Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym samouczku wyjaśniono, jak stworzyć rozwiązanie generacji rozszerzonej (RAG, retrieval-augmented generation) z użyciem Azure Content Understanding w Foundry Tools. Obejmuje ona kluczowe kroki tworzenia silnego systemu RAG, oferuje wskazówki dotyczące poprawy istotności i dokładności oraz pokazuje, jak nawiązać połączenie z innymi usługami platformy Azure. Na koniec możesz użyć usługi Content Understanding, aby obsługiwać dane wielomodalne, ulepszać pobieranie i pomagać modelom sztucznej inteligencji w dostarczaniu dokładnych i znaczących odpowiedzi.
Ćwiczenia zawarte w tym samouczku
- Tworzenie analizatorów. Dowiedz się, jak tworzyć analizatory wielokrotnego użytku w celu wyodrębniania zawartości ustrukturyzowanej z danych wielomodalnych przy użyciu wyodrębniania zawartości.
- Generowanie docelowych metadanych za pomocą wyodrębniania pól. Dowiedz się, jak używać sztucznej inteligencji do generowania dalszych metadanych, takich jak podsumowania lub kluczowe tematy, w celu wzbogacania wyodrębnionej zawartości.
- Wstępnie przetwarza wyodrębnianą zawartość. Poznaj sposoby przekształcania wyodrębnionej zawartości w wektorowe osadzanie na potrzeby semantycznego wyszukiwania i pobierania.
- Projektowanie ujednoliconego indeksu. Utwórz ujednolicony indeks usługi Azure AI Search, który integruje i organizuje dane wielomodalne w celu wydajnego pobierania.
- Pobieranie fragmentu semantycznego. Wyodrębnij kontekstowo istotne informacje, aby dostarczać bardziej precyzyjne i zrozumiałe odpowiedzi na zapytania użytkowników.
- Interakcja z danymi przy użyciu modeli czatów Korzystanie z modeli czatów usługi Azure OpenAI w celu angażowania się w indeksowane dane, włączania wyszukiwania konwersacyjnego, wykonywania zapytań i odpowiadania.
Wymagania wstępne
Aby rozpocząć pracę, potrzebujesz aktywnej subskrypcji platformy Azure. Jeśli nie masz konta platformy Azure, możesz utworzyć bezpłatną subskrypcję.
Po utworzeniu subskrypcji platformy Azure utwórz zasób Microsoft Foundry w witrynie Azure Portal.
Ten zasób znajduje się w obszarze Foundry>Foundry w portalu.
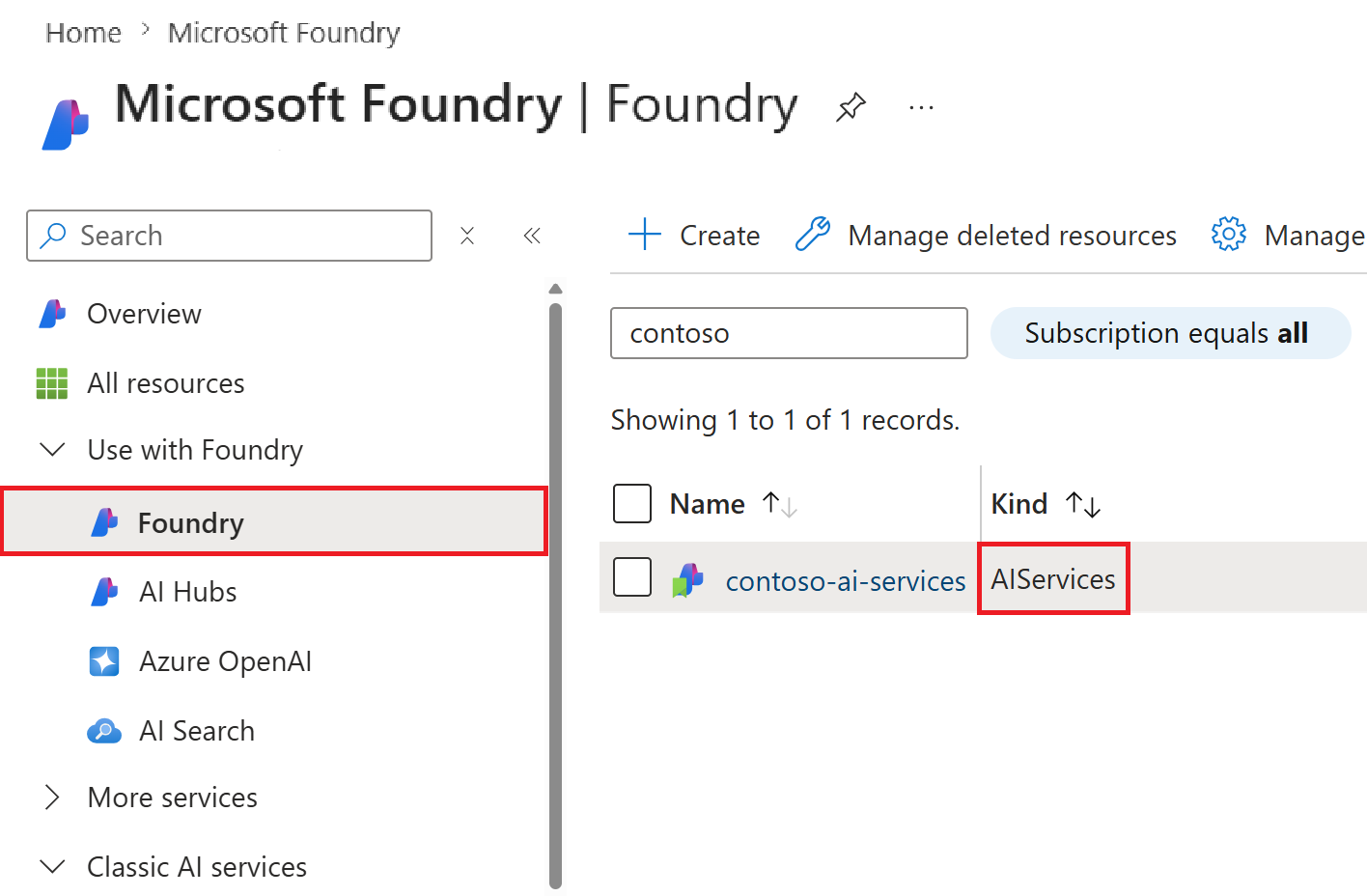
Zasób usługi Azure AI Search: Skonfiguruj zasób usługi Azure AI Search , aby umożliwić indeksowanie i pobieranie danych wielomodalnych.
Wdrażanie modelu czatu usługi Azure OpenAI: Wdróż model czatu usługi Azure OpenAI , który umożliwia interakcję konwersacyjną.
Model osadzający wdrożenie: Upewnij się, że wdrożono model osadzający w celu wygenerowania reprezentacji wektorowych na potrzeby wyszukiwania semantycznego.
Wersja interfejsu API: W tym samouczku jest używana najnowsza wersja interfejsu API w wersji zapoznawczej.
Środowisko języka Python: Zainstaluj język Python 3.11 , aby wykonać podane przykłady kodu i skrypty.
Ten samouczek jest zgodny z tym przykładowym kodem, który można znaleźć w notesie języka Python. Postępuj zgodnie z instrukcjami README , aby utworzyć podstawowe zasoby, przyznać zasobom odpowiednie role kontroli dostępu (zarządzanie dostępem i tożsamościami) i zainstalować wszystkie pakiety potrzebne do tego samouczka.
Dane wielomodalne używane w tym samouczku składają się z dokumentów, obrazów, audio i wideo. Zostały one zaprojektowane tak, aby przeprowadzą Cię przez proces tworzenia niezawodnego rozwiązania RAG za pomocą usługi Azure Content Understanding w narzędziach Foundry.
Wyodrębnianie danych
Generowanie rozszerzonego pobierania (RAG*) to metoda, która zwiększa funkcjonalność dużych modeli językowych (LLM), integrując dane z zewnętrznych źródeł wiedzy. Tworzenie niezawodnego wielomodalnego rozwiązania RAG rozpoczyna się od wyodrębniania i tworzenia struktur danych z różnych typów zawartości. Usługa Azure Content Understanding udostępnia trzy kluczowe składniki ułatwiające ten proces: wyodrębnianie zawartości, wyodrębnianie pól i analizatory. Razem te składniki stanowią podstawę tworzenia ujednoliconego, wielokrotnie używalnego i ulepszonego przepływu danych dla przepływów pracy RAG.
Kroki implementacji
Aby zaimplementować wyodrębnianie danych w usłudze Content Understanding, wykonaj następujące kroki:
Tworzenie analizatora: Zdefiniuj analizator przy użyciu interfejsów API REST lub naszych przykładów kodu w języku Python.
Wyodrębnianie zawartości: Analizator umożliwia przetwarzanie plików i wyodrębnianie zawartości ustrukturyzowanej.
(Opcjonalnie) Ulepsz za pomocą wyodrębniania pól: Opcjonalnie określ pola generowane przez sztuczną inteligencję, aby wzbogacić wyodrębnianą zawartość z dodanymi metadanymi.
Tworzenie analizatorów
Analizatory są składnikami wielokrotnego użytku w usłudze Content Understanding, które usprawniają proces wyodrębniania danych. Po utworzeniu analizatora można go wielokrotnie używać do przetwarzania plików i wyodrębniania zawartości lub pól na podstawie wstępnie zdefiniowanych schematów. Analizator działa jako strategia sposobu przetwarzania danych, zapewniając spójność i wydajność w wielu plikach i typach zawartości.
Poniższe przykłady kodu pokazują, jak utworzyć analizatory dla każdej modalności, określając dane ustrukturyzowane do wyodrębnienia, takie jak pola kluczy, podsumowania lub klasyfikacje. Te analizatory stanowią fundament do wyodrębniania i wzbogacania zawartości w rozwiązaniu RAG.
Załaduj wszystkie zmienne środowiskowe i niezbędne biblioteki z witryny Langchain
import os
from dotenv import load_dotenv
load_dotenv()
# Load and validate Foundry Tools configs
AZURE_AI_SERVICE_ENDPOINT = os.getenv("AZURE_AI_SERVICE_ENDPOINT")
AZURE_AI_SERVICE_API_VERSION = os.getenv("AZURE_AI_SERVICE_API_VERSION") or "2024-12-01-preview"
AZURE_DOCUMENT_INTELLIGENCE_API_VERSION = os.getenv("AZURE_DOCUMENT_INTELLIGENCE_API_VERSION") or "2024-11-30"
# Load and validate Azure OpenAI configs
AZURE_OPENAI_ENDPOINT = os.getenv("AZURE_OPENAI_ENDPOINT")
AZURE_OPENAI_CHAT_DEPLOYMENT_NAME = os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT_NAME")
AZURE_OPENAI_CHAT_API_VERSION = os.getenv("AZURE_OPENAI_CHAT_API_VERSION") or "2024-08-01-preview"
AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME = os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME")
AZURE_OPENAI_EMBEDDING_API_VERSION = os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION") or "2023-05-15"
# Load and validate Azure Search Services configs
AZURE_SEARCH_ENDPOINT = os.getenv("AZURE_SEARCH_ENDPOINT")
AZURE_SEARCH_INDEX_NAME = os.getenv("AZURE_SEARCH_INDEX_NAME") or "sample-doc-index"
# Import libraries from Langchain
from langchain import hub
from langchain_openai import AzureChatOpenAI
from langchain_openai import AzureOpenAIEmbeddings
from langchain.schema import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain.text_splitter import MarkdownHeaderTextSplitter
from langchain.vectorstores.azuresearch import AzureSearch
from langchain_core.prompts import ChatPromptTemplate
from langchain.schema import Document
import requests
import json
import sys
import uuid
from pathlib import Path
from dotenv import find_dotenv, load_dotenv
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
# Add the parent directory to the path to use shared modules
parent_dir = Path(Path.cwd()).parent
sys.path.append(str(parent_dir))
Przykład kodu: Tworzenie analizatora
from pathlib import Path
from python.content_understanding_client import AzureContentUnderstandingClient
credential = DefaultAzureCredential()
token_provider = get_bearer_token_provider(credential, "https://cognitiveservices.azure.com/.default")
#set analyzer configs
analyzer_configs = [
{
"id": "doc-analyzer" + str(uuid.uuid4()),
"template_path": "../analyzer_templates/content_document.json",
"location": Path("../data/sample_layout.pdf"),
},
{
"id": "image-analyzer" + str(uuid.uuid4()),
"template_path": "../analyzer_templates/image_chart_diagram_understanding.json",
"location": Path("../data/sample_report.pdf"),
},
{
"id": "audio-analyzer" + str(uuid.uuid4()),
"template_path": "../analyzer_templates/call_recording_analytics.json",
"location": Path("../data/callCenterRecording.mp3"),
},
{
"id": "video-analyzer" + str(uuid.uuid4()),
"template_path": "../analyzer_templates/video_content_understanding.json",
"location": Path("../data/FlightSimulator.mp4"),
},
]
# Create Content Understanding client
content_understanding_client = AzureContentUnderstandingClient(
endpoint=AZURE_AI_SERVICE_ENDPOINT,
api_version=AZURE_AI_SERVICE_API_VERSION,
token_provider=token_provider,
x_ms_useragent="azure-ai-content-understanding-python/content_extraction", # This header is used for sample usage telemetry, please comment out this line if you want to opt out.
)
# Iterate through each config and create an analyzer
for analyzer in analyzer_configs:
analyzer_id = analyzer["id"]
template_path = analyzer["template_path"]
try:
# Create the analyzer using the content understanding client
response = content_understanding_client.begin_create_analyzer(
analyzer_id=analyzer_id,
analyzer_template_path=template_path
)
result = content_understanding_client.poll_result(response)
print(f"Successfully created analyzer: {analyzer_id}")
except Exception as e:
print(f"Failed to create analyzer: {analyzer_id}")
print(f"Error: {e}")
Nuta: Schematy wyodrębniania pól są opcjonalne i nie są wymagane do wyodrębniania zawartości. Aby wykonać wyodrębnianie zawartości i utworzyć analizatory bez definiowania schematów pól, wystarczy podać identyfikator analizatora i plik do przeanalizowania.
Schematy zostały użyte w tym samouczku. Oto przykład definicji schematu
W poniższym przykładzie definiujemy schemat wyodrębniania podstawowych informacji z dokumentu faktury.
{
"description": "Sample invoice analyzer",
"scenario": "document",
"config": {
"returnDetails": true
},
"fieldSchema": {
"fields": {
"VendorName": {
"type": "string",
"method": "extract",
"description": "Vendor issuing the invoice"
},
"Items": {
"type": "array",
"method": "extract",
"items": {
"type": "object",
"properties": {
"Description": {
"type": "string",
"method": "extract",
"description": "Description of the item"
},
"Amount": {
"type": "number",
"method": "extract",
"description": "Amount of the item"
}
}
}
}
}
}
}
Wyodrębnianie zawartości i pól
Wyodrębnianie zawartości to pierwszy krok w procesie implementacji RAG. Przekształca nieprzetworzone dane wielomodalne na formaty ustrukturyzowane, z możliwością wyszukiwania. Ten podstawowy krok gwarantuje, że zawartość jest zorganizowana i gotowa do indeksowania i pobierania. Wyodrębnianie zawartości zapewnia punkt odniesienia do indeksowania i pobierania, ale może nie w pełni zaspokoić potrzeb specyficznych dla domeny lub zapewnić bardziej szczegółowe informacje kontekstowe. Dowiedz się więcej o możliwościach wyodrębniania zawartości dla każdej modalności.
Wyodrębnianie pól opiera się na wyodrębnieniu zawartości przy użyciu sztucznej inteligencji w celu wygenerowania dalszych metadanych wzbogacających bazę wiedzy. Ten krok umożliwia zdefiniowanie pól niestandardowych dostosowanych do konkretnego przypadku użycia, co umożliwia dokładniejsze pobieranie i rozszerzone znaczenie wyszukiwania. Wyodrębnianie pól uzupełnia wyodrębnianie zawartości przez dodanie głębi i kontekstu, dzięki czemu dane będą bardziej dostępne dla scenariuszy RAG. Dowiedz się więcej o możliwościach wyodrębniania pól dla każdej modalności.
Dzięki analizatorom utworzonym dla każdej modalności możemy teraz przetwarzać pliki w celu wyodrębniania zawartości ustrukturyzowanej i metadanych generowanych przez sztuczną inteligencję na podstawie zdefiniowanych schematów. W tej sekcji pokazano, jak używać analizatorów do analizowania danych wielomodalnych i przedstawia przykład wyników zwracanych przez interfejsy API. Te wyniki przedstawiają przekształcanie nieprzetworzonych danych w szczegółowe informacje umożliwiające podejmowanie działań, tworząc podstawy do indeksowania, pobierania i RAG przepływów pracy.
Analizowanie plików
#Iterate through each analyzer created and analyze content for each modality
analyzer_results =[]
extracted_markdown = []
analyzer_content = []
for analyzer in analyzer_configs:
analyzer_id = analyzer["id"]
template_path = analyzer["template_path"]
file_location = analyzer["location"]
try:
# Analyze content
response = content_understanding_client.begin_analyze(analyzer_id, file_location)
result = content_understanding_client.poll_result(response)
analyzer_results.append({"id":analyzer_id, "result": result["result"]})
analyzer_content.append({"id": analyzer_id, "content": result["result"]["contents"]})
except Exception as e:
print(e)
print("Error in creating analyzer. Please double-check your analysis settings.\nIf there is a conflict, you can delete the analyzer and then recreate it, or move to the next cell and use the existing analyzer.")
print("Analyzer Results:")
for analyzer_result in analyzer_results:
print(f"Analyzer ID: {analyzer_result['id']}")
print(json.dumps(analyzer_result["result"], indent=2))
# Delete the analyzer if it is no longer needed
#content_understanding_client.delete_analyzer(ANALYZER_ID)
Wyodrębnianie wyników
Poniższe przykłady kodu przedstawiają dane wyjściowe wyodrębniania zawartości i pól przy użyciu usługi Azure Content Understanding. Odpowiedź JSON zawiera wiele pól, z których każda obsługuje określony cel w reprezentowaniu wyodrębnionych danych.
Pole języka Markdown:
markdownpole zawiera uproszczoną, czytelną dla człowieka reprezentację wyodrębnionej zawartości. Jest to szczególnie przydatne w przypadku szybkich wersji zapoznawczych lub integrowania wyodrębnionych danych z aplikacjami, które wymagają tekstu ustrukturyzowanego, takiego jak bazy wiedzy lub interfejsy wyszukiwania. Na przykład w przypadku dokumentumarkdownpole może zawierać nagłówki, akapity i inne elementy strukturalne sformatowane w celu ułatwienia czytelności.Dane wyjściowe JSON: Pełne dane wyjściowe JSON zapewniają kompleksową reprezentację wyodrębnionych danych, w tym zarówno zawartość, jak i metadane wygenerowane podczas procesu wyodrębniania, w tym następujące właściwości:
- Pola: Metadane generowane przez sztuczną inteligencję, takie jak podsumowania, kluczowe tematy lub klasyfikacje, dostosowane do określonego schematu zdefiniowanego w analizatorze.
- Współczynniki ufności: Wskaźniki niezawodności wyodrębnionych danych.
- Obejmuje: Informacje o lokalizacji wyodrębnionej zawartości w pliku źródłowym.
- Dodatkowe metadane: Szczegóły, takie jak numery stron, wymiary i inne informacje kontekstowe.
Wynik przedstawia wyodrębnianie nagłówków, akapitów, tabel i innych elementów strukturalnych przy zachowaniu logicznej organizacji zawartości. Ponadto prezentuje możliwość wyodrębniania kluczowych pól, zapewniając zwięzłe wyciąganie informacji z obszernych materiałów.
{
"id": "bcf8c7c7-03ab-4204-b22c-2b34203ef5db",
"status": "Succeeded",
"result": {
"analyzerId": "training_document_analyzer",
"apiVersion": "2024-12-01-preview",
"createdAt": "2024-11-13T07:15:46Z",
"warnings": [],
"contents": [
{
"markdown": "CONTOSO LTD.\n\n\n# Contoso Training Topics\n\nContoso Headquarters...",
"fields": {
"ChapterTitle": {
"type": "string",
"valueString": "Risks and Compliance regulations",
"spans": [ { "offset": 0, "length": 12 } ],
"confidence": 0.941,
"source": "D(1,0.5729,0.6582,2.3353,0.6582,2.3353,0.8957,0.5729,0.8957)"
},
"ChapterAuthor": {
"type": "string",
"valueString": "John Smith",
"spans": [ { "offset": 0, "length": 12 } ],
"confidence": 0.941,
"source": "D(1,0.5729,0.6582,2.3353,0.6582,2.3353,0.8957,0.5729,0.8957)"
},
"ChapterPublishDate": {
"type": "Date",
"valueString": "04-11-2017",
"spans": [ { "offset": 0, "length": 12 } ],
"confidence": 0.941,
"source": "D(1,0.5729,0.6582,2.3353,0.6582,2.3353,0.8957,0.5729,0.8957)"
},
},
"kind": "document",
"startPageNumber": 1,
"endPageNumber": 1,
"unit": "inch",
"pages": [
{
"pageNumber": 1,
"angle": -0.0039,
"width": 8.5,
"height": 11,
"spans": [ { "offset": 0, "length": 1650 } ],
"words": [
{
....
},
],
"lines": [
{
...
},
]
}
],
}
]
}
}
Wstępne przetwarzanie danych wyjściowych z usługi Content Understanding
Po wyodrębnieniu danych przy użyciu usługi Azure Content Understanding następnym krokiem jest przygotowanie danych wyjściowych analizy do osadzania w systemie wyszukiwania. Wstępne przetwarzanie danych wyjściowych gwarantuje, że wyodrębniona zawartość zostanie przekształcona w format odpowiedni do indeksowania i pobierania. Ten krok obejmuje konwertowanie danych wyjściowych JSON z analizatorów na ciągi ustrukturyzowane, zachowując zarówno zawartość, jak i metadane w celu bezproblemowej integracji z podrzędnymi przepływami pracy.
W poniższym przykładzie pokazano, jak wstępnie przetworzyć dane wyjściowe z analizatorów, w tym dokumenty, obrazy, dźwięk i wideo. Proces konwertowania danych wyjściowych JSON na ciąg ustrukturyzowany określa podstawy osadzania danych w systemie wyszukiwania opartego na wektorach, umożliwiając wydajne pobieranie i ulepszone przepływy pracy RAG.
def convert_values_to_strings(json_obj):
return [str(value) for value in json_obj]
#process all content and convert to string
def process_allJSON_content(all_content):
# Initialize empty list to store string of all content
output = []
document_splits = [
"This is a json string representing a document with text and metadata for the file located in "+str(analyzer_configs[0]["location"])+" "
+ v
+ "```"
for v in convert_values_to_strings(all_content[0]["content"])
]
docs = [Document(page_content=v) for v in document_splits]
output += docs
#convert image json object to string and append file metadata to the string
image_splits = [
"This is a json string representing an image verbalization and OCR extraction for the file located in "+str(analyzer_configs[1]["location"])+" "
+ v
+ "```"
for v in convert_values_to_strings(all_content[1]["content"])
]
image = [Document(page_content=v) for v in image_splits]
output+=image
#convert audio json object to string and append file metadata to the string
audio_splits = [
"This is a json string representing an audio segment with transcription for the file located in "+str(analyzer_configs[2]["location"])+" "
+ v
+ "```"
for v in convert_values_to_strings(all_content[2]["content"])
]
audio = [Document(page_content=v) for v in audio_splits]
output += audio
#convert video json object to string and append file metadata to the string
video_splits = [
"The following is a json string representing a video segment with scene description and transcript for the file located in "+str(analyzer_configs[3]["location"])+" "
+ v
+ "```"
for v in convert_values_to_strings(all_content[3]["content"])
]
video = [Document(page_content=v) for v in video_splits]
output+=video
return output
all_splits = process_allJSON_content(analyzer_content)
print("There are " + str(len(all_splits)) + " documents.")
# Print the content of all doc splits
for doc in all_splits:
print(f"doc content", doc.page_content)
Osadzanie i indeksowanie wyodrębnionej zawartości
Po zakończeniu wstępnego przetwarzania wyodrębnionych danych z usługi Azure Content Understanding następnym krokiem jest osadzanie i indeksowanie zawartości w celu wydajnego pobierania. Ten krok obejmuje przekształcenie ciągów strukturalnych w wektorowe osadzanie przy użyciu modelu osadzania i przechowywanie ich w systemie usługi Azure AI Search. Osadzając zawartość, włączasz funkcje wyszukiwania semantycznego, umożliwiając systemowi pobieranie najbardziej odpowiednich informacji na podstawie znaczenia, a nie dokładnych dopasowań słów kluczowych. Ten krok ma kluczowe znaczenie dla tworzenia niezawodnego rozwiązania RAG, ponieważ gwarantuje, że wyodrębniona zawartość jest zoptymalizowana pod kątem zaawansowanych przepływów pracy wyszukiwania i pobierania.
# Embed the splitted documents and insert into Azure Search vector store
def embed_and_index_chunks(docs):
aoai_embeddings = AzureOpenAIEmbeddings(
azure_deployment=AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME,
openai_api_version=AZURE_OPENAI_EMBEDDING_API_VERSION, # e.g., "2023-12-01-preview"
azure_endpoint=AZURE_OPENAI_ENDPOINT,
azure_ad_token_provider=token_provider
)
vector_store: AzureSearch = AzureSearch(
azure_search_endpoint=AZURE_SEARCH_ENDPOINT,
azure_search_key=None,
index_name=AZURE_SEARCH_INDEX_NAME,
embedding_function=aoai_embeddings.embed_query
)
vector_store.add_documents(documents=docs)
return vector_store
# embed and index the docs:
vector_store = embed_and_index_chunks(all_splits)
Pobieranie fragmentu semantycznego
W przypadku wyodrębnionej zawartości osadzonej i indeksowanej następnym krokiem jest użycie możliwości wyszukiwania podobieństwa i wektorów w celu pobrania najbardziej odpowiednich fragmentów informacji. W tej sekcji pokazano, jak wykonywać zarówno podobieństwo, jak i wyszukiwania hybrydowe, umożliwiając systemowi uwidocznienie zawartości na podstawie znaczenia semantycznego, a nie dokładnych dopasowań słów kluczowych. Po pobraniu kontekstowych fragmentów można zwiększyć precyzję przepływów pracy RAG i zapewnić dokładniejsze, znaczące odpowiedzi na zapytania użytkowników.
# Set your query
query = "japan"
# Perform a similarity search
docs = vector_store.similarity_search(
query=query,
k=3,
search_type="similarity",
)
for doc in docs:
print(doc.page_content)
# Perform a hybrid search using the search_type parameter
docs = vector_store.hybrid_search(query=query, k=3)
for doc in docs:
print(doc.page_content)
Korzystanie z interfejsu OpenAI do interakcji z danymi
Po osadzeniu i zindeksowaniu wyodrębnionej zawartości, ostatnim krokiem w budowaniu niezawodnego rozwiązania RAG jest umożliwienie interakcji konwersacyjnych przy użyciu modeli czatu OpenAI. W tej sekcji pokazano, jak wykonywać zapytania dotyczące indeksowanych danych i stosować modele czatów OpenAI w celu zapewnienia zwięzłych, kontekstowych odpowiedzi. Integrując konwersacyjną sztuczną inteligencję, możesz przekształcić rozwiązanie RAG w interaktywny system, który zapewnia znaczące szczegółowe informacje i zwiększa zaangażowanie użytkowników. W poniższych przykładach przedstawiono sposób konfigurowania przepływu konwersacji rozszerzonej na potrzeby pobierania, zapewniając bezproblemową integrację danych z modelami czatów OpenAI.
# Setup rag chain
prompt_str = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:"""
def setup_rag_chain(vector_store):
retriever = vector_store.as_retriever(search_type="similarity", k=3)
prompt = ChatPromptTemplate.from_template(prompt_str)
llm = AzureChatOpenAI(
openai_api_version=AZURE_OPENAI_CHAT_API_VERSION,
azure_deployment=AZURE_OPENAI_CHAT_DEPLOYMENT_NAME,
azure_ad_token_provider=token_provider,
temperature=0.7,
)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
return rag_chain
# Setup conversational search
def conversational_search(rag_chain, query):
print(rag_chain.invoke(query))
rag_chain = setup_rag_chain(vector_store)
while True:
query = input("Enter your query: ")
if query=="":
break
conversational_search(rag_chain, query)