Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
LangChain to ekosystem deweloperów, który ułatwia deweloperom tworzenie aplikacji z tego powodu. Ekosystem składa się z wielu składników. Większość z nich może być używana samodzielnie, co pozwala wybrać i wybrać wybrane składniki, które chcesz najlepiej.
Modele wdrożone w narzędziu Azure AI Foundry można używać z aplikacją LangChain na dwa sposoby:
Korzystanie z interfejsu API wnioskowania modelu AI platformy Azure: Wszystkie modele wdrożone w usłudze Azure AI Foundry obsługują interfejs API wnioskowania modelu, który oferuje wspólny zestaw funkcji, których można używać w większości modeli w katalogu. Zaletą tego interfejsu API jest to, że ponieważ jest taka sama dla wszystkich modeli, zmiana z jednego na drugą jest tak prosta, jak zmiana używanego wdrożenia modelu. W kodzie nie są wymagane żadne dalsze zmiany. Podczas pracy z aplikacją LangChain zainstaluj rozszerzenia
langchain-azure-ai.Korzystanie z interfejsu API specyficznego dla dostawcy modelu: niektóre modele, takie jak OpenAI, Cohere lub Mistral, oferują własny zestaw interfejsów API i rozszerzeń dla biblioteki LangChain. Rozszerzenia te mogą zawierać określone funkcje obsługiwane przez model i dlatego są odpowiednie, jeśli chcesz je wykorzystać. Podczas pracy z aplikacją LangChain zainstaluj rozszerzenie specyficzne dla modelu, którego chcesz użyć, na przykład
langchain-openailublangchain-cohere.
Z tego samouczka dowiesz się, jak tworzyć aplikacje za pomocą pakietu langchain-azure-ai LangChain.
Wymagania wstępne
Do uruchomienia tego samouczka potrzebne są następujące elementy:
Wdrożenie modelu obsługujące interfejs API wnioskowania modelu zostało wdrożone. W tym przykładzie używamy
Mistral-Large-2411wdrożenia w modelach Foundry.Zainstalowano środowisko Python w wersji 3.9 lub nowszej, w tym narzędzie.
Zainstalowano aplikację LangChain. Można to zrobić za pomocą:
pip install langchainW tym przykładzie pracujemy z interfejsem API wnioskowania modelu, dlatego instalujemy następujące pakiety:
pip install -U langchain-azure-ai
Konfigurowanie środowiska
Aby używać usług LLM wdrożonych w portalu usługi Azure AI Foundry, potrzebny jest punkt końcowy i poświadczenia, aby nawiązać z nim połączenie. Wykonaj następujące kroki, aby uzyskać potrzebne informacje z modelu, którego chcesz użyć:
Wskazówka
Ponieważ możesz dostosować okienko po lewej stronie w portalu azure AI Foundry, możesz zobaczyć inne elementy niż pokazano w tych krokach. Jeśli nie widzisz szukanych danych, wybierz pozycję ... Więcej w dolnej części okienka po lewej stronie.
Przejdź do usługi Azure AI Foundry.
Otwórz projekt, w którym wdrożono model, jeśli nie jest jeszcze otwarty.
Przejdź do pozycji Modele i punkty końcowe i wybierz wdrożony model zgodnie z wymaganiami wstępnymi.
Skopiuj adres URL punktu końcowego i klucz.
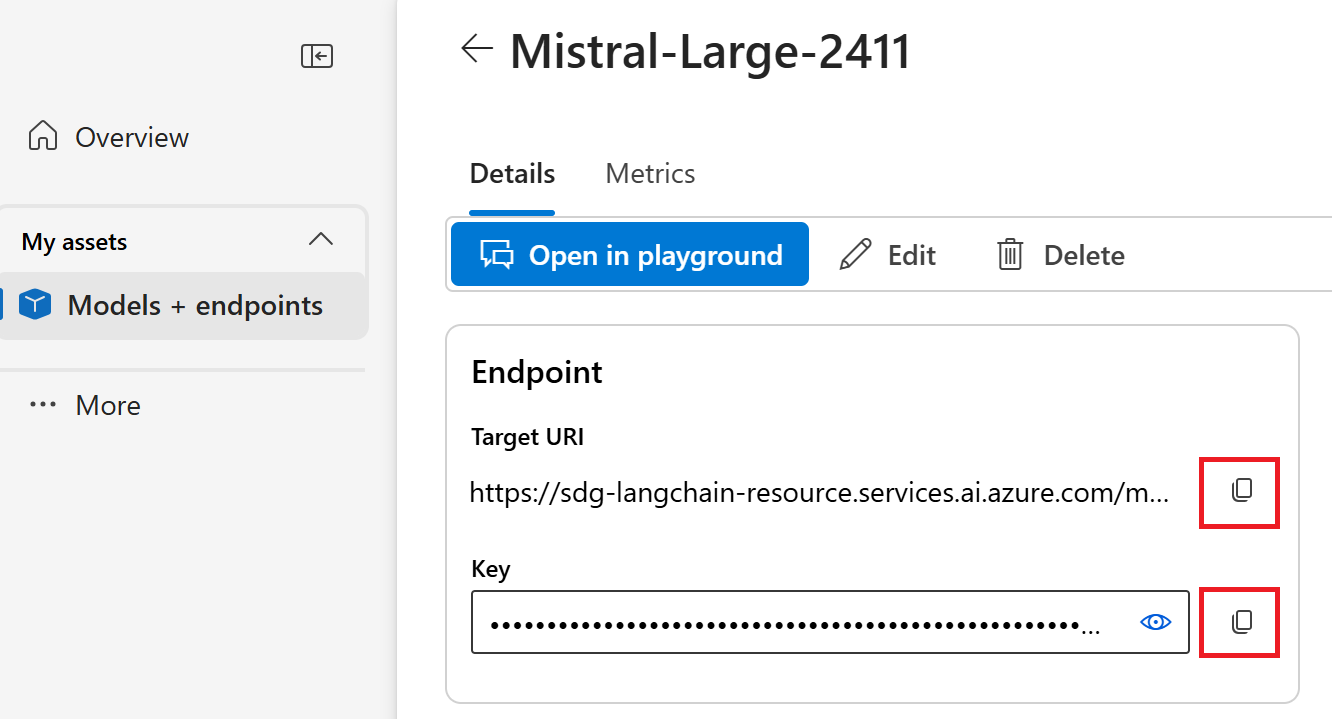
Wskazówka
Jeśli model został wdrożony przy użyciu obsługi identyfikatora Entra firmy Microsoft, nie potrzebujesz klucza.

W tym scenariuszu ustaw adres URL punktu końcowego i klucz jako zmienne środowiskowe. (Jeśli skopiowany punkt końcowy zawiera dodatkowy tekst po /models, usuń go, aby adres URL zakończył się w /models sposób pokazany poniżej).
export AZURE_INFERENCE_ENDPOINT="https://<resource>.services.ai.azure.com/models"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Po skonfigurowaniu utwórz klienta, aby nawiązać połączenie z modelem czatu przy użyciu polecenia init_chat_model. W przypadku modeli usługi Azure OpenAI skonfiguruj klienta zgodnie z sekcją Korzystanie z modeli Azure OpenAI.
from langchain.chat_models import init_chat_model
llm = init_chat_model(model="Mistral-Large-2411", model_provider="azure_ai")
Możesz również użyć klasy AzureAIChatCompletionsModel bezpośrednio.
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model="Mistral-Large-2411",
)Ostrzeżenie
Zmiana powodująca niezgodność: Parametr model_name został przemianowany na model w wersji 0.1.3.
Możesz użyć następującego kodu, aby utworzyć klienta, jeśli punkt końcowy obsługuje identyfikator Entra firmy Microsoft:
import os
from azure.identity import DefaultAzureCredential
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="Mistral-Large-2411",
)
Uwaga / Notatka
W przypadku korzystania z identyfikatora Entra firmy Microsoft upewnij się, że punkt końcowy został wdrożony przy użyciu tej metody uwierzytelniania i że masz wymagane uprawnienia do jego wywołania.
Jeśli planujesz użycie wywołania asynchronicznego, najlepszym rozwiązaniem jest użycie wersji asynchronicznej dla poświadczeń:
from azure.identity.aio import (
DefaultAzureCredential as DefaultAzureCredentialAsync,
)
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredentialAsync(),
model="Mistral-Large-2411",
)
Jeśli punkt końcowy obsługuje jeden model, podobnie jak we wdrożeniu bezserwerowego interfejsu API, nie musisz wskazywać model parametru:
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
)
Korzystanie z modeli uzupełniania czatów
Najpierw użyjemy modelu bezpośrednio.
ChatModels są wystąpieniami biblioteki LangChain Runnable, co oznacza, że uwidaczniają standardowy interfejs do interakcji z nimi. Aby wywołać model, możemy przekazać listę komunikatów do metody invoke.
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="Translate the following from English into Italian"),
HumanMessage(content="hi!"),
]
model.invoke(messages)Możesz również tworzyć operacje zgodnie z potrzebami w łańcuchach. Teraz użyjemy szablonu monitu, aby przetłumaczyć zdania:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
Jak widać w szablonie monitu, ten łańcuch zawiera language dane wejściowe i text . Teraz utwórzmy analizator danych wyjściowych:
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()Teraz możemy połączyć szablon, model i analizator danych wyjściowych z góry przy użyciu operatora potoku (|):
chain = prompt_template | model | parser
Aby wywołać łańcuch, zidentyfikuj wymagane dane wejściowe i podaj wartości przy użyciu invoke metody :
chain.invoke({"language": "italian", "text": "hi"})
Łączenie wielu modułów LLM
Modele wdrożone w usłudze Azure AI Foundry obsługują interfejs API wnioskowania modelu, który jest standardem we wszystkich modelach. Łączenie wielu operacji LLM na podstawie możliwości każdego modelu, dzięki czemu można zoptymalizować odpowiedni model na podstawie możliwości.
W poniższym przykładzie utworzymy dwóch modelowych klientów. Jeden jest producentem, a drugi jest weryfikatorem. Aby uczynić rozróżnienie jasnym, używamy punktu końcowego obsługującego wiele modeli, takiego jak Foundry Models API, i dlatego przekazujemy parametr model, aby użyć modelu Mistral-Large oraz Mistral-Small, podkreślając fakt, że tworzenie treści jest bardziej złożone niż jej weryfikowanie.
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
producer = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model="Mistral-Large-2411",
)
verifier = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model="mistral-small",
)Wskazówka
Zapoznaj się z kartą modelu każdego z modeli, aby zrozumieć najlepsze przypadki użycia dla każdego modelu.
Poniższy przykład generuje wiersz napisany przez miejskiego poetę:
from langchain_core.prompts import PromptTemplate
producer_template = PromptTemplate(
template="You are an urban poet, your job is to come up \
verses based on a given topic.\n\
Here is the topic you have been asked to generate a verse on:\n\
{topic}",
input_variables=["topic"],
)
verifier_template = PromptTemplate(
template="You are a verifier of poems, you are tasked\
to inspect the verses of poem. If they consist of violence and abusive language\
report it. Your response should be only one word either True or False.\n \
Here is the lyrics submitted to you:\n\
{input}",
input_variables=["input"],
)Teraz utwórzmy łańcuch elementów:
chain = producer_template | producer | parser | verifier_template | verifier | parserPoprzedni łańcuch zwraca tylko dane wyjściowe kroku verifier . Ponieważ chcemy uzyskać dostęp do wyniku pośredniego wygenerowanego producerprzez element , w usłudze LangChain należy użyć RunnablePassthrough obiektu, aby również wyświetlić ten krok pośredni.
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
generate_poem = producer_template | producer | parser
verify_poem = verifier_template | verifier | parser
chain = generate_poem | RunnableParallel(poem=RunnablePassthrough(), verification=RunnablePassthrough() | verify_poem)
Aby wywołać łańcuch, zidentyfikuj wymagane dane wejściowe i podaj wartości przy użyciu invoke metody :
chain.invoke({"topic": "living in a foreign country"})Korzystanie z modeli osadzania
W ten sam sposób tworzysz klienta LLM, możesz nawiązać połączenie z modelem osadzania. W poniższym przykładzie ustawiamy zmienną środowiskową tak, aby wskazywała model osadzania:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Następnie utwórz klienta:
import os
from langchain_azure_ai.embeddings import AzureAIEmbeddingsModel
embed_model = AzureAIEmbeddingsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model="text-embedding-3-large",
)Poniższy przykład przedstawia prosty przykład użycia magazynu wektorów w pamięci:
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embed_model)Dodajmy kilka dokumentów:
from langchain_core.documents import Document
document_1 = Document(id="1", page_content="foo", metadata={"baz": "bar"})
document_2 = Document(id="2", page_content="thud", metadata={"bar": "baz"})
documents = [document_1, document_2]
vector_store.add_documents(documents=documents)Wyszukajmy według podobieństwa:
results = vector_store.similarity_search(query="thud", k=1)
for doc in results:
print(f"* {doc.page_content} [{doc.metadata}]")Korzystanie z modeli usługi Azure OpenAI
Jeśli używasz modeli usługi Azure OpenAI z pakietem langchain-azure-ai , użyj następującego adresu URL:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.openai.azure.com/openai/v1",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model="gpt-4o"
)
Debugowanie i rozwiązywanie problemów
Jeśli musisz debugować aplikację i rozumieć żądania wysyłane do modeli w usłudze Azure AI Foundry, możesz użyć funkcji debugowania integracji w następujący sposób:
Najpierw skonfiguruj rejestrowanie na poziomie, który cię interesuje:
import sys
import logging
# Acquire the logger for this client library. Use 'azure' to affect both
# 'azure.core` and `azure.ai.inference' libraries.
logger = logging.getLogger("azure")
# Set the desired logging level. logging.INFO or logging.DEBUG are good options.
logger.setLevel(logging.DEBUG)
# Direct logging output to stdout:
handler = logging.StreamHandler(stream=sys.stdout)
# Or direct logging output to a file:
# handler = logging.FileHandler(filename="sample.log")
logger.addHandler(handler)
# Optional: change the default logging format. Here we add a timestamp.
formatter = logging.Formatter("%(asctime)s:%(levelname)s:%(name)s:%(message)s")
handler.setFormatter(formatter)Aby wyświetlić ładunki żądań, podczas tworzenia wystąpienia klienta przekaż argument do logging_enableelementu =Trueclient_kwargs :
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model="Mistral-Large-2411",
client_kwargs={"logging_enable": True},
)Użyj klienta jak zwykle w kodzie.
Śledzenie
Możesz użyć funkcji śledzenia w narzędziu Azure AI Foundry, tworząc narzędzie tracer. Dzienniki są przechowywane w usłudze aplikacja systemu Azure Insights i mogą być odpytywane w dowolnym momencie przy użyciu usługi Azure Monitor lub portalu usługi Azure AI Foundry. Każde centrum sztucznej inteligencji ma skojarzony aplikacja systemu Azure Insights.
Uzyskiwanie parametry połączenia instrumentacji
Wskazówka
Ponieważ możesz dostosować okienko po lewej stronie w portalu azure AI Foundry, możesz zobaczyć inne elementy niż pokazano w tych krokach. Jeśli nie widzisz szukanych danych, wybierz pozycję ... Więcej w dolnej części okienka po lewej stronie.
Aplikację można skonfigurować tak, aby wysyłała dane telemetryczne do usługi aplikacja systemu Azure Insights, wykonując następujące czynności:
Bezpośrednie parametry połączenia aplikacja systemu Azure Insights:
Przejdź do portalu usługi Azure AI Foundry i wybierz pozycję Śledzenie.
Wybierz pozycję Zarządzaj źródłem danych. Na tym ekranie widać wystąpienie skojarzone z projektem.
Skopiuj wartość w polu Parametry połączenia i ustaw ją na następującą zmienną:
import os application_insights_connection_string = "instrumentation...."
Przy użyciu zestawu SDK usługi Azure AI Foundry i parametrów połączenia projektu (tylko projekty oparte na centrum).
Upewnij się, że pakiet
azure-ai-projectszostał zainstalowany w środowisku.Przejdź do portalu usługi Azure AI Foundry.
Skopiuj parametry połączenia projektu i ustaw go w następującym kodzie:
from azure.ai.projects import AIProjectClient from azure.identity import DefaultAzureCredential project_client = AIProjectClient.from_connection_string( credential=DefaultAzureCredential(), conn_str="<your-project-connection-string>", ) application_insights_connection_string = project_client.telemetry.get_connection_string()
Konfigurowanie śledzenia dla usługi Azure AI Foundry
Poniższy kod tworzy narzędzie tracer połączone z usługą aplikacja systemu Azure Insights za projektem w usłudze Azure AI Foundry. Zwróć uwagę, że parametr enable_content_recording jest ustawiony na Truewartość . Umożliwia to przechwytywanie danych wejściowych i wyjściowych całej aplikacji, a także kroków pośrednich. Jest to przydatne podczas debugowania i kompilowania aplikacji, ale warto je wyłączyć w środowiskach produkcyjnych. Domyślnie jest to zmienna środowiskowa AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED:
from langchain_azure_ai.callbacks.tracers import AzureAIInferenceTracer
tracer = AzureAIInferenceTracer(
connection_string=application_insights_connection_string,
enable_content_recording=True,
)
Aby skonfigurować śledzenie za pomocą łańcucha, wskaż konfigurację wartości w invoke operacji jako wywołanie zwrotne:
chain.invoke({"topic": "living in a foreign country"}, config={"callbacks": [tracer]})
Aby skonfigurować sam łańcuch do śledzenia, użyj .with_config() metody :
chain = chain.with_config({"callbacks": [tracer]})
Następnie użyj invoke() metody w zwykły sposób:
chain.invoke({"topic": "living in a foreign country"})
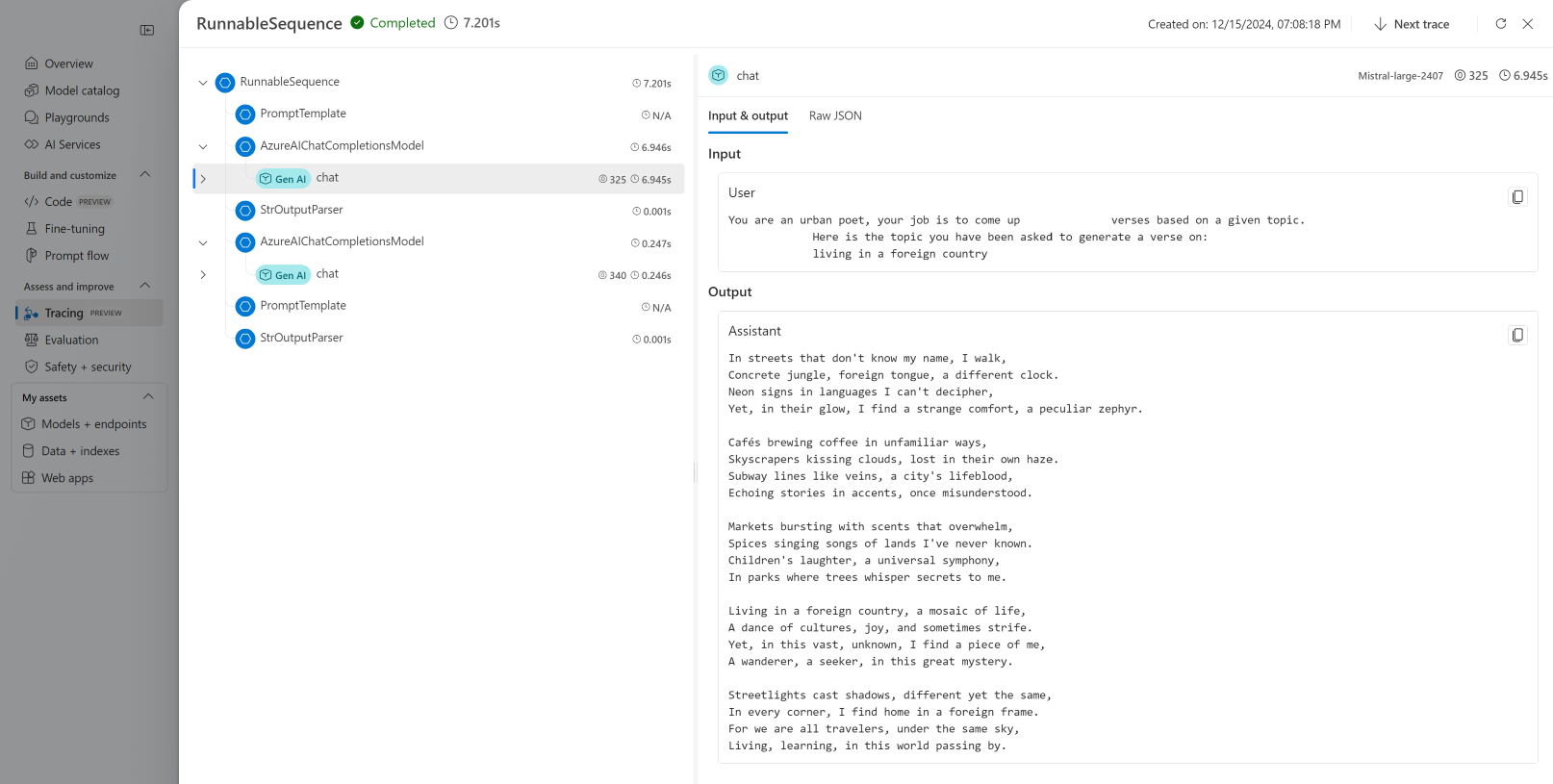
Wyświetlanie śladów
Aby wyświetlić ślady:
Przejdź do portalu usługi Azure AI Foundry.
Przejdź do sekcji Śledzenie .
Zidentyfikuj utworzony ślad. Wyświetlenie śladu może potrwać kilka sekund.

Dowiedz się więcej na temat wizualizowania śladów i zarządzania nimi.