Tworzenie i trenowanie niestandardowego modelu klasyfikacji
Ta zawartość dotyczy:![]() wersja 4.0 (wersja zapoznawcza) | Poprzednie wersje:
wersja 4.0 (wersja zapoznawcza) | Poprzednie wersje: ![]() v3.1 (GA) v3.0 (GA)
v3.1 (GA) v3.0 (GA) ![]()
Ważne
Niestandardowy model klasyfikacji jest obecnie w publicznej wersji zapoznawczej. Funkcje, podejścia i procesy mogą ulec zmianie przed ogólną dostępnością na podstawie opinii użytkowników.
Niestandardowe modele klasyfikacji mogą klasyfikować każdą stronę w pliku wejściowym, aby zidentyfikować co najmniej jeden dokument w obrębie. Modele klasyfikatora mogą również identyfikować wiele dokumentów lub wiele wystąpień pojedynczego dokumentu w pliku wejściowym. Niestandardowe modele analizy dokumentów wymagają nawet pięciu dokumentów szkoleniowych na klasę dokumentów, aby rozpocząć pracę. Aby rozpocząć trenowanie niestandardowego modelu klasyfikacji, potrzebujesz co najmniej pięciu dokumentów dla każdej klasy i dwóch klas dokumentów.
Niestandardowe wymagania dotyczące danych wejściowych modelu klasyfikacji
Upewnij się, że zestaw danych szkoleniowych jest zgodny z wymaganiami wejściowymi dotyczącymi analizy dokumentów.
Obsługiwane formaty plików:
Model PDF Obraz: JPEG/JPG, ,BMPPNG, ,TIFFHEIFMicrosoft Office:
Word (), Excel (XLSXDOCX), PowerPoint (PPTX), HTMLPrzeczytaj ✔ ✔ ✔ Układ ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Dokument ogólny ✔ ✔ Wstępnie utworzona ✔ ✔ Niestandardowe wyodrębnianie ✔ ✔ Klasyfikacja niestandardowa ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron (w przypadku subskrypcji warstwy Bezpłatna przetwarzane są tylko pierwsze dwie strony).
Rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i
4MB za bezpłatną (F0).Wymiary obrazu muszą mieć od 50 pikseli x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Minimalna wysokość tekstu do wyodrębnienia to 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada tekstowi
8punktowemu na 150 kropek na cal (DPI).W przypadku trenowania modelu niestandardowego maksymalna liczba stron dla danych szkoleniowych wynosi 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
W przypadku trenowania niestandardowego modelu wyodrębniania łączny rozmiar danych treningowych wynosi 50 MB dla modelu szablonu i
1GB dla modelu neuronowego.W przypadku trenowania niestandardowego modelu klasyfikacji całkowity rozmiar danych treningowych wynosi
1GB z maksymalnie 10 000 stron. W przypadku wersji 2024-07-31-preview i nowszych łączny rozmiar danych treningowych wynosi2GB z maksymalnie 10 000 stron.
Porady dotyczące danych szkoleniowych
Postępuj zgodnie z poniższymi wskazówkami, aby zoptymalizować zestaw danych pod kątem trenowania:
Jeśli to możliwe, użyj dokumentów tekstowych w formacie PDF zamiast dokumentów opartych na obrazach. Zeskanowane pliki PDF są obsługiwane jako obrazy.
Jeśli obrazy formularzy są niższej jakości, użyj większego zestawu danych (zawierającego na przykład 10–15 obrazów).
Przekazywanie danych treningowych
Po zebraniu zestawu formularzy lub dokumentów na potrzeby trenowania należy przekazać go do kontenera usługi Azure Blob Storage. Jeśli nie wiesz, jak utworzyć konto usługi Azure Storage za pomocą kontenera, postępuj zgodnie z przewodnikiem Szybki start usługi Azure Storage w witrynie Azure Portal. Możesz użyć bezpłatnej warstwy cenowej (F0), aby wypróbować usługę, a następnie uaktualnić ją do warstwy płatnej dla środowiska produkcyjnego. Jeśli zestaw danych jest zorganizowany jako foldery, zachowaj strukturę, ponieważ program Studio może używać nazw folderów dla etykiet, aby uprościć proces etykietowania.
Tworzenie projektu klasyfikacji w programie Document Intelligence Studio
Program Document Intelligence Studio udostępnia i organizuje wszystkie wywołania interfejsu API wymagane do ukończenia zestawu danych i trenowania modelu.
Zacznij od przechodzenia do programu Document Intelligence Studio. Przy pierwszym użyciu programu Studio należy zainicjować subskrypcję, grupę zasobów i zasób. Następnie postępuj zgodnie z wymaganiami wstępnymi dotyczącymi projektów niestandardowych, aby skonfigurować program Studio w celu uzyskania dostępu do zestawu danych szkoleniowych.
W programie Studio wybierz kafelek Niestandardowy model klasyfikacji w sekcji Modele niestandardowe na stronie i wybierz przycisk Utwórz projekt .

Create ProjectW oknie dialogowym podaj nazwę projektu, opcjonalnie opis i wybierz pozycję Kontynuuj.Następnie wybierz lub wybierz pozycję Utwórz zasób analizy dokumentów przed kontynuowaniem.
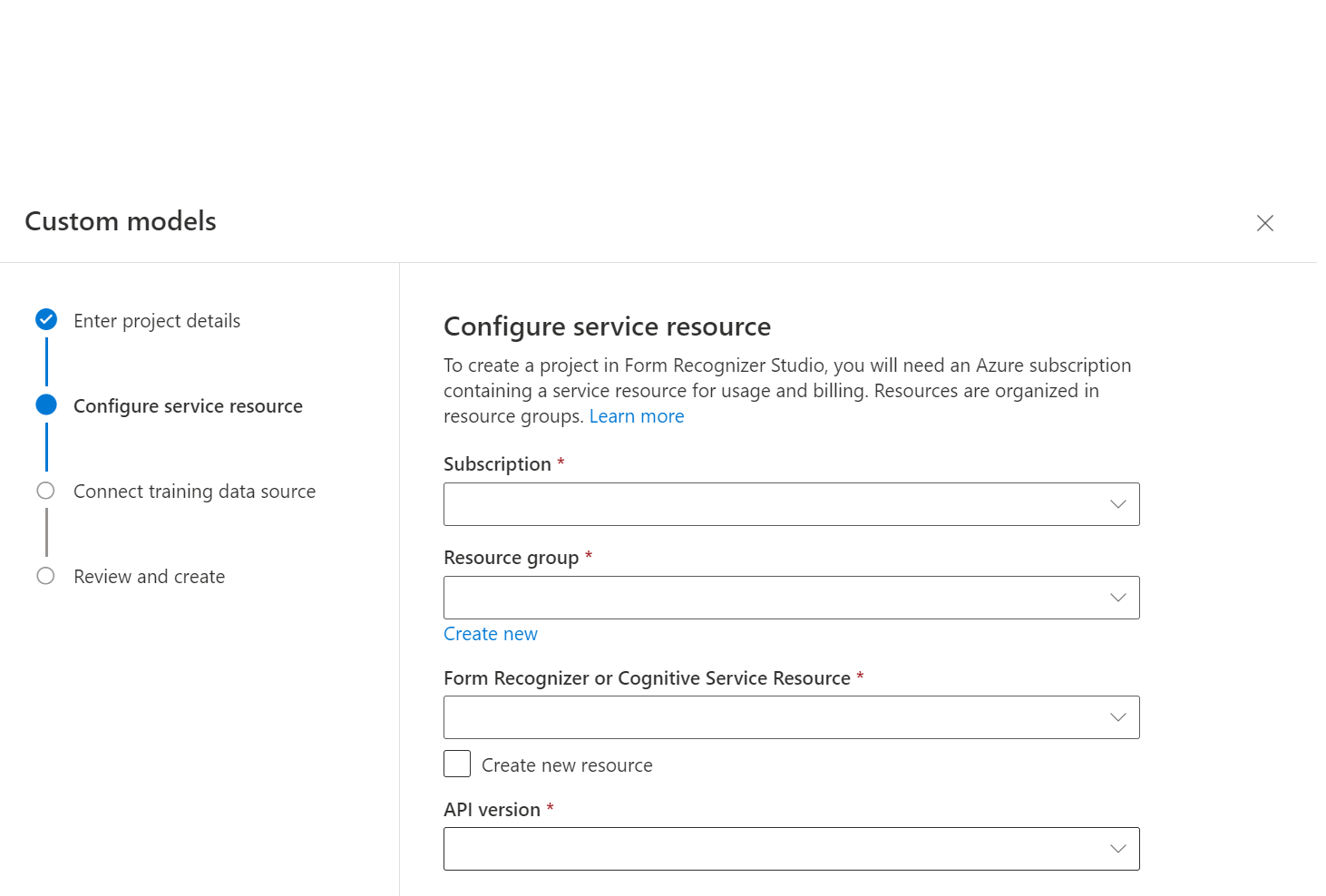
Następnie wybierz konto magazynu użyte do przekazania niestandardowego zestawu danych trenowania modelu. Ścieżka folderu powinna być pusta, jeśli dokumenty szkoleniowe znajdują się w katalogu głównym kontenera. Jeśli dokumenty znajdują się w podfolderze, wprowadź ścieżkę względną z katalogu głównego kontenera w polu Ścieżka folderu. Po skonfigurowaniu konta magazynu wybierz pozycję Kontynuuj.
Ważne
Zestaw danych trenowania można organizować według folderów, w których nazwa folderu jest etykietą lub klasą dokumentów albo utworzyć płaską listę dokumentów, do których można przypisać etykietę w programie Studio.
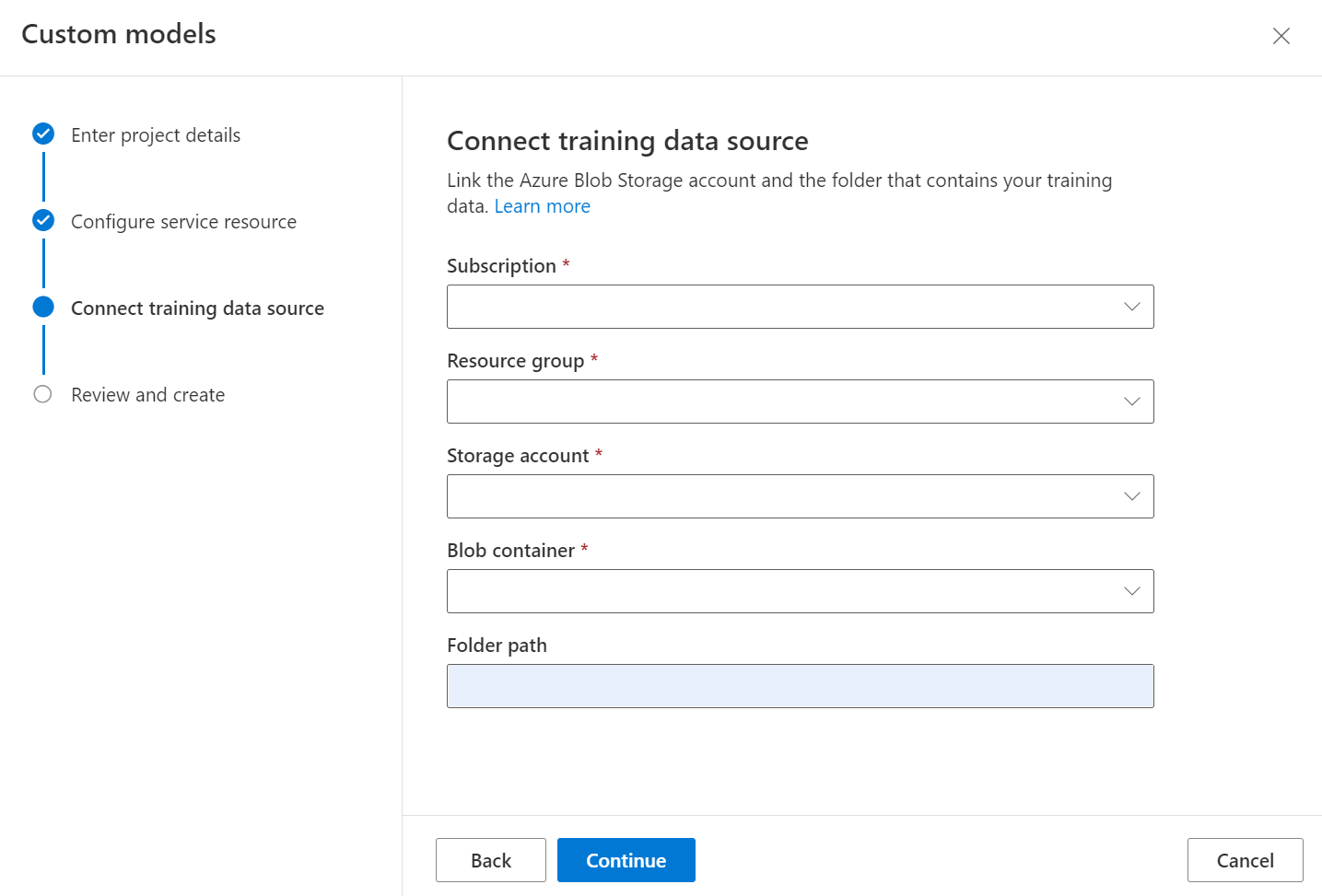
Trenowanie klasyfikatora niestandardowego wymaga danych wyjściowych z modelu Układu dla każdego dokumentu w zestawie danych. Uruchom układ we wszystkich dokumentach przed procesem trenowania modelu.
Na koniec przejrzyj ustawienia projektu i wybierz pozycję Utwórz projekt , aby utworzyć nowy projekt. Powinien być teraz w oknie etykietowania i zobaczyć pliki na liście zestawów danych.
Etykietowanie danych
W projekcie należy oznaczyć tylko każdy dokument odpowiednią etykietą klasy.

Zostaną wyświetlone pliki przekazane do magazynu na liście plików, które będą gotowe do etykietowania. Istnieje kilka opcji etykietowania zestawu danych.
Jeśli dokumenty są zorganizowane w folderach, program Studio wyświetli monit o użycie nazw folderów jako etykiet. Ten krok upraszcza etykietowanie w dół do pojedynczego zaznaczenia.
Aby przypisać etykietę do dokumentu, wybierz pozycję ,
add label selection markaby przypisać etykietę.Kontrolowanie wyboru do dokumentów wielokrotnego wybierania w celu przypisania etykiety
Wszystkie dokumenty powinny być teraz oznaczone etykietą zestawu danych. Jeśli spojrzysz na konto magazynu, znajdziesz pliki .ocr.json , które odpowiadają każdemu dokumentowi w zestawie danych trenowania, oraz nowy plik class-name.jsonl dla każdej klasy oznaczonej etykietą. Ten zestaw danych trenowania jest przesyłany do trenowania modelu.
Szkolenie modelu
Zestaw danych z etykietą jest teraz gotowy do trenowania modelu. Wybierz przycisk pociągu w prawym górnym rogu.
W oknie dialogowym trenowania modelu podaj unikatowy identyfikator klasyfikatora i opcjonalnie opis. Identyfikator klasyfikatora akceptuje typ danych ciągu.
Wybierz pozycję Trenuj , aby zainicjować proces trenowania.
Modele klasyfikatora trenują w ciągu kilku minut.
Przejdź do menu Modele , aby wyświetlić stan operacji trenowania.
Testowanie modelu
Po zakończeniu trenowania modelu możesz przetestować model, wybierając model na stronie listy modeli.
Wybierz model i wybierz przycisk Testuj.
Dodaj nowy plik, przeglądając plik lub upuszczając plik do selektora dokumentów.
Po wybraniu pliku wybierz przycisk Analizuj , aby przetestować model.
Wyniki modelu są wyświetlane z listą zidentyfikowanych dokumentów, współczynnik ufności dla każdego zidentyfikowanego dokumentu i zakres stron dla każdego zidentyfikowanego dokumentu.
Zweryfikuj model, oceniając wyniki dla każdego zidentyfikowanych dokumentów.
Trenowanie niestandardowego klasyfikatora przy użyciu zestawu SDK lub interfejsu API
Program Studio organizuje wywołania interfejsu API w celu wytrenowania klasyfikatora niestandardowego. Zestaw danych trenowania klasyfikatora wymaga danych wyjściowych z interfejsu API układu zgodnego z wersją interfejsu API dla modelu trenowania. Użycie wyników układu ze starszej wersji interfejsu API może spowodować, że model będzie mieć niższą dokładność.
Program Studio generuje wyniki układu dla zestawu danych trenowania, jeśli zestaw danych nie zawiera wyników układu. W przypadku trenowania klasyfikatora przy użyciu interfejsu API lub zestawu SDK należy dodać wyniki układu do folderów zawierających poszczególne dokumenty. Wyniki układu powinny być w formacie odpowiedzi interfejsu API podczas bezpośredniego wywoływania układu. Model obiektów zestawu SDK jest inny. Upewnij się, że layout results są to wyniki interfejsu SDK responseAPI, a nie .
Rozwiązywanie problemów
Model klasyfikacji wymaga wyników z modelu układu dla każdego dokumentu szkoleniowego. Jeśli nie podasz wyników układu, program Studio podejmie próbę uruchomienia modelu układu dla każdego dokumentu przed wytrenowanie klasyfikatora. Ten proces jest ograniczany i może spowodować odpowiedź 429.
W programie Studio przed rozpoczęciem trenowania z modelem klasyfikacji uruchom model układu w każdym dokumencie i przekaż go do tej samej lokalizacji co oryginalny dokument. Po dodaniu wyników układu możesz wytrenować model klasyfikatora przy użyciu dokumentów.