Interfejs API syntezy usługi Batch na potrzeby zamiany tekstu na mowę
Interfejs API syntezy usługi Batch może syntetyzować dużą ilość danych wejściowych tekstu (długich i krótkich) asynchronicznie. Wydawcy i platformy zawartości audio mogą tworzyć długą zawartość audio w partii. Na przykład: książki audio, artykuły z wiadomościami i dokumenty. Interfejs API syntezy wsadowej może utworzyć syntetyzowany dźwięk dłuższy niż 10 minut.
Ważne
Interfejs API syntezy usługi Batch jest ogólnie dostępny. Interfejs Long Audio API zostanie wycofany 1 kwietnia 2027 r. Aby uzyskać więcej informacji, zobacz Migrowanie do interfejsu API syntezy wsadowej.
Interfejs API syntezy wsadowej jest asynchroniczny i nie zwraca syntetyzowanego dźwięku w czasie rzeczywistym. Przesyłasz pliki tekstowe do syntetyzowania, sondowania stanu i pobierania danych wyjściowych dźwięku, gdy stan wskazuje powodzenie. Dane wejściowe tekstu muszą mieć zwykły tekst lub tekst języka SSML (Speech Synthesis Markup Language).
Ten diagram zawiera ogólne omówienie przepływu pracy.
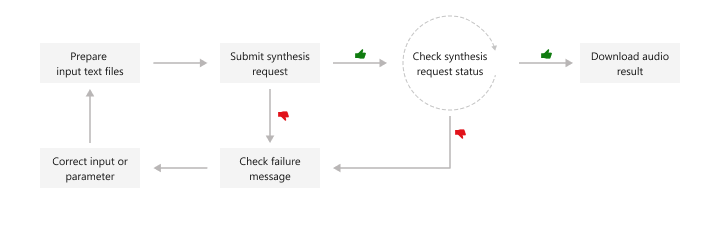
Napiwek
Zestaw SPEECH SDK umożliwia również tworzenie syntetyzowanego dźwięku dłuższego niż 10 minut przez iterowanie tekstu i synchronizowanie go we fragmentach. Aby zapoznać się z przykładem języka C#, zobacz GitHub.
Na potrzeby syntezy wsadowej można użyć następujących operacji interfejsu API REST:
| Operacja | Method | Wywołanie interfejsu API REST |
|---|---|---|
| Tworzenie syntezy wsadowej | PUT |
texttospeech/batchsyntheses/YourSynthesisId |
| Pobieranie syntezy wsadowej | GET |
texttospeech/batchsyntheses/YourSynthesisId |
| Lista syntezy wsadowej | GET |
texttospeech/batchsyntheses |
| Usuwanie syntezy wsadowej | DELETE |
texttospeech/batchsyntheses/YourSynthesisId |
Aby zapoznać się z przykładami kodu, zobacz GitHub.
Tworzenie syntezy wsadowej
Aby przesłać żądanie syntezy wsadowej, skonstruuj ścieżkę żądania HTTP PUT i treść zgodnie z następującymi instrukcjami:
- Ustaw wymaganą
inputKindwłaściwość. inputKindJeśli właściwość jest ustawiona na wartość "PlainText", należy również ustawićvoicewłaściwość w obiekciesynthesisConfig. W poniższyminputKindprzykładzie parametr jest ustawiony na wartość "SSML", więcsynthesisConfigparametr nie jest ustawiony.- Opcjonalnie można ustawić
descriptionwłaściwości ,timeToLiveInHoursi inne. Aby uzyskać więcej informacji, zobacz właściwości syntezy wsadowej.
Uwaga
Maksymalny rozmiar ładunku JSON, który jest akceptowany, to 2 megabajty.
Ustaw wartość wymaganą YourSynthesisId w ścieżce. Element YourSynthesisId musi być unikatowy. Musi mieć długość od 3 do 64, zawiera tylko cyfry, litery, łączniki, podkreślenia i kropki, rozpoczyna się i kończy literą lub cyfrą.
Utwórz żądanie HTTP PUT przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie. Zastąp YourSpeechKey ciąg kluczem zasobu usługi Mowa, zastąp YourSpeechRegion element regionem zasobu usługi Mowa i ustaw właściwości treści żądania zgodnie z wcześniejszym opisem.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourSpeechKey" -H "Content-Type: application/json" -d '{
"description": "my ssml test",
"inputKind": "SSML",
"inputs": [
{
"content": "<speak version=\"1.0\" xml:lang=\"en-US\"><voice name=\"en-US-JennyNeural\">The rainbow has seven colors.</voice></speak>"
}
],
"properties": {
"outputFormat": "riff-24khz-16bit-mono-pcm",
"wordBoundaryEnabled": false,
"sentenceBoundaryEnabled": false,
"concatenateResult": false,
"decompressOutputFiles": false
}
}' "https://YourSpeechRegion.api.cognitive.microsoft.com/texttospeech/batchsyntheses/YourSynthesisId?api-version=2024-04-01"
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"id": "YourSynthesisId",
"internalId": "7ab84171-9070-4d3b-88d4-1b8cc1cb928a",
"status": "NotStarted",
"createdDateTime": "2024-03-12T07:23:18.0097387Z",
"lastActionDateTime": "2024-03-12T07:23:18.0097388Z",
"inputKind": "SSML",
"customVoices": {},
"properties": {
"timeToLiveInHours": 744,
"outputFormat": "riff-24khz-16bit-mono-pcm",
"concatenateResult": false,
"decompressOutputFiles": false,
"wordBoundaryEnabled": false,
"sentenceBoundaryEnabled": false
}
}
Właściwość status powinna przechodzić ze NotStarted stanu do Running, i na koniec do Succeeded lub Failed. Interfejs API syntezy wsadowej GET można wywołać okresowo do momentu, gdy zwrócony stan to Succeeded lub Failed.
Pobieranie syntezy wsadowej
Aby uzyskać stan zadania syntezy wsadowej, utwórz żądanie HTTP GET przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie. Zastąp YourSpeechKey ciąg kluczem zasobu usługi Mowa i zastąp YourSpeechRegion element regionem zasobu usługi Mowa.
curl -v -X GET "https://YourSpeechRegion.api.cognitive.microsoft.com/texttospeech/batchsyntheses/YourSynthesisId?api-version=2024-04-01" -H "Ocp-Apim-Subscription-Key: YourSpeechKey"
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"id": "YourSynthesisId",
"internalId": "7ab84171-9070-4d3b-88d4-1b8cc1cb928a",
"status": "Succeeded",
"createdDateTime": "2024-03-12T07:23:18.0097387Z",
"lastActionDateTime": "2024-03-12T07:23:18.7979669",
"inputKind": "SSML",
"customVoices": {},
"properties": {
"timeToLiveInHours": 744,
"outputFormat": "riff-24khz-16bit-mono-pcm",
"concatenateResult": false,
"decompressOutputFiles": false,
"wordBoundaryEnabled": false,
"sentenceBoundaryEnabled": false,
"sizeInBytes": 120000,
"succeededAudioCount": 1,
"failedAudioCount": 0,
"durationInMilliseconds": 2500,
"billingDetails": {
"neuralCharacters": 29
}
},
"outputs": {
"result": "https://stttssvcuse.blob.core.windows.net/batchsynthesis-output/29f2105f997c4bfea176d39d05ff201e/YourSynthesisId/results.zip?SAS_Token"
}
}
W outputs.resultprogramie możesz pobrać plik ZIP zawierający dźwięk (na przykład 0001.wav), podsumowanie i szczegóły debugowania. Aby uzyskać więcej informacji, zobacz wyniki syntezy wsadowej.
Lista syntezy wsadowej
Aby wyświetlić listę wszystkich zadań syntezy wsadowej dla zasobu usługi Mowa, utwórz żądanie HTTP GET przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie. Zastąp YourSpeechKey ciąg kluczem zasobu usługi Mowa i zastąp YourSpeechRegion element regionem zasobu usługi Mowa. Opcjonalnie można ustawić skip parametry zapytania i maxpagesize (maksymalnie 100) w adresie URL. Wartość domyślna parametru skip to 0, a wartość maxpagesize domyślna to 100.
curl -v -X GET "https://YourSpeechRegion.api.cognitive.microsoft.com/texttospeech/batchsyntheses?api-version=2024-04-01&skip=1&maxpagesize=2" -H "Ocp-Apim-Subscription-Key: YourSpeechKey"
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"value": [
{
"id": "my-job-03",
"internalId": "5f7e9ab6-2c92-4dcb-b5ee-ec0983ee4db0",
"status": "Succeeded",
"createdDateTime": "2024-03-12T07:28:32.5690441Z",
"lastActionDateTime": "2024-03-12T07:28:33.0042293",
"inputKind": "SSML",
"customVoices": {},
"properties": {
"timeToLiveInHours": 744,
"outputFormat": "riff-24khz-16bit-mono-pcm",
"concatenateResult": false,
"decompressOutputFiles": false,
"wordBoundaryEnabled": false,
"sentenceBoundaryEnabled": false,
"sizeInBytes": 120000,
"succeededAudioCount": 1,
"failedAudioCount": 0,
"durationInMilliseconds": 2500,
"billingDetails": {
"neuralCharacters": 29
}
},
"outputs": {
"result": "https://stttssvcuse.blob.core.windows.net/batchsynthesis-output/29f2105f997c4bfea176d39d05ff201e/my-job-03/results.zip?SAS_Token"
}
},
{
"id": "my-job-02",
"internalId": "5577585f-4710-4d4f-aab6-162d14bd7ee0",
"status": "Succeeded",
"createdDateTime": "2024-03-12T07:28:29.6418211Z",
"lastActionDateTime": "2024-03-12T07:28:30.0910306",
"inputKind": "SSML",
"customVoices": {},
"properties": {
"timeToLiveInHours": 744,
"outputFormat": "riff-24khz-16bit-mono-pcm",
"concatenateResult": false,
"decompressOutputFiles": false,
"wordBoundaryEnabled": false,
"sentenceBoundaryEnabled": false,
"sizeInBytes": 120000,
"succeededAudioCount": 1,
"failedAudioCount": 0,
"durationInMilliseconds": 2500,
"billingDetails": {
"neuralCharacters": 29
}
},
"outputs": {
"result": "https://stttssvcuse.blob.core.windows.net/batchsynthesis-output/29f2105f997c4bfea176d39d05ff201e/my-job-02/results.zip?SAS_Token"
}
}
],
"nextLink": "https://YourSpeechRegion.api.cognitive.microsoft.com/texttospeech/batchsyntheses?skip=3&maxpagesize=2&api-version=2024-04-01"
}
W outputs.resultprogramie możesz pobrać plik ZIP zawierający dźwięk (na przykład 0001.wav), podsumowanie i szczegóły debugowania. Aby uzyskać więcej informacji, zobacz wyniki syntezy wsadowej.
Właściwość value w odpowiedzi json zawiera listę żądań syntezy. Lista jest podzielony na strony z maksymalnym rozmiarem strony 100. Właściwość "nextLink" jest udostępniana zgodnie z potrzebami, aby uzyskać następną stronę listy podzielonej na strony.
Usuwanie syntezy wsadowej
Usuń historię zadania syntezy wsadowej po pobraniu wyników wyjściowych dźwięku. Usługa rozpoznawania mowy przechowuje historię syntezy wsadowej przez maksymalnie 31 dni lub czas trwania właściwości żądania timeToLiveInHours , w zależności od tego, co nastąpi wcześniej. Data i godzina automatycznego usuwania (w przypadku zadań syntezy ze stanem "Powodzenie" lub "Niepowodzenie") jest równa lastActionDateTime + timeToLiveInHours właściwościom.
Aby usunąć zadanie syntezy wsadowej, utwórz żądanie HTTP DELETE przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie. Zastąp YourSynthesisId ciąg identyfikatorem syntezy wsadowej, zastąp ciąg kluczem zasobu usługi Mowa i zastąp YourSpeechKey YourSpeechRegion element regionem zasobu usługi Mowa.
curl -v -X DELETE "https://YourSpeechRegion.api.cognitive.microsoft.com/texttospeech/batchsyntheses/YourSynthesisId?api-version=2024-04-01" -H "Ocp-Apim-Subscription-Key: YourSpeechKey"
Nagłówki odpowiedzi zawierają HTTP/1.1 204 No Content informację, czy żądanie usunięcia zakończyło się pomyślnie.
Wyniki syntezy wsadowej
Po pobraniu zadania syntezy wsadowej z komunikatem status "Powodzenie" możesz pobrać wyniki wyjściowe audio. Użyj adresu URL z outputs.result właściwości odpowiedzi GET syntezy wsadowej.
Aby uzyskać plik wyników syntezy wsadowej, utwórz żądanie HTTP GET przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie. Zastąp YourOutputsResultUrl ciąg adresem URL właściwości outputs.result odpowiedzi GET syntezy wsadowej. Zastąp YourSpeechKey ciąg kluczem zasobu usługi Mowa.
curl -v -X GET "YourOutputsResultUrl" -H "Ocp-Apim-Subscription-Key: YourSpeechKey" > results.zip
Wyniki znajdują się w pliku ZIP zawierającym dźwięk (na przykład 0001.wav), podsumowanie i szczegóły debugowania. Numerowany prefiks każdej nazwy pliku (pokazany poniżej jako ) jest w takiej samej kolejności, [nnnn]jak dane wejściowe tekstu używane podczas tworzenia syntezy wsadowej.
Uwaga
Plik [nnnn].debug.json zawiera identyfikator wyniku syntezy i inne informacje, które mogą pomóc w rozwiązywaniu problemów. Właściwości, które zawiera, mogą ulec zmianie, więc nie należy brać żadnych zależności od formatu JSON.
Plik podsumowania zawiera wyniki syntezy dla każdego wejściowego tekstu. Oto przykładowy summary.json plik:
{
"jobID": "7ab84171-9070-4d3b-88d4-1b8cc1cb928a",
"status": "Succeeded",
"results": [
{
"contents": [
"<speak version=\"1.0\" xml:lang=\"en-US\"><voice name=\"en-US-JennyNeural\">The rainbow has seven colors.</voice></speak>"
],
"status": "Succeeded",
"audioFileName": "0001.wav",
"properties": {
"sizeInBytes": "120000",
"durationInMilliseconds": "2500"
}
}
]
}
Jeśli zażądano danych granic zdań ("sentenceBoundaryEnabled": true), odpowiedni [nnnn].sentence.json plik zostanie uwzględniony w wynikach. Podobnie, jeśli zażądano danych granicy wyrazu ("wordBoundaryEnabled": true), odpowiedni [nnnn].word.json plik zostanie uwzględniony w wynikach.
Oto przykładowy plik danych wyrazów z przesunięciem dźwięku i czasem trwania w milisekundach:
[
{
"Text": "The",
"AudioOffset": 50,
"Duration": 137
},
{
"Text": "rainbow",
"AudioOffset": 200,
"Duration": 350
},
{
"Text": "has",
"AudioOffset": 562,
"Duration": 175
},
{
"Text": "seven",
"AudioOffset": 750,
"Duration": 300
},
{
"Text": "colors",
"AudioOffset": 1062,
"Duration": 625
},
{
"Text": ".",
"AudioOffset": 1700,
"Duration": 100
}
]
Opóźnienie syntezy wsadowej i najlepsze rozwiązania
Podczas używania syntezy wsadowej do generowania syntetyzowanej mowy należy wziąć pod uwagę związane z opóźnieniami i postępować zgodnie z najlepszymi rozwiązaniami w celu uzyskania optymalnych wyników.
Opóźnienie syntezy wsadowej
Opóźnienie syntezy wsadowej zależy od różnych czynników, w tym złożoności tekstu wejściowego, liczby danych wejściowych w partii oraz możliwości przetwarzania bazowego sprzętu.
Opóźnienie syntezy wsadowej jest następujące (w przybliżeniu):
Opóźnienie 50% syntetyzowanych danych wyjściowych mowy wynosi od 10 do 20 sekund.
Opóźnienie 95% syntetyzowanych danych wyjściowych mowy wynosi 120 sekund.
Najlepsze rozwiązania
Podczas rozważania syntezy wsadowej dla aplikacji zaleca się ocenę, czy opóźnienie spełnia twoje wymagania. Jeśli opóźnienie jest zgodne z żądaną wydajnością, synteza wsadowa może być odpowiednim wyborem. Jeśli jednak opóźnienie nie spełnia Twoich potrzeb, możesz rozważyć użycie interfejsu API w czasie rzeczywistym.
Kody stanu HTTP
Sekcja zawiera szczegółowe informacje na temat kodów odpowiedzi HTTP i komunikatów z interfejsu API syntezy wsadowej.
HTTP 200 OK
HTTP 200 OK wskazuje, że żądanie zakończyło się pomyślnie.
Utworzono protokół HTTP 201
Utworzono protokół HTTP 201 wskazuje, że żądanie utworzenia syntezy wsadowej (za pośrednictwem protokołu HTTP PUT) zakończyło się pomyślnie.
Błąd HTTP 204
Błąd HTTP 204 wskazuje, że żądanie zakończyło się pomyślnie, ale zasób nie istnieje. Na przykład:
- Próbowano pobrać lub usunąć zadanie syntezy, które nie istnieje.
- Pomyślnie usunięto zadanie syntezy.
Błąd HTTP 400
Oto przykłady, które mogą spowodować błąd 400:
- Element
outputFormatjest nieobsługiwany lub nieprawidłowy. Podaj prawidłową wartość formatu lub pozostawoutputFormatwartość pustą, aby użyć ustawienia domyślnego. - Liczba żądanych danych wejściowych tekstu przekroczyła limit 10 000.
- Próbowano użyć nieprawidłowego identyfikatora wdrożenia lub niestandardowego głosu, który nie został pomyślnie wdrożony. Upewnij się, że zasób usługi Mowa ma dostęp do niestandardowego głosu, a niestandardowy głos został pomyślnie wdrożony. Należy również upewnić się, że mapowanie parametru
{"your-custom-voice-name": "your-deployment-ID"}jest poprawne w żądaniu syntezy wsadowej. - Próbowano użyć zasobu usługi Mowa F0, ale region obsługuje tylko warstwę cenową zasobu usługi Mowa w warstwie Standardowa.
Błąd HTTP 404
Nie można odnaleźć określonej jednostki. Upewnij się, że identyfikator syntezy jest poprawny.
Błąd HTTP 429
Istnieje zbyt wiele ostatnich żądań. Każda aplikacja kliencka może przesyłać do 100 żądań na 10 sekund dla każdego zasobu usługi Mowa. Zmniejsz liczbę żądań na sekundę.
Błąd HTTP 500
Błąd wewnętrzny serwera HTTP 500 wskazuje, że żądanie nie powiodło się. Treść odpowiedzi zawiera komunikat o błędzie.
Przykład błędu HTTP
Oto przykładowe żądanie, które powoduje błąd HTTP 400, ponieważ inputs właściwość jest wymagana do utworzenia zadania.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourSpeechKey" -H "Content-Type: application/json" -d '{
"inputKind": "SSML"
}' "https://YourSpeechRegion.api.cognitive.microsoft.com/texttospeech/batchsyntheses/YourSynthesisId?api-version=2024-04-01"
W takim przypadku nagłówki odpowiedzi obejmują HTTP/1.1 400 Bad Request.
Treść odpowiedzi przypomina następujący przykład JSON:
{
"error": {
"code": "BadRequest",
"message": "The inputs is required."
}
}