Analizowanie odpowiedzi interfejsu API dokumentu
Ta zawartość dotyczy: ![]() wersja 4.0 (wersja zapoznawcza)
wersja 4.0 (wersja zapoznawcza) ![]() w wersji 3.1 (OGÓLNA) 3.0 (ogólna dostępność)
w wersji 3.1 (OGÓLNA) 3.0 (ogólna dostępność) ![]()
W tym artykule przyjrzyjmy się różnym obiektom zwracanym w ramach AnalyzeDocument odpowiedzi i sposobom używania odpowiedzi interfejsu API analizy dokumentów w aplikacjach.
Analizowanie żądania dokumentu
Interfejsy API analizy dokumentów analizują obrazy, pliki PDF i inne pliki dokumentów w celu wyodrębniania i wykrywania różnych elementów, układu, stylu i semantyki. Operacja analizowania to asynchroniczny interfejs API. Przesyłanie dokumentu zwraca nagłówek Operation-Location zawierający adres URL do sondowania pod kątem ukończenia. Po pomyślnym zakończeniu żądania analizy odpowiedź zawiera elementy opisane w wyodrębnieniu danych modelu.
Elementy odpowiedzi
Elementy zawartości to podstawowe elementy tekstowe wyodrębnione z dokumentu.
Elementy układu grupuje elementy zawartości w jednostki strukturalne.
Elementy stylu opisują czcionkę i język elementów zawartości.
Elementy semantyczne przypisują znaczenie do określonych elementów zawartości.
Wszystkie elementy zawartości są grupowane według stron określonych przez numer strony (1indeksowany). Są one również sortowane według kolejności czytania, która rozmieszcza semantycznie ciągłe elementy razem, nawet jeśli przecinają granice linii lub kolumny. Gdy kolejność odczytu między akapitami i innymi elementami układu jest niejednoznaczna, usługa zazwyczaj zwraca zawartość w kolejności od lewej do prawej, od góry do dołu.
Uwaga
Obecnie analiza dokumentów nie obsługuje kolejności odczytywania po granicach stron. Znaczniki zaznaczenia nie są umieszczone w otaczających wyrazach.
Właściwość zawartości najwyższego poziomu zawiera łączenie wszystkich elementów zawartości w kolejności odczytu. Wszystkie elementy określają swoją pozycję w kolejności czytnika za pośrednictwem zakresów w tym ciągu zawartości. Zawartość niektórych elementów nie zawsze jest ciągła.
Analizowanie odpowiedzi
Odpowiedź analizy dla każdego interfejsu API zwraca różne obiekty. Odpowiedzi interfejsu API zawierają elementy z modeli składników, jeśli ma to zastosowanie.
| Zawartość odpowiedzi | opis | interfejs API |
|---|---|---|
| Stron | Wyrazy, wiersze i zakresy rozpoznawane z każdej strony dokumentu wejściowego. | Odczytywanie, układ, dokument ogólny, wstępnie utworzone i modele niestandardowe |
| Ustępów | Zawartość rozpoznawana jako akapity. | Odczytywanie, układ, dokument ogólny, wstępnie utworzone i modele niestandardowe |
| Style | Zidentyfikowane właściwości elementu tekstowego. | Odczytywanie, układ, dokument ogólny, wstępnie utworzone i modele niestandardowe |
| Języki | Zidentyfikowany język skojarzony z każdym zakresem wyodrębnionego tekstu | Przeczytaj |
| Tabel | Zawartość tabelaryczna zidentyfikowana i wyodrębniona z dokumentu. Tabele odnoszą się do tabel zidentyfikowanych przez wstępnie wytrenowany model układu. Zawartość oznaczona jako tabele jest wyodrębniona jako pola strukturalne w obiekcie dokumentów. | Układ, Ogólny dokument, Faktura i Modele niestandardowe |
| Dane | Ilustracje (wykresy, obrazy) zidentyfikowane i wyodrębnione z dokumentu, udostępniając wizualne reprezentacje, które ułatwiają zrozumienie złożonych informacji. | Model układu |
| Sekcje | Hierarchiczna struktura dokumentów zidentyfikowana i wyodrębniona z dokumentu. Sekcja lub podsekcja z odpowiednimi elementami (akapit, tabela, rysunek) dołączonymi do niego. | Model układu |
| keyValuePairs | Pary klucz-wartość rozpoznawane przez wstępnie wytrenowany model. Klucz jest zakresem tekstu z dokumentu ze skojarzona wartością. | Ogólne modele dokumentów i faktur |
| Dokumentów | Rozpoznane pola są zwracane w słowniku fields na liście dokumentów |
Wstępnie utworzone modele, Modele niestandardowe. |
Aby uzyskać więcej informacji na temat obiektów zwracanych przez każdy interfejs API, zobacz wyodrębnianie danych modelu.
Właściwości elementu
Obejmuje
Zakresy określają logiczną pozycję każdego elementu w ogólnej kolejności odczytu, z każdym zakresem określającym przesunięcie i długość znaku do właściwości ciągu zawartości najwyższego poziomu. Domyślnie przesunięcia i długości znaków są zwracane w jednostkach znaków postrzeganych przez użytkownika (nazywanych grapheme clusters również elementami tekstowymi). Aby obsłużyć różne środowiska programistyczne korzystające z różnych jednostek znaków, użytkownik może określić stringIndexIndex parametr zapytania, aby zwrócić przesunięcia i długości zakresu w punktach kodu Unicode (Python 3) lub JEDNOSTKAch kodu UTF16 (Java, JavaScript, .NET), jak również. Aby uzyskać więcej informacji, zobacz obsługa języków/emoji.
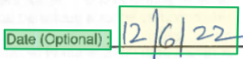
Region ograniczenia
Regiony ograniczenia opisują położenie wizualne każdego elementu w pliku. Gdy elementy nie są wizualnie ciągłe lub krzyżowe strony (tabele), pozycje większości elementów są opisywane za pośrednictwem tablicy regionów ograniczenia. Każdy region określa numer strony (1indeksowany) i graniczący wielokąt. Wielokąt ograniczenia jest opisany jako sekwencja punktów, zgodnie z ruchem wskazówek zegara względem naturalnej orientacji elementu. W przypadku czworokątów punkty wykresu to lewy górny, prawy górny, prawy dolny i dolny lewy róg. Każdy punkt reprezentuje jego współrzędną x, y w jednostce strony określonej przez właściwość jednostki. Ogólnie rzecz biorąc, jednostka miary dla obrazów to piksele, podczas gdy pliki PDF używają cali.
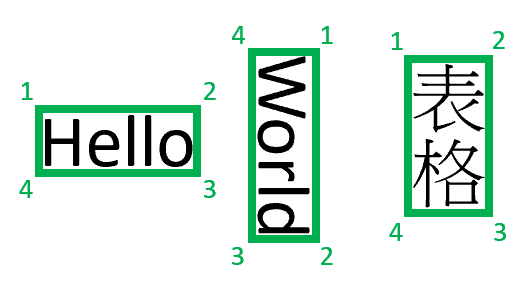
Uwaga
Obecnie analiza dokumentów zwraca tylko 4-wierzchołki czworokątne jako granice wielokątów. Przyszłe wersje mogą zwracać inną liczbę punktów, aby opisać bardziej złożone kształty, takie jak krzywe linie lub obrazy nie prostokątne. Regiony ograniczenia stosowane tylko do renderowanych plików, jeśli plik nie jest renderowany, regiony ograniczenia nie są zwracane. Obecnie pliki w formacie docx/xlsx/pptx/html nie są renderowane.
Elementy zawartości
Word
Wyraz jest elementem zawartości składającym się z sekwencji znaków. W przypadku analizy dokumentów wyraz jest definiowany jako sekwencja sąsiednich znaków z odstępami od siebie wyrazami. W przypadku języków, które nie używają separatorów spacji między wyrazami, każdy znak jest zwracany jako oddzielny wyraz, nawet jeśli nie reprezentuje semantycznej jednostki wyrazów.

Znaczniki zaznaczenia
Znacznik wyboru to element zawartości, który reprezentuje wizualny glyph wskazujący stan zaznaczenia. Pole wyboru jest typową formą znaków zaznaczenia. Jednak są one również reprezentowane za pośrednictwem przycisków radiowych lub komórki skrzynkowej w formie wizualnej. Stan znacznika wyboru można wybrać lub usunąć zaznaczenie z inną reprezentacją wizualną, aby wskazać stan.

Elementy układu
Linia
Wiersz jest uporządkowaną sekwencją kolejnych elementów zawartości oddzielonych spacją wizualizacji lub tymi, które są bezpośrednio sąsiadujące dla języków bez ograniczników spacji między wyrazami. Elementy zawartości w tej samej płaszczyźnie poziomej (wierszu), ale oddzielone większą niż jedną przestrzenią wizualną są najczęściej podzielone na wiele wierszy. Chociaż ta funkcja czasami dzieli semantycznie ciągłą zawartość na oddzielne wiersze, umożliwia reprezentację zawartości tekstowej podzielonej na wiele kolumn lub komórek. Linie w zapisie pionowym są wykrywane w kierunku pionowym.

Akapit
Akapit to uporządkowana sekwencja wierszy tworzących jednostkę logiczną. Zazwyczaj linie mają wspólne wyrównanie i odstępy między liniami. Akapity są często rozdzielane przez wcięcie, dodane odstępy lub punktory/numerowanie. Zawartość można przypisać tylko do pojedynczego akapitu. W dokumencie można również skojarzyć akapity z rolą funkcjonalną. Obecnie obsługiwane role obejmują nagłówek strony, stopkę strony, numer strony, tytuł, nagłówek sekcji i przypis dolny.

Strona
Strona to grupa zawartości, która zazwyczaj odpowiada jednej stronie arkusza papieru. Renderowana strona charakteryzuje się szerokością i wysokością w określonej lekcji. Ogólnie rzecz biorąc, obrazy używają pikseli, podczas gdy pliki PDF używają cala. Właściwość kąta opisuje ogólny kąt tekstu w stopniach dla stron, które można obracać.
Uwaga
W przypadku arkuszy kalkulacyjnych, takich jak program Excel, każdy arkusz jest mapowany na stronę. W przypadku prezentacji, takich jak program PowerPoint, każdy slajd jest mapowany na stronę. W przypadku formatów plików bez natywnej koncepcji stron bez renderowania, takich jak dokumenty HTML lub Word, główna zawartość pliku jest uważana za jedną stronę.
Table
Tabela organizuje zawartość w grupę komórek w układzie siatki. Wiersze i kolumny mogą być wizualnie oddzielone liniami siatki, pasowaniem kolorów lub większym odstępem. Pozycja komórki tabeli jest określana za pośrednictwem indeksów wierszy i kolumn. Komórka może obejmować wiele wierszy i kolumn.
Na podstawie położenia i stylu komórka może być klasyfikowana jako ogólna zawartość, nagłówek wiersza, nagłówek kolumny, nagłówek wycinków lub opis:
Komórka nagłówka wiersza jest zazwyczaj pierwszą komórką w wierszu opisającą inne komórki w wierszu.
Komórka nagłówka kolumny jest zazwyczaj pierwszą komórką w kolumnie, która opisuje inne komórki w kolumnie.
Wiersz lub kolumna może zawierać wiele komórek nagłówka w celu opisania zawartości hierarchicznej.
Komórka głowy wycinków jest zazwyczaj komórką w pierwszym wierszu i pierwszej pozycji kolumny. Może być pusty lub opisywać wartości w komórkach nagłówka w tym samym wierszu/kolumnie.
Komórka opisu zazwyczaj pojawia się w górnym lub dolnym obszarze tabeli, opisując ogólną zawartość tabeli. Jednak czasami może się pojawić w środku tabeli, aby podzielić tabelę na sekcje. Zazwyczaj komórki opisu obejmują wiele komórek w jednym wierszu.
Podpis tabeli określa zawartość, która wyjaśnia tabelę. Tabela może dodatkowo mieć skojarzony podpis i zestaw przypisów dolnych. W przeciwieństwie do komórki opisu podpis zwykle znajduje się poza układem siatki. Przypis dolny tabeli dodaje adnotacje do zawartości w tabeli, często oznaczone symbolem przypisu dolnego, często spotykanym poniżej siatki tabeli.
Tabele układu różnią się od pól dokumentów wyodrębnionych z danych tabelarycznych. Tabele układu są wyodrębniane z zawartości wizualizacji tabelarycznych w dokumencie bez uwzględniania semantyki zawartości. W rzeczywistości niektóre tabele układu są przeznaczone wyłącznie dla układu wizualnego i nie zawsze zawierają dane ustrukturyzowane. Metoda wyodrębniania danych strukturalnych z dokumentów z różnymi układami wizualnymi, takimi jak wyszczególnione szczegóły paragonu, zwykle wymaga znacznego przetwarzania końcowego. Ważne jest mapowanie nagłówków wierszy lub kolumn na pola ustrukturyzowane z znormalizowanymi nazwami pól. W zależności od typu dokumentu użyj wstępnie utworzonych modeli lub wytrenuj model niestandardowy w celu wyodrębnienia takiej zawartości ustrukturyzowanej. Wynikowe informacje są widoczne jako pola dokumentu. Takie wytrenowane modele mogą również obsługiwać dane tabelaryczne bez nagłówków i danych ustrukturyzowanych w formularzach nietabularnych, na przykład sekcję środowiska pracy w wznowieniu.

Dane
Ilustracje (wykresy, obrazy) w dokumentach odgrywają kluczową rolę w uzupełnianiu i ulepszaniu zawartości tekstowej, zapewniając wizualne reprezentacje, które pomagają w zrozumieniu złożonych informacji. Obiekt rysunków wykryty przez model Układu ma kluczowe właściwości, takie jak boundingRegions (lokalizacje przestrzenne rysunku na stronach dokumentu, w tym numer strony i współrzędne wielokątne, które przedstawiają granicę rysunku), spans (szczegóły zakresy tekstu związane z rysunkiem, określając ich przesunięcia i długości w tekście dokumentu. To połączenie pomaga skojarzyć rysunek z odpowiednim kontekstem tekstowym), elements (identyfikatory elementów tekstowych lub akapitów w dokumencie, które są powiązane z rysunkiem lub opisują je) i caption jeśli istnieją.
{
"figures": [
{
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Sekcje
Hierarchiczna analiza struktury dokumentów jest kluczowa w organizowaniu, zrozumieniu i przetwarzaniu obszernych dokumentów. Takie podejście ma kluczowe znaczenie dla semantycznie segmentacji długich dokumentów w celu zwiększenia zrozumienia, ułatwienia nawigacji i poprawy pobierania informacji. Pojawienie się rozszerzonej generacji pobierania (RAG) w dokumencie generowania sztucznej inteligencji podkreśla znaczenie hierarchicznej analizy struktury dokumentów. Model układu obsługuje sekcje i podsekcje w danych wyjściowych, które identyfikują relację sekcji i obiektu w każdej sekcji. Struktura hierarchiczna jest utrzymywana w elements każdej sekcji.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
Pole formularza (para wartości klucza)
Pole formularza składa się z etykiety pola (klucza) i wartości. Etykieta pola jest zazwyczaj opisowym ciągiem tekstowym opisującym znaczenie pola. Często pojawia się po lewej stronie wartości, ale może również pojawić się w obszarze lub poniżej wartości. Wartość pola zawiera wartość zawartości określonego wystąpienia pola. Wartość może zawierać wyrazy, znaczniki zaznaczenia i inne elementy zawartości. Może być również pusty w przypadku niezapełnionych pól formularza. Specjalny typ pola formularza ma wartość znacznika wyboru z etykietą pola po prawej stronie. Pole dokumentu jest podobne, ale odrębne pojęcie od ogólnych pól formularza. Etykieta pola (klucz) w polu formularza ogólnego musi być wyświetlana w dokumencie. W związku z tym nie może on zazwyczaj przechwytywać informacji, takich jak nazwa sprzedawcy w paragonie. Pola dokumentu są oznaczone etykietą i nie wyodrębniają klucza. Pola dokumentu mapować tylko wyodrębnione wartości na klucz oznaczony etykietą. Aby uzyskać więcej informacji, zobacz pola dokumentów.

Elementy stylu
Styl
Element stylu opisuje styl czcionki, który ma być stosowany do zawartości tekstowej. Zawartość jest określana za pośrednictwem zakresów w globalnej właściwości zawartości. Obecnie jedynym wykrytym stylem czcionki jest to, czy tekst jest odręczny. W miarę dodawania innych stylów tekst można opisać za pomocą wielu obiektów stylów niekonflictingowych. W przypadku kompaktowania cały tekst współużytkujący określony styl czcionki (z taką samą ufnością) jest opisywany za pośrednictwem pojedynczego obiektu stylu.
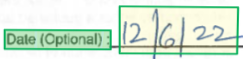
{
"confidence": 1,
"spans": [
{
"offset": 2402,
"length": 7
}
],
"isHandwritten": true
}
Język
Element języka opisuje wykryty język zawartości określonej za pośrednictwem zakresów w globalnej właściwości zawartości. Wykryty język jest określany za pośrednictwem tagu języka BCP-47, aby wskazać język podstawowy oraz opcjonalny skrypt i informacje o regionie. Na przykład angielski i tradycyjny chiński są rozpoznawane odpowiednio jako "en" i zh-Bungalow. Regionalne różnice pisowni w brytyjskim języku angielskim mogą prowadzić do wykrycia tekstu jako en-GB. Elementy języka nie obejmują tekstu bez języka dominującego (np. liczb).
Elementy semantyczne
Uwaga
Elementy semantyczne omówione tutaj dotyczą wstępnie utworzonych modeli analizy dokumentów. Modele niestandardowe mogą zwracać różne reprezentacje danych. Na przykład data i godzina zwrócona przez model niestandardowy mogą być reprezentowane we wzorcu, który różni się od standardowego formatowania ISO 8601.
Dokument
Dokument jest semantycznie kompletną jednostką. Plik może zawierać wiele dokumentów, takich jak wiele formularzy podatkowych w pliku PDF lub wiele paragonów na jednej stronie. Jednak kolejność dokumentów w pliku nie ma zasadniczo wpływu na przekazywane informacje.
Uwaga
Obecnie analiza dokumentów nie obsługuje wielu dokumentów na jednej stronie.
Typ dokumentu opisuje dokumenty współużytujące wspólny zestaw pól semantycznych reprezentowanych przez schemat ustrukturyzowany, niezależnie od szablonu wizualizacji lub układu. Na przykład wszystkie dokumenty typu "paragon" mogą zawierać nazwę sprzedawcy, datę transakcji i sumę transakcji, chociaż paragony restauracji i hotelu często różnią się wyglądem.
Element dokumentu zawiera listę rozpoznanych pól z pól określonych przez semantyczny schemat wykrytego typu dokumentu:
Pole dokumentu można wyodrębnić lub wywnioskować. Wyodrębnione pola są reprezentowane za pośrednictwem wyodrębnionej zawartości i opcjonalnie znormalizowanej wartości, jeśli można je interpretować.
Wywnioskowane pole nie ma właściwości zawartości i jest reprezentowane tylko za pośrednictwem jego wartości.
Pole tablicy nie zawiera właściwości zawartości. Zawartość może być połączona z zawartością elementów tablicy.
Pole obiektu zawiera właściwość zawartości, która określa pełną zawartość reprezentującą obiekt, który może być nadzbiorem wyodrębnionych pól podrzędnych.
Semantyczny schemat typu dokumentu jest opisywany za pośrednictwem pól, które zawiera. Każdy schemat pola jest określany za pośrednictwem nazwy kanonicznej i typu wartości. Typy wartości pól obejmują podstawowe (np. ciąg), złożone (np. adres) i typy ustrukturyzowane (np. tablica, obiekt). Typ wartości pola określa również normalizację semantyczną wykonaną w celu przekonwertowania wykrytej zawartości na reprezentację normalizacji. Normalizacja może być zależna od ustawień regionalnych.
Typy podstawowe
| Typ wartości pola | opis | Znormalizowana reprezentacja | Przykład (zawartość pola —> wartość) |
|---|---|---|---|
| string | Zwykły tekst | Tak samo jak zawartość | MerchantName: "Contoso" → "Contoso" |
| data | Data | ISO 8601 - RRRR-MM-DD | InvoiceDate: "5/7/2022" → "2022-05-07" |
| time | Czas | ISO 8601 — hh:mm:ss | TransactionTime: "19:45" → "21:45:00" |
| phoneNumber | Numer telefonu | E.164 — +{CountryCode}{Liczba subskrybentów} | Telefon służbowy: "(800) 555-7676" → "+18005557676" |
| countryRegion | Kraj/region | ISO 3166-1 alfa-3 | CountryRegion: "Stany Zjednoczone" → "USA" |
| selectionMark | Jest zaznaczona | "podpisany" lub "niepodpisany" | AcceptEula: ☑ → "selected" |
| podpis | Jest podpisany | Tak samo jak zawartość | LendeeSignature: {signature} → "signed" |
| Liczba | Liczba zmiennoprzecinkowa | Liczba zmiennoprzecinkowa | Ilość: "1.20" → 1.2 |
| integer | Liczba całkowita | 64-bitowy numer ze znakiem | Liczba: "123" → 123 |
| boolean | Wartość logiczna | prawda/fałsz | IsStatutoryEmployee: ☑ → true |
Typy złożone
Waluta: kwota waluty z opcjonalną jednostką walutową. Wartość, na przykład:
InvoiceTotal: $123.45{ "amount": 123.45, "currencySymbol": "$" }Adres: przeanalizowany adres. Na przykład:
ShipToAddress: 123 Main St., Redmond, WA 98052.{ "poBox": "PO Box 12", "houseNumber": "123", "streetName": "Main St.", "city": "Redmond", "state": "WA", "postalCode": "98052", "countryRegion": "USA", "streetAddress": "123 Main St." }
Typy ustrukturyzowane
Tablica: lista pól tego samego typu
"Items": { "type": "array", "valueArray": [ ] }Obiekt: Nazwana lista pól podrzędnych potencjalnie różnych typów
"InvoiceTotal": { "type": "currency", "valueCurrency": { "currencySymbol": "$", "amount": 110 }, "content": "$110.00", "boundingRegions": [ { "pageNumber": 1, "polygon": [ 7.3842, 7.465, 7.9181, 7.465, 7.9181, 7.6089, 7.3842, 7.6089 ] } ], "confidence": 0.945, "spans": [ { "offset": 806, "length": 7 } ] }
Następne kroki
Spróbuj przetwarzać własne formularze i dokumenty za pomocą programu Document Intelligence Studio.
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla