Pobieranie rozszerzonej generacji za pomocą analizy dokumentów sztucznej inteligencji platformy Azure
Ta zawartość dotyczy: ![]() wersja 4.0 (wersja zapoznawcza)
wersja 4.0 (wersja zapoznawcza)
Wprowadzenie
Generowanie rozszerzonej generacji (RAG, Retrieval-Augmented Generation) to wzorzec projektowy, który łączy wstępnie wytrenowany model dużego języka (LLM), taki jak ChatGPT z zewnętrznym systemem pobierania danych w celu wygenerowania rozszerzonej odpowiedzi zawierającej nowe dane poza oryginalnymi danymi treningowymi. Dodanie systemu pobierania informacji do aplikacji umożliwia czatowanie z dokumentami, generowanie urzekającej zawartości i uzyskiwanie dostępu do możliwości modeli usługi Azure OpenAI dla danych. Masz również większą kontrolę nad danymi używanymi przez llM, ponieważ formułuje odpowiedź.
Model układu analizy dokumentów to zaawansowany interfejs API analizy dokumentów oparty na uczeniu maszynowym. Model układu oferuje kompleksowe rozwiązanie umożliwiające zaawansowane funkcje wyodrębniania zawartości i analizy struktury dokumentów. Model Układu umożliwia łatwe wyodrębnianie tekstu i elementów strukturalnych w celu dzielenia dużych treści tekstu na mniejsze, znaczące fragmenty na podstawie zawartości semantycznej, a nie dowolnych podziałów. Wyodrębnione informacje mogą być wygodnie wyprowadzane do formatu Markdown, co umożliwia zdefiniowanie strategii fragmentowania semantycznego na podstawie podanych bloków konstrukcyjnych.
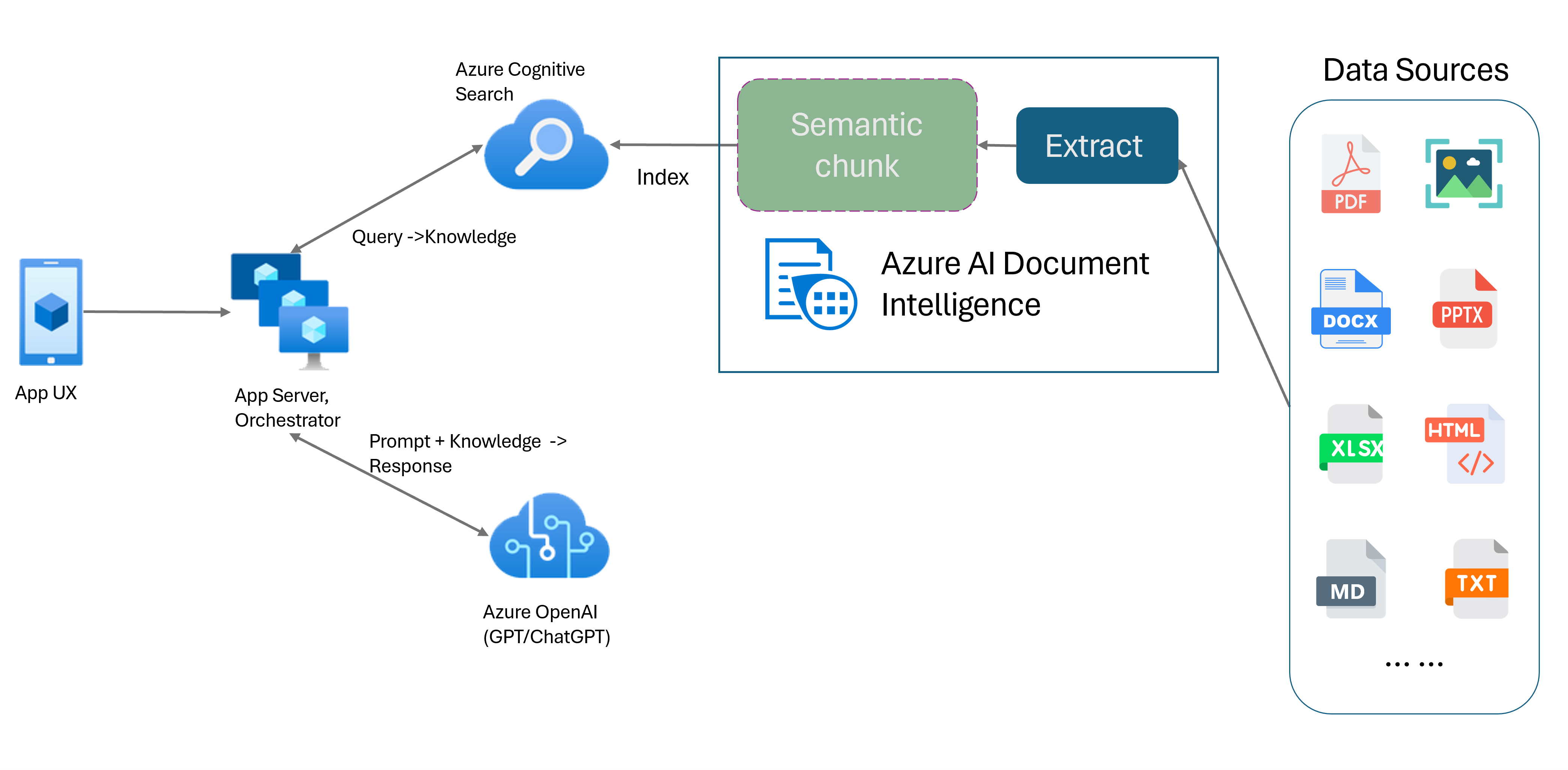
Fragmentowanie semantyczne
Długie zdania są trudne dla aplikacji przetwarzania języka naturalnego (NLP). Szczególnie, gdy składają się one z wielu klauzul, złożonych fraz czasowników lub czasowników, klauzul względnych i grupowania nawiasów. Podobnie jak w przypadku człowieka, system NLP musi również pomyślnie śledzić wszystkie przedstawione zależności. Celem semantycznego fragmentowania jest znalezienie semantycznie spójnych fragmentów reprezentacji zdania. Te fragmenty można następnie przetwarzać niezależnie i ponownie połączyć jako semantyczne reprezentacje bez utraty informacji, interpretacji lub istotności semantycznej. Nieodłączne znaczenie tekstu jest używane jako przewodnik dla procesu fragmentowania.
Strategie fragmentowania danych tekstowych odgrywają kluczową rolę w optymalizacji odpowiedzi RAG i wydajności. Stałe rozmiary i semantyka to dwie odrębne metody fragmentowania:
Fragmentowanie o stałym rozmiarze. Większość strategii fragmentowania używanych obecnie w programie RAG opiera się na segmentach tekstu o poprawionym rozmiarze znanym jako fragmenty. Fragmentowanie o stałym rozmiarze jest szybkie, łatwe i skuteczne w przypadku tekstu, który nie ma silnej struktury semantycznej, takiej jak dzienniki i dane. Jednak nie jest zalecane w przypadku tekstu, który wymaga semantycznego zrozumienia i dokładnego kontekstu. Stały charakter okna może spowodować zerwanie wyrazów, zdań lub akapitów utrudniających zrozumienie i zakłócanie przepływu informacji i zrozumienia.
Fragmentowanie semantyczne. Ta metoda dzieli tekst na fragmenty na podstawie semantycznego zrozumienia. Granice dzielenia koncentrują się na temacie zdań i używają znaczących zasobów obliczeniowych algorytmicznie złożonych. Jednak ma on wyraźną zaletę utrzymania spójności semantycznej w poszczególnych fragmentach. Jest to przydatne w przypadku podsumowywania tekstu, analizy tonacji i zadań klasyfikacji dokumentów.
Semantyczne fragmentowanie z modelem układu analizy dokumentów
Markdown to ustrukturyzowany i sformatowany język znaczników oraz popularne dane wejściowe umożliwiające semantyczne fragmentowanie w generacji RAG (generowanie rozszerzonej pobierania). Możesz użyć zawartości języka Markdown z modelu układu, aby podzielić dokumenty na podstawie granic akapitu, utworzyć określone fragmenty dla tabel i dostosować strategię fragmentowania, aby poprawić jakość wygenerowanych odpowiedzi.
Zalety korzystania z modelu Układu
Uproszczone przetwarzanie. Możesz analizować różne typy dokumentów, takie jak cyfrowe i zeskanowane pliki PDF, obrazy, pliki pakietu Office (docx, xlsx, pptx) i HTML, przy użyciu tylko jednego wywołania interfejsu API.
Skalowalność i jakość sztucznej inteligencji. Model układu jest wysoce skalowalny w funkcji optycznego rozpoznawania znaków (OCR), wyodrębniania tabel i analizy struktury dokumentów. Obsługuje 309 języków drukowanych i 12 języków odręcznych, co dodatkowo zapewnia wysokiej jakości wyniki oparte na funkcjach sztucznej inteligencji.
