Wskaźnik ufności odpowiedzi
Gdy zapytanie użytkownika jest dopasowane do baza wiedzy, usługa QnA Maker zwraca odpowiednie odpowiedzi wraz z oceną ufności. Ten wynik wskazuje pewność, że odpowiedź jest odpowiednia dla danego zapytania użytkownika.
Współczynnik ufności to liczba z zakresu od 0 do 100. Wynik 100 jest prawdopodobnie dokładnym dopasowaniem, a wynik 0 oznacza, że nie znaleziono pasującej odpowiedzi. Im wyższy wynik — tym większe zaufanie do odpowiedzi. W przypadku danego zapytania może zostać zwróconych wiele odpowiedzi. W takim przypadku odpowiedzi są zwracane w celu zmniejszenia wskaźnika ufności.
W poniższym przykładzie można zobaczyć jedną jednostkę pytań i odpowiedzi z 2 pytaniami.

W powyższym przykładzie można oczekiwać wyników, takich jak poniższy przykładowy zakres wyników dla różnych typów zapytań użytkownika:
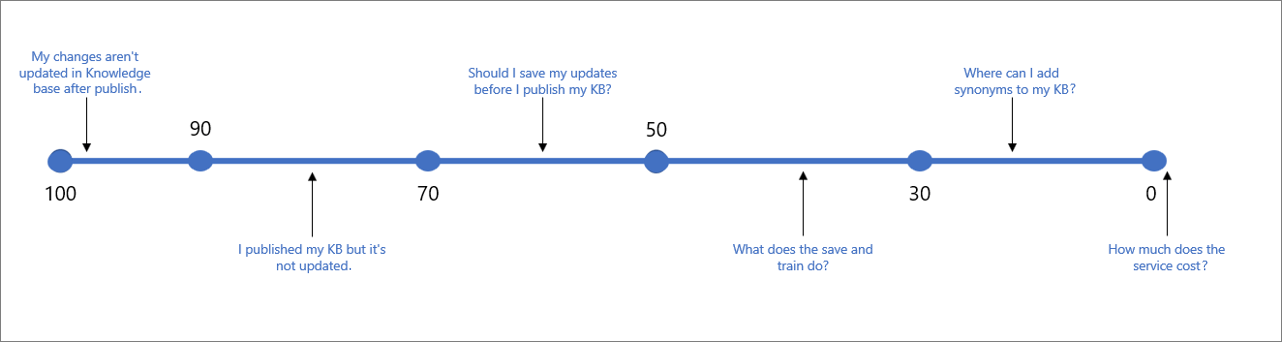
W poniższej tabeli przedstawiono typową pewność skojarzona z danym wynikiem.
| Wartość wyniku | Znaczenie wyniku | Przykładowe zapytanie |
|---|---|---|
| 90 - 100 | Niemal dokładne dopasowanie zapytania użytkownika i pytanie BAZY wiedzy | "Moje zmiany nie są aktualizowane w bazie wiedzy po opublikowaniu" |
| > 70 | Wysoka pewność — zazwyczaj dobra odpowiedź, która całkowicie odpowiada na zapytanie użytkownika | "Opublikowano moją bazę wiedzy, ale nie jest ona aktualizowana" |
| 50 - 70 | Średnia pewność — zazwyczaj dość dobra odpowiedź, która powinna odpowiadać na główną intencję zapytania użytkownika | "Czy należy zapisać aktualizacje przed opublikowaniem bazy wiedzy?" |
| 30 - 50 | Niska pewność — zazwyczaj powiązana odpowiedź, która częściowo odpowiada na intencję użytkownika | " Co robi zapisywanie i szkolenie?" |
| < 30 | Bardzo niska pewność siebie — zazwyczaj nie odpowiada na zapytanie użytkownika, ale zawiera pasujące wyrazy lub frazy | " Gdzie mogę dodać synonimy do mojej bazy wiedzy" |
| 0 | Brak dopasowania, więc odpowiedź nie jest zwracana. | "Ile kosztuje usługa" |
Wybierz próg oceny
W powyższej tabeli przedstawiono wyniki oczekiwane dla większości KB. Jednak ponieważ każda baza wiedzy jest inna i ma różne typy słów, intencji i celów— zalecamy przetestowanie i wybranie progu, który najlepiej działa dla Ciebie. Domyślnie próg jest ustawiony na 0, aby wszystkie możliwe odpowiedzi zostały zwrócone. Zalecany próg, który powinien działać dla większości KB, wynosi 50.
Podczas wybierania progu należy pamiętać o równowadze między dokładnością a pokryciem i dostosować próg w zależności od wymagań.
Jeśli dokładność (lub precyzja) jest ważniejsza dla danego scenariusza, zwiększ próg. Dzięki temu za każdym razem, gdy zwracasz odpowiedź, będzie to znacznie bardziej pewny siebie przypadek i znacznie bardziej prawdopodobne, że użytkownicy odpowiedzi szukają. W takim przypadku może się skończyć pozostawienie większej liczby pytań bez odpowiedzi. Na przykład: jeśli próg 70 zostanie przekroczony, możesz przegapić kilka niejednoznacznych przykładów, takich jak "co to jest zapisywanie i trenowanie?".
Jeśli pokrycie (lub kompletność) jest ważniejsze — i chcesz odpowiedzieć na jak najwięcej pytań, nawet jeśli istnieje tylko częściowa relacja z pytaniem użytkownika, a następnie obniżyć próg. Oznacza to, że może istnieć więcej przypadków, w których odpowiedź nie odpowiada na rzeczywiste zapytanie użytkownika, ale daje inną nieco powiązaną odpowiedź. Na przykład: jeśli ustawisz próg 30, możesz udzielić odpowiedzi na pytania, takie jak "Gdzie mogę edytować moją bazę wiedzy?"
Uwaga
Nowsze wersje usługi QnA Maker obejmują ulepszenia logiki oceniania i mogą mieć wpływ na próg. Za każdym razem, gdy zaktualizujesz usługę, upewnij się, że w razie potrzeby przetestuj i dostosuj próg. Możesz sprawdzić wersję usługi QnA tutaj i zobaczyć, jak uzyskać najnowsze aktualizacje tutaj.
Ustaw próg
Ustaw wynik progu jako właściwość treści JSON interfejsu API GenerateAnswer. Oznacza to, że dla każdego wywołania metody GenerateAnswer jest ustawiana wartość .
W strukturze botów ustaw wynik jako część obiektu options za pomocą języka C# lub Node.js.
Zwiększanie współczynników ufności
Aby zwiększyć współczynnik ufności konkretnej odpowiedzi na zapytanie użytkownika, możesz dodać zapytanie użytkownika do baza wiedzy jako alternatywne pytanie dotyczące tej odpowiedzi. Możesz również użyć zmian wyrazów bez uwzględniania wielkości liter, aby dodać synonimy do słów kluczowych w bazie wiedzy.
Podobne wyniki ufności
Jeśli wiele odpowiedzi ma podobny współczynnik ufności, prawdopodobnie zapytanie było zbyt ogólne i dlatego było zgodne z równym prawdopodobieństwem z wieloma odpowiedziami. Spróbuj lepiej utworzyć strukturę pytań i odpowiedzi, aby każda jednostka pytań i odpowiedzi ma odrębną intencję.
Różnice współczynnika ufności między testem a produkcją
Współczynnik ufności odpowiedzi może nieco się zmieniać między testową i opublikowaną wersją bazy wiedzy, nawet jeśli zawartość jest taka sama. Dzieje się tak, ponieważ zawartość testu i opublikowanego baza wiedzy znajdują się w różnych indeksach usługi Azure AI Search.
Indeks testowy przechowuje wszystkie pary pytań i odpowiedzi baza wiedzy. Podczas wykonywania zapytań względem indeksu testowego zapytanie dotyczy całego indeksu, a wyniki są ograniczone do partycji dla tej konkretnej baza wiedzy. Jeśli wyniki zapytania testowego negatywnie wpływają na możliwość weryfikacji baza wiedzy, możesz:
- organizowanie baza wiedzy przy użyciu jednego z następujących elementów:
- 1 zasób ograniczony do 1 KB: ogranicz pojedynczy zasób QnA (i wynikowy indeks testowy usługi Azure AI Search) do pojedynczego baza wiedzy.
- 2 zasoby — 1 do testowania, 1 dla środowiska produkcyjnego: mają dwa zasoby usługi QnA Maker, używając jednego do testowania (z własnymi indeksami testowymi i produkcyjnymi) i jeden dla produktu (również z własnymi indeksami testowymi i produkcyjnymi)
- i zawsze używaj tych samych parametrów, takich jak top podczas wykonywania zapytań dotyczących zarówno testowych, jak i produkcyjnych baza wiedzy
Podczas publikowania baza wiedzy zawartość pytania i odpowiedzi baza wiedzy przechodzi z indeksu testowego do indeksu produkcyjnego w usłudze Azure Search. Zobacz, jak działa operacja publikowania.
Jeśli masz baza wiedzy w różnych regionach, każdy region używa własnego indeksu usługi Azure AI Search. Ponieważ są używane różne indeksy, wyniki nie będą dokładnie takie same.
Nie znaleziono dopasowania
Jeśli nie zostanie znalezione dobre dopasowanie przez klasyfikator, zwracany jest współczynnik ufności 0,0 lub "Brak", a domyślna odpowiedź to "Nie znaleziono dobrego dopasowania w kb". Tę domyślną odpowiedź można zastąpić w kodzie bota lub aplikacji wywołującym punkt końcowy. Alternatywnie można również ustawić odpowiedź przesłaniania na platformie Azure i to zmienia wartość domyślną dla wszystkich baza wiedzy wdrożonych w określonej usłudze QnA Maker.