Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Po utworzeniu schematu dla zadania dostrajania dodasz do projektu wypowiedzi szkoleniowe. Wypowiedzi powinny być podobne do używanych przez użytkowników podczas interakcji z projektem. Po dodaniu wypowiedzi musisz przypisać intencję, do której należy. Po dodaniu wypowiedzi oznacz wyrazy w wypowiedzi, które chcesz wyodrębnić jako jednostki.
Etykietowanie danych to kluczowy krok w cyklu rozwoju i szkolenia systemów rozumienia języka konwersacyjnego (CLU). Te dane są używane w następnym kroku podczas trenowania modelu, aby model mógł uczyć się na podstawie oznaczonych danych. Jeśli wypowiedzi zostały już oznaczone etykietą, możesz je bezpośrednio zaimportować do projektu, jeśli dane są zgodne z akceptowanym formatem danych. Aby dowiedzieć się więcej na temat importowania danych etykietowanych, zobacz w Utwórz zadanie dostrajania CLU. Dane oznaczone etykietami informują model o sposobie interpretowania tekstu i jest używany do trenowania i oceny.
Napiwek
Użyj opcji Szybkie wdrażanie, aby wdrożyć niestandardowe trasowanie intencji CLU, które jest obsługiwane przez własne wdrożenie dużego modelu językowego, bez konieczności dodawania lub etykietowania jakichkolwiek danych szkoleniowych.
Wymagania wstępne
- Pomyślnie utworzono projekt.
Aby uzyskać więcej informacji, zobacz cykl rozwoju CLU.
Wytyczne dotyczące etykietowania danych
Po utworzeniu schematu i utworzeniu projektu należy oznaczyć je etykietami. Etykietowanie danych jest ważne, aby model wiedział, które zdania i wyrazy są skojarzone z intencjami i jednostkami w projekcie. Poświęcaj czas na etykietowanie wypowiedzi, aby wprowadzić i uściślić dane używane podczas trenowania modeli.
Podczas dodawania wypowiedzi i etykietowania ich należy pamiętać:
Modele uczenia maszynowego są uogólniane na podstawie przekazanych przykładów z etykietami. Im więcej przykładów podajesz, tym więcej punktów danych ma model, aby dokonywać lepszych uogólnień.
Precyzja, spójność i kompletność danych oznaczonych etykietami są kluczowymi czynnikami do określania wydajności modelu:
- Dokładnie oznacz: Oznacz każdą intencję i jednostkę zawsze do odpowiedniego typu. Uwzględnij tylko to, co chcesz sklasyfikować i wyodrębnić. Unikaj niepotrzebnych danych w etykietach.
- Spójna etykieta: Ta sama jednostka powinna mieć tę samą etykietę we wszystkich wypowiedziach.
- Oznacz w pełni: Podaj różne wypowiedzi dla każdej zamierzonej intencji. Oznacz wszystkie wystąpienia jednostki we wszystkich wypowiedziach.
Jasne etykietowanie wypowiedzi
Upewnij się, że pojęcia, do których odwołują się jednostki, są dobrze zdefiniowane i możliwe do ich separowania. Sprawdź, czy możesz łatwo określić różnice niezawodnie. Jeśli nie możesz, ten brak rozróżnienia może wskazywać na trudności dla komponentu poznawczego.
Upewnij się, że jakiś aspekt danych może zapewnić sygnał różnic, gdy istnieje podobieństwo między jednostkami.
Jeśli na przykład utworzono model do zarezerwowania lotów, użytkownik może użyć wypowiedzi, takiej jak "Chcę lotu z Bostonu do Seattle". Oczekuje się, że miasto pochodzenia i miasto docelowe dla takich wypowiedzi będzie podobne. Sygnałem do odróżnienia miasta pochodzenia może być to, że słowo z często go poprzedza.
Upewnij się, że oznaczysz wszystkie wystąpienia każdej jednostki zarówno w danych szkoleniowych, jak i testowych. Jedną z metod jest użycie funkcji wyszukiwania w celu znalezienia wszystkich wystąpień wyrazu lub frazy w danych w celu sprawdzenia, czy są one poprawnie oznaczone.
Upewnij się, że oznaczysz dane testowe dla jednostek bez wyuczonych komponentów, a także dla jednostek z nimi. Ta praktyka pomaga upewnić się, że metryki oceny są dokładne.
W przypadku projektów wielojęzycznych dodawanie wypowiedzi w innych językach zwiększa wydajność modelu w tych językach. Unikaj duplikowania danych we wszystkich językach, które chcesz obsługiwać. Na przykład, aby poprawić funkcjonalność bota kalendarza dla użytkowników, programista może dodać przykłady głównie w języku angielskim oraz kilka w językach hiszpańskim lub francuskim. Mogą one dodawać wypowiedzi, takie jak:
- "Ustaw spotkanie z Mattem i Kevinemjutro o 12:00." (angielski)
- "Odpowiedz jako wstępna na cotygodniowe spotkanie aktualizacji "." (angielski)
- "Anuluj mi próxima reunión." (hiszpański)
Etykietowanie wypowiedzi
Aby oznaczyć wypowiedzi, wykonaj następujące kroki:
Przejdź do strony projektu w narzędziu Azure AI Foundry.
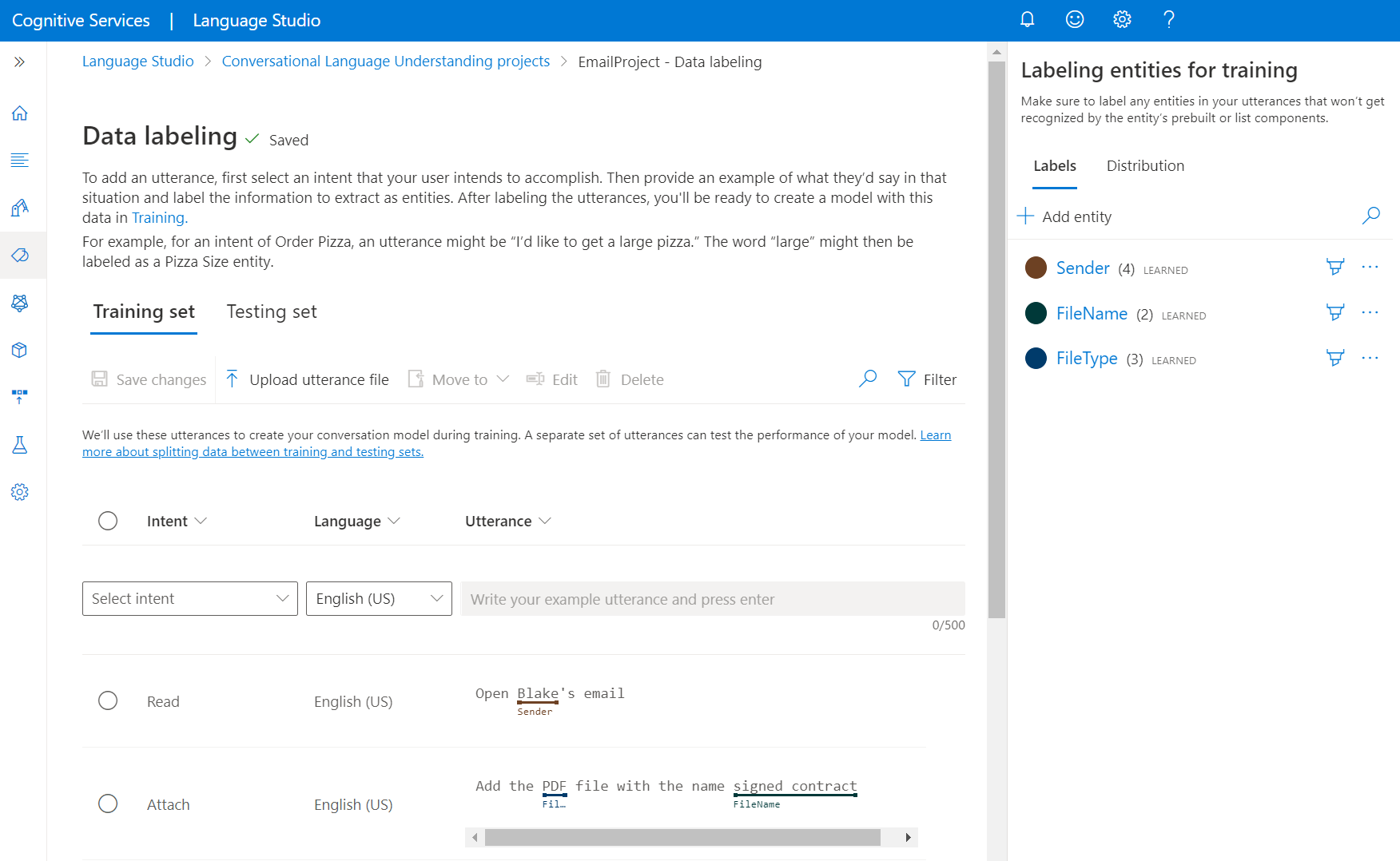
W okienku po lewej stronie wybierz pozycję Zarządzaj danymi. Na tej stronie możesz dodać wypowiedzi i oznaczyć je etykietami. Możesz również przekazać wypowiedzi bezpośrednio, wybierając pozycję Przekaż plik wypowiedzi z górnego menu. Pamiętaj, aby postępować zgodnie z akceptowanym formatem.
Korzystając z kart u góry, możesz zmienić widok na Zestaw trenowania lub Zestaw testowania. Dowiedz się więcej na temat zestawów trenowania i testowania oraz sposobu ich użycia na potrzeby trenowania i oceny modelu.
Napiwek
Jeśli planujesz użyć Automatyczne podzielenie zestawu testowego od danych treningowych, dodaj wszystkie wypowiedzi do zestawu treningowego.
Z menu rozwijanego Wybierz intencję wybierz jedną z intencji, język wypowiedzi (dla projektów wielojęzycznych) i samą wypowiedź. Naciśnij Enter w polu tekstowym wypowiedzi i dodaj wypowiedź.
Istnieją dwie opcje etykietowania jednostek w wypowiedzi:
Opcja Opis Etykieta przy użyciu pędzla Wybierz ikonę pędzla obok jednostki w okienku po prawej stronie, a następnie wyróżnij tekst w wypowiedzi, którą chcesz oznaczyć. Oznacz za pomocą menu wbudowanego Wyróżnij słowo, które chcesz oznaczyć jako jednostkę, i zostanie wyświetlone menu. Wybierz jednostkę, za pomocą której chcesz oznaczyć te wyrazy. W okienku po prawej stronie na karcie Etykiety można znaleźć wszystkie typy jednostek w projekcie i liczbę wystąpień z etykietami na każdy z nich.
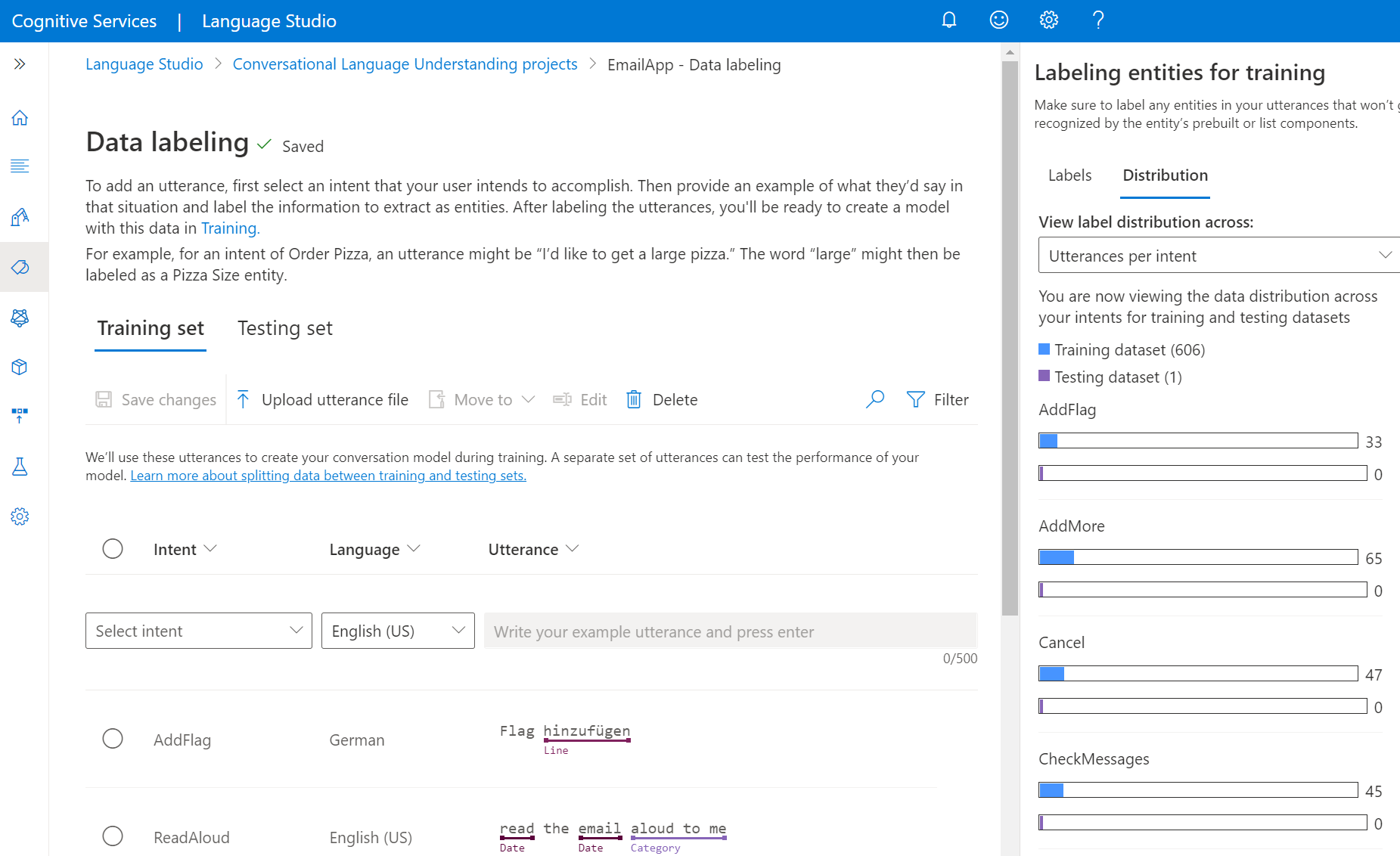
Na karcie Dystrybucja można wyświetlić rozkład między zestawami trenowania i testowania. Dostępne są następujące opcje wyświetlania:
- Łączna liczba wystąpień na jednostkę oznaczona etykietą: Możesz wyświetlić liczbę wszystkich oznaczonych etykietami wystąpień określonej jednostki.
- Unikatowe wypowiedzi na jednostkę oznaczoną etykietą: Każda wypowiedź jest liczona, jeśli zawiera co najmniej jedno wystąpienie oznaczone etykietą tej jednostki.
- Wypowiedzi na intencję: Liczbę wypowiedzi na intencję można wyświetlić.


Uwaga
Składniki list, regex i wstępnie utworzone nie są wyświetlane na stronie etykietowania danych. Wszystkie etykiety mają zastosowanie tylko do poznanego składnika.
Aby usunąć etykietę:
- W wypowiedzi wybierz jednostkę, z której chcesz usunąć etykietę.
- Przewiń wyświetlone menu i wybierz pozycję Usuń etykietę.
Aby usunąć jednostkę:
- Wybierz ikonę kosza na śmieci obok jednostki, którą chcesz edytować w okienku po prawej stronie.
- Wybierz Usuń, aby potwierdzić.
Sugerowanie wypowiedzi za pomocą usługi Azure OpenAI
W narzędziu CLU używaj Azure OpenAI, aby zasugerować wypowiedzi do dodania do projektu, korzystając z generatywnych modeli językowych. Zalecamy użycie zasobu usługi Azure AI Foundry podczas korzystania z jednostki CLU, aby nie trzeba było łączyć wielu zasobów.
Aby korzystać z zasobu Azure AI Foundry, musisz zapewnić mu podwyższony poziom dostępu. W tym celu uzyskaj dostęp do witryny Azure Portal. W ramach zasobu usługi Azure AI zapewnij dostęp jako użytkownik usług Cognitive Services do samego siebie. Ten krok gwarantuje, że wszystkie części zasobu komunikują się poprawnie.
Łączenie się z oddzielnymi zasobami Language i Azure OpenAI
Najpierw musisz uzyskać dostęp i utworzyć zasób w usłudze Azure OpenAI. Następnie utwórz połączenie z zasobem usługi Azure OpenAI w ramach tego samego projektu rozwiązania Azure AI Foundry w centrum zarządzania w lewym okienku strony usługi Azure AI Foundry. Następnie należy utworzyć wdrożenie dla modeli usługi Azure OpenAI w ramach połączonego zasobu usługi Azure OpenAI. Aby utworzyć nowy zasób, wykonaj kroki opisane w artykule Tworzenie i wdrażanie usługi Azure OpenAI w zasobie Azure AI Foundry Models.
Przed rozpoczęciem, funkcja propozycji wypowiedzi jest dostępna tylko wtedy, gdy zasób językowy znajduje się w następujących regionach.
- Wschodnie stany USA
- Południowo-środkowe stany USA
- Europa Zachodnia
Na stronie Etykietowanie danych :
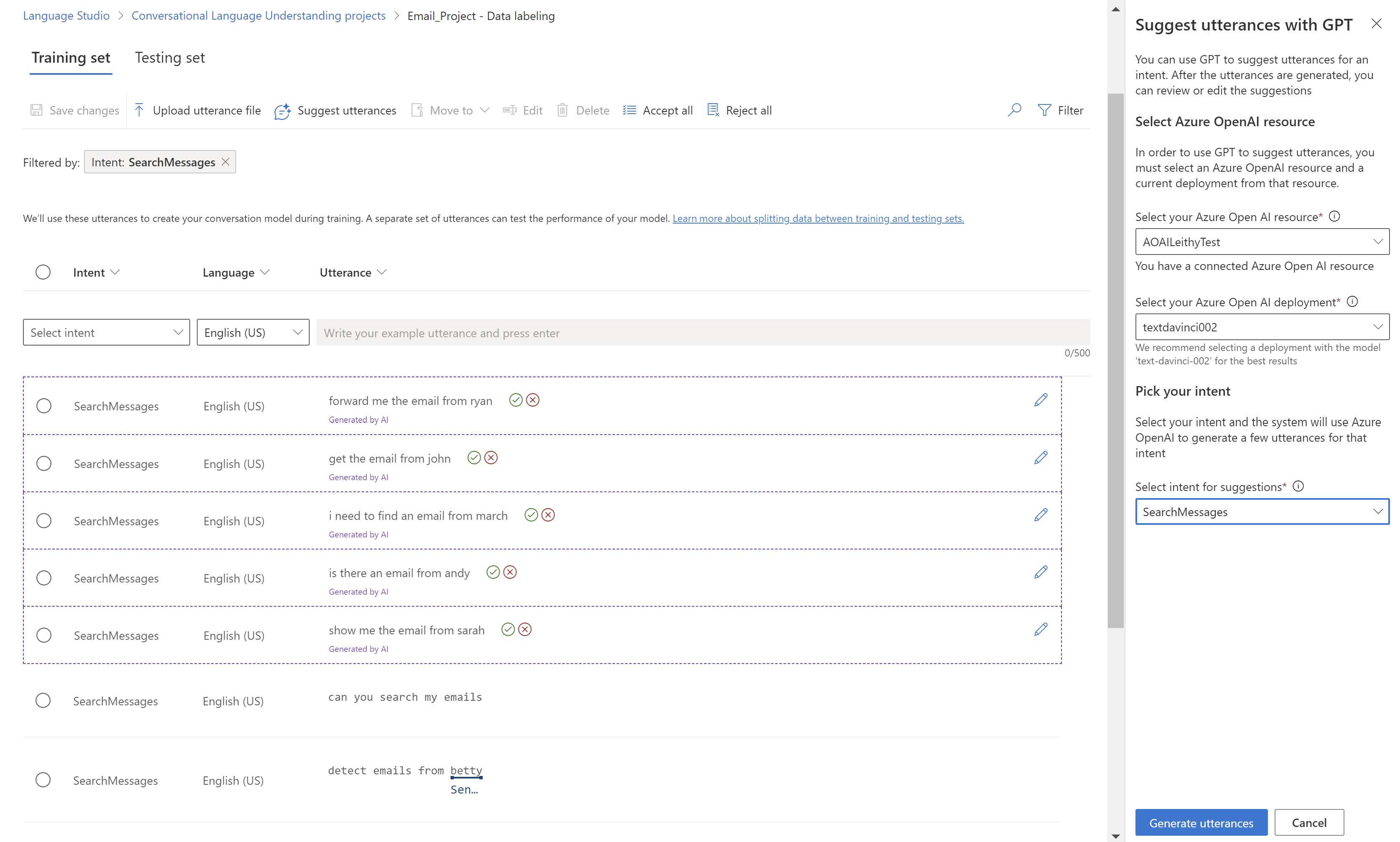
Wybierz pozycję Zaproponuj wypowiedzi. Po prawej stronie zostanie otwarte okienko z monitem o wybranie zasobu i wdrożenia usługi Azure OpenAI.
Po wybraniu zasobu azure OpenAI wybierz pozycję Połącz , aby zasób Language miał bezpośredni dostęp do zasobu usługi Azure OpenAI. Przypisuje Twojemu zasobowi językowemu rolę użytkownika usług Cognitive Services do zasobu usługi Azure OpenAI. Teraz bieżący zasób językowy ma dostęp do usługi Azure OpenAI. Jeśli połączenie nie powiedzie się, wykonaj następujące kroki , aby ręcznie dodać poprawną rolę do zasobu usługi Azure OpenAI.
Po nawiązaniu połączenia z zasobem wybierz wdrożenie. Zalecanym modelem wdrożenia usługi Azure OpenAI jest
gpt-35-turbo-instruct.Wybierz intencję, dla której chcesz uzyskać sugestie. Upewnij się, że wybrana intencja zawiera co najmniej pięć zapisanych wypowiedzi, aby mogła być używana do sugestii wypowiedzi. Sugestie udostępniane przez usługę Azure OpenAI są oparte na najnowszych wypowiedziach dodanych dla tego celu.
Wybierz pozycję Generuj wypowiedzi.
Sugerowane wypowiedzi są wyświetlane z kropkowaną linią wokół nich i notatką wygenerowaną przez sztuczną inteligencję. Te sugestie muszą zostać zaakceptowane lub odrzucone. Zaakceptowanie sugestii spowoduje dodanie jej do projektu, tak jakby zostało ono dodane samodzielnie. Odrzucenie sugestii powoduje jego całkowite usunięcie. Tylko zaakceptowane wypowiedzi są częścią projektu i są używane do trenowania lub testowania.
Aby zaakceptować lub odrzucić, wybierz zielony znacznik wyboru lub czerwone przyciski anulowania obok każdej wypowiedzi. Możesz również użyć opcji Zaakceptuj wszystkie i Odrzuć wszystkie na pasku narzędzi.

Użycie tej funkcji wiąże się z opłatą za zasób usługi Azure OpenAI za liczbę tokenów odpowiadającą generowanym sugerowanym wypowiedziom. Aby uzyskać informacje na temat cennika usługi Azure OpenAI, zobacz Cennik usługi Azure OpenAI.
Dodawanie wymaganych konfiguracji do zasobu usługi Azure OpenAI
Włącz zarządzanie tożsamościami dla zasobu language, korzystając z poniższych opcji.
Zasób języka musi mieć zarządzanie tożsamością. Aby ją włączyć przy użyciu witryny Azure Portal:
- Przejdź do zasobu Język.
- W okienku po lewej stronie w sekcji Zarządzanie zasobami wybierz pozycję Tożsamość.
- Na karcie System przypisany ustaw Status na Włączony.
Po włączeniu tożsamości zarządzanej przypisz rolę użytkownika usług Cognitive Services do zasobu usługi Azure OpenAI przy użyciu tożsamości zarządzanej zasobu Language.
Zaloguj się do witryny Azure Portal i przejdź do zasobu azure OpenAI.
Wybierz kartę Kontrola dostępu (IAM).
Wybierz Dodaj>Dodaj przypisanie roli.
Wybierz Role funkcji zadania i Dalej.
Wybierz pozycję Użytkownik usług Cognitive Services z listy ról, a następnie wybierz pozycję Dalej.
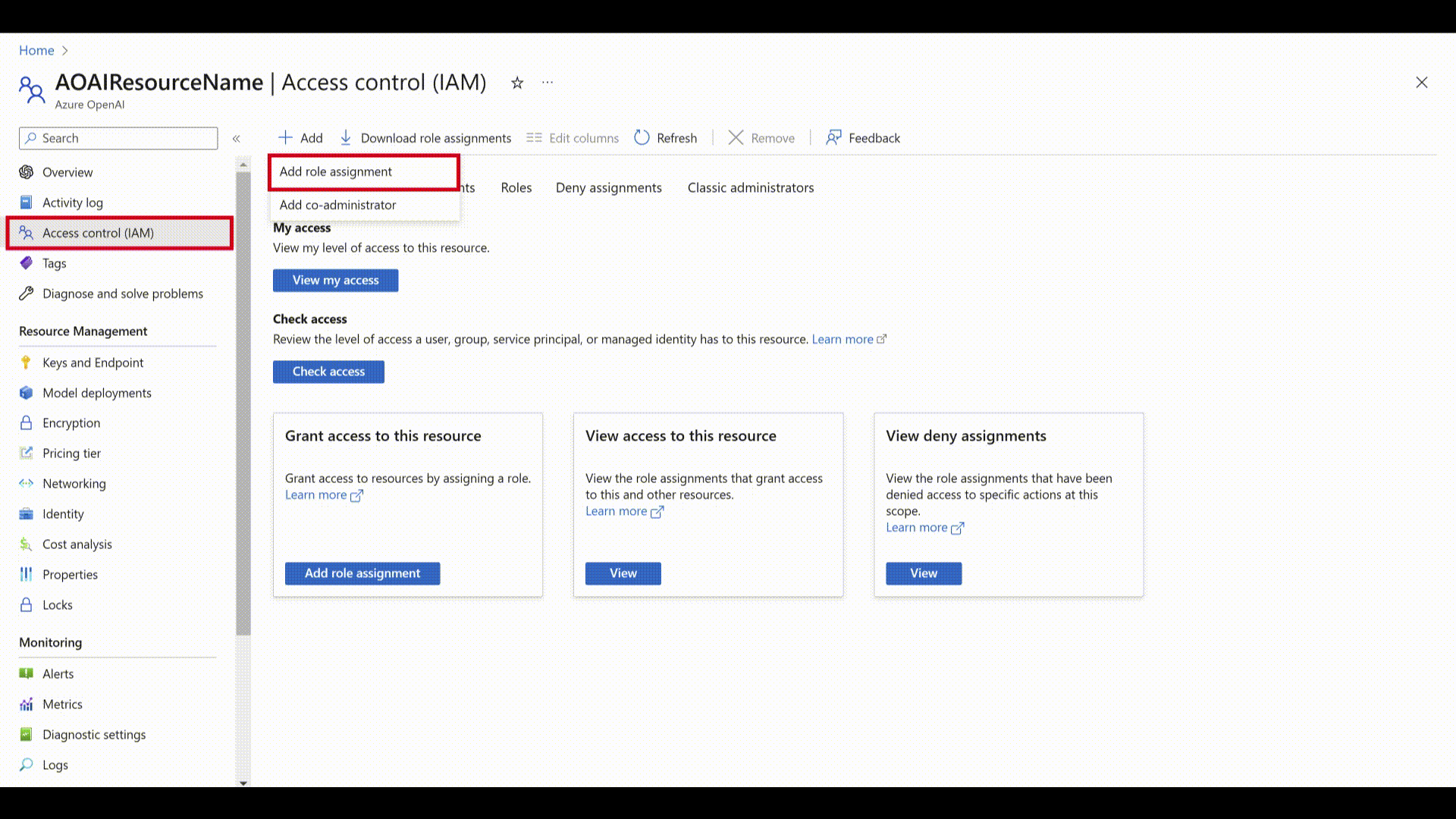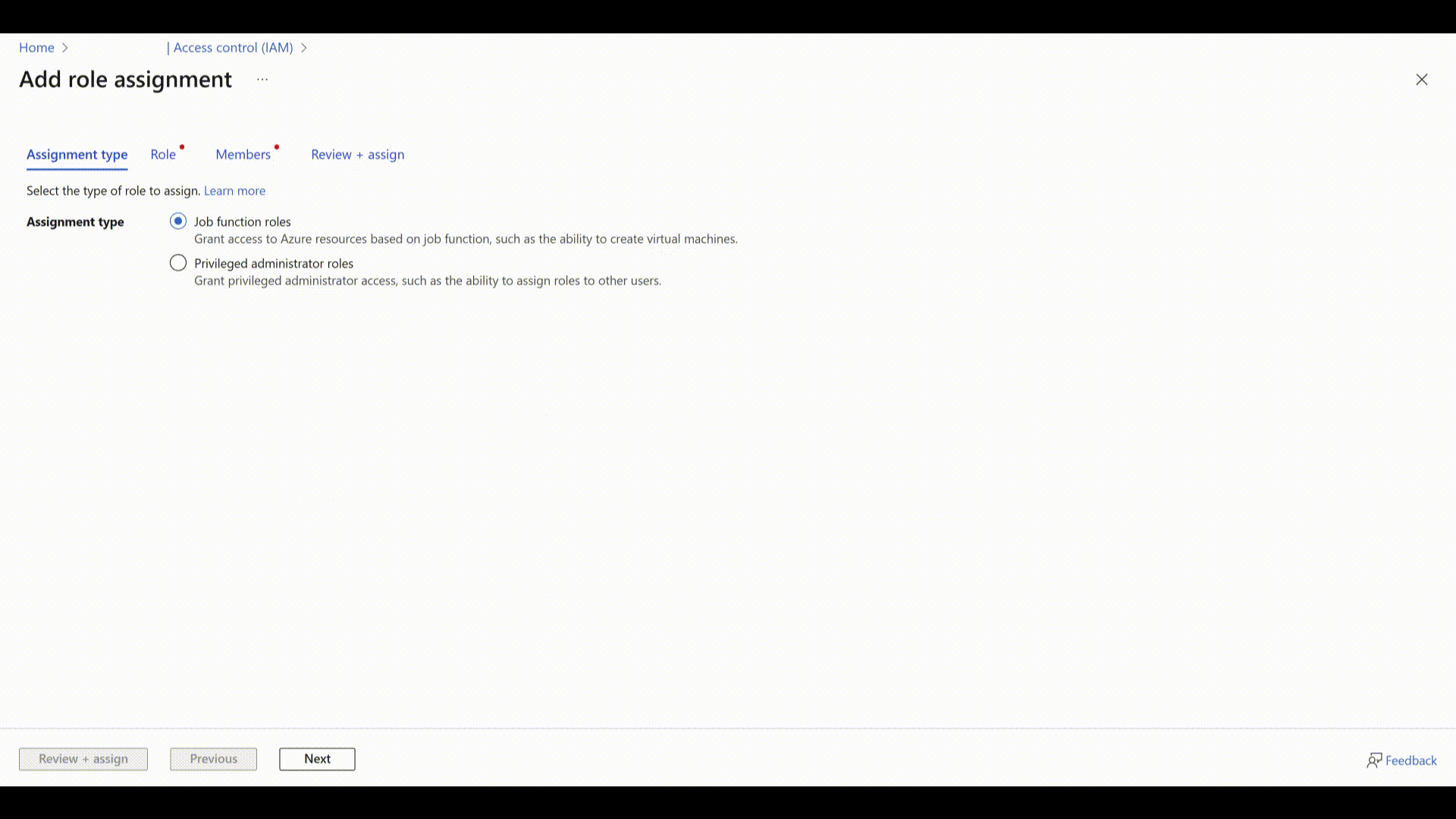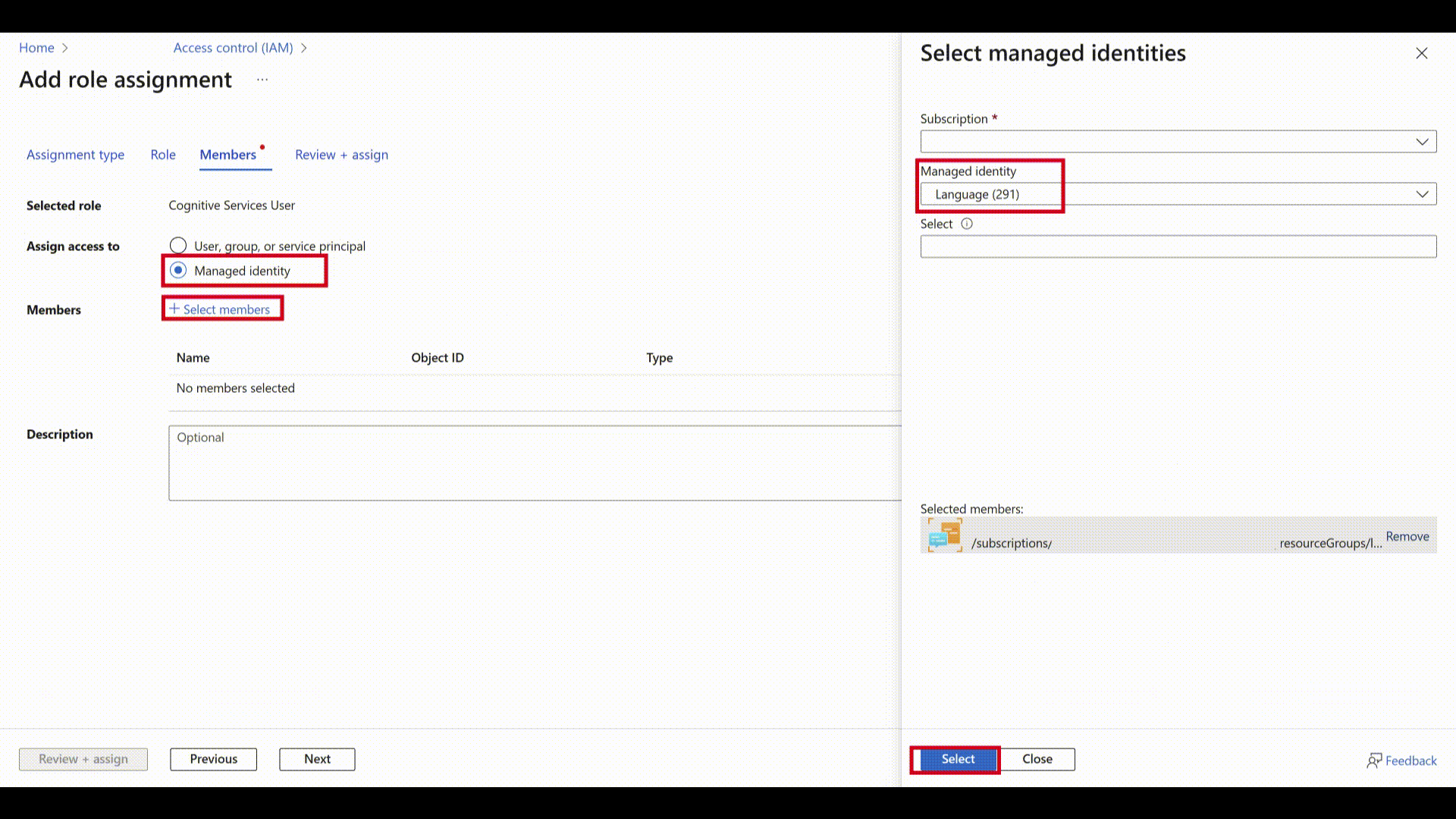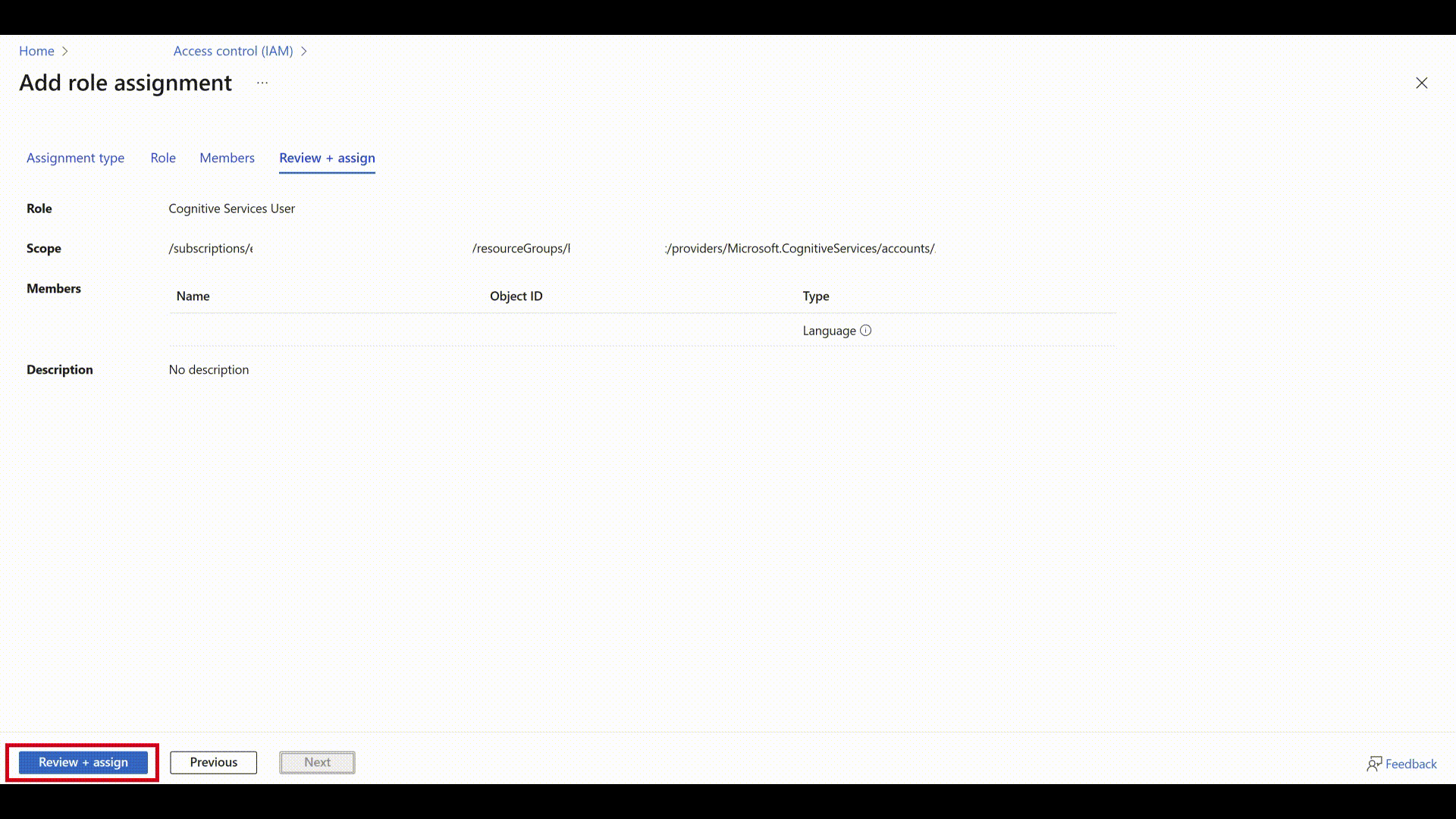
Wybierz Przypisz dostęp do: Tożsamość zarządzana i Wybierz członków.
W obszarze Tożsamość zarządzana wybierz pozycję Język.
Wyszukaj zasób i wybierz go. Następnie wybierz pozycję Dalej i ukończ proces.
Przejrzyj szczegóły i wybierz Przejrzyj i przypisz.

Po kilku minutach odśwież usługę Azure AI Foundry i możesz pomyślnie nawiązać połączenie z usługą Azure OpenAI.