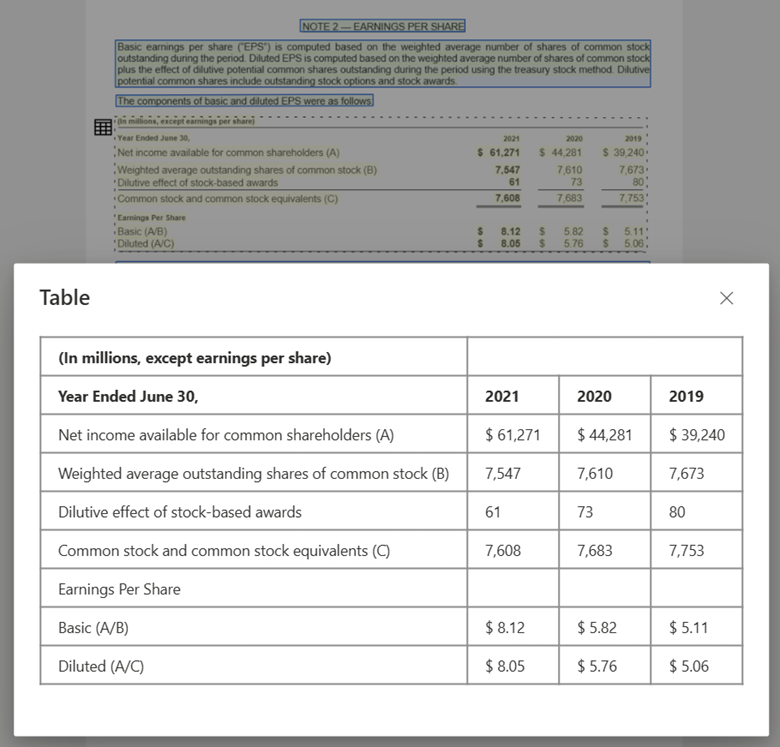
Zgodność dużego modelu językowego (LLM). Formatowane dane wyjściowe modelu układu Markdown są przyjazne dla języka LLM i ułatwiają bezproblemową integrację z przepływami pracy. Możesz przekształcić dowolną tabelę w dokumencie w format markdown i uniknąć obszernego analizowania dokumentów, aby lepiej zrozumieć funkcję LLM.
Obraz tekstowy przetwarzany za pomocą programu Document Intelligence Studio i danych wyjściowych do języka MarkDown przy użyciu modelu układu

Obraz tabeli przetworzony za pomocą programu Document Intelligence Studio przy użyciu modelu układu
Rozpocznij
Model układu analizy dokumentów 2024-02-29-preview i 2023-10-31-preview obsługuje następujące opcje programowania:
Wszystko gotowe do rozpoczęcia?
Document Intelligence Studio
Aby rozpocząć pracę, możesz skorzystać z przewodnika Szybki start dotyczącego programu Document Intelligence Studio. Następnie możesz zintegrować funkcje analizy dokumentów z własną aplikacją przy użyciu udostępnionego przykładowego kodu.
Zacznij od modelu Układu. Musisz wybrać następujące opcje analizy, aby użyć programu RAG w studio:
**Required**- Uruchom zakres analizy → bieżący dokument.
- Zakres stron → wszystkie strony.
- Styl formatu danych wyjściowych → markdown.
**Optional**- Możesz również wybrać odpowiednie opcjonalne parametry wykrywania.
Wybierz pozycję Zapisz.
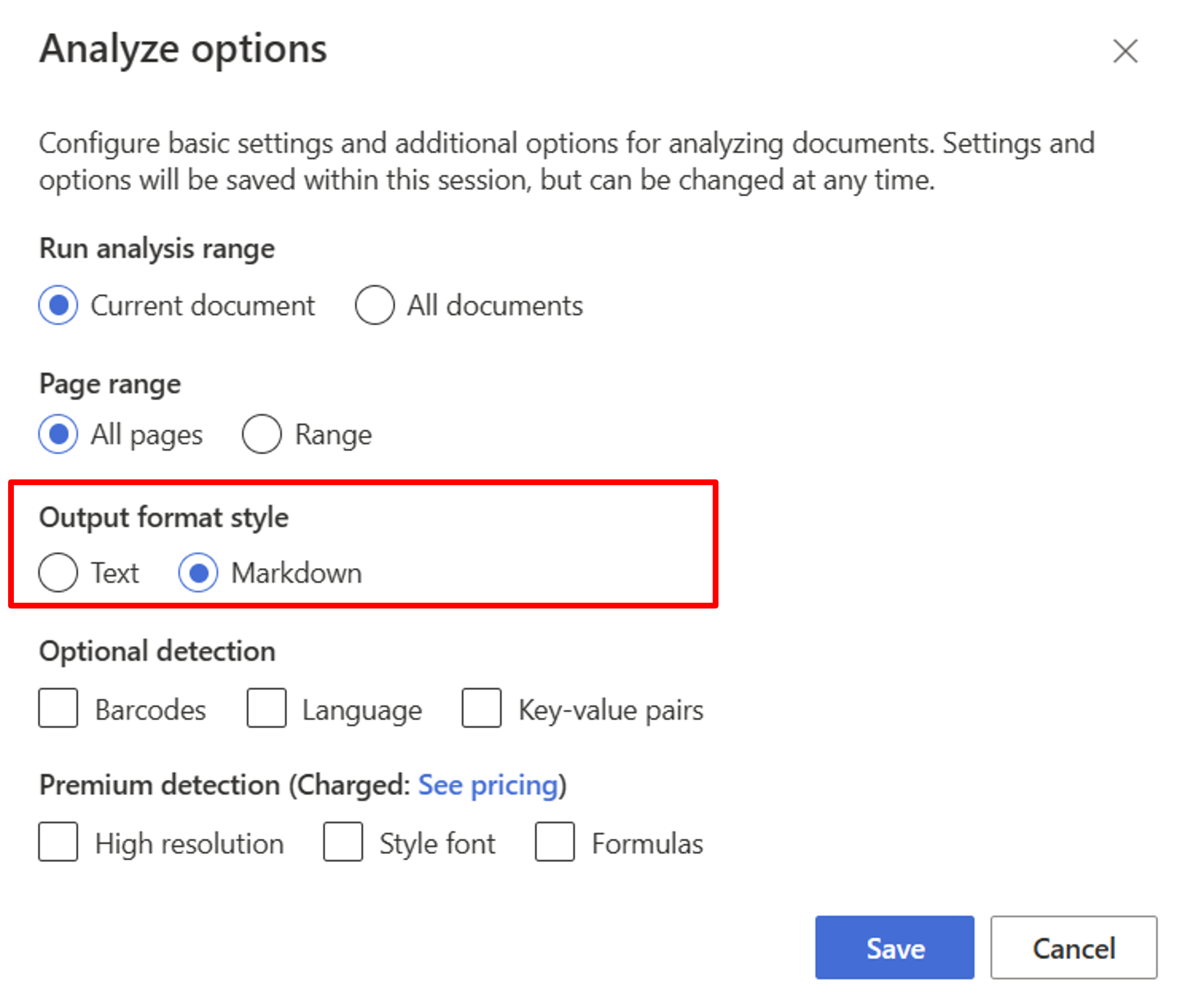
Wybierz przycisk Uruchom analizę, aby wyświetlić dane wyjściowe.

Zestaw SDK lub interfejs API REST
Możesz skorzystać z przewodnika Szybki start dotyczącego analizy dokumentów dla preferowanego zestawu SDK języka programowania lub interfejsu API REST. Użyj modelu układu, aby wyodrębnić zawartość i strukturę z dokumentów.
Możesz również zapoznać się z repozytoriami GitHub, aby zapoznać się z przykładami kodu i wskazówkami dotyczącymi analizowania dokumentu w formacie danych wyjściowych języka Markdown.
Kompilowanie czatu dokumentu za pomocą fragmentów semantycznych
Usługa Azure OpenAI na danych umożliwia uruchamianie obsługiwanego czatu na dokumentach. Usługa Azure OpenAI na danych stosuje model układu analizy dokumentów w celu wyodrębniania i analizowania danych dokumentów przez fragmentowanie długiego tekstu na podstawie tabel i akapitów. Możesz również dostosować strategię fragmentowania przy użyciu przykładowych skryptów usługi Azure OpenAI znajdujących się w naszym repozytorium GitHub.
Usługa Azure AI Document Intelligence jest teraz zintegrowana z aplikacją LangChain jako jeden z modułów ładujących dokumenty. Służy do łatwego ładowania danych i danych wyjściowych do formatu Markdown. Aby uzyskać więcej informacji, zobacz nasz przykładowy kod , który przedstawia prosty pokaz wzorca RAG z usługą Azure AI Document Intelligence jako modułem ładujący dokumentów i usługą Azure Search jako modułem pobierania w języku LangChain.
Przykładowy kod akceleratora rozwiązań danych na czacie przedstawia przykładowy wzorzec RAG kompleksowej linii bazowej. Używa usługi Azure AI Search jako narzędzia pobierania i analizy dokumentów usługi Azure AI na potrzeby ładowania i semantycznego fragmentowania dokumentów.
Przypadek użycia
Jeśli szukasz określonej sekcji w dokumencie, możesz użyć fragmentów semantycznych, aby podzielić dokument na mniejsze fragmenty w oparciu o nagłówki sekcji, pomagając znaleźć sekcję, której szukasz szybko i łatwo:
# Using SDK targeting 2024-02-29-preview or 2023-10-31-preview, make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
Następne kroki
Dowiedz się więcej o usłudze Azure AI Document Intelligence.
Dowiedz się, jak przetwarzać własne formularze i dokumenty za pomocą programu Document Intelligence Studio.
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla