Wykrywanie anomalii w usłudze Azure Stream Analytics
Usługa Azure Stream Analytics dostępna zarówno w chmurze, jak i w usłudze Azure IoT Edge oferuje wbudowane funkcje wykrywania anomalii oparte na uczeniu maszynowym, które mogą służyć do monitorowania dwóch najczęściej występujących anomalii: tymczasowych i trwałych. Dzięki funkcjom AnomalyDetection_SpikeAndDip i AnomalyDetection_ChangePoint można wykonywać wykrywanie anomalii bezpośrednio w zadaniu usługi Stream Analytics.
Modele uczenia maszynowego zakładają równomiernie próbkowany szereg czasowy. Jeśli szereg czasowy nie jest jednolity, możesz wstawić krok agregacji z oknem wirowania przed wywołaniem wykrywania anomalii.
Obecnie operacje uczenia maszynowego nie obsługują trendów sezonowości ani korelacji wielowariancji.
Wykrywanie anomalii przy użyciu uczenia maszynowego w usłudze Azure Stream Analytics
W poniższym wideo pokazano, jak wykryć anomalię w czasie rzeczywistym przy użyciu funkcji uczenia maszynowego w usłudze Azure Stream Analytics.
Zachowanie modelu
Ogólnie rzecz biorąc, dokładność modelu poprawia się przy użyciu większej ilości danych w oknie przesuwnym. Dane w określonym oknie przewijania są traktowane jako część normalnego zakresu wartości dla tego przedziału czasu. Model uwzględnia tylko historię zdarzeń w oknie przewijania, aby sprawdzić, czy bieżące zdarzenie jest nietypowe. W miarę przesuwania okna stare wartości są eksmitowane z trenowania modelu.
Funkcje działają, ustanawiając pewną normalność na podstawie tego, co widzieli do tej pory. Wartości odstające są identyfikowane przez porównanie z ustalonym normalnym poziomem ufności. Rozmiar okna powinien być oparty na minimalnych zdarzeniach wymaganych do wytrenowania modelu pod kątem normalnego zachowania, aby w przypadku wystąpienia anomalii można było go rozpoznać.
Czas odpowiedzi modelu wzrasta wraz z rozmiarem historii, ponieważ musi być porównywany z większą liczbą przeszłych zdarzeń. Zalecamy uwzględnienie tylko niezbędnej liczby zdarzeń w celu uzyskania lepszej wydajności.
Luki w szeregach czasowych mogą być wynikiem braku odbierania zdarzeń przez model w określonych punktach w czasie. Ta sytuacja jest obsługiwana przez usługę Stream Analytics przy użyciu logiki imputacji. Rozmiar historii, a także czas trwania, dla tego samego okna przesuwanego jest używany do obliczania średniej szybkości, z jaką zdarzenia mają pochodzić.
Generator anomalii dostępny tutaj może służyć do podawania centrum IoT Hub przy użyciu danych z różnymi wzorcami anomalii. Zadanie usługi Azure Stream Analytics można skonfigurować za pomocą tych funkcji wykrywania anomalii w celu odczytu z tego centrum IoT Hub i wykrywania anomalii.
Skok i spadek
Tymczasowe anomalie w strumieniu zdarzeń szeregów czasowych są nazywane skokami i spadkami. Skoki i spadki można monitorować przy użyciu operatora Edukacja opartego na maszynie, AnomalyDetection_SpikeAndDip.
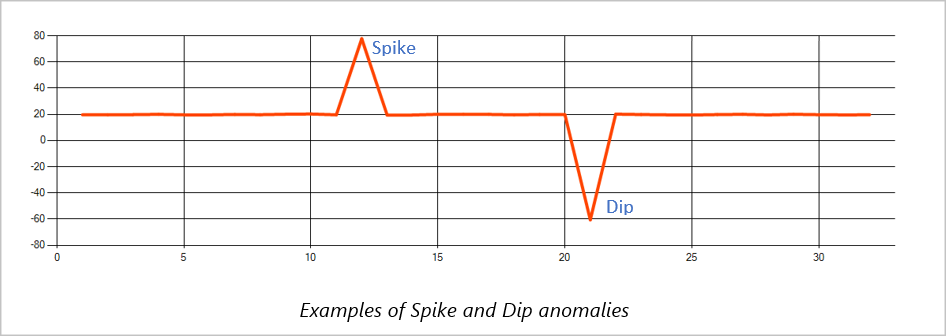
W tym samym oknie przesuwnym, jeśli drugi skok jest mniejszy niż pierwszy, obliczony wynik dla mniejszego skoku prawdopodobnie nie jest wystarczająco znaczący w porównaniu do wyniku pierwszego skoku w określonym poziomie ufności. Możesz spróbować zmniejszyć poziom ufności modelu, aby wykryć takie anomalie. Jeśli jednak zaczniesz otrzymywać zbyt wiele alertów, możesz użyć większego interwału ufności.
Poniższe przykładowe zapytanie zakłada jednolitą szybkość wprowadzania jednego zdarzenia na sekundę w 2-minutowym oknie przewijania z historią 120 zdarzeń. Końcowa instrukcja SELECT wyodrębnia i generuje wynik oraz stan anomalii z poziomem ufności 95%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
Punkt zmiany
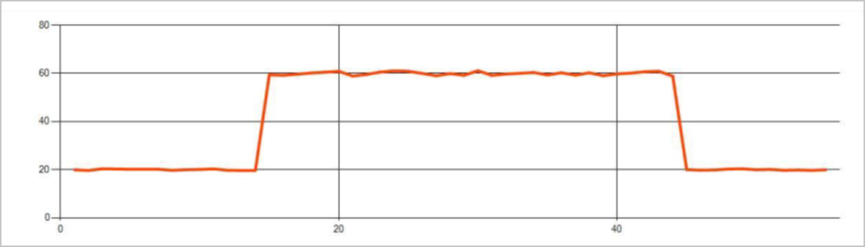
Trwałe anomalie w strumieniu zdarzeń szeregów czasowych to zmiany w dystrybucji wartości w strumieniu zdarzeń, takie jak zmiany na poziomie i trendy. W usłudze Stream Analytics takie anomalie są wykrywane przy użyciu operatora AnomalyDetection_ChangePoint opartego na maszynie Edukacja.
Trwałe zmiany trwają znacznie dłużej niż skoki i spadki i mogą wskazywać na katastrofalne zdarzenia. Trwałe zmiany nie są zwykle widoczne dla nagiego oka, ale można je wykryć za pomocą operatora AnomalyDetection_ChangePoint .
Na poniższej ilustracji przedstawiono przykład zmiany poziomu:
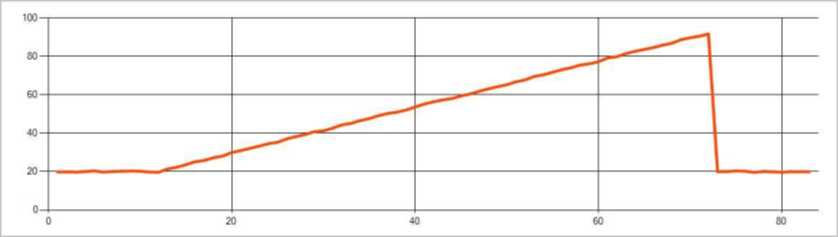
Na poniższej ilustracji przedstawiono przykład zmiany trendu:
Poniższe przykładowe zapytanie zakłada jednolitą szybkość wprowadzania jednego zdarzenia na sekundę w 20-minutowym oknie przewijania z rozmiarem historii wynoszącym 1200 zdarzeń. Końcowa instrukcja SELECT wyodrębnia i generuje wynik oraz stan anomalii z poziomem ufności 80%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
Charakterystyka wydajności
Wydajność tych modeli zależy od rozmiaru historii, czasu trwania okna, obciążenia zdarzeń i tego, czy jest używane partycjonowanie na poziomie funkcji. W tej sekcji omówiono te konfiguracje i przedstawiono przykłady dotyczące utrzymania współczynników pozyskiwania 1 K, 5 K i 10 000 zdarzeń na sekundę.
- Rozmiar historii — te modele działają liniowo z rozmiarem historii. Tym dłuższy rozmiar historii, tym dłużej modele będą oceniać nowe zdarzenie. Wynika to z faktu, że modele porównują nowe zdarzenie z każdym z poprzednich zdarzeń w buforze historii.
- Czas trwania okna — czas trwania okna powinien odzwierciedlać czas odbierania jak największej liczby zdarzeń określonych przez rozmiar historii. Bez tych wielu zdarzeń w oknie usługa Azure Stream Analytics będzie imputować brakujące wartości. W związku z tym użycie procesora CPU jest funkcją rozmiaru historii.
- Ładowanie zdarzeń — im większe obciążenie zdarzeń, tym większa praca wykonywana przez modele, co ma wpływ na użycie procesora CPU. Zadanie można skalować w poziomie, co sprawia, że jest to żenujące równolegle, zakładając, że logika biznesowa ma sens, aby używać większej liczby partycji wejściowych.
- Partycjonowanie na poziomie funkcji partycjonowanie - na poziomie funkcji odbywa się przy użyciu
PARTITION BYwywołania funkcji wykrywania anomalii. Ten typ partycjonowania dodaje obciążenie, ponieważ stan musi być utrzymywany dla wielu modeli w tym samym czasie. Partycjonowanie na poziomie funkcji jest używane w scenariuszach, takich jak partycjonowanie na poziomie urządzenia.
Relacja
Rozmiar historii, czas trwania okna i łączne obciążenie zdarzeniami są powiązane w następujący sposób:
windowDuration (w ms) = 1000 * historySize / (łączna liczba zdarzeń wejściowych na sekundę / Liczba partycji wejściowych)
Podczas partycjonowania funkcji według identyfikatora deviceId dodaj element "PARTITION BY deviceId" do wywołania funkcji wykrywania anomalii.
Obserwacje
Poniższa tabela zawiera obserwacje przepływności dla jednego węzła (sześć jednostek SU) dla przypadku niepartycyjnego:
| Rozmiar historii (zdarzenia) | Czas trwania okna (ms) | Łączna liczba zdarzeń wejściowych na sekundę |
|---|---|---|
| 60 | 55 | 2200 |
| 600 | 728 | 1,650 |
| 6000 | 10,910 | 1,100 |
W poniższej tabeli przedstawiono obserwacje przepływności dla jednego węzła (sześć jednostek przesyłania danych) dla przypadku partycjonowanego:
| Rozmiar historii (zdarzenia) | Czas trwania okna (ms) | Łączna liczba zdarzeń wejściowych na sekundę | Liczba urządzeń |
|---|---|---|---|
| 60 | 1,091 | 1,100 | 10 |
| 600 | 10,910 | 1,100 | 10 |
| 6000 | 218,182 | <550 | 10 |
| 60 | 21,819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6000 | 2,181,819 | <550 | 100 |
Przykładowy kod do uruchamiania niepartycjonowanych konfiguracji znajduje się w repozytorium Streaming At Scale przykładów platformy Azure. Kod tworzy zadanie analizy strumienia bez partycjonowania na poziomie funkcji, które używa usługi Event Hubs jako danych wejściowych i wyjściowych. Obciążenie wejściowe jest generowane przy użyciu klientów testowych. Każde zdarzenie wejściowe jest dokumentem json o rozmiarze 1 KB. Zdarzenia symulują urządzenie IoT wysyłające dane JSON (do 1 K urządzeń). Rozmiar historii, czas trwania okna i łączne obciążenie zdarzeń różnią się w zależności od dwóch partycji wejściowych.
Uwaga
Aby uzyskać dokładniejsze oszacowanie, dostosuj przykłady, aby pasowały do danego scenariusza.
Identyfikowanie wąskich gardeł
Aby zidentyfikować wąskie gardła w potoku, użyj okienka Metryki w zadaniu usługi Azure Stream Analytics. Przejrzyj zdarzenia wejściowe/wyjściowe pod kątem przepływności i "Opóźnienie znaku wodnego" lub Zdarzenia z zaległymi, aby sprawdzić, czy zadanie utrzymuje szybkość wprowadzania. W przypadku metryk usługi Event Hubs poszukaj żądań ograniczonych i odpowiednio dostosuj jednostki progowe. W przypadku metryk usługi Azure Cosmos DB zapoznaj się z artykułem Maksymalna liczba jednostek RU/s na zakres kluczy partycji w obszarze Przepływność, aby upewnić się, że zakresy kluczy partycji są równomiernie używane. W przypadku usługi Azure SQL DB monitoruj we/ wy dzienników i procesor CPU.
Wideo z pokazem
Następne kroki
- Wprowadzenie do usługi Azure Stream Analytics
- Get started using Azure Stream Analytics (Rozpoczynanie pracy z usługą Azure Stream Analytics)
- Scale Azure Stream Analytics jobs (Skalowanie zadań usługi Azure Stream Analytics)
- Azure Stream Analytics Query Language Reference (Dokumentacja dotycząca języka zapytań usługi Azure Stream Analytics)
- Azure Stream Analytics Management REST API Reference (Dokumentacja interfejsu API REST zarządzania usługą Azure Stream Analytics)
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla