Trenowanie modelu niestandardowego przy użyciu narzędzia do etykietowania przykładowego
Ta zawartość dotyczy: ![]() wersja 2.1.
wersja 2.1.
Napiwek
- Aby uzyskać ulepszone środowisko i zaawansowaną jakość modelu, wypróbuj narzędzie Document Intelligence w wersji 3.0 Studio.
- Program Studio w wersji 3.0 obsługuje dowolny model trenowany z danymi oznaczonymi etykietami w wersji 2.1.
- Szczegółowe informacje na temat migracji z wersji 2.1 do wersji 3.0 można znaleźć w przewodniku migracji interfejsu API.
- Zobacz nasze przewodniki Szybki start dotyczące interfejsu API REST lub języka C#, Java, JavaScript lub Python SDK, aby rozpocząć pracę z platformą V3.0.
W tym artykule użyjesz interfejsu API REST analizy dokumentów z narzędziem Do etykietowania przykładowego, aby wytrenować model niestandardowy z ręcznie oznaczonymi danymi.
Wymagania wstępne
Do ukończenia tego projektu potrzebne są następujące zasoby:
- Subskrypcja platformy Azure — utwórz bezpłatnie
- Po utworzeniu subskrypcji platformy Azure utwórz zasób analizy dokumentów w witrynie Azure Portal, aby uzyskać klucz i punkt końcowy. Po wdrożeniu wybierz pozycję Przejdź do zasobu.
- Potrzebujesz klucza i punktu końcowego z utworzonego zasobu, aby połączyć aplikację z interfejsem API analizy dokumentów. Klucz i punkt końcowy wklejasz do kodu w dalszej części przewodnika Szybki start.
- Możesz użyć warstwy cenowej bezpłatna (
F0), aby wypróbować usługę, a następnie uaktualnić ją do warstwy płatnej dla środowiska produkcyjnego.
- Zestaw co najmniej sześciu formularzy tego samego typu. Te dane służą do trenowania modelu i testowania formularza. Na potrzeby tego przewodnika Szybki start możesz użyć przykładowego zestawu danych (pobierz i wyodrębnij sample_data.zip). Przekaż pliki szkoleniowe do katalogu głównego kontenera magazynu obiektów blob na koncie usługi Azure Storage w warstwie Standardowa.
Tworzenie zasobu analizy dokumentów
Przejdź do witryny Azure Portal i utwórz nowy zasób analizy dokumentów. W okienku Tworzenie podaj następujące informacje:
| Szczegóły projektu | opis |
|---|---|
| Subskrypcja | Wybierz subskrypcję platformy Azure, której udzielono dostępu. |
| Grupa zasobów: | Grupa zasobów platformy Azure zawierająca zasób. Możesz utworzyć nową grupę lub dodać ją do istniejącej grupy. |
| Region | Lokalizacja zasobu usług Azure AI. Różne lokalizacje mogą powodować opóźnienie, ale nie mają wpływu na dostępność zasobu w czasie wykonywania. |
| Nazwa/nazwisko | Opisowa nazwa zasobu. Zalecamy użycie nazwy opisowej, na przykład MyNameFormRecognizer. |
| Warstwa cenowa | Koszt zasobu zależy od wybranej warstwy cenowej i użycia. Aby uzyskać więcej informacji, zobacz szczegóły cennika interfejsu API. |
| Przeglądanie i tworzenie | Wybierz przycisk Przejrzyj i utwórz, aby wdrożyć zasób w witrynie Azure Portal. |
Pobieranie klucza i punktu końcowego
Po zakończeniu wdrażania zasobu analizy dokumentów znajdź go i wybierz go z listy Wszystkie zasoby w portalu. Klucz i punkt końcowy będą znajdować się na stronie Klucz i punkt końcowy zasobu w obszarze Zarządzanie zasobami. Zapisz oba te elementy w lokalizacji tymczasowej przed kontynuowaniem.
Czas to wypróbować
Wypróbuj narzędzie do etykietowania przykładowego analizy dokumentów w trybie online:
Potrzebujesz subskrypcji platformy Azure (utwórz ją bezpłatnie) oraz punktu końcowego zasobów analizy dokumentów i klucza, aby wypróbować usługę Analizy dokumentów.
Konfigurowanie narzędzia do etykietowania przykładowego
Uwaga
Jeśli dane magazynu znajduje się za siecią wirtualną lub zaporą, musisz wdrożyć narzędzie do etykietowania przykładowego analizy dokumentów za siecią wirtualną lub zaporą i udzielić dostępu, tworząc tożsamość zarządzaną przypisaną przez system.
Aparat platformy Docker służy do uruchamiania narzędzia do etykietowania przykładowego. Wykonaj następujące kroki, aby skonfigurować kontener platformy Docker. Aby uzyskać podstawowe informacje na temat platformy Docker i kontenerów, zapoznaj się z artykułem Docker overview (Przegląd platformy Docker).
Napiwek
Narzędzie do etykietowania formularzy OCR jest również dostępne jako projekt open source w witrynie GitHub. To narzędzie jest aplikacją internetową TypeScript utworzoną przy użyciu platformy React + Redux. Aby dowiedzieć się więcej lub współtworzyć, zobacz repozytorium narzędzia do etykietowania formularzy OCR. Aby wypróbować narzędzie w trybie online, przejdź do witryny internetowej narzędzia do etykietowania przykładowego analizy dokumentów.
Najpierw zainstaluj platformę Docker na komputerze hosta. W tym przewodniku pokazano, jak używać komputera lokalnego jako hosta. Jeśli chcesz użyć usługi hostingu platformy Docker na platformie Azure, zobacz przewodnik Wdrażanie narzędzia do etykietowania przykładowego.
Komputer hosta musi spełniać następujące wymagania sprzętowe:
Kontener Minimum Zalecane Przykładowe narzędzie do etykietowania 2rdzeń, 4 GB pamięci4rdzeń, 8 GB pamięciZainstaluj platformę Docker na swojej maszynie, postępując zgodnie z odpowiednimi instrukcjami dotyczącymi systemu operacyjnego:
Pobierz kontener narzędzia do etykietowania przykładowego za
docker pullpomocą polecenia .docker pull mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1Teraz możesz uruchomić kontener za pomocą
docker runpolecenia .docker run -it -p 3000:80 mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1 eula=acceptTo polecenie udostępnia przykładowe narzędzie etykietowania za pośrednictwem przeglądarki internetowej. Przejdź do
http://localhost:3000.
Uwaga
Możesz również oznaczyć dokumenty i trenować modele przy użyciu interfejsu API REST analizy dokumentów. Aby trenować i analizować za pomocą interfejsu API REST, zobacz Trenowanie za pomocą etykiet przy użyciu interfejsu API REST i języka Python.
Konfigurowanie danych wejściowych
Najpierw upewnij się, że wszystkie dokumenty szkoleniowe mają ten sam format. Jeśli masz formularze w wielu formatach, podziel je na podfoldery w oparciu o wspólny format. Podczas trenowania należy skierować interfejs API do podfolderu.
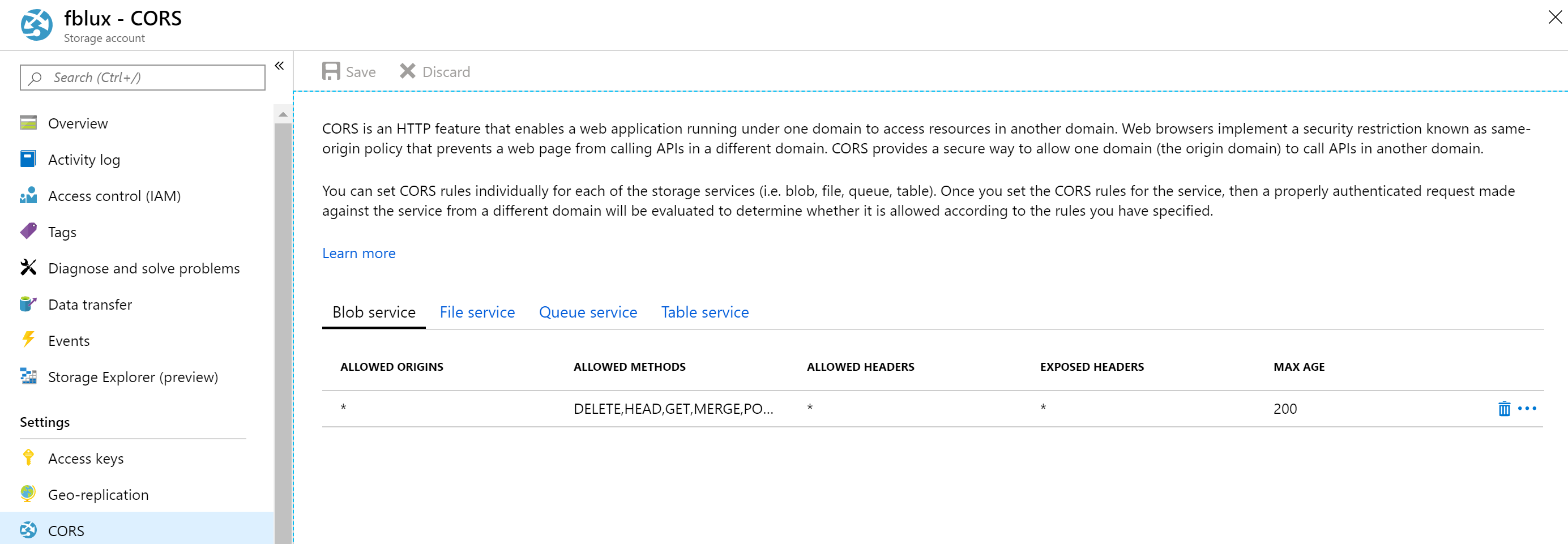
Konfigurowanie współużytkowania zasobów między domenami (CORS)
Włącz mechanizm CORS na koncie magazynu. Wybierz konto magazynu w witrynie Azure Portal, a następnie wybierz kartę CORS w okienku po lewej stronie. W dolnej linii wypełnij następujące wartości. Wybierz Zapisz na górze.
- Dozwolone źródła = *
- Dozwolone metody = [zaznacz wszystko]
- Dozwolone nagłówki = *
- Uwidocznione nagłówki = *
- Maksymalny wiek = 200 lat
Nawiązywanie połączenia z narzędziem do etykietowania przykładowego
Narzędzie Przykładowe etykietowanie łączy się ze źródłem (oryginalnymi przekazanymi formularzami) i elementem docelowym (utworzone etykiety i dane wyjściowe).
Połączenia można konfigurować i udostępniać w projektach. Używają one rozszerzalnego modelu dostawcy, dzięki czemu można łatwo dodawać nowych dostawców źródłowych/docelowych.
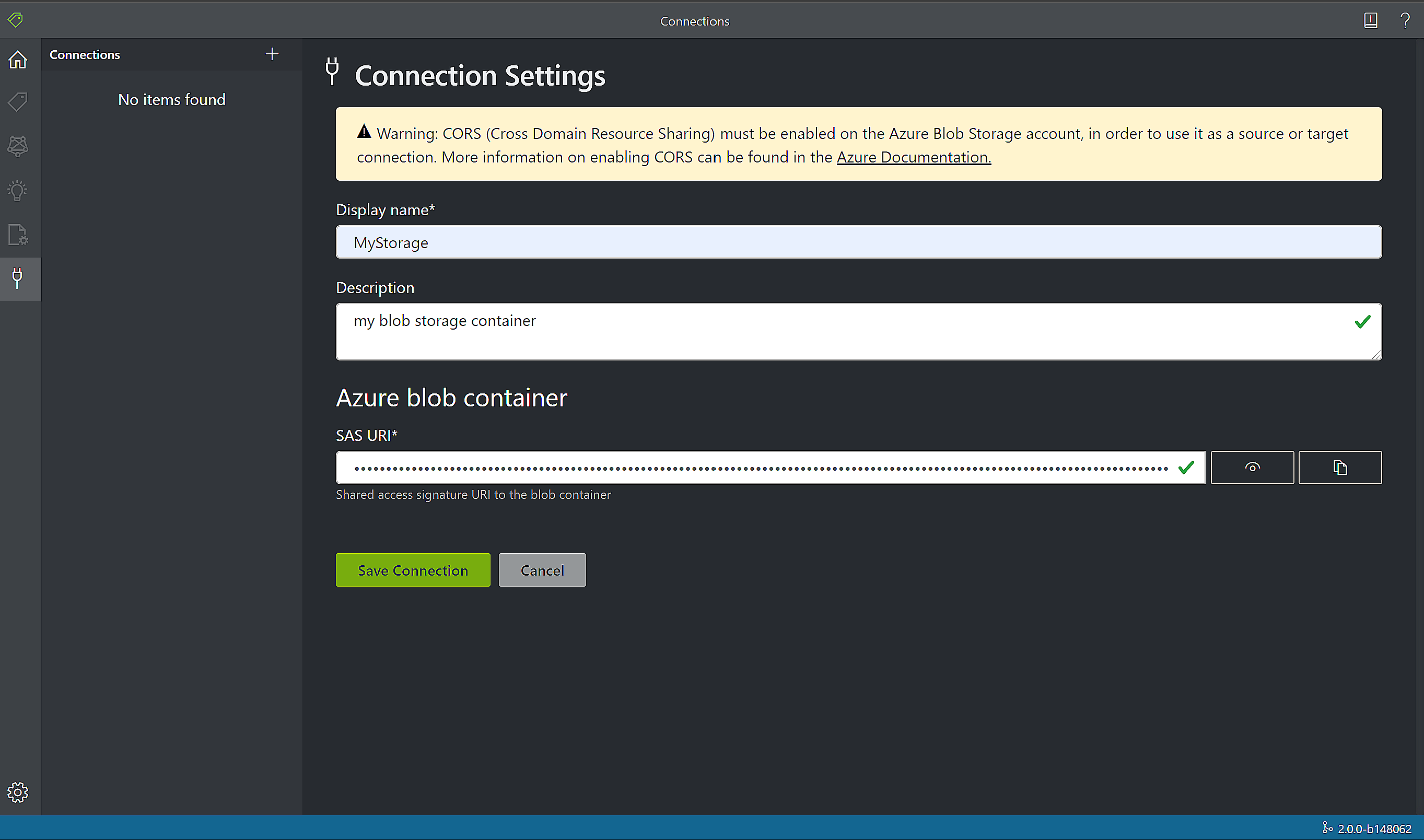
Aby utworzyć nowe połączenie, wybierz ikonę Nowe połączenia (wtyczka) na pasku nawigacyjnym po lewej stronie.
Wypełnij pola następującymi wartościami:
Nazwa wyświetlana — nazwa wyświetlana połączenia.
Opis — opis projektu.
Adres URL sygnatury dostępu współdzielonego — adres URL sygnatury dostępu współdzielonego kontenera usługi Azure Blob Storage. Aby pobrać adres URL sygnatury dostępu współdzielonego dla danych trenowania modelu niestandardowego, przejdź do zasobu magazynu w witrynie Azure Portal i wybierz kartę Eksplorator usługi Storage. Przejdź do kontenera, kliknij prawym przyciskiem myszy i wybierz pozycję Pobierz sygnaturę dostępu współdzielonego. Ważne jest, aby uzyskać sygnaturę dostępu współdzielonego dla kontenera, a nie dla samego konta magazynu. Upewnij się, że zaznaczono uprawnienia Odczyt, Zapis, Usuń i Lista , a następnie kliknij przycisk Utwórz. Następnie skopiuj wartość w sekcji Adres URL do lokalizacji tymczasowej. Powinna ona mieć postać:
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>.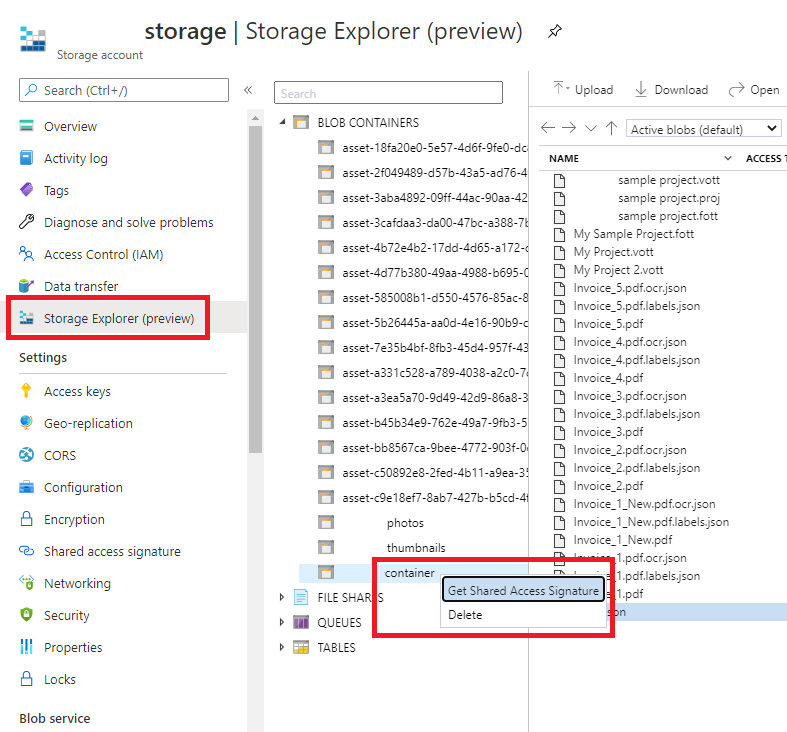
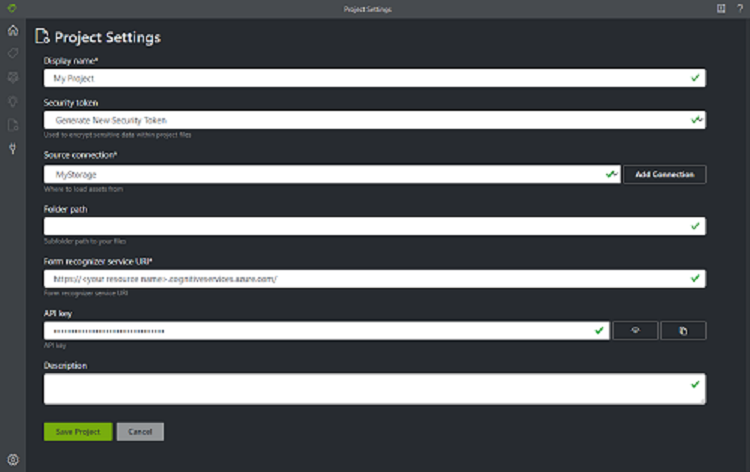
Tworzenie nowego projektu
W narzędziu Przykładowe etykietowanie projekty przechowują konfiguracje i ustawienia. Utwórz nowy projekt i wypełnij pola następującymi wartościami:
- Nazwa wyświetlana — nazwa wyświetlana projektu
- Token zabezpieczający — niektóre ustawienia projektu mogą zawierać poufne wartości, takie jak klucze lub inne udostępnione wpisy tajne. Każdy projekt generuje token zabezpieczający, który może służyć do szyfrowania/odszyfrowywania poufnych ustawień projektu. Tokeny zabezpieczające można znaleźć w obszarze Ustawienia aplikacji, wybierając ikonę koła zębatego w dolnej części lewego paska nawigacyjnego.
- Połączenie źródłowe — połączenie usługi Azure Blob Storage utworzone w poprzednim kroku, którego chcesz użyć dla tego projektu.
- Ścieżka folderu — opcjonalnie — jeśli formularze źródłowe znajdują się w folderze w kontenerze obiektów blob, określ nazwę folderu tutaj
- Identyfikator URI usługi Document Intelligence Service — adres URL punktu końcowego analizy dokumentów.
- Klucz — klucz analizy dokumentów.
- Opis — opcjonalny — opis projektu
Etykietowanie formularzy
Po utworzeniu lub otwarciu projektu zostanie otwarte okno edytora tagów głównych. Edytor tagów składa się z trzech części:
- Okienko z możliwością zmiany rozmiaru w wersji 3.0, które zawiera przewijaną listę formularzy z połączenia źródłowego.
- Okienko edytora głównego, które umożliwia stosowanie tagów.
- Okienko edytora tagów umożliwiające użytkownikom modyfikowanie, blokowanie, zmienianie kolejności i usuwanie tagów.
Identyfikowanie tekstu i tabel
Wybierz pozycję Uruchom układ dla nienadzorowanych dokumentów w okienku po lewej stronie, aby uzyskać informacje o tekście i układzie tabeli dla każdego dokumentu. Narzędzie etykietowania rysuje pola ograniczenia wokół każdego elementu tekstowego.
Narzędzie etykietowania pokazuje również, które tabele zostały wyodrębnione automatycznie. Wybierz ikonę tabeli/siatki po lewej stronie dokumentu, aby wyświetlić wyodrębnionej tabeli. W tym przewodniku Szybki start, ponieważ zawartość tabeli jest automatycznie wyodrębniona, nie oznaczamy zawartości tabeli, ale raczej polegamy na automatycznym wyodrębnieniu.
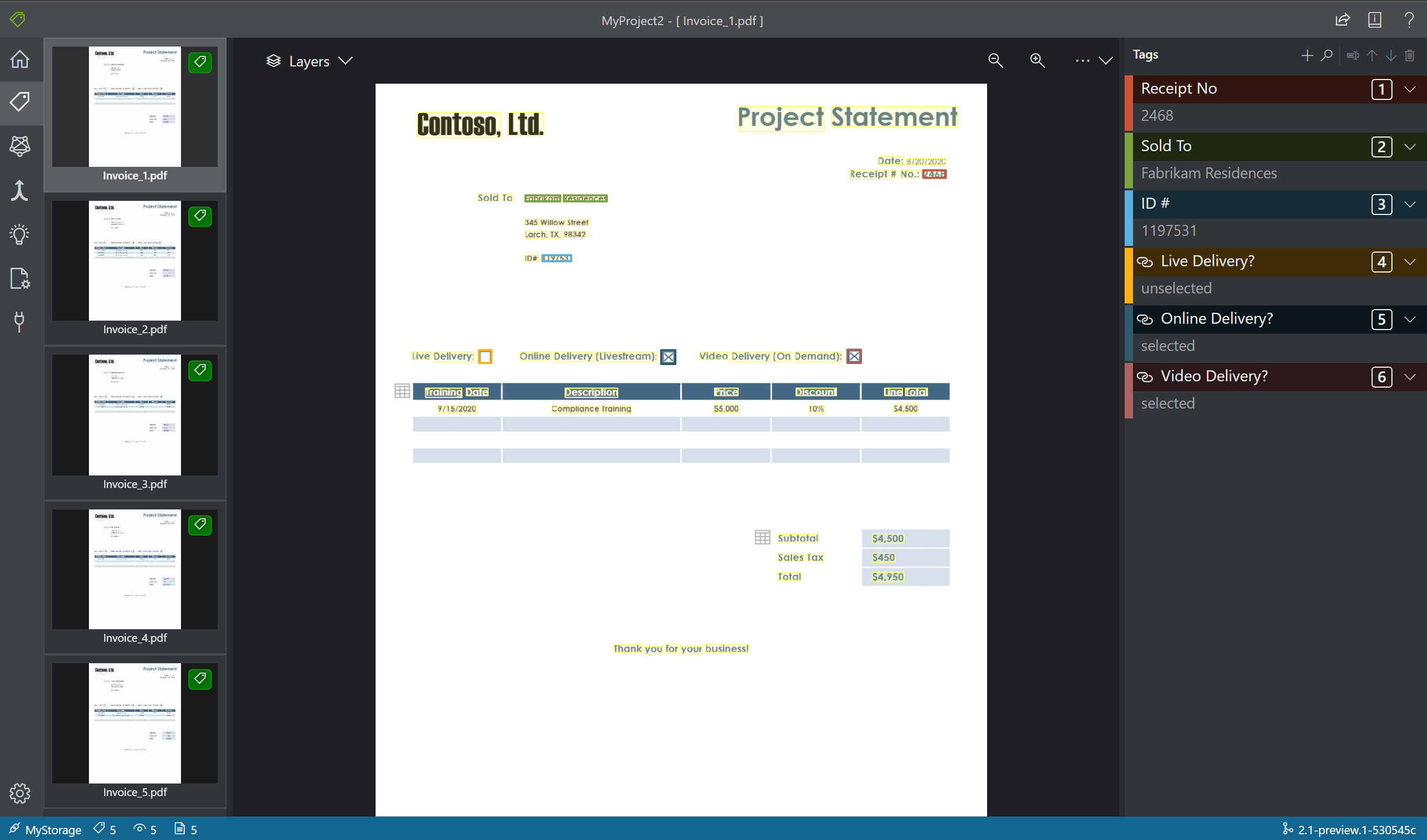
W wersji 2.1, jeśli dokument szkoleniowy nie ma wypełnionej wartości, możesz narysować pole, w którym powinna być wartość. Użyj obszaru Rysuj w lewym górnym rogu okna, aby oznaczyć region tagami.
Stosowanie etykiet do tekstu
Następnie utworzysz tagi (etykiety) i zastosujesz je do elementów tekstowych, które mają być analizowane przez model.
- Najpierw użyj okienka edytora tagów, aby utworzyć tagi, które chcesz zidentyfikować.
- Wybierz + , aby utworzyć nowy tag.
- Wprowadź nazwę tagu.
- Naciśnij Enter, aby zapisać tag.
- W edytorze głównym wybierz wyrazy z wyróżnionych elementów tekstowych lub regionu, w którym został wyświetlony.
- Wybierz tag, który chcesz zastosować, lub naciśnij odpowiedni klawiatury. Klucze liczbowe są przypisywane jako klucze dostępu dla pierwszych 10 tagów. Tagi można zmienić za pomocą ikon strzałek w górę i w dół w okienku edytora tagów.
- Wykonaj następujące kroki, aby oznaczyć co najmniej pięć formularzy.
Napiwek
Podczas etykietowania formularzy pamiętaj o następujących wskazówkach:
- Do każdego zaznaczonego elementu tekstowego można zastosować tylko jeden tag.
- Każdy tag można stosować tylko raz na stronę. Jeśli wartość jest wyświetlana wiele razy w tym samym formularzu, utwórz różne tagi dla każdego wystąpienia. Na przykład: "invoice# 1", "invoice# 2" itd.
- Tagi nie mogą obejmować między stronami.
- Etykiety wartości wyświetlane w formularzu; Nie próbuj dzielić wartości na dwie części z dwoma różnymi tagami. Na przykład pole adresu powinno być oznaczone pojedynczym tagiem, nawet jeśli obejmuje wiele wierszy.
- Nie dołączaj kluczy do otagowanych pól — tylko wartości.
- Dane tabeli powinny być wykrywane automatycznie i będą dostępne w ostatnim wyjściowym pliku JSON. Jeśli jednak model nie wykryje wszystkich danych tabeli, możesz również ręcznie oznaczyć te pola. Oznacz każdą komórkę w tabeli inną etykietą. Jeśli formularze zawierają tabele o różnej liczbie wierszy, upewnij się, że tagujesz co najmniej jeden formularz z największą możliwą tabelą.
- Użyj przycisków z prawej strony, + aby wyszukać, zmienić nazwę, zmienić kolejność i usunąć tagi.
- Aby usunąć zastosowany tag bez usuwania samego tagu, zaznacz prostokąt oznakowany w widoku dokumentu i naciśnij delete.
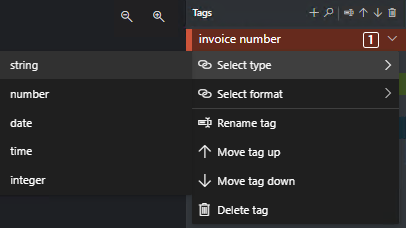
Określanie typów wartości tagów
Można ustawić oczekiwany typ danych dla każdego tagu. Otwórz menu kontekstowe po prawej stronie tagu i wybierz typ z menu. Ta funkcja umożliwia algorytmowi wykrywania wprowadzanie założeń, które zwiększają dokładność wykrywania tekstu. Gwarantuje to również, że wykryte wartości są zwracane w formacie ustandaryzowanym w ostatnim danych wyjściowych JSON. Informacje o typie wartości są zapisywane w pliku fields.json w tej samej ścieżce co pliki etykiet.
Obecnie obsługiwane są następujące typy wartości i odmiany:
string- wartość domyślna,
no-whitespaces,alphanumeric
- wartość domyślna,
number- domyślny
currency - Sformatowane jako wartość zmiennoprzecinkowa.
- Przykład: 1234.98 w dokumencie jest sformatowany w formacie 1234.98 w danych wyjściowych
- domyślny
date- default,
dmy, ,mdyymd
- default,
timeinteger- Sformatowany jako wartość całkowita.
- Przykład: 1234.98 w dokumencie jest sformatowany w 123498 danych wyjściowych.
selectionMark
Uwaga
Zobacz następujące reguły formatowania dat:
Musisz określić format (dmy, mdy, ymd), aby formatowanie daty działało.
Jako ograniczniki dat mogą być używane następujące znaki: , - / . \. Białe znaki nie mogą być używane jako ogranicznik. Na przykład:
- 01,01,2020
- 01-01-2020
- 01/01/2020
Dzień i miesiąc mogą być pisane jako jedna lub dwie cyfry, a rok może mieć dwie lub cztery cyfry:
- 1-1-2020
- 1-01-20
Jeśli ciąg daty ma osiem cyfr, ogranicznik jest opcjonalny:
- 01012020
- 01 01 2020
Miesiąc może być także zapisany jako jego pełna lub krótka nazwa. Jeśli nazwa jest używana, znaki ogranicznika są opcjonalne. Jednak ten format może zostać rozpoznany mniej dokładnie niż inne.
- 01/sty/2020
- 01sty2020
- 01 sty 2020
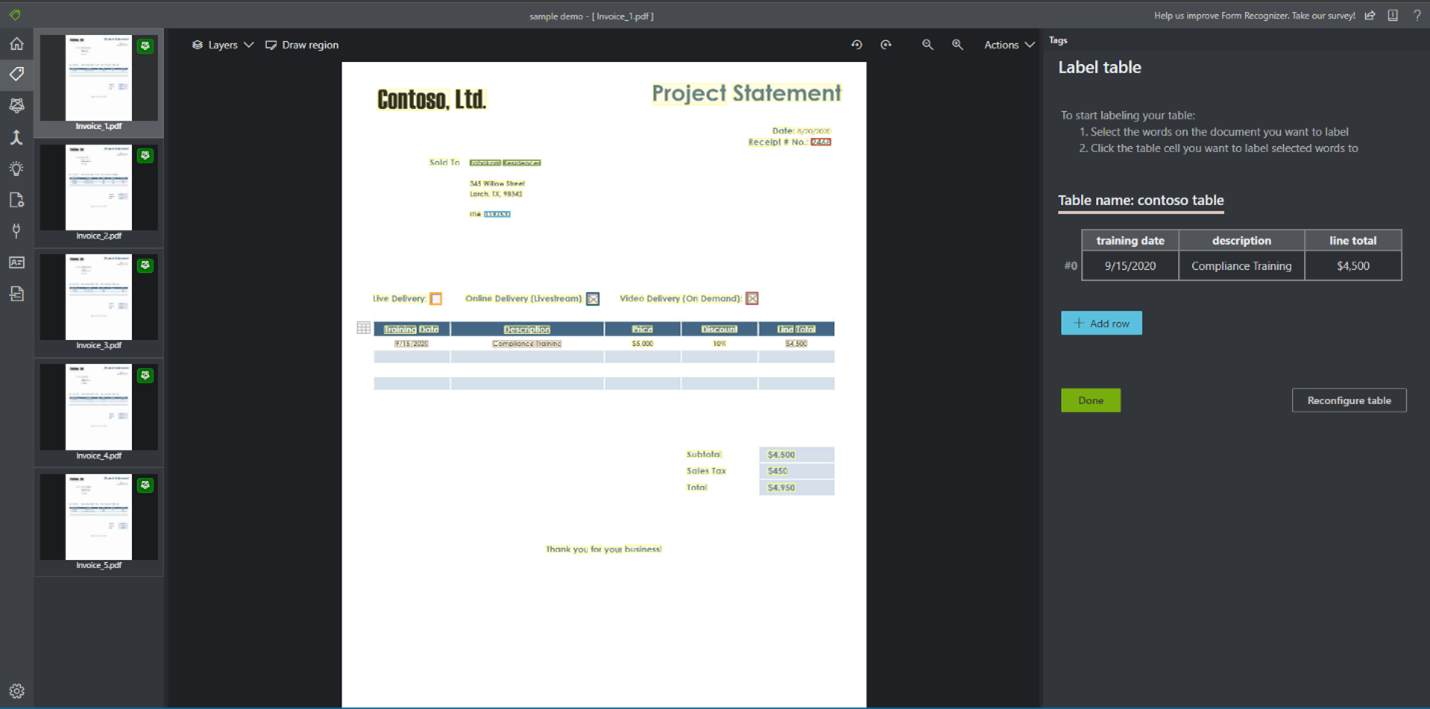
Tabele etykiet (tylko wersja 2.1)
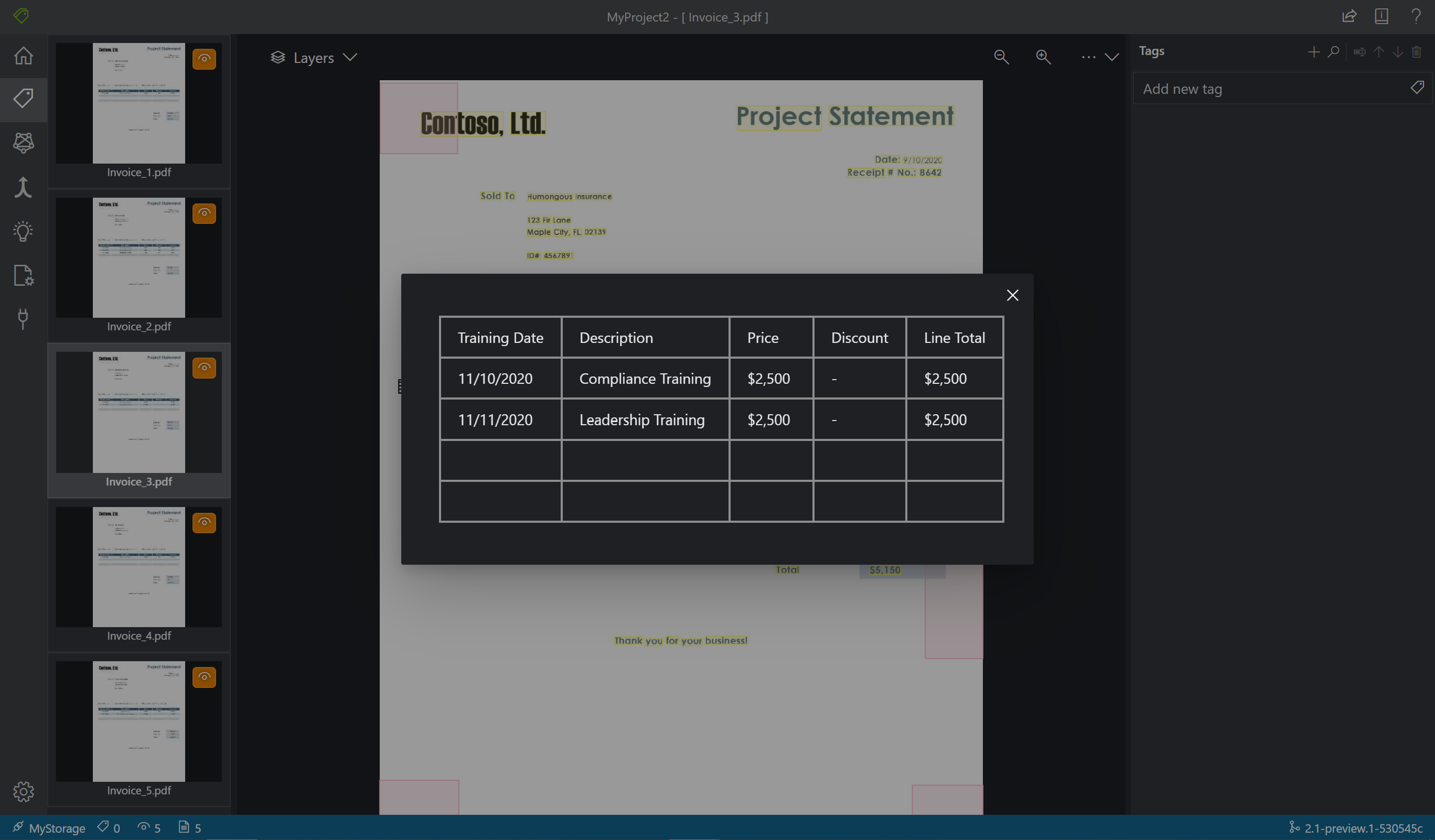
Czasami dane mogą być lepiej oznaczone jako tabela, a nie pary klucz-wartość. W takim przypadku możesz utworzyć tag tabeli, wybierając pozycję Dodaj nowy tag tabeli. Określ, czy tabela ma stałą liczbę wierszy lub zmienną liczbę wierszy w zależności od dokumentu i zdefiniuj schemat.
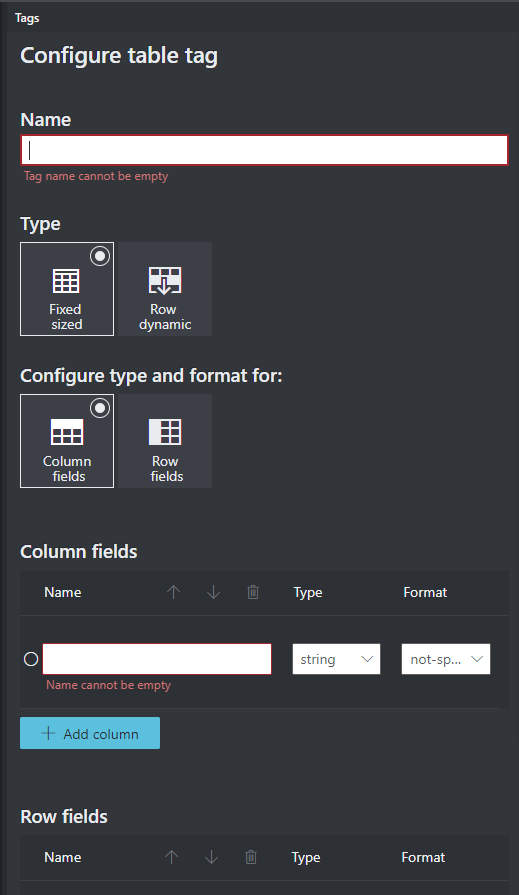
Po zdefiniowaniu tagu tabeli oznacz wartości komórek.
Trenowanie modelu niestandardowego
Wybierz ikonę Trenowanie w okienku po lewej stronie, aby otworzyć stronę Trenowanie. Następnie wybierz przycisk Trenuj, aby rozpocząć trenowanie modelu. Po zakończeniu procesu trenowania zobaczysz następujące informacje:
- Identyfikator modelu — identyfikator modelu, który został utworzony i wytrenowany. Każde wywołanie trenowania tworzy nowy model z własnym identyfikatorem. Skopiuj ten ciąg do bezpiecznej lokalizacji; Potrzebujesz go, jeśli chcesz wykonać wywołania przewidywania za pomocą interfejsu API REST lub przewodnika po bibliotece klienta.
- Średnia dokładność — średnia dokładność modelu. Dokładność modelu można poprawić przez dodanie i etykietowanie większej liczby formularzy, a następnie ponowne trenowanie w celu utworzenia nowego modelu. Zalecamy rozpoczęcie od etykietowania pięciu formularzy i dodawania większej liczby formularzy zgodnie z potrzebami.
- Lista tagów i szacowana dokładność na tag.
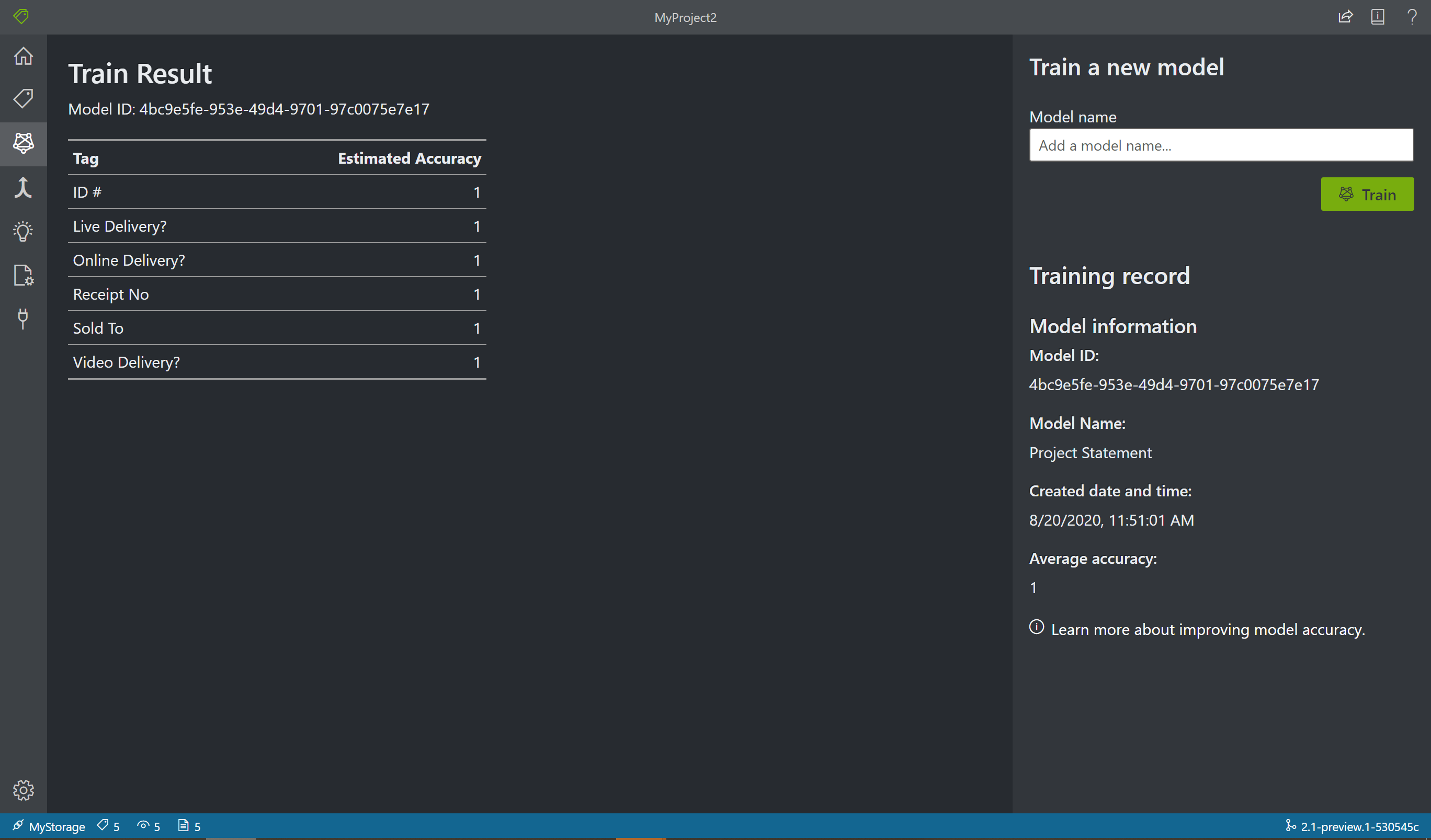
Po zakończeniu trenowania sprawdź wartość Average Accuracy (Średnia dokładność). Jeśli jest niska, należy dodać więcej dokumentów wejściowych i powtórzyć kroki etykietowania. Dokumenty, które zostały już oznaczone, pozostają w indeksie projektu.
Napiwek
Możesz również uruchomić proces trenowania za pomocą wywołania interfejsu API REST. Aby dowiedzieć się, jak to zrobić, zobacz Szkolenie z etykietami przy użyciu języka Python.
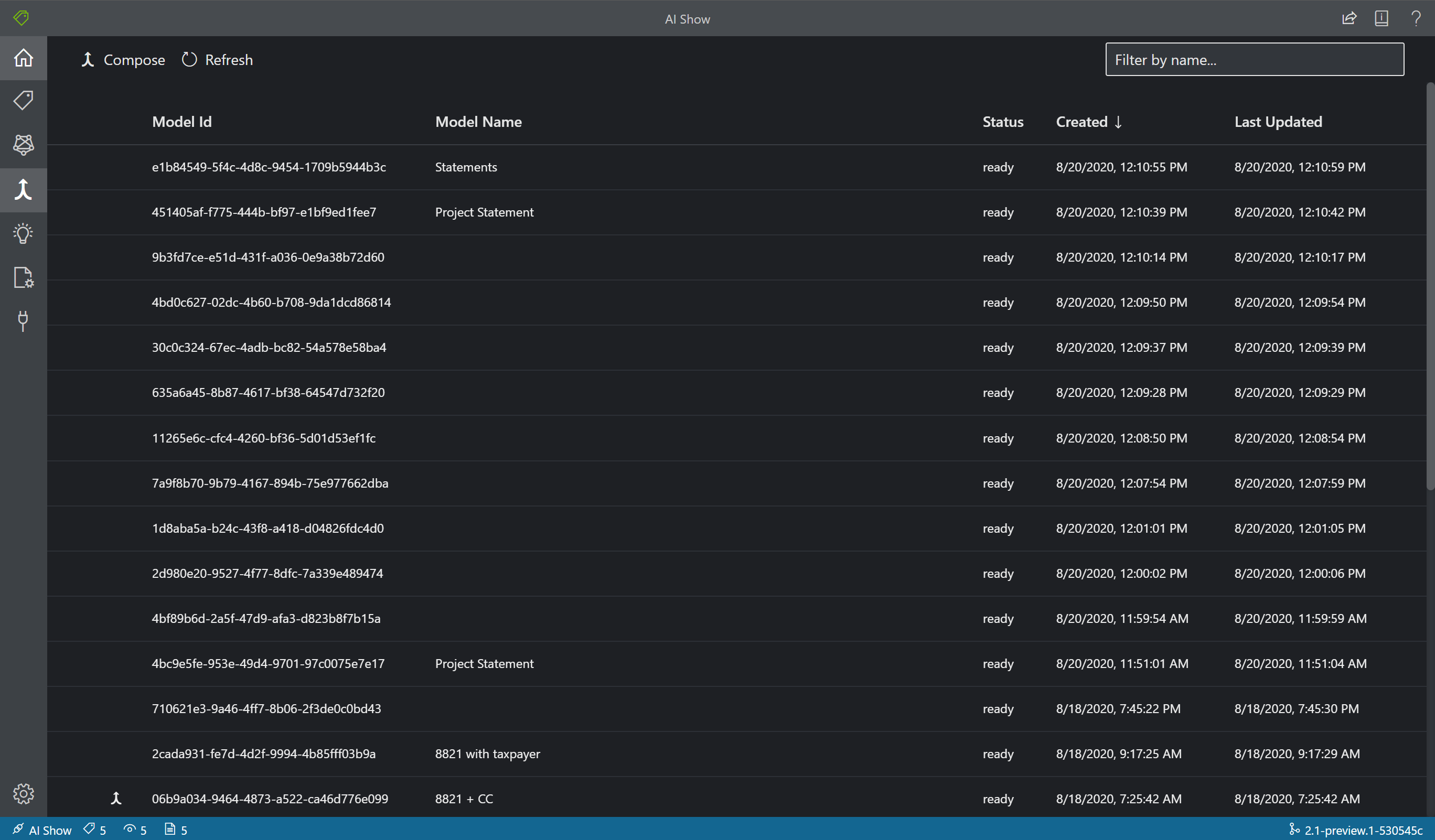
Tworzenie wytrenowanych modeli
Za pomocą narzędzia Model Compose można tworzyć maksymalnie 200 modeli do jednego identyfikatora modelu. Po wywołaniu funkcji Analizuj z komponowanym modelIDelementem analiza dokumentów klasyfikuje przesłany formularz, wybierz najlepszy model dopasowania, a następnie zwraca wyniki dla tego modelu. Ta operacja jest przydatna, gdy formularze przychodzące mogą należeć do jednego z kilku szablonów.
- Aby utworzyć modele w narzędziu Przykładowe etykietowanie, wybierz ikonę Redagowanie modelu (strzałka scalania) na pasku nawigacyjnym.
- Wybierz modele, które chcesz utworzyć razem. Modele z ikoną strzałek już składają się z modeli.
- Wybierz przycisk Redaguj. W oknie podręcznym nadaj nowemu modelowi nazwę i wybierz pozycję Utwórz.
- Po zakończeniu operacji nowo utworzony model powinien pojawić się na liście.
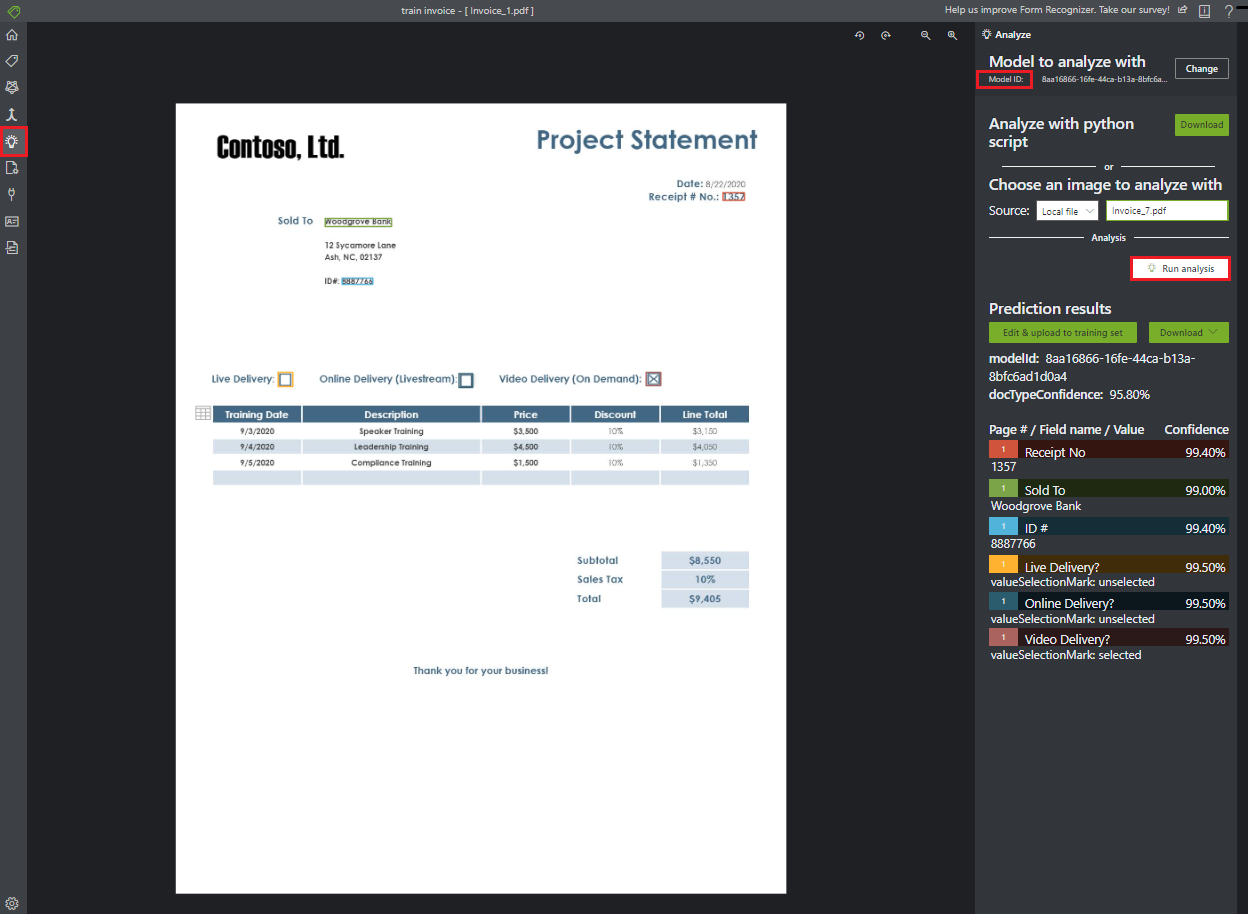
Analizowanie formularza
Wybierz ikonę Analizuj na pasku nawigacyjnym, aby przetestować model. Wybierz źródłowy plik lokalny. Wyszukaj plik i wybierz plik z przykładowego zestawu danych, który został rozpakowany w folderze testowym. Następnie wybierz przycisk Run analysis ( Uruchom analizę), aby pobrać pary klucz/wartość, przewidywania tekstowe i tabele dla formularza. Narzędzie stosuje tagi w polach ograniczenia i zgłasza pewność każdego tagu.
Napiwek
Możesz również uruchomić interfejs API analizowania za pomocą wywołania REST. Aby dowiedzieć się, jak to zrobić, zobacz Szkolenie z etykietami przy użyciu języka Python.
Ulepszanie wyników
W zależności od zgłoszonej dokładności warto przeprowadzić dalsze szkolenia, aby ulepszyć model. Po wykonaniu przewidywania sprawdź wartości ufności dla każdego z zastosowanych tagów. Jeśli średnia wartość trenowania dokładności jest wysoka, ale wyniki ufności są niskie (lub wyniki są niedokładne), dodaj plik przewidywania do zestawu treningowego, oznacz go i wytrenuj ponownie.
Zgłoszona średnia dokładność, wyniki ufności i rzeczywista dokładność mogą być niespójne, gdy analizowane dokumenty różnią się od dokumentów używanych podczas trenowania. Pamiętaj, że niektóre dokumenty wyglądają podobnie, gdy są wyświetlane przez osoby, ale mogą wyglądać różnie od modelu sztucznej inteligencji. Na przykład możesz trenować przy użyciu typu formularza, który ma dwie odmiany, gdzie zestaw treningowy składa się z 20% odmianY A i 80% odmiany B. Podczas przewidywania wyniki ufności dla dokumentów odmiany A prawdopodobnie będą niższe.
Zapisywanie projektu i wznawianie później
Aby wznowić projekt w innym czasie lub w innej przeglądarce, musisz zapisać token zabezpieczający projektu i ponownie go wprowadzić później.
Pobieranie poświadczeń projektu
Przejdź do strony ustawień projektu (ikona suwaka) i zanotuj nazwę tokenu zabezpieczającego. Następnie przejdź do ustawień aplikacji (ikona koła zębatego), który pokazuje wszystkie tokeny zabezpieczające w bieżącym wystąpieniu przeglądarki. Znajdź token zabezpieczający projektu i skopiuj jego nazwę i wartość klucza do bezpiecznej lokalizacji.
Przywracanie poświadczeń projektu
Aby wznowić projekt, należy najpierw utworzyć połączenie z tym samym kontenerem usługi Blob Storage. W tym celu powtórz kroki. Następnie przejdź do strony ustawień aplikacji (ikona koła zębatego) i sprawdź, czy istnieje token zabezpieczający projektu. Jeśli tak nie jest, dodaj nowy token zabezpieczający i skopiuj nazwę tokenu i klucz z poprzedniego kroku. Wybierz pozycję Zapisz , aby zachować ustawienia.
Wznawianie projektu
Na koniec przejdź do strony głównej (ikona domu) i wybierz pozycję Otwórz projekt w chmurze. Następnie wybierz połączenie magazynu obiektów blob i wybierz plik projektu .fott . Aplikacja ładuje wszystkie ustawienia projektu, ponieważ ma token zabezpieczający.
Następne kroki
W tym przewodniku Szybki start przedstawiono sposób użycia narzędzia do etykietowania przykładowego analizy dokumentów w celu wytrenowania modelu z ręcznie oznaczonymi danymi. Jeśli chcesz utworzyć własne narzędzie do etykietowania danych treningowych, użyj interfejsów API REST, które zajmują się trenowaniem danych oznaczonych etykietami.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla