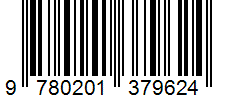Funkcje dodatków są dostępne we wszystkich modelach z wyjątkiem modelu wizytówek.
Możliwości
Analiza dokumentów obsługuje bardziej zaawansowane i modułowe możliwości analizy. Użyj funkcji dodatku, aby rozszerzyć wyniki, aby uwzględnić więcej funkcji wyodrębnionych z dokumentów. Niektóre funkcje dodatków generują dodatkowe koszty. Te opcjonalne funkcje można włączyć i wyłączyć w zależności od scenariusza wyodrębniania dokumentów. Aby włączyć funkcję, dodaj skojarzona nazwa funkcji do features właściwości ciągu zapytania. Możesz włączyć więcej niż jedną funkcję dodatku na żądanie, podając rozdzielaną przecinkami listę funkcji. Następujące funkcje dodatku są dostępne dla 2023-07-31 (GA) wersji i nowszych.
Implementacja pól zapytania w interfejsie API 2023-10-30-preview różni się od ostatniej wersji zapoznawczej. Nowa implementacja jest tańsza i dobrze współpracuje ze ustrukturyzowanymi dokumentami.
✱ Dodatek — pola zapytania są wyceniane inaczej niż inne funkcje dodatku. Aby uzyskać szczegółowe informacje, zobacz cennik .
Obsługiwane formaty plików
PDF
Obrazy: JPEG/JPG, , BMPPNG, , TIFFHEIF
✱ Pliki pakietu Microsoft Office nie są obecnie obsługiwane.
Wyodrębnianie o wysokiej rozdzielczości
Zadanie rozpoznawania małego tekstu z dużych dokumentów, takich jak rysunki inżynieryjne, jest wyzwaniem. Często tekst jest mieszany z innymi elementami graficznymi i ma różne czcionki, rozmiary i orientacje. Ponadto tekst można podzielić na oddzielne części lub połączyć się z innymi symbolami. Analiza dokumentów obsługuje teraz wyodrębnianie zawartości z tych typów dokumentów z ocr.highResolution możliwością. Ulepszono jakość wyodrębniania zawartości z dokumentów A1/A2/A3, włączając tę funkcję dodatku.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.OCR_HIGH_RESOLUTION], # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_with_highres]
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
# Analyze a document at a URL:
url = "(https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.OCR_HIGH_RESOLUTION] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_with_highres]
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
Funkcja ocr.formula wyodrębnia wszystkie zidentyfikowane formuły, takie jak równania matematyczne, w formulas kolekcji jako obiekt najwyższego poziomu w obszarze content. Wewnątrz contentfunkcji wykryte formuły są reprezentowane jako :formula:. Każdy wpis w tej kolekcji reprezentuje formułę zawierającą typ formuły jako inline lub display, a jej reprezentację LaTeX wraz value ze polygon współrzędnymi. Początkowo formuły są wyświetlane na końcu każdej strony.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.FORMULAS], # Specify which add-on capabilities to enable
)
result: AnalyzeResult = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
if page.formulas:
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
# To learn the detailed concept of "polygon" in the following content, visit: https://aka.ms/bounding-region
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.FORMULAS] # Specify which add-on capabilities to enable
)
result = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
"content": ":formula:",
"pages": [
{
"pageNumber": 1,
"formulas": [
{
"kind": "inline",
"value": "\\frac { \\partial a } { \\partial b }",
"polygon": [...],
"span": {...},
"confidence": 0.99
},
{
"kind": "display",
"value": "y = a \\times b + a \\times c",
"polygon": [...],
"span": {...},
"confidence": 0.99
}
]
}
]
Wyodrębnianie właściwości czcionki
Funkcja ocr.font wyodrębnia wszystkie właściwości czcionki tekstu wyodrębnionego w styles kolekcji jako obiekt najwyższego poziomu w obszarze content. Każdy obiekt stylu określa pojedynczą właściwość czcionki, zakres tekstu, do których ma zastosowanie, oraz odpowiadający mu współczynnik ufności. Istniejąca właściwość stylu jest rozszerzona o więcej właściwości czcionki, takich jak czcionka tekstu, fontStyle style, takie jak similarFontFamily kursywa i normalna, fontWeight dla pogrubienia lub normalnego, color kolor tekstu i backgroundColor kolor pola ograniczenia tekstu.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
return
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
Funkcja ocr.barcode wyodrębnia wszystkie zidentyfikowane kody kreskowe w barcodes kolekcji jako obiekt najwyższego poziomu w obszarze content. W obiekcie contentwykryte kody kreskowe są reprezentowane jako :barcode:. Każdy wpis w tej kolekcji reprezentuje kod kreskowy i zawiera typ kodu kreskowego jako kind i osadzoną zawartość kodu kreskowego wraz value ze polygon współrzędnymi. Początkowo kody kreskowe są wyświetlane na końcu każdej strony. Element confidence jest zakodowany jako 1.
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-barcodes.jpg?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.BARCODES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_barcodes]
# Iterate over extracted barcodes on each page.
for page in result.pages:
print(f"----Barcodes detected from page #{page.page_number}----")
print(f"Detected {len(page.barcodes)} barcodes:")
for barcode_idx, barcode in enumerate(page.barcodes):
print(f"- Barcode #{barcode_idx}: {barcode.value}")
print(f" Kind: {barcode.kind}")
print(f" Confidence: {barcode.confidence}")
print(f" Bounding regions: {format_polygon(barcode.polygon)}")
languages Dodanie funkcji do analyzeResult żądania przewiduje wykryty język podstawowy dla każdego wiersza tekstu wraz z elementem confidence w kolekcji w languages obszarze analyzeResult.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
if result.languages:
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(
f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'"
)
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'")
We wcześniejszych wersjach interfejsu API model wstępnie utworzonego dokumentu wyodrębnił pary klucz-wartość z formularzy i dokumentów. Po dodaniu funkcji do wstępnie utworzonego keyValuePairs układu model układu generuje teraz te same wyniki.
Pary klucz-wartość są określonymi zakresami w dokumencie, które identyfikują etykietę lub klucz i powiązaną z nią odpowiedź lub wartość. W formularzu ustrukturyzowanym te pary mogą być etykietą i wartością wprowadzoną przez użytkownika dla tego pola. W dokumencie bez struktury mogą one być datą wykonania umowy na podstawie tekstu w akapicie. Model sztucznej inteligencji jest trenowany w celu wyodrębniania możliwych do zidentyfikowania kluczy i wartości w oparciu o szeroką gamę typów dokumentów, formatów i struktur.
Klucze mogą również istnieć w izolacji, gdy model wykryje, że klucz istnieje, bez skojarzonej wartości lub podczas przetwarzania pól opcjonalnych. Na przykład pole nazwy środkowej może być puste w formularzu w niektórych przypadkach. Pary klucz-wartość to zakresy tekstu zawartego w dokumencie. W przypadku dokumentów, w których ta sama wartość jest opisana na różne sposoby, na przykład klient/użytkownik, skojarzony klucz jest klientem lub użytkownikiem (na podstawie kontekstu).
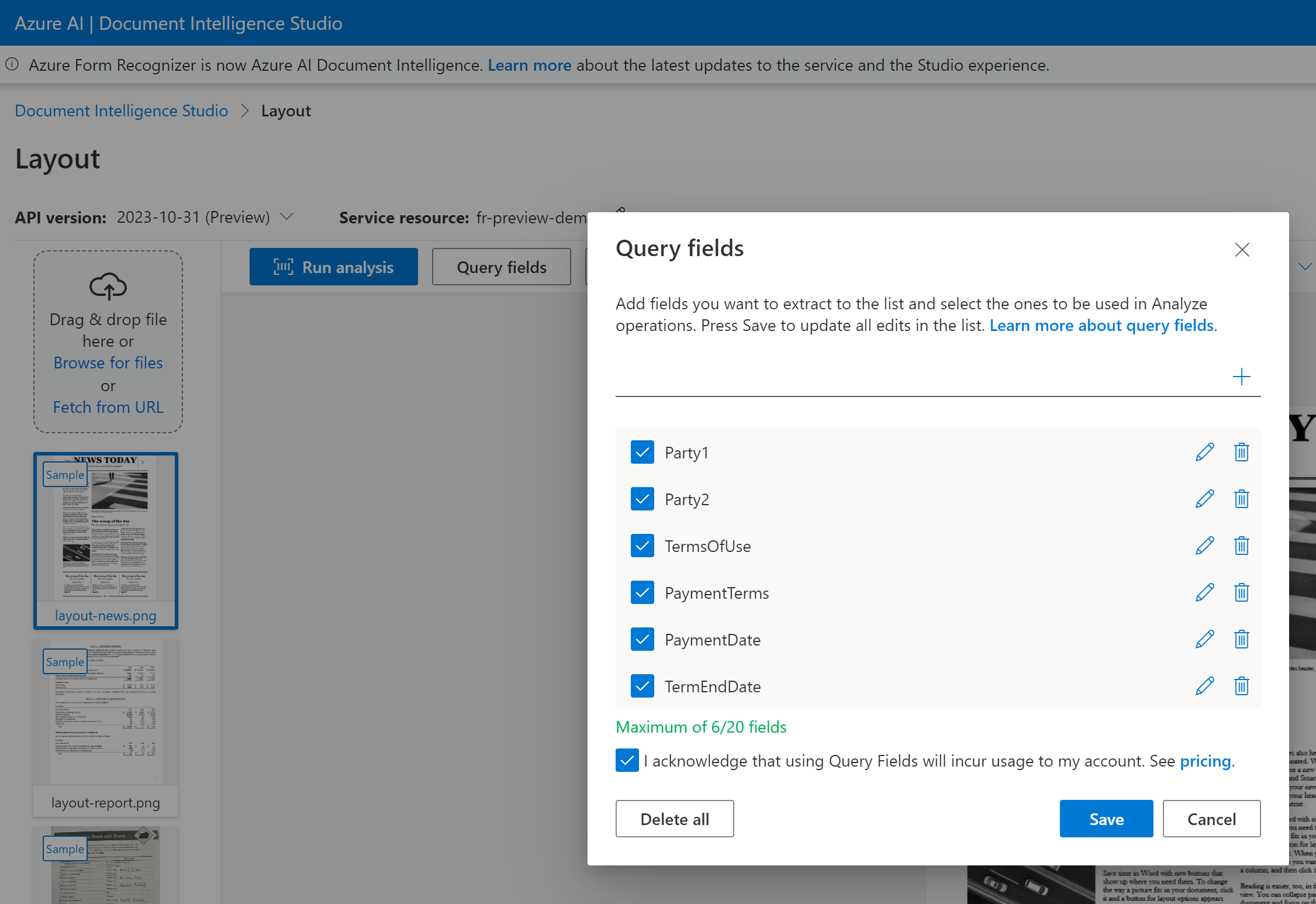
Pola zapytań to możliwość rozszerzenia schematu wyodrębnionego z dowolnego wstępnie utworzonego modelu lub zdefiniowania określonej nazwy klucza, gdy nazwa klucza jest zmienna. Aby użyć pól zapytania, ustaw funkcje na queryFields i podaj rozdzielaną przecinkami listę nazw pól we queryFields właściwości .
Analiza dokumentów obsługuje teraz wyodrębnianie pól zapytań. Wyodrębnianie pól zapytania umożliwia dodawanie pól do procesu wyodrębniania przy użyciu żądania zapytania bez konieczności dodawania trenowania.
Użyj pól zapytania, gdy musisz rozszerzyć schemat wstępnie utworzonego lub niestandardowego modelu lub wyodrębnić kilka pól z danymi wyjściowymi układu.
Pola zapytań to funkcja dodatku w warstwie Premium. Aby uzyskać najlepsze wyniki, zdefiniuj pola, które chcesz wyodrębnić przy użyciu wielkości liter wielbłądu lub nazw pól wielkości liter Pascal dla nazw pól wielo wyrazów.
Pola zapytania obsługują maksymalnie 20 pól na żądanie. Jeśli dokument zawiera wartość pola, zwracane jest pole i wartość.
Ta wersja ma nową implementację możliwości pól zapytań, która jest wyceniona poniżej wcześniejszej implementacji i powinna zostać zweryfikowana.
Uwaga
Wyodrębnianie pól zapytań programu Document Intelligence Studio jest obecnie dostępne w interfejsie API układów i wstępnie utworzonych modeli 2024-02-29-preview2023-10-31-preview oraz nowszych wersjach z wyjątkiem US tax modeli W2, 1098 i 1099s.
Wyodrębnianie pól zapytania
W przypadku wyodrębniania pól zapytania określ pola, które chcesz wyodrębnić, a analiza dokumentów analizuje odpowiednio dokument. Oto przykład:
Jeśli przetwarzasz kontrakt w programie Document Intelligence Studio, użyj wersji 2024-02-29-preview lub 2023-10-31-preview :
Możesz przekazać listę etykiet pól, takich jak Party1, Party2, TermsOfUse, PaymentTerms, PaymentDatei TermEndDate w ramach analyze document żądania.
Analiza dokumentów umożliwia analizowanie i wyodrębnianie danych pól oraz zwracanie wartości w danych wyjściowych JSON ze strukturą.
Oprócz pól zapytania odpowiedź zawiera tekst, tabele, znaczniki wyboru i inne istotne dane.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/invoice/simple-invoice.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.QUERY_FIELDS], # Specify which add-on capabilities to enable.
query_fields=["Address", "InvoiceNumber"], # Set the features and provide a comma-separated list of field names.
)
result: AnalyzeResult = poller.result()
print("Here are extra fields in result:\n")
if result.documents:
for doc in result.documents:
if doc.fields and doc.fields["Address"]:
print(f"Address: {doc.fields['Address'].value_string}")
if doc.fields and doc.fields["InvoiceNumber"]:
print(f"Invoice number: {doc.fields['InvoiceNumber'].value_string}")
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.