Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
- Usługa Azure AI Content Understanding jest dostępna w wersji zapoznawczej. Publiczne wersje zapoznawcze zapewniają wczesny dostęp do funkcji, które są w aktywnym rozwoju.
- Funkcje, podejścia i procesy mogą ulec zmianie lub mieć ograniczone możliwości przed ogólną dostępnością.
- Aby uzyskać więcej informacji, zobacz Dodatkowe warunki użytkowania dla wersji zapoznawczych platformy Microsoft Azure.
Przegląd
Funkcje analizy dokumentów usługi Azure AI Content Understanding ułatwiają przekształcanie danych dokumentów bez struktury na ustrukturyzowane informacje czytelne dla maszyn. Dzięki precyzyjnemu identyfikowaniu i wyodrębnieniu elementów dokumentu przy zachowaniu ich relacji strukturalnych można tworzyć zaawansowane przepływy pracy przetwarzania dokumentów dla szerokiej gamy aplikacji.
W tym artykule opisano funkcje analizy dokumentów, które umożliwiają wyodrębnianie istotnej zawartości z dokumentów, zachowywanie struktur dokumentów i odblokowywanie pełnego potencjału danych dokumentu.
Elementy dokumentu
Następujące elementy dokumentu można wyodrębnić za pomocą wyodrębniania zawartości:
- Markdown
- Elementy zawartości
- Elementy układu
Uwaga / Notatka
Nie wszystkie elementy zawartości i układu mają zastosowanie lub są obecnie obsługiwane przez wszystkie typy plików dokumentów.
Elementy treści Markdown
Usługa Content Understanding generuje bogato sformatowany kod markdown, który zachowuje strukturę oryginalnego dokumentu, umożliwiając dużym modelom językowym lepsze zrozumienie kontekstu dokumentu i relacji hierarchicznych na potrzeby zadań analizy i generowania opartych na sztucznej inteligencji. Oprócz wyrazów, znaczników zaznaczenia, kodów kreskowych, formuł i obrazów jako zawartości, formatowanie markdown zawiera również sekcje, tabele i metadane strony do renderowania wizualnego i przetwarzania maszynowego. Dowiedz się więcej o tym, jak usługa Content Understanding reprezentuje zawartość i element układu w języku znaczników markdown.
Słowa
Element word jest elementem zawartości składającym się z sekwencji znaków. Usługa Content Understanding używa granic słów zdefiniowanych w załączniku Standard Unicode nr 29. W przypadku języków łacińskich, wyrazy mogą być oddzielone od znaków interpunkcyjnych nawet bez występowania spacji. W niektórych językach, takich jak chiński, słowniki uzupełniające są używane, aby umożliwić podział wyrazów na granicach semantycznych. Aby uzyskać więcej informacji, zobaczAnaliza granic.

Znaczniki wyboru
A selection mark to element zawartości, który reprezentuje symbol graficzny wskazujący stan zaznaczenia. Mogą one pojawiać się w dokumencie jako pola wyboru, znaki zaznaczenia, przyciski radiowe itp. Stan znacznika może być wybrany lub niewybrany, przy czym różne wizualizacje wskazują stan. Są one kodowane jako wyrazy w wyniku analizy dokumentu przy użyciu ( ☒ wybrane) i ☐ (niezaznaczone).
Usługa Content Understanding wykrywa znaczniki wyboru wewnątrz komórki tabeli jako znaczniki zaznaczenia w wybranym stanie. Jednak nie wykrywa pustych komórek tabeli jako znaków zaznaczenia, gdy nie są zaznaczone.

Kody kreskowe
A barcode to element zawartości, który opisuje kody kreskowe (np. UPC, EAN) i 2D (np. QR, MaxiCode). Usługa Content Understanding reprezentuje kody kreskowe na podstawie rozpoznanego typu i wyodrębnionej wartości. Obecnie akceptowane są następujące formaty kodów kreskowych:
QR CodeCode 39Code 93Code 128UPC (UPC-A & UPC-E)PDF417EAN-8EAN-13CodabarDatabarDatabar (expanded)ITFData Matrix
Formuły
A formula jest elementem zawartości reprezentującym wyrażenia matematyczne w dokumencie. Może to być formuła inline osadzona z innym tekstem lub formuła display , która zajmuje cały wiersz. Formuły wielowierszowe są reprezentowane jako wiele elementów formuł display zgrupowanych w paragraphs w celu zachowania relacji matematycznych.
