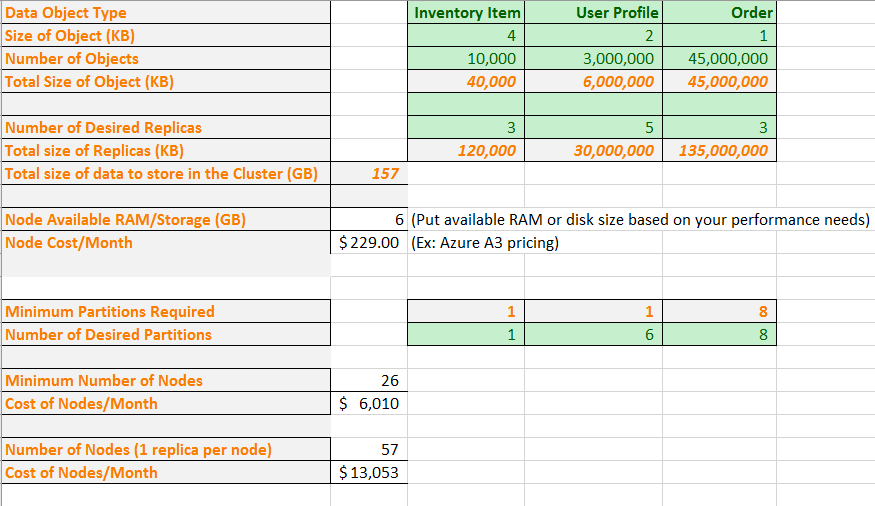
Teraz w formule umieśćmy kilka rzeczywistych liczb. Przykładowy arkusz kalkulacyjny przedstawia sposób planowania pojemności aplikacji zawierającej trzy typy obiektów danych. Dla każdego obiektu przybliżamy jego rozmiar i liczbę obiektów, których oczekujemy. Wybieramy również liczbę replik każdego typu obiektu. Arkusz kalkulacyjny oblicza całkowitą ilość pamięci, która ma być przechowywana w klastrze.
Następnie wprowadzamy rozmiar maszyny wirtualnej i miesięczny koszt. Na podstawie rozmiaru maszyny wirtualnej arkusz kalkulacyjny informuje o minimalnej liczbie partycji, których należy użyć do podzielenia danych w celu fizycznego dopasowania ich do węzłów. Możesz potrzebować większej liczby partycji, aby zaspokoić potrzeby aplikacji w zakresie określonych obliczeń i ruchu sieciowego. Arkusz kalkulacyjny pokazuje liczbę partycji, które zarządzają obiektami profilu użytkownika, wzrosła z jednego do sześciu.
Teraz, na podstawie wszystkich tych informacji, arkusz kalkulacyjny pokazuje, że można fizycznie pobrać wszystkie dane z żądanymi partycjami i replikami w klastrze 26 węzłów. Jednak ten klaster będzie gęsto zapakowany, więc może być konieczne, aby niektóre dodatkowe węzły uwzględniały awarie i uaktualnienia węzłów. Arkusz kalkulacyjny pokazuje również, że posiadanie więcej niż 57 węzłów nie zapewnia dodatkowej wartości, ponieważ masz puste węzły. Ponownie możesz mimo to chcieć przejść powyżej 57 węzłów, aby uwzględnić awarie i uaktualnienia węzłów. Możesz dostosować arkusz kalkulacyjny, aby dopasować go do konkretnych potrzeb aplikacji.
Następne kroki
Zapoznaj się z tematem Partitioning Service Fabric services (Partycjonowanie usług Service Fabric ), aby dowiedzieć się więcej o partycjonowaniu usługi.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla