Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy: SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
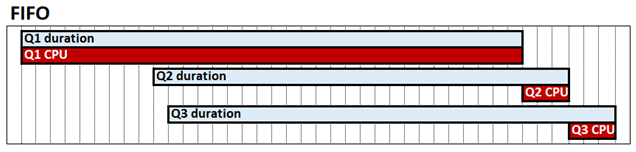
Przeplatanie zapytań to konfiguracja systemu w trybie tabelarycznym, która może poprawić wydajność zapytań w scenariuszach o wysokiej współbieżności. Domyślnie aparat tabelaryczny usług Analysis Services działa na zasadzie pierwsze weszło, pierwsze wyszło (FIFO) w odniesieniu do procesora. Na przykład w przypadku FIFO, jeśli kosztowne i prawdopodobnie wolne zapytanie do silnika magazynującego jest otrzymywane, a następnie dwa inne szybkie zapytania, szybkie zapytania mogą potencjalnie zostać zablokowane, czekając na zakończenie kosztownego zapytania. To zachowanie pokazano na poniższym diagramie, który przedstawia Q1, Q2 i Q3 jako odpowiednie zapytania, ich czas trwania i czas procesora CPU.
Przeplatanie zapytań z preferencją dla krótkich zapytań umożliwia współdzielenie zasobów CPU przez współbieżne zapytania, co oznacza, że szybkie zapytania nie są blokowane za powolnymi zapytaniami. Czas potrzebny na ukończenie wszystkich trzech zapytań jest nadal taki sam, ale w naszym przykładzie Q2 i Q3 nie są blokowane do końca. Preferencja dla krótkich zapytań oznacza, że szybkie zapytania, zdefiniowane przez czas procesora CPU zużyty już przez każde zapytanie w danym momencie, mogą otrzymać większy przydział zasobów niż zapytania długotrwałe. Na poniższym diagramie zapytania Q2 i Q3 są uznawane za szybkie i przydziela się im więcej mocy obliczeniowej CPU niż Q1.
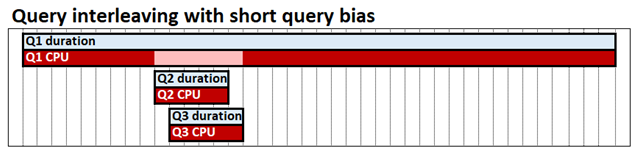
Przeplatanie zapytań ma mieć niewielki lub żaden wpływ na wydajność zapytań uruchamianych w izolacji; pojedyncze zapytanie może nadal zużywać tyle samo procesora CPU, co w przypadku modelu FIFO.
Ważne uwagi
Przed ustaleniem, czy przeplatanie zapytań jest odpowiednie dla danego scenariusza, należy pamiętać o następujących kwestiach:
- Przeplatanie zapytań dotyczy tylko modeli importu. Nie ma to wpływu na modele DirectQuery.
- Przeplatanie zapytań uwzględnia tylko zużycie CPU przez zapytania aparatu magazynowania VertiPaq. Nie ma zastosowania do operacji silnika formuł.
- Pojedyncze zapytanie języka DAX może spowodować wiele zapytań silnika magazynującego VertiPaq. Zapytanie języka DAX jest uznawane za szybkie lub powolne na podstawie zużycia procesora przez zapytania silnika magazynującego. Zapytanie języka DAX jest jednostką miary.
- Operacje odświeżania są domyślnie chronione przed przeplataniem zapytań. Długotrwałe operacje odświeżania są kategoryzowane inaczej niż długotrwałe zapytania.
Konfiguruj
Aby skonfigurować przeplatanie zapytań, ustaw właściwość Threadpool\SchedulingBehavior . Tę właściwość można określić przy użyciu następujących wartości:
| Wartość | Description |
|---|---|
| -1 | Automatyczny. Silnik wybierze typ kolejki. |
| 0 (ustawienie domyślne dla usług SSAS 2019) | Pierwsze weszło, pierwsze wyszło (FIFO). |
| 1 | Stronniczość krótkich kwerend. Silnik stopniowo ogranicza długotrwałe zapytania pod obciążeniem na rzecz szybkich zapytań. |
| 3 (ustawienie domyślne dla usług Azure AS, Power BI, SSAS 2022 i nowszych) | Krótka kwerenda z tendencją do szybkiego anulowania. Poprawia czas odpowiedzi na zapytania użytkownika w scenariuszach o wysokiej współbieżności. Dotyczy tylko usług Azure AS, Power BI, SSAS 2022 i nowszych. |
W tej chwili właściwość SchedulingBehavior można ustawić tylko przy użyciu xmlA. W programie SQL Server Management Studio poniższy fragment kodu XMLA ustawia właściwość SchedulingBehavior na 1, krótką stronniczość zapytań.
<Alter AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object />
<ObjectDefinition>
<Server xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="http://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="http://schemas.microsoft.com/analysisservices/2012/engine/400/400" xmlns:ddl500="http://schemas.microsoft.com/analysisservices/2013/engine/500" xmlns:ddl500_500="http://schemas.microsoft.com/analysisservices/2013/engine/500/500">
<ID>myserver</ID>
<Name>myserver</Name>
<ServerProperties>
<ServerProperty>
<Name>ThreadPool\SchedulingBehavior</Name>
<Value>1</Value>
</ServerProperty>
</ServerProperties>
</Server>
</ObjectDefinition>
</Alter>
Ważne
Wymagane jest ponowne uruchomienie wystąpienia serwera. W usługach Azure Analysis Services należy wstrzymać, a następnie wznowić działanie serwera, co spowoduje skuteczne ponowne uruchomienie.
Dodatkowe właściwości
W większości przypadków funkcja SchedulingBehavior jest jedyną właściwością, którą należy ustawić. Poniższe dodatkowe właściwości mają domyślne wartości, które powinny działać w większości scenariuszy z tendencją do krótkich zapytań, jednak można je zmienić w razie potrzeby. Następujące właściwości nie mają wpływu , chyba że przeplatanie zapytań jest włączone przez ustawienie właściwości SchedulingBehavior.
ReservedComputeForFastQueries — określa liczbę zarezerwowanych rdzeni logicznych na potrzeby szybkich zapytań. Wszystkie zapytania są uznawane za szybkie do momentu, gdy osłabną, gdyż wykorzystały pewną ilość procesora CPU. ReservedComputeForFastQueries jest liczbą całkowitą z zakresu od 0 do 100. Wartość domyślna to 75.
Jednostka miary dla ReservedComputeForFastQueries jest procentem rdzeni. Na przykład wartość 80 na serwerze z 20 rdzeniami próbuje zarezerwować 16 rdzeni na potrzeby szybkich zapytań (podczas gdy nie są wykonywane żadne operacje odświeżania). ReservedComputeForFastQueries zaokrągla do najbliższej całkowitej liczby rdzeni. Zaleca się, aby nie ustawiać tej wartości właściwości poniżej 50. Wynika to z faktu, że szybkie zapytania mogą być ograniczone, co jest sprzeczne z ogólnym projektem funkcji.
DecayIntervalCPUTime — liczba całkowita reprezentująca czas procesora CPU w milisekundach, który zapytanie spędza, zanim ulegnie rozkładowi. Jeśli system jest pod obciążeniem procesora, degradowane zapytania są ograniczone do pozostałych rdzeni, które nie są zarezerwowane dla szybkich zapytań. Wartość domyślna to 60 000. Reprezentuje to 1 minutę czasu CPU, a nie upłynięty czas kalendarzowy.
ReservedComputeForProcessing — określa liczbę zarezerwowanych rdzeni logicznych dla każdej operacji przetwarzania (odświeżanie danych). Wartość właściwości jest liczbą całkowitą z zakresu od 0 do 100, z wartością domyślną 75 wyrażoną. Wartość reprezentuje procent rdzeni określonych przez właściwość ReservedComputeForFastQueries. Wartość 0 (zero) oznacza, że operacje przetwarzania podlegają tej samej logice przeplatania co zapytania, więc mogą się opóźniać.
Chociaż nie są wykonywane żadne operacje przetwarzania, ReservedComputeForProcessing nie ma wpływu. Na przykład z wartością 80 ReservedComputeForFastQueries na serwerze z 20 rdzeniami rezerwuje 16 rdzeni na potrzeby szybkich zapytań. Przy wartości 75, ReservedComputeForProcessing zarezerwuje 12 z 16 rdzeni na operacje odświeżania, pozostawiając 4 na potrzeby szybkich zapytań, podczas gdy operacje przetwarzania są uruchomione i zużywają przy tym CPU. Zgodnie z opisem w poniższej sekcji Usterka zapytania pozostałe 4 rdzenie (nie zarezerwowane dla szybkich zapytań lub operacji przetwarzania) będą nadal używane do szybkiego wykonywania zapytań i przetwarzania, jeśli są bezczynne.
Te dodatkowe właściwości znajdują się w węźle Właściwości zarządzania zasobami . W programie SQL Server Management Studio poniższy przykładowy fragment kodu XMLA ustawia właściwość DecayIntervalCPUTime na wartość niższą niż domyślna:
<Alter AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object />
<ObjectDefinition>
<Server xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="http://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="http://schemas.microsoft.com/analysisservices/2012/engine/400/400" xmlns:ddl500="http://schemas.microsoft.com/analysisservices/2013/engine/500" xmlns:ddl500_500="http://schemas.microsoft.com/analysisservices/2013/engine/500/500">
<ID>myserver</ID>
<Name>myserver</Name>
<ServerProperties>
<ServerProperty>
<Name>ResourceGovernance\DecayIntervalCPUTime</Name>
<Value>15000</Value>
</ServerProperty>
</ServerProperties>
</Server>
</ObjectDefinition>
</Alter>
Zepsute zapytania
Ograniczenia opisane w tej sekcji mają zastosowanie tylko wtedy, gdy system jest pod ciśnieniem procesora CPU. Na przykład jedno zapytanie, jeśli jest jedynym uruchomionym w systemie w danym momencie, może korzystać ze wszystkich dostępnych rdzeni niezależnie od tego, czy zmniejszyło swoją wydajność, czy nie.
Każde zapytanie może wymagać wielu zadań silnika magazynowania. Gdy rdzeń w puli dla rozpadających się zapytań stanie się dostępny, harmonogram sprawdzi najstarsze uruchomione zapytanie na podstawie czasu kalendarzowego, aby sprawdzić, czy używa już maksymalnego uprawnienia rdzenia (MCE). Jeśli nie, zostanie wykonane następne zadanie. Jeśli tak, zostanie ocenione następne najstarsze zapytanie. Zapytanie MCE jest określane przez liczbę interwałów rozpadu, które zostały już użyte. W przypadku każdego stosowanego interwału rozkładu MCE ulega zmniejszeniu na podstawie algorytmu przedstawionego w poniższej tabeli. Będzie to kontynuowane do momentu ukończenia zapytania, limitu czasu lub ograniczenia mcE do pojedynczego rdzenia.
W poniższym przykładzie system ma 32 rdzenie, a procesor CPU systemu jest pod presją.
ReservedComputeForFastQueries jest 60 (60%).
- 20 rdzeni (19,2 zaokrąglone w górę) jest zarezerwowane dla szybkich zapytań.
- Pozostałe 12 rdzeni jest przydzielone do obsługi wygasających zapytań.
DecayIntervalCPUTime to 60 000 (1 minuta czasu procesora).
Cykl życia zapytania może przebiegać następująco, o ile nie upłynie jego limit czasu ani nie zostanie zakończony.
| Etap | Status | Wykonywanie/planowanie | MCE |
|---|---|---|---|
| 0 | Szybko | McE to 20 rdzeni (zarezerwowane dla szybkich zapytań). Zapytanie jest wykonywane zgodnie z zasadą FIFO w odniesieniu do innych szybkich zapytań wśród 20 zarezerwowanych rdzeni. Użyty został interwał rozpadu wynoszący 1 minutę czasu CPU. |
20 = MIN(32/2˄0, 20) |
| 1 | Zbutwiałe | McE jest ustawiony na 12 rdzeni (12 pozostałych rdzeni nie jest zarezerwowanych dla szybkich zapytań). Zadania są wykonywane na podstawie dostępności do mcE. Używany jest interwał rozkładu wynoszący 1 minutę czasu procesora CPU. |
12 = MIN(32/2˄1, 12) |
| 2 | Zdegradowany | MCE jest ustawiona na 8 rdzeni (jedna czwarta z 32 rdzeni). Zadania są wykonywane w oparciu o dostępność do MCE. Interwał zużycia 1 minuty czasu procesora został wykorzystany. |
8 = MIN(32/2^2, 12) |
| 3 | Zdegradowane | McE jest ustawiony na 4 rdzenie. Zadania są wykonywane w oparciu o dostępność do MCE. Interwał zużycia 1 minuty czasu procesora został wykorzystany. |
4 = MIN(32/2˄3, 12) |
| 4 | Zbutwiałe | McE jest ustawiony na 2 rdzenie. Zadania są wykonywane w oparciu o dostępność do MCE. Interwał zużycia 1 minuty czasu procesora został wykorzystany. |
2 = MIN(32/2˄4, 12) |
| 5 | Zbutwiałe | McE jest ustawiony na 1 rdzeń. Zadania są wykonywane w oparciu o dostępność do MCE. Interwał rozkładu nie ma zastosowania, ponieważ zapytanie osiągnęło swoje minimum. Nie dochodzi do dalszego rozpadu, ponieważ osiągnięto minimum 1 rdzenia. |
1 = MIN(32/2^5, 12) |
Jeśli system jest pod obciążeniem CPU, każdemu zapytaniu zostanie przypisane nie więcej rdzeni niż jego MCE. Jeśli wszystkie rdzenie są obecnie używane przez zapytania w odpowiednich MCEs, inne zapytania czekają, aż rdzenie staną się dostępne. Gdy rdzenie staną się dostępne, zostanie odebrane najstarsze uprawnione zapytanie na podstawie czasu kalendarzowego, który upłynął. MCE jest limitem pod presją; nie gwarantuje, że liczba rdzeni jest gwarantowana w dowolnym momencie.