Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Wbudowany model rozpoznawania tekstu w AI Builder wyodrębnia tekst drukowany i odręczny z obrazów i dokumentów. Korzystając z tego modelu w Power Automate, można tworzyć procesy automatycznie przetwarzające tekst ze skanów dokumentów, zdjęć i plików PDF, co pozwala na wydajną obsługę danych i integrację z innymi aplikacjami.
Ten dokument zawiera instrukcje dotyczące korzystania z gotowego modelu rozpoznawania tekstu w Power Automate.
Zainicjuj przepływ chmury Power Automate
Inicjalizacja przepływu chmury Power Automate to pierwszy krok w konfiguracji zautomatyzowanego procesu. Ten krok umożliwia zdefiniowanie wyzwalacza i początkowych parametrów wejściowych przepływu w chmurze. Podczas inicjowania można upewnić się, że przepływ w chmurze jest uruchamiany poprawnie i zawiera informacje niezbędne do wydajnego przetwarzania zadań rozpoznawania tekstu.
Aby zainicjować przepływ w chmurze, wykonaj następujące czynności:
Zaloguj się do usługi Power Automate.
Wybierz w lewym oknie pozycję Moje przepływy, a następnie wybierz nowy przepływ>Natychmiastowy przepływ w chmurze, wpaneu nawigacyjnym.
Nazwij przepływ w chmurze, kliknij opcję Wyzwól przepływ ręcznie w sekcji Wybierz sposób wyzwalania tego przepływu, a następnie kliknij przycisk Utwórz.
Rozwiń okienko Wyzwól przepływ ręcznie, kliknij opcję +Dodaj dane wejściowe>Plik jako typ danych wejściowych.
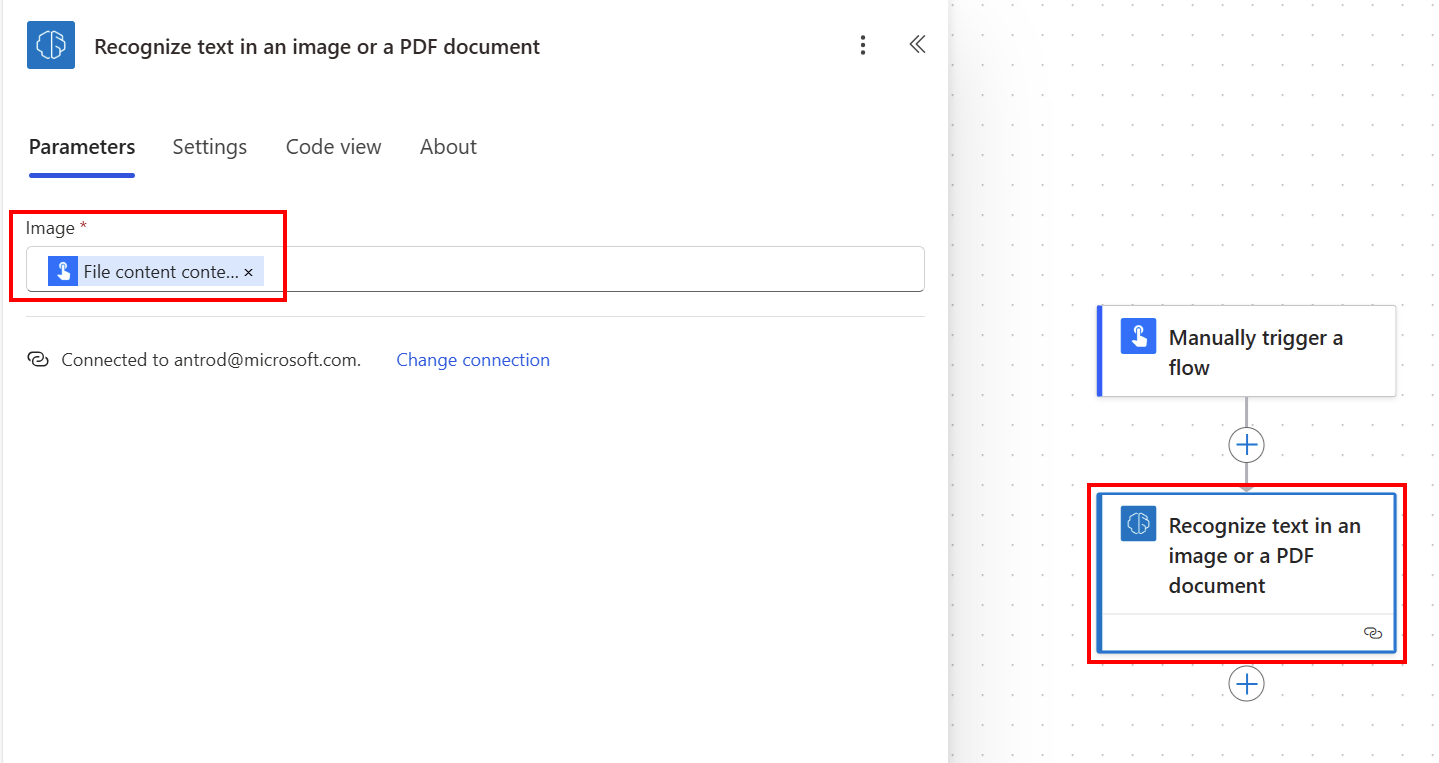
Wybierz opcję +Nowy krok>AI Builder, a następnie na liście akcji wybierz pozycję Rozpoznaj tekst na obrazie lub dokumencie PDF.
Wybierz dane wejściowe typu Obraz, a następnie z listy Zawartości dynamicznej wybierz pozycję Zawartość pliku:
Aby przetworzyć wyniki, można użyć pełnego tekstu dokumentu, tekstu strony lub tekstu dokumentu wiersz po wierszu.
Pobierz pełny tekst dokumentu lub pełny tekst strony
Jeśli musisz wykonać operację na całym tekście dokumentu lub na określonym tekście strony, ta opcja jest przydatna. Przykładem użycia tekstu strony jest wyszukanie podciągu lub przekazanie go do akcji podrzędnej.
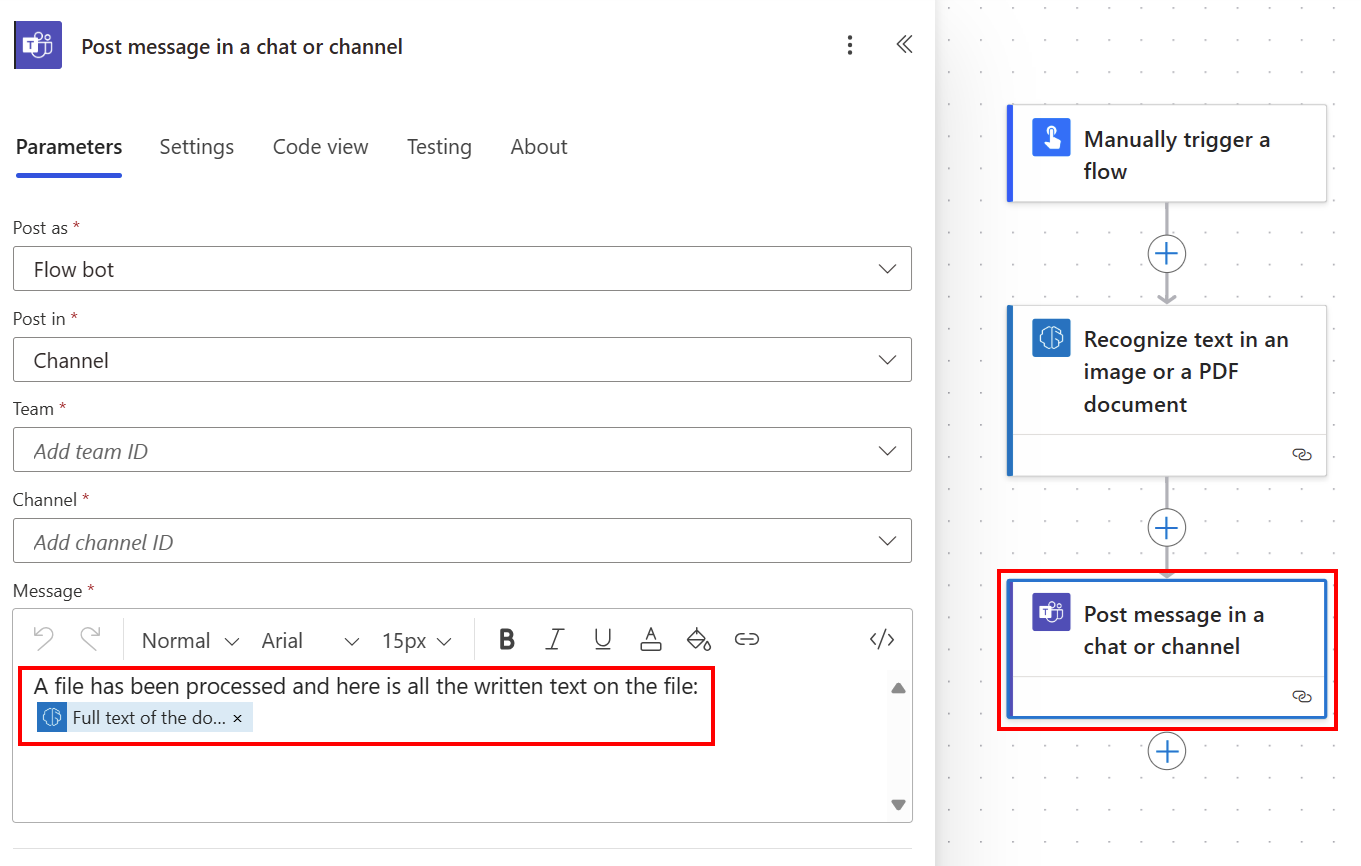
Cały wyodrębniony tekst można opublikować w kanale Teams, korzystając z opcji Pełny tekst dokumentu z listy Treść dynamiczna.
Pobierz tekst dokumentu wiersz po wierszu
Pobieranie tekstu dokumentu wiersz po wierszu może być przydatne, jeśli chcesz wyizolować określony wiersz tekstu lub sformatować tekst w dogodnym dla siebie czasie.
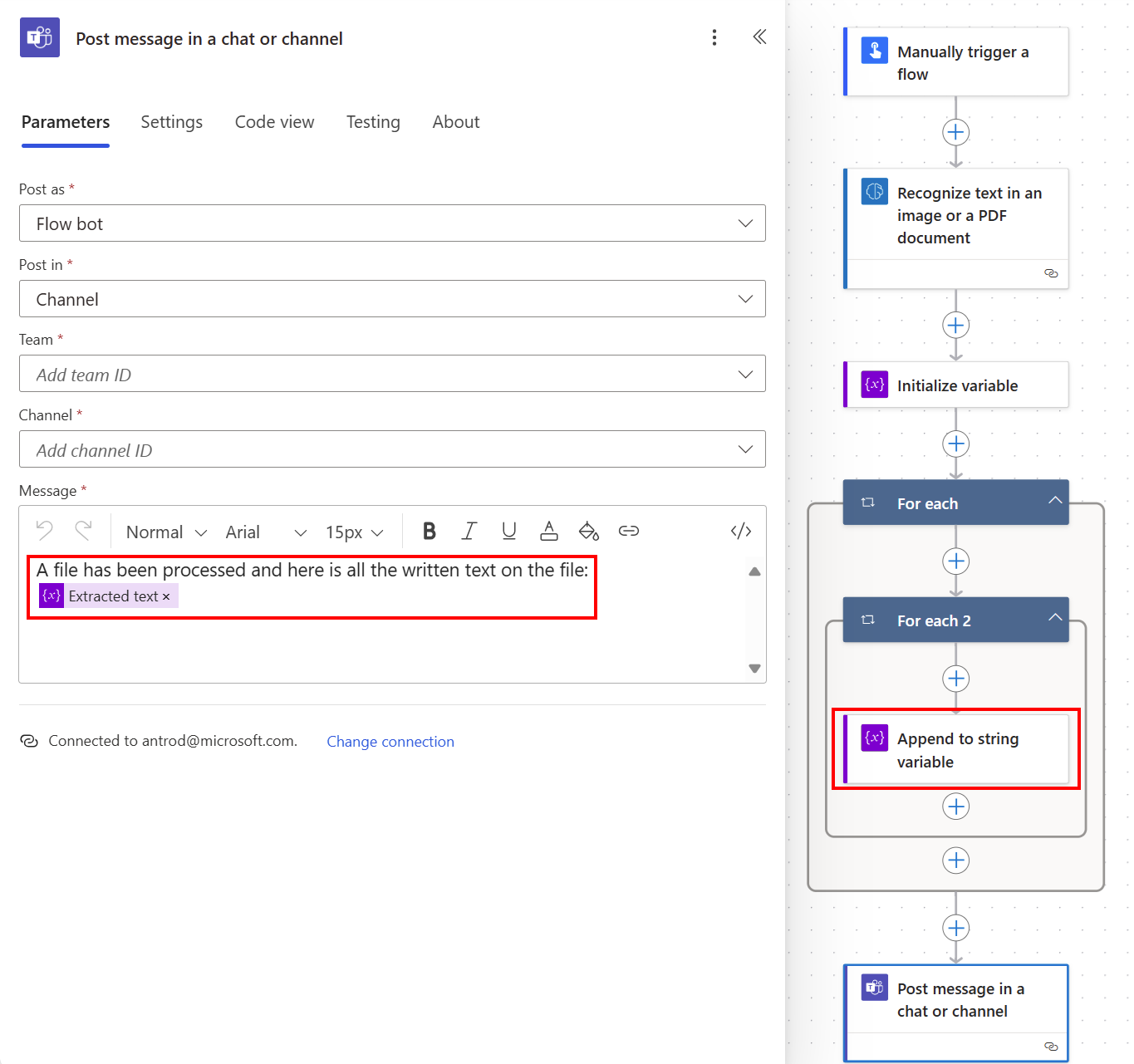
Aby utworzyć zmienną ciągu, wybierz +Nowy krok>Kontrolka, a następnie wybierz pozycję Zainicjuj zmienną.
Na przykład, nazwij ją Wyodrębniony tekst.
Wybierz +Nowy krok>Kontrolka, a następnie wybierz pozycję Dodaj do zmiennej ciągu.
W polu wartość wybierz tekst z listy Dynamiczna treść.
Automatycznie generuje dwie akcje Zastosuj do każdej ponieważ odczytuje listę linii tekstu na liście stron. Następnie możesz wpisać cały wyodrębniony tekst w kanale Teams.
Gratulacje! Udało Ci się utworzyć przepływ w chmurze korzystający z modelu rozpoznawania tekstu. Możesz nadal rozbudowywać ten przepływ w chmurze, aby dostosować go do swoich potrzeb. Wybierz pozycję Zapisz w prawym górnym rogu, a następnie wybierz pozycję Test, aby wypróbować przepływ w chmurze.
Parametry
Wstępnie zbudowany model rozpoznawania tekstu w AI Builder zawiera następujące parametry wejściowe i wyjściowe.
Dane wejściowe
| Nazwa/nazwisko | Wymagania | Type | Podpis |
|---|---|---|---|
| Obraz | Tak | file | Obraz do przeanalizowania |
Dane wyjściowe
Wykryty tekst jest osadzony w wierszach pod listą wyników. Najpierw musisz wybrać kolumnę wiersze z akcji Zastosuj do każdego, aby wyświetlić wszystkie następujące kolumny.
| Nazwa/nazwisko | Pisz | Opis |
|---|---|---|
| Tekst | ciąg | Ciągi zawierające wykryty wiersz tekstu |
| Numer strony | string | Numer strony wykrytego tekstu |
| Współrzędne | liczba zmiennoprzecinkowa | Koordynaty strony wykrytego tekstu |
| Pełny tekst dokumentu | string | Wykryto pełny tekst |
| Pełny tekst strony | string | Wykryto tekst na całej stronie |