Obrazy
Element image jest elementem zawartości reprezentującym osadzony obraz, rysunek lub wykres w dokumencie. Usługa Content Understanding wyodrębnia dowolny osadzony tekst z obrazów oraz wszystkie skojarzone podpisy i przypisy dolne.
Elementy układu
Elementy układu dokumentu to składniki wizualne i strukturalne, takie jak strony, tabele, akapity, wiersze, tabele, sekcje i ogólna struktura, które ułatwiają interpretację zawartości. Wyodrębnianie tych elementów umożliwia narzędziom efektywne analizowanie dokumentów pod kątem zadań, takich jak pobieranie informacji, interpretacja semantyczna i struktura danych.
Strony
A page to grupowanie zawartości, która zwykle odpowiada jednej stronie arkusza papieru. Renderowana strona charakteryzuje się znakiem width i height w określonym unitobiekcie . Ogólnie rzecz biorąc, obrazy używają pikseli, podczas gdy pliki PDF używają cala. Właściwość angle opisuje ogólny kąt tekstu w stopniach dla stron, które mogą być obracane.
Uwaga / Notatka
W przypadku arkuszy kalkulacyjnych, takich jak program Excel, każdy arkusz jest mapowany na stronę. W przypadku prezentacji, takich jak program PowerPoint, każdy slajd jest mapowany na stronę. W przypadku formatów plików, takich jak dokumenty HTML lub Word, które nie mają koncepcji strony natywnej bez renderowania, cała zawartość główna jest traktowana jako pojedyncza strona.
Ustępy
A paragraph to uporządkowana sekwencja wierszy tworzących jednostkę logiczną. Zazwyczaj linie mają wspólne wyrównanie i odstępy między liniami. Akapity są często rozdzielane przez wcięcie, dodane odstępy lub punktory/numerowanie. Niektóre akapity mają specjalne funkcje role w dokumencie. Obecnie obsługiwane role obejmują nagłówek strony, stopkę strony, numer strony, tytuł, nagłówek sekcji, przypis dolny i blok formuły.
Linie
A line to uporządkowana sekwencja kolejnych elementów zawartości, często oddzielona spacjami wizualnymi. Elementy zawartości w tej samej płaszczyźnie poziomej (wierszu), ale oddzielone większą niż jedną przestrzenią wizualną są najczęściej podzielone na wiele wierszy. Chociaż ta funkcja czasami dzieli semantycznie ciągłą zawartość na oddzielne wiersze, umożliwia reprezentację zawartości tekstowej podzielonej na wiele kolumn lub komórek. Linie w zapisie pionowym są wykrywane w kierunku pionowym.
Tabele
Obiekt table organizuje zawartość w grupę komórek w układzie siatki. Wiersze i kolumny mogą być wizualnie oddzielone liniami siatki, paskowaniem kolorów lub większym odstępem. Pozycja komórki tabeli jest określana za pośrednictwem indeksów wierszy i kolumn. Komórka może obejmować wiele wierszy i kolumn.
Na podstawie położenia i stylu komórka może być klasyfikowana jako ogólna zawartość, nagłówek wiersza, nagłówek kolumny, nagłówek wycinków lub opis:
Komórka nagłówka wiersza jest zazwyczaj pierwszą komórką w wierszu opisającą inne komórki w wierszu.
Komórka nagłówka kolumny jest zazwyczaj pierwszą komórką w kolumnie, która opisuje inne komórki w kolumnie.
Wiersz lub kolumna może zawierać wiele komórek nagłówka w celu opisania zawartości hierarchicznej.
Komórka głowy wycinków jest zazwyczaj komórką w pierwszym wierszu i pierwszej pozycji kolumny. Może być pusty lub opisywać wartości w komórkach nagłówka w tym samym wierszu/kolumnie.
Komórka opisu zazwyczaj pojawia się u góry lub dolnej większości obszaru tabeli, opisując ogólną zawartość tabeli. Jednak czasami może się pojawić w środku tabeli, aby podzielić tabelę na sekcje. Zazwyczaj komórki opisu obejmują wiele komórek w jednym wierszu.
Podpis tabeli określa zawartość, która wyjaśnia tabelę. Tabela może dodatkowo zawierać zestaw przypisów dolnych. W przeciwieństwie do komórki opisu podpis zwykle znajduje się poza układem siatki. Przypisy tabeli dodają adnotacje do zawartości w tabeli, często oznaczone symbolami przypisów. Często znajdują się one poniżej siatki tabeli.
Tabela może obejmować kolejne strony dokumentu. W takiej sytuacji kontynuacje tabeli na kolejnych stronach zwykle zachowują tę samą liczbę kolumn, szerokość i styl. Często powtarzają nagłówki kolumn. Poza nagłówkami stron, stopkami i numerami stron, zazwyczaj nie ma żadnej pośredniej zawartości między początkową tabelą a jej kontynuacjami.
Uwaga / Notatka
Zakres tabel obejmuje tylko podstawową zawartość i wyklucza powiązany nagłówek oraz przypisy dolne.
Sekcje
A section to logiczne grupowanie powiązanych elementów zawartości, które tworzą hierarchiczną strukturę w dokumencie. Często zaczyna się od nagłówka sekcji, będącego pierwszym akapitem. Sekcja może zawierać podsekcje, tworząc zagnieżdżone struktury dokumentów, która zachowuje relacje semantyczne.
Właściwości elementu
Dokumenty składają się z różnych składników, które można podzielić na elementy strukturalne, tekstowe i związane z formularzem. Te elementy nie tylko definiują organizację i prezentację dokumentu, ale także można je systematycznie identyfikować i wyodrębniać do dalszej analizy lub aplikacji.
Zakres
Właściwość span określa logiczną pozycję elementu w dokumencie poprzez przesunięcie i długość znaków w odniesieniu do właściwości ciągu najwyższego poziomu markdown. Domyślnie przesunięcia i długości znaków są zwracane w punktach kodu Unicode używanych przez język Python 3. Aby obsłużyć różne środowiska programistyczne korzystające z różnych jednostek znaków, użytkownik może zdefiniować parametr zapytania stringEncoding, aby zwrócić przesunięcia i długości zakresu w jednostkach kodowych UTF16 (Java, JavaScript, .NET) lub bajtach UTF8 (Go, Rust, Ruby, PHP).
Źródło
Właściwość source opisuje położenie wizualne elementu w pliku przy użyciu zakodowanego ciągu. W przypadku dokumentów ciąg źródłowy może mieć jeden z następujących formatów:
- Wiązanie wielokąta:
D({pageNumber},{x1},{y1},{x2},{y2},{x3},{y3},{x4},{y4}) - Pole ograniczenia wyrównane do osi:
D({pageNumber},{left},{top},{width},{height})
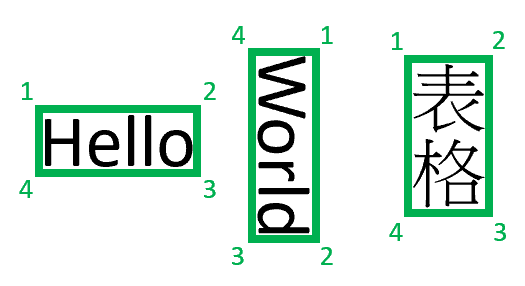
Numeracja stron zaczyna się od 1. Wielokąt opisuje sekwencję punktów zgodnie z ruchem wskazówek zegara, zaczynając od lewej strony względem naturalnej orientacji elementu. W przypadku czworokątów punkty reprezentują lewy górny, prawy górny, prawy dolny i lewy dolny róg. Każdy punkt reprezentuje współrzędną x, y w jednostce długości określonej przez unit właściwość . Ogólnie rzecz biorąc, jednostka miary dla obrazów to piksele, podczas gdy pliki PDF używają cali.
Uwaga / Notatka
Obecnie funkcja Content Understanding zwraca tylko 4-punktowe czworokąty jako wielokąty ograniczające. Przyszłe wersje mogą zwracać inną liczbę punktów, aby opisać bardziej złożone kształty, takie jak krzywe linie lub nierektangularne obrazy. Obecnie źródło jest zwracane tylko dla elementów z renderowanych plików (pdf/image).
Dalsze kroki
- Spróbuj przetwarzać zawartość dokumentu przy użyciu usługi Content Understanding w usłudze Azure AI Foundry.
- Dowiedz się, jak analizować szablony analizatora zawartości dokumentu.
- Przejrzyj przykłady kodu: wyszukiwanie w dokumentach wizualnych.
- Przejrzyj przykładowy kod: szablony analizatora.