Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule dowiesz się, jak automatycznie skalować obciążenia procesora GPU w usłudze Azure Kubernetes Service (AKS) przy użyciu metryk procesora GPU zebranych przez eksportera NVIDIA Data Center GPU Manager (DCGM). Te metryki są udostępniane za pośrednictwem usługi Azure Managed Prometheus i używane przez platformę Kubernetes Event-Driven autoskalowanie (KEDA) w celu automatycznego skalowania obciążeń na podstawie wykorzystania procesora GPU w czasie rzeczywistym. To rozwiązanie pomaga zoptymalizować użycie zasobów procesora GPU i kontrolować koszty operacyjne, dynamicznie dostosowując skalę aplikacji w odpowiedzi na zapotrzebowanie na obciążenia.
Wymagania wstępne
-
Interfejs wiersza polecenia platformy Azure w wersji 2.60.0 lub nowszej. Uruchom
az --version, aby znaleźć wersję. Jeśli konieczna będzie instalacja lub uaktualnienie, zobacz Instalowanie interfejsu wiersza polecenia platformy Azure. - Zainstalowano program Helm w wersji 3.17.0 lub nowszej.
- zainstalowany program kubectl w wersji 1.28.9 lub nowszej.
- Limit przydziału procesora GPU firmy NVIDIA w ramach subskrypcji platformy Azure. W tym przykładzie użyto jednostki SKU
Standard_NC40ads_H100_v5, ale obsługiwane są również inne jednostki SKU VM NVIDIA H100.
Przed kontynuowaniem upewnij się, że klaster usługi AKS jest skonfigurowany przy użyciu następujących elementów:
- Integrowanie usługi KEDA z klastrem usługi Azure Kubernetes Service.
- Monitorowanie metryk GPU od eksportera NVIDIA DCGM za pomocą Azure Managed Prometheus i Azure Managed Grafana.
W tym momencie powinieneś mieć:
- Klaster AKS z pulami węzłów z obsługą GPU firmy NVIDIA i GPU potwierdzonymi jako możliwe do użycia.
- Usługa Azure Managed Prometheus i Grafana są włączone w klastrze usługi AKS. Usługa KEDA jest włączona w klastrze.
- Tożsamość zarządzana przypisana przez użytkownika, używana przez KEDA, ma przypisany zakres roli
Monitoring Data Readerdo obszaru roboczego Azure Monitor skojarzonego z klastrem AKS.
Tworzenie nowego modułu skalowania KEDA przy użyciu metryk eksportera NVIDIA DCGM
Aby utworzyć moduł skalowania KEDA, potrzebne są dwa składniki:
- Punkt końcowy zapytania Prometheus.
- Tożsamość zarządzana przypisana przez użytkownika.
Pobierz punkt końcowy zapytania zarządzanego przez Azure Prometheusa
Tę wartość można znaleźć w sekcji Przegląd obszaru roboczego usługi Azure Monitor dołączonego do klastra usługi AKS w witrynie Azure Portal.
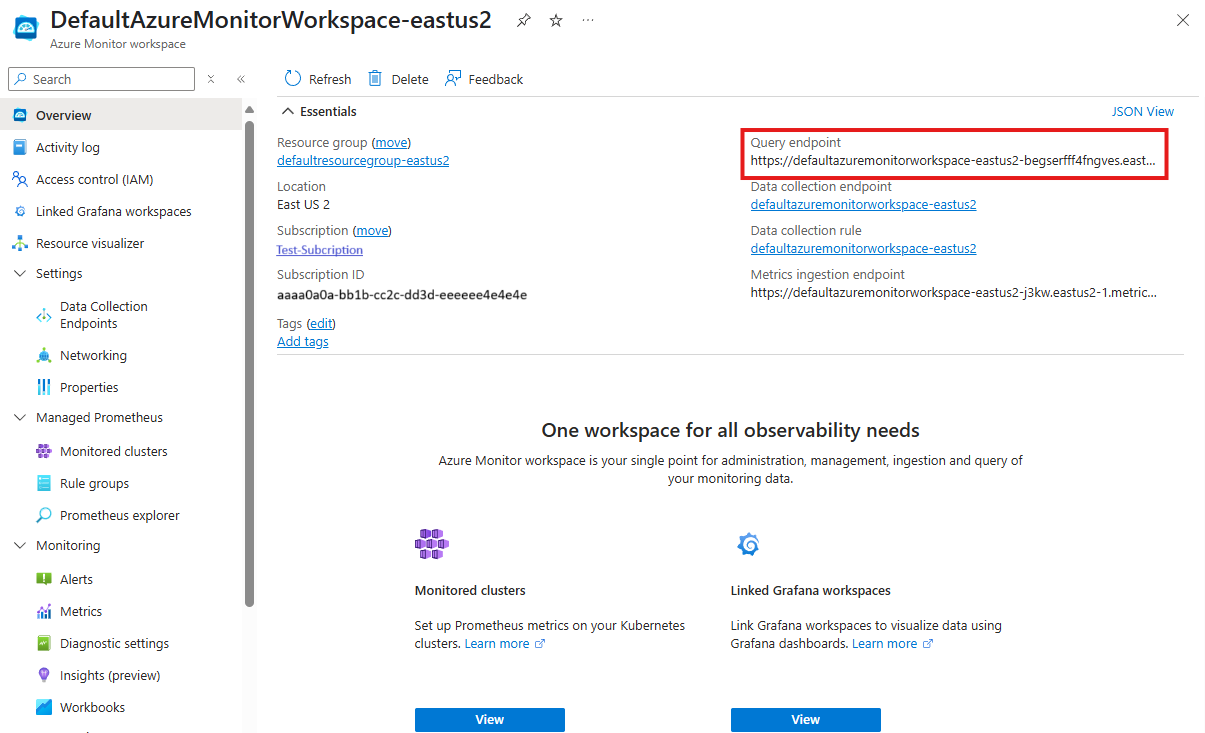
Wyeksportuj punkt końcowy zapytania zarządzanego rozwiązania Prometheus platformy Azure do zmiennej środowiskowej:
export PROMETHEUS_QUERY_ENDPOINT="https://example.prometheus.monitor.azure.com"
Pobieranie tożsamości zarządzanej przypisanej przez użytkownika
Tożsamość zarządzana przypisana przez użytkownika została wcześniej utworzona po wykonaniu kroków integracji usługi KEDA. W razie potrzeby załaduj ponownie tę wartość za pomocą polecenia az identity show.
export USER_ASSIGNED_CLIENT_ID="$(az identity show --resource-group $RESOURCE_GROUP --name $USER_ASSIGNED_IDENTITY_NAME --query 'clientId' -o tsv)"
Tworzenie manifestu narzędzia skalowania KEDA
Ten manifest tworzy TriggerAuthentication i ScaledObject do skalowania automatycznego na podstawie wykorzystania GPU mierzonego przez metrykę DCGM_FI_DEV_GPU_UTIL.
Uwaga / Notatka
W tym przykładzie użyto DCGM_FI_DEV_GPU_UTIL metryki, która mierzy użycie procesora GPU. Inne metryki są również dostępne od eksportera DCGM w zależności od wymagań związanych z obciążeniem. Pełną listę dostępnych metryk można znaleźć w dokumentacji eksportera NVIDIA DCGM.
| (No changes needed) | Opis |
|---|---|
metricName |
Określa metrykę GPU do monitorowania.
DCGM_FI_DEV_GPU_UTIL raportuje procent czasu, w jaki procesor GPU aktywnie przetwarza obciążenia. Ta wartość zazwyczaj waha się od 0 do 100. |
query |
Zapytanie PromQL, które oblicza średnie wykorzystanie GPU we wszystkich podach we wdrożeniu my-gpu-workload. Dzięki temu decyzje dotyczące skalowania są oparte na ogólnym użyciu procesora GPU, a nie na pojedynczym zasobniku. |
threshold |
Docelowy średni procent wykorzystania procesora GPU, który wyzwala skalowanie. Jeśli średnia przekracza 5%, skalownik zwiększa liczbę replik zasobników. |
activationThreshold |
Minimalne średnie wykorzystanie procesora GPU wymagane do aktywowania skalowania. Jeśli użycie jest poniżej 2%, akcje skalowania nie zostaną wykonane, uniemożliwiając niepotrzebne skalowanie w okresach niskiej aktywności. |
Utwórz następujący manifest KEDA:
cat <<EOF > keda-gpu-scaler-prometheus.yaml apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: azure-managed-prometheus-trigger-auth spec: podIdentity: provider: azure-workload identityId: ${USER_ASSIGNED_CLIENT_ID} --- apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: my-gpu-workload spec: scaleTargetRef: name: my-gpu-workload minReplicaCount: 1 maxReplicaCount: 20 triggers: - type: prometheus metadata: serverAddress: ${PROMETHEUS_QUERY_ENDPOINT} metricName: DCGM_FI_DEV_GPU_UTIL query: avg(DCGM_FI_DEV_GPU_UTIL{deployment="my-gpu-workload"}) threshold: '5' activationThreshold: '2' authenticationRef: name: azure-managed-prometheus-trigger-auth EOFZastosuj ten manifest przy użyciu
kubectl applypolecenia :kubectl apply -f keda-gpu-scaler-prometheus.yaml
Testowanie nowych możliwości skalowania
Utwórz przykładowe obciążenie, które zużywa zasoby procesora GPU w klastrze usługi AKS. Możesz zacząć od następującego przykładu:
cat <<EOF > my-gpu-workload.yaml apiVersion: apps/v1 kind: Deployment metadata: name: my-gpu-workload namespace: default spec: replicas: 1 selector: matchLabels: app: my-gpu-workload template: metadata: labels: app: my-gpu-workload spec: tolerations: - key: "sku" operator: "Equal" value: "gpu" effect: "NoSchedule" containers: - name: my-gpu-workload image: mcr.microsoft.com/azuredocs/samples-tf-mnist-demo:gpu command: ["/bin/sh"] args: ["-c", "while true; do python /app/main.py --max_steps=500; done"] resources: limits: nvidia.com/gpu: 1 EOFZastosuj ten manifest wdrożenia przy użyciu
kubectl applypolecenia :kubectl apply -f my-gpu-workload.yamlUwaga / Notatka
Jeśli węzły GPU nie są obecnie dostępne, pod będzie w stanie
Pendingdo momentu uruchomienia węzła, co spowoduje wyświetlenie następującego komunikatu:Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 3m19s default-scheduler 0/2 nodes are available: 2 Insufficient nvidia.com/gpu. preemption: 0/2 nodes are available: 2 No preemption victims found for incoming pod.Narzędzie do automatycznego skalowania klastra zostanie ostatecznie uruchomione i aprowizuje nowy węzeł GPU.
Normal TriggeredScaleUp 2m43s cluster-autoscaler pod triggered scale-up: [{aks-gpunp-36854149-vmss 0->1 (max: 2)}]Uwaga / Notatka
W zależności od rozmiaru aprowizowanej jednostki SKU procesora GPU aprowizacja węzłów może potrwać kilka minut.
Aby sprawdzić postęp, użyj polecenia
kubectl describedo sprawdzenia zdarzeń narzędzia Horizontal Pod Autoscaler (HPA).kubectl describe hpa my-gpu-workloadDane wyjściowe powinny wyglądać następująco:
Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale recommended size matches current size ScalingActive True ValidMetricFound the HPA successfully calculated a replica count from external metric s0-prometheus(&LabelSelector{MatchLabels:map[string]string{scaledobject.keda.sh/name: my-gpu-workload}}) ScalingLimited True TooFewReplicas the desired replica count is less than the minimum replica countUpewnij się, że węzeł GPU został dodany i pod jest uruchomiony za pomocą polecenia
kubectl get.kubectl get nodesDane wyjściowe powinny wyglądać następująco:
NAME STATUS ROLES AGE VERSION aks-gpunp-36854149-vmss000005 Ready <none> 4m36s v1.31.7 aks-nodepool1-34179260-vmss000002 Ready <none> 26h v1.31.7 aks-nodepool1-34179260-vmss000003 Ready <none> 26h v1.31.7
Zmniejszenie puli węzłów GPU
Aby zmniejszyć rozmiar puli węzłów GPU, usuń wdrożenie obciążenia przy użyciu polecenia kubectl delete.
kubectl delete deployment my-gpu-workload
Uwaga / Notatka
Pulę węzłów można skonfigurować tak, aby skalowała się w dół do zera, włączając klastrowe automatyczne skalowanie i ustawiając min-count na 0 podczas tworzenia puli węzłów. Przykład:
az aks nodepool add \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name gpunp \
--node-count 1 \
--node-vm-size Standard_NC40ads_H100_v5 \
--node-taints sku=gpu:NoSchedule \
--enable-cluster-autoscaler \
--min-count 0 \
--max-count 3
Dalsze kroki
- Wdrożenie obciążenia z GPU z wieloma wystąpieniami (MIG) na AKS.
- Zapoznaj się z usługą KAITO w usłudze AKS na potrzeby wnioskowania i dostrajania sztucznej inteligencji.
- Dowiedz się więcej o klastrach Ray na AKS.
Współpracuj z nami w serwisie GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy i żądania ściągnięcia. Więcej informacji znajdziesz w naszym przewodniku dla współtwórców.

Azure Kubernetes Service