Model wizytówek analizy dokumentów
Ważne
Począwszy od analizy dokumentów w wersji 4.0 (wersja zapoznawcza) i w przyszłości model wizytówek (wstępnie skompilowany businessCard) jest przestarzały. Aby wyodrębnić dane z formatów wizytówek, użyj następujących elementów:
| Funkcja | version | Model ID |
|---|---|---|
| Model wizytówek | • v3.1:2023-07-31 (GA)• v3.0:2022-08-31 (GA) • wersja 2.1 (GA) |
prebuilt-businessCard |
Ta zawartość dotyczy: ![]() wersja 3.0 (GA) | Najnowsze wersje:
wersja 3.0 (GA) | Najnowsze wersje: ![]() wersja 4.0 (wersja zapoznawcza)
wersja 4.0 (wersja zapoznawcza) ![]() 3.1 | Poprzednia wersja:
3.1 | Poprzednia wersja: ![]() wersja 2.1
wersja 2.1
Ta zawartość dotyczy: ![]() wersja 2.1 | Najnowsza wersja:
wersja 2.1 | Najnowsza wersja: ![]() wersja 4.0 (wersja zapoznawcza)
wersja 4.0 (wersja zapoznawcza)
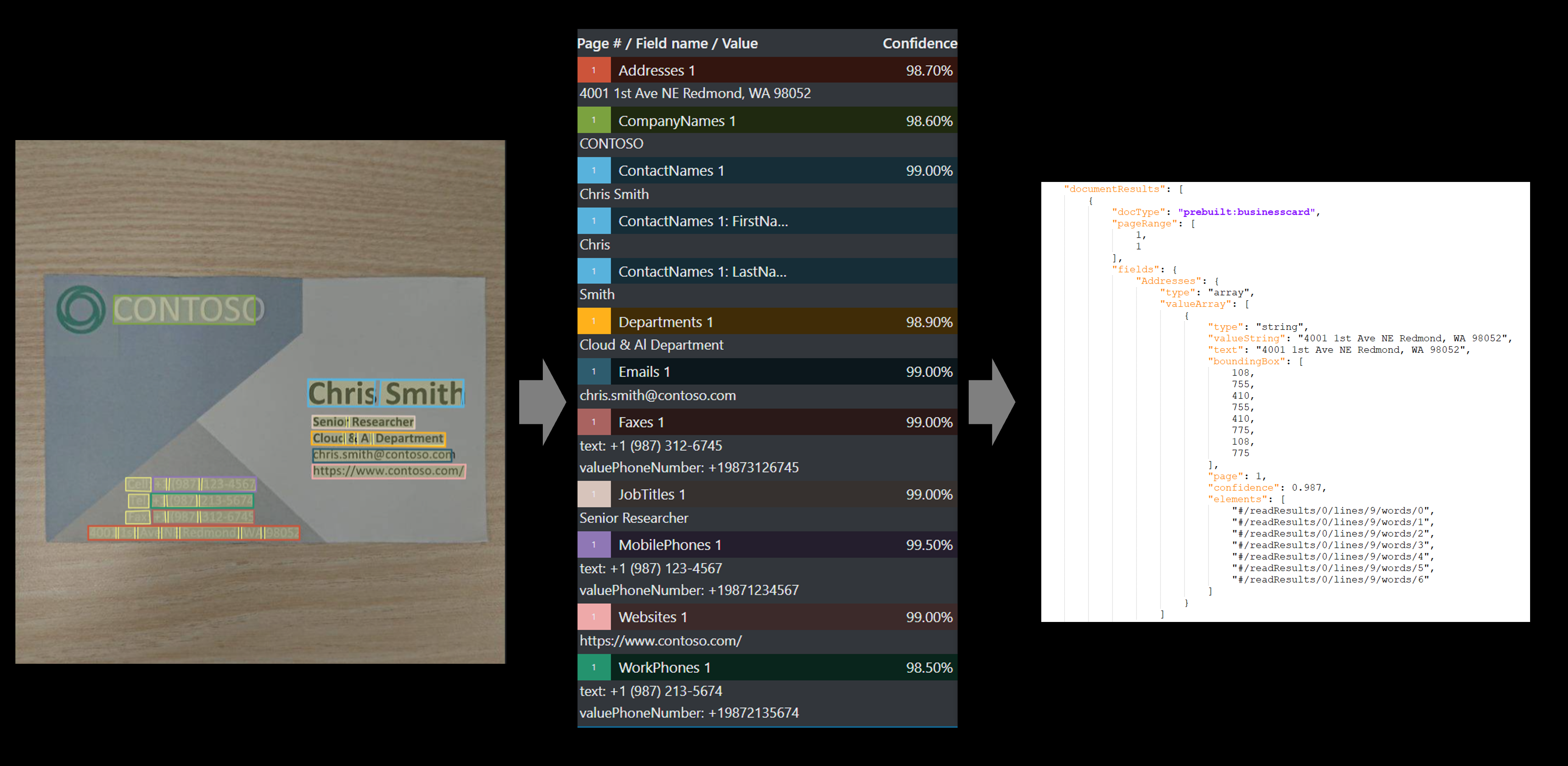
Model wizytówek analizy dokumentów łączy zaawansowane funkcje optycznego rozpoznawania znaków (OCR) z modelami uczenia głębokiego w celu analizowania i wyodrębniania danych z obrazów wizytówek. Interfejs API analizuje drukowane wizytówki; Wyodrębnia kluczowe informacje, takie jak imię, nazwisko, nazwisko, nazwa firmy, adres e-mail i numer telefonu; funkcja zwraca ustrukturyzowaną reprezentację danych JSON.
Wyodrębnianie danych wizytówki
Wizytówki to doskonały sposób reprezentowania firmy lub profesjonalisty. Logo firmy, czcionki i obrazy tła znalezione w wizytówkach pomagają promować markę firmy i odróżniać ją od innych. Stosowanie technik OCR i opartych na uczeniu maszynowym w celu zautomatyzowania skanowania wizytówek jest typowym scenariuszem przetwarzania obrazów. Systemy przedsiębiorstwa używane przez zespoły ds. sprzedaży i marketingu zwykle mają możliwość wyodrębniania danych wizytówek w celu uzyskania korzyści dla użytkowników.
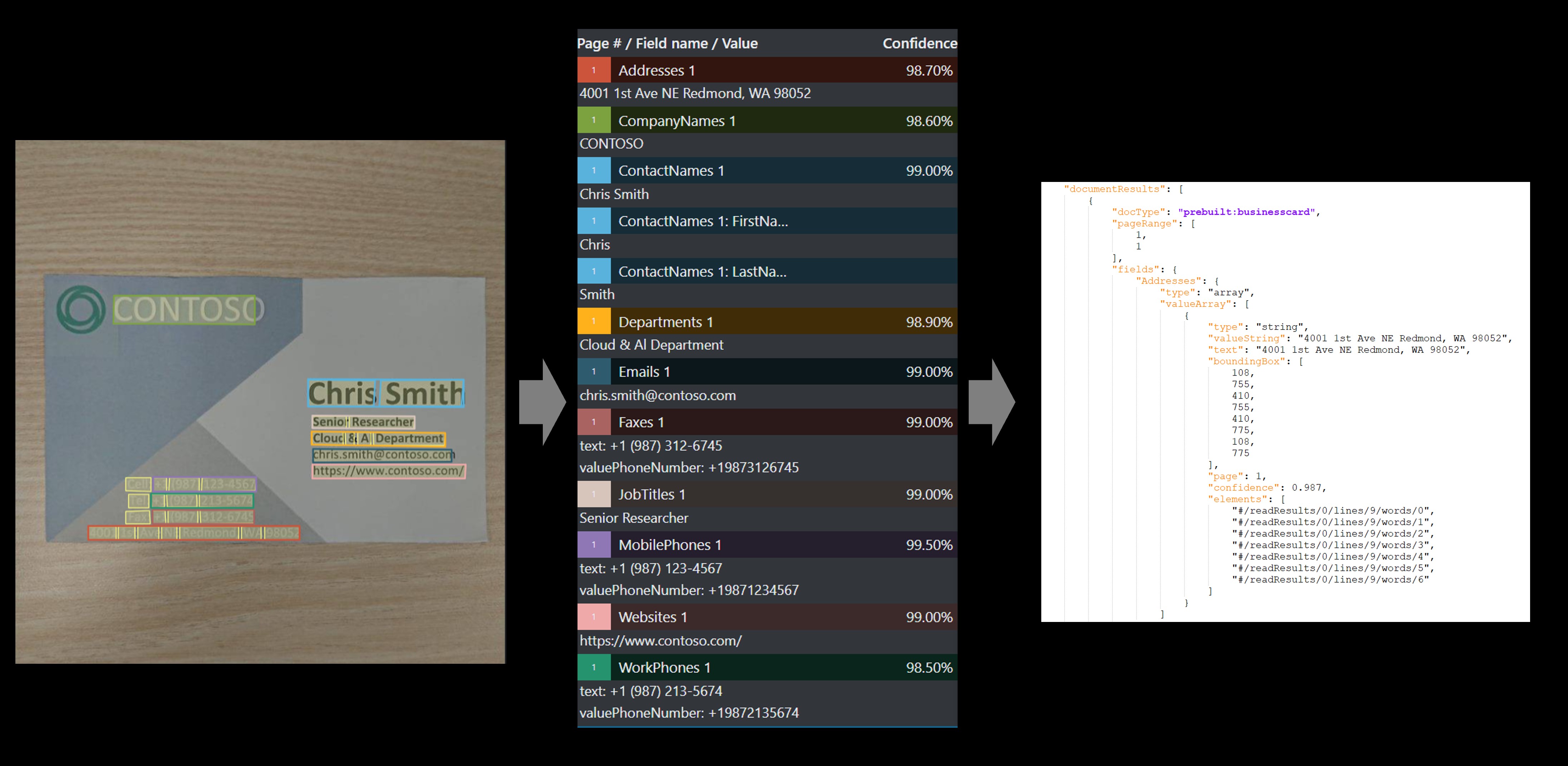
Przykładowa wizytówka przetworzona za pomocą usługi Document Intelligence Studio

Przykładowa firma przetworzona za pomocą narzędzia do etykietowania przykładowego analizy dokumentów
Opcje programowania
Analiza dokumentów w wersji 3.1:2023-07-31 (GA) obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Model wizytówek | • Document Intelligence Studio • Interfejs API REST • Zestaw SDK języka C# • Zestaw PYTHON SDK • Zestaw JAVA SDK • Zestaw SDK języka JavaScript |
wstępnie utworzona karta biznesowa |
Analiza dokumentów w wersji 3.0:2022-08-31 (GA) obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Model wizytówek | • Document Intelligence Studio • Interfejs API REST • Zestaw SDK języka C# • Zestaw PYTHON SDK • Zestaw JAVA SDK • Zestaw SDK języka JavaScript |
wstępnie utworzona karta biznesowa |
Analiza dokumentów w wersji 2.1 (GA) obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby |
|---|---|
| Model wizytówek | • Narzędzie do etykietowania analizy dokumentów • Interfejs API REST • Zestaw SDK biblioteki klienta • Kontener docker analizy dokumentów |
Wypróbuj wyodrębnianie danych wizytówek
Zobacz, w jaki sposób dane, w tym nazwa, stanowisko, adres, adres e-mail i nazwa firmy, są wyodrębniane z wizytówek. Potrzebne są następujące zasoby:
Subskrypcja platformy Azure — możesz bezpłatnie utworzyć subskrypcję platformy Azure
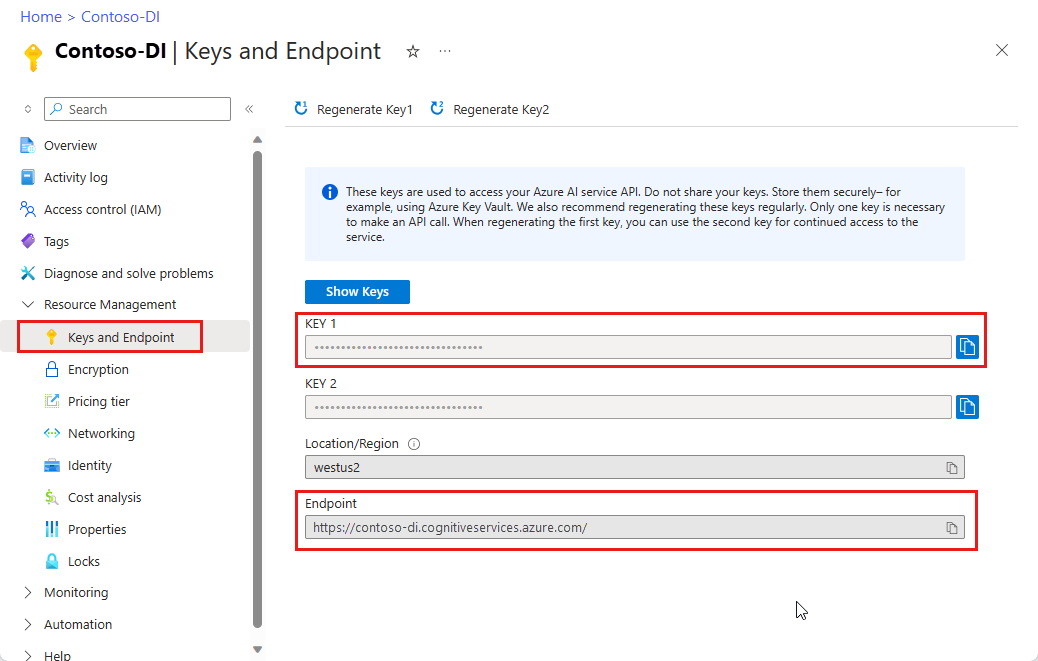
Wystąpienie analizy dokumentów w witrynie Azure Portal. Aby wypróbować usługę, możesz użyć bezpłatnej warstwy cenowej (
F0). Po wdrożeniu zasobu wybierz pozycję Przejdź do zasobu , aby uzyskać klucz i punkt końcowy.
Document Intelligence Studio
Uwaga
Program Document Intelligence Studio jest dostępny z interfejsami API w wersji 3.1 i 3.0.

Narzędzie do etykietowania przykładowego analizy dokumentów
Przejdź do narzędzia przykładowego analizy dokumentów.
Na stronie głównej przykładowego narzędzia wybierz kafelek Użyj wstępnie utworzonego modelu, aby pobrać dane .
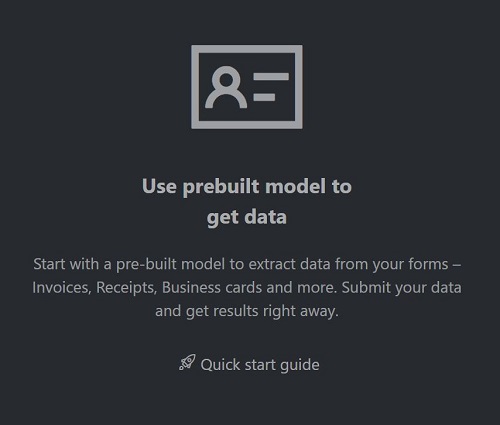
Wybierz typ formularza do przeanalizowania z menu rozwijanego.
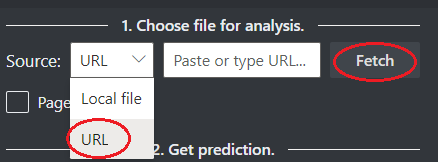
Wybierz adres URL pliku, który chcesz przeanalizować z poniższych opcji:
- Przykładowy dokument faktury.
- Przykładowy dokument o identyfikatorze.
- Przykładowy obraz potwierdzenia.
- Przykładowy obraz wizytówki.
W polu Źródło wybierz pozycję Adres URL z menu rozwijanego, wklej wybrany adres URL i wybierz przycisk Pobierz.
W polu Punkt końcowy usługi Analizy dokumentów wklej punkt końcowy uzyskany w ramach subskrypcji analizy dokumentów.
W polu klucza wklej klucz uzyskany z zasobu analizy dokumentów.
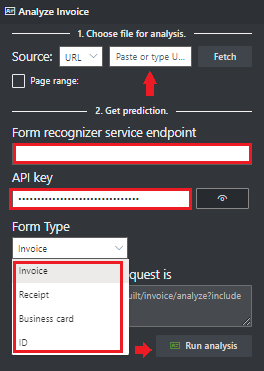
Wybierz pozycję Uruchom analizę. Narzędzie do etykietowania przykładowego analizy dokumentów wywołuje interfejs API analizy wstępnie utworzonej i analizuje dokument.
Wyświetl wyniki — zobacz wyodrębnione pary klucz-wartość, elementy wiersza, wyróżniony tekst wyodrębniony i wykryte tabele.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Uwaga
Przykładowe narzędzie etykietowania nie obsługuje formatu pliku BMP. Jest to ograniczenie narzędzia, a nie usługi analizy dokumentów.
Wymagania dotyczące danych wejściowych
Obsługiwane formaty plików:
Model PDF Obraz: JPEG/JPG, ,BMPPNG, ,TIFFHEIFMicrosoft Office:
Word (), Excel (XLSXDOCX), PowerPoint (PPTX), HTMLPrzeczytaj ✔ ✔ ✔ Układ ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Dokument ogólny ✔ ✔ Wstępnie utworzona ✔ ✔ Niestandardowe wyodrębnianie ✔ ✔ Klasyfikacja niestandardowa ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron (w przypadku subskrypcji warstwy Bezpłatna przetwarzane są tylko pierwsze dwie strony).
Rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i
4MB za bezpłatną (F0).Wymiary obrazu muszą mieć od 50 pikseli x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Minimalna wysokość tekstu do wyodrębnienia to 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada tekstowi
8punktowemu na 150 kropek na cal (DPI).W przypadku trenowania modelu niestandardowego maksymalna liczba stron dla danych szkoleniowych wynosi 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
W przypadku trenowania niestandardowego modelu wyodrębniania łączny rozmiar danych treningowych wynosi 50 MB dla modelu szablonu i
1GB dla modelu neuronowego.W przypadku trenowania niestandardowego modelu klasyfikacji całkowity rozmiar danych treningowych wynosi
1GB z maksymalnie 10 000 stron. W przypadku wersji 2024-07-31-preview i nowszych łączny rozmiar danych treningowych wynosi2GB z maksymalnie 10 000 stron.
- Obsługiwane formaty plików: JPEG, PNG, PDF i TIFF
- Przetwarzane są pliki PDF i TIFF, maksymalnie 2000 stron. W przypadku subskrybentów warstwy Bezpłatna przetwarzane są tylko dwie pierwsze strony.
- Rozmiar pliku musi być mniejszy niż 50 MB i wymiary co najmniej 50 x 50 pikseli i maksymalnie 10 000 x 10 000 pikseli.
Obsługiwane języki i ustawienia regionalne
Aby uzyskać pełną listę obsługiwanych języków, zobacz naszą stronę Pomocy technicznej języka.
Wyodrębnianie pól
| Nazwisko | Pisz | Opis | Standardowe dane wyjściowe |
|---|---|---|---|
| ContactNames | Tablica obiektów | Nazwa kontaktu | |
| FirstName | String | Imię (podane) imię i nazwisko kontaktu | |
| LastName | String | Nazwisko (rodzina) kontaktu | |
| Nazwy firmy | Tablica ciągów | Nazwa firmy | |
| Oddziały | Tablica ciągów | Dział lub organizacja kontaktu | |
| Tytuły zadań | Tablica ciągów | Wymieniony tytuł stanowiska kontaktu | |
| Wiadomości e-mail | Tablica ciągów | Kontaktowy adres e-mail | |
| Witryny internetowe | Tablica ciągów | Witryna internetowa firmy | |
| Adresy | Tablica ciągów | Adres wyodrębniony z wizytówki | |
| Telefony komórkowe | Tablica numerów telefonów | Numer telefonu komórkowego z wizytówki | +1 xxx xxx xxxx |
| Faksy | Tablica numerów telefonów | Numer telefonu faksu od wizytówki | +1 xxx xxx xxxx |
| Telefony służbowe | Tablica numerów telefonów | Numer telefonu służbowego z wizytówki | +1 xxx xxx xxxx |
| Inne telefony | Tablica numerów telefonów | Inny numer telefonu od wizytówki | +1 xxx xxx xxxx |
Wyodrębnione pola
| Nazwisko | Pisz | Opis | Tekst |
|---|---|---|---|
| ContactNames | tablica obiektów | Nazwa kontaktu wyodrębniona z wizytówki | [{ "FirstName": "John", "LastName": "Doe" }] |
| FirstName | string | Imię (podane) imię i nazwisko kontaktu | "Jan" |
| LastName | string | Nazwisko (rodzina) kontaktu | "Doe" |
| Nazwy firmy | tablica ciągów | Nazwa firmy wyodrębniona z wizytówki | ["Contoso"] |
| Oddziały | tablica ciągów | Dział lub organizacja kontaktu | ["R&D"] |
| Tytuły zadań | tablica ciągów | Wymieniony tytuł stanowiska kontaktu | ["Inżynier oprogramowania"] |
| Wiadomości e-mail | tablica ciągów | Kontaktowa wiadomość e-mail wyodrębniona z wizytówki | [""johndoe@contoso.com] |
| Witryny internetowe | tablica ciągów | Witryna internetowa wyodrębniona z wizytówki | ["https://www.contoso.com"] |
| Adresy | tablica ciągów | Adres wyodrębniony z wizytówki | ["123 Main Street, Redmond, Waszyngton 98052"] |
| Telefony komórkowe | tablica numerów telefonów | Numer telefonu komórkowego wyodrębniony z wizytówki | ["+19876543210"] |
| Faksy | tablica numerów telefonów | Numer telefonu faksu wyodrębniony z wizytówki | ["+19876543211"] |
| Telefony służbowe | tablica numerów telefonów | Numer telefonu służbowego wyodrębniony z wizytówki | ["+19876543231"] |
| Inne telefony | tablica numerów telefonów | Inny numer telefonu wyodrębniony z wizytówki | ["+19876543233"] |
Obsługiwane ustawienia regionalne
Wstępnie utworzone wizytówki w wersji 2.1 obsługują następujące ustawienia regionalne:
- en-us
- en-au
- en-ca
- en-gb
- en-in
Przewodnik migracji i interfejs API REST w wersji 3.1
- Postępuj zgodnie z naszym przewodnikiem migracji do analizy dokumentów w wersji 3.1, aby dowiedzieć się, jak używać wersji 3.0 w aplikacjach i przepływach pracy.
Następne kroki
Spróbuj przetwarzać własne formularze i dokumenty za pomocą programu Document Intelligence Studio
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.
Spróbuj przetwarzać własne formularze i dokumenty za pomocą narzędzia do etykietowania przykładowego analizy dokumentów
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.