Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym przewodniku pokazano, jak zweryfikować odporność klastra Valkey wdrożonego w usłudze Azure Kubernetes Service (AKS) przy użyciu struktury testowania obciążenia locust. Przeprowadzi on proces tworzenia klienta testowego, wdrażania go w usłudze AKS, symulowania błędów i analizowania zachowania klastra.
Note
Ten artykuł zawiera odwołania do terminu master (primary), który jest terminem, który nie jest już używany przez firmę Microsoft. Po usunięciu terminu z oprogramowania Valkey usuniemy go z tego artykułu.
Tworzenie przykładowej aplikacji klienckiej dla rozwiązania Valkey
W poniższych krokach pokazano, jak utworzyć przykładową aplikację kliencką dla rozwiązania Valkey.
Przykładowa aplikacja kliencka używa struktury testowania obciążenia locust do symulowania obciążenia w skonfigurowanym i wdrożonym klastrze Valkey. Kod w języku Python implementuje klasę Locust User, która łączy się z klastrem Valkey i wykonuje operacje ustawiania i pobierania. Tę klasę można rozszerzyć, aby zaimplementować bardziej złożone operacje.
Note
Zalecamy korzystanie z najbezpieczniejszego dostępnego przepływu uwierzytelniania. Przepływ uwierzytelniania opisany w tej procedurze wymaga bardzo wysokiego poziomu zaufania w aplikacji i niesie ze sobą ryzyko, które nie występują w innych przepływach. Tego przepływu należy używać tylko wtedy, gdy inne bezpieczniejsze przepływy, takie jak tożsamości zarządzane, nie są opłacalne.
Utwórz plik Dockerfile i
requirements.txtumieść je w nowym katalogu przy użyciu następujących poleceń:mkdir valkey-client cd valkey-client cat > Dockerfile <<EOF FROM python:3.10-slim-bullseye COPY requirements.txt . COPY locustfile.py . RUN pip install --upgrade pip && pip install --no-cache-dir -r requirements.txt EOF cat > requirements.txt <<EOF valkey locust EOFlocustfile.pyUtwórz plik zawierający kod aplikacji klienckiej Valkey:cat > locustfile.py <<EOF import time from locust import between, task, User, events,tag, constant_throughput from valkey import ValkeyCluster from random import randint class ValkeyLocust(User): wait_time = constant_throughput(50) host = "valkey-cluster.valkey.svc.cluster.local" def __init__(self, *args, **kwargs): super(ValkeyLocust, self).__init__(*args, **kwargs) self.client = ValkeyClient(host=self.host) def on_stop(self): self.client.close() @task @tag("set") def set_value(self): self.client.set_value("set_value") @task @tag("get") def get_value(self): self.client.get_value("get_value") class ValkeyClient(object): def __init__(self, host, *args, **kwargs): super().__init__(*args, **kwargs) with open("/etc/valkey-password/valkey-password-file.conf", "r") as f: self.password = f.readlines()[0].split(" ")[1].strip() self.host = host self.vc = ValkeyCluster(host=self.host, port=6379, password=self.password, username="default", cluster_error_retry_attempts=0, socket_timeout=2, keepalive=1 ) def set_value(self, key, command='SET'): start_time = time.perf_counter() try: result = self.vc.set(randint(0, 1000), randint(0, 1000)) if not result: result = '' length = len(str(result)) total_time = (time.perf_counter()- start_time) * 1000 events.request.fire( request_type=command, name=key, response_time=total_time, response_length=length, ) except Exception as e: total_time = (time.perf_counter()- start_time) * 1000 events.request.fire( request_type=command, name=key, response_time=total_time, response_length=0, exception=e ) result = '' return result def get_value(self, key, command='GET'): start_time = time.perf_counter() try: result = self.vc.get(randint(0, 1000)) if not result: result = '' length = len(str(result)) total_time = (time.perf_counter()- start_time) * 1000 events.request.fire( request_type=command, name=key, response_time=total_time, response_length=length, ) except Exception as e: total_time = (time.perf_counter()- start_time) * 1000 events.request.fire( request_type=command, name=key, response_time=total_time, response_length=0, exception=e ) result = '' return result EOF
Budowanie i przesyłanie obrazu Docker do ACR
Skompiluj obraz platformy Docker i przekaż go do usługi Azure Container Registry (ACR) przy użyciu
az acr buildpolecenia .az acr build --image valkey-client --registry ${MY_ACR_REGISTRY} .Sprawdź, czy obraz został pomyślnie przesłany przy użyciu polecenia
az acr repository list.az acr repository list --name ${MY_ACR_REGISTRY} --output tableDane wyjściowe powinny wyświetlić
valkey-clientobraz, jak w poniższym przykładzie:Result ---------------- valkey-client
Wdróż przykładowy pod klienta do AKS
Utwórz element, który
Podużywa obrazu klienta Valkey wbudowanego w poprzednim kroku przy użyciukubectl applypolecenia . Specyfikacja zasobnika zawiera wolumin CSI magazynu wpisów tajnych z hasłem Valkey używanym przez klienta do nawiązywania połączenia z klastrem Valkey.kubectl apply -f - <<EOF --- kind: Pod apiVersion: v1 metadata: name: valkey-client namespace: valkey spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: agentpool operator: In values: - nodepool1 containers: - name: valkey-client image: ${MY_ACR_REGISTRY}.azurecr.io/valkey-client command: ["locust", "--processes", "4"] volumeMounts: - name: valkey-password mountPath: "/etc/valkey-password" volumes: - name: valkey-password csi: driver: secrets-store.csi.k8s.io readOnly: true volumeAttributes: secretProviderClass: "valkey-password" EOFPort przekazuje port 8089, aby uzyskać dostęp do interfejsu sieci Web Locust na komputerze lokalnym przy użyciu
kubectl port-forwardpolecenia .kubectl port-forward -n valkey valkey-client 8089:8089Uzyskaj dostęp do interfejsu sieci Web Locust pod
http://localhost:8089adresem i rozpocznij test. Możesz dostosować liczbę użytkowników i szybkość zduplikowania, aby zasymulować obciążenie w klastrze Valkey. Poniższy wykres używa 100 użytkowników i 10 współczynnika zduplikowania: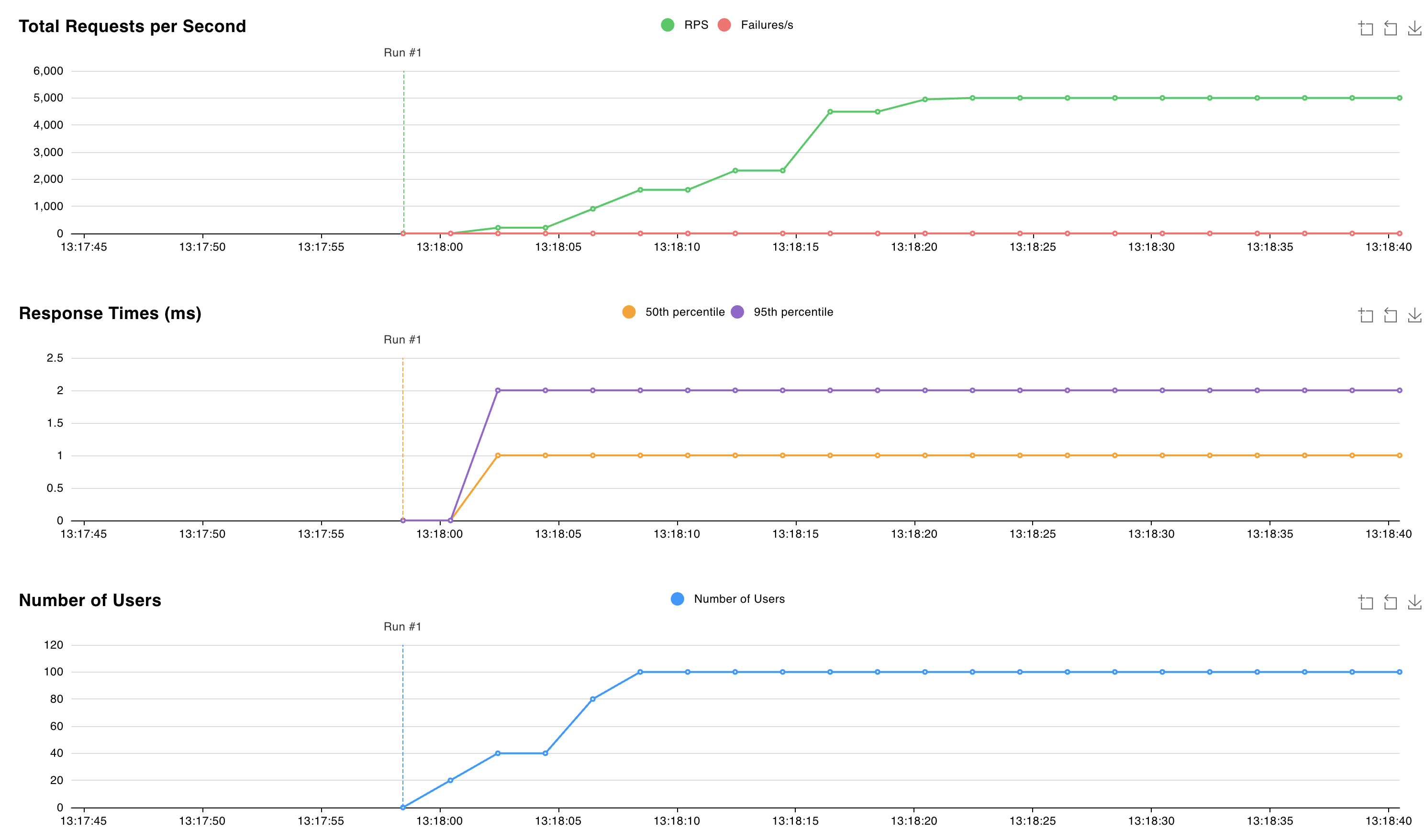
Symulowanie awarii i obserwowanie zachowania klastra Valkey
Zasymuluj awarię, usuwając
StatefulSetpolecenie za pomocąkubectl deleteflagi--cascade=orphan. Celem jest możliwość usunięcia pojedynczego podu bez natychmiastowego odtworzeniaStatefulSetusuniętego podu.kubectl delete statefulset valkey-masters --cascade=orphanUsuń zasobnik
valkey-masters-0przy użyciukubectl delete podpolecenia .kubectl delete pod valkey-masters-0Sprawdź listę podów przy użyciu polecenia
kubectl get pods.kubectl get podsDane wyjściowe powinny wskazywać, że zasobnik
valkey-masters-0został usunięty. Inne zasobniki powinny być wRunningstanie, jak pokazano w poniższym przykładzie:NAME READY STATUS RESTARTS AGE valkey-client 1/1 Running 0 6m34s valkey-masters-1 1/1 Running 0 16m valkey-masters-2 1/1 Running 0 16m valkey-replicas-0 1/1 Running 0 16m valkey-replicas-1 1/1 Running 0 16m valkey-replicas-2 1/1 Running 0 16mPobierz dzienniki z zasobnika
valkey-replicas-0używając poleceniakubectl logs valkey-replicas-0.kubectl logs valkey-replicas-0W danych wyjściowych obserwujemy, że pełne zdarzenie trwa około 18 sekund:
1:S 05 Nov 2024 12:18:53.961 * Connection with primary lost. 1:S 05 Nov 2024 12:18:53.961 * Caching the disconnected primary state. 1:S 05 Nov 2024 12:18:53.961 * Reconnecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:18:53.961 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:18:53.964 # Error condition on socket for SYNC: Connection refused 1:S 05 Nov 2024 12:18:54.910 * Connecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:18:54.910 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:18:54.912 # Error condition on socket for SYNC: Connection refused 1:S 05 Nov 2024 12:18:55.920 * Connecting to PRIMARY 10.224.0.250:6379 [..CUT..] 1:S 05 Nov 2024 12:19:10.056 * Connecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:19:10.057 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:19:10.058 # Error condition on socket for SYNC: Connection refused 1:S 05 Nov 2024 12:19:10.709 * Node c44d4b682b6fb9b37033d3e30574873545266d67 () reported node 9e7c43890613cc3ad4006a9cdc0b5e5fc5b6d44e () as not reachable. 1:S 05 Nov 2024 12:19:10.864 * NODE 9e7c43890613cc3ad4006a9cdc0b5e5fc5b6d44e () possibly failing. 1:S 05 Nov 2024 12:19:11.066 * 10000 changes in 60 seconds. Saving... 1:S 05 Nov 2024 12:19:11.068 * Background saving started by pid 29 1:S 05 Nov 2024 12:19:11.068 * Connecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:19:11.068 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:19:11.069 # Error condition on socket for SYNC: Connection refused 29:C 05 Nov 2024 12:19:11.090 * DB saved on disk 29:C 05 Nov 2024 12:19:11.090 * Fork CoW for RDB: current 0 MB, peak 0 MB, average 0 MB 1:S 05 Nov 2024 12:19:11.169 * Background saving terminated with success 1:S 05 Nov 2024 12:19:11.884 * FAIL message received from ba36d5167ee6016c01296a4a0127716f8edf8290 () about 9e7c43890613cc3ad4006a9cdc0b5e5fc5b6d44e () 1:S 05 Nov 2024 12:19:11.884 # Cluster state changed: fail 1:S 05 Nov 2024 12:19:11.974 * Start of election delayed for 510 milliseconds (rank #0, offset 7225807). 1:S 05 Nov 2024 12:19:11.976 * Node d43f370a417d299b78bd1983792469fe5c39dcdf () reported node 9e7c43890613cc3ad4006a9cdc0b5e5fc5b6d44e () as not reachable. 1:S 05 Nov 2024 12:19:12.076 * Connecting to PRIMARY 10.224.0.250:6379 1:S 05 Nov 2024 12:19:12.076 * PRIMARY <-> REPLICA sync started 1:S 05 Nov 2024 12:19:12.076 * Currently unable to failover: Waiting the delay before I can start a new failover. 1:S 05 Nov 2024 12:19:12.078 # Error condition on socket for SYNC: Connection refused 1:S 05 Nov 2024 12:19:12.581 * Starting a failover election for epoch 15. 1:S 05 Nov 2024 12:19:12.616 * Currently unable to failover: Waiting for votes, but majority still not reached. 1:S 05 Nov 2024 12:19:12.616 * Needed quorum: 2. Number of votes received so far: 1 1:S 05 Nov 2024 12:19:12.616 * Failover election won: I'm the new primary. 1:S 05 Nov 2024 12:19:12.616 * configEpoch set to 15 after successful failover 1:M 05 Nov 2024 12:19:12.616 * Discarding previously cached primary state. 1:M 05 Nov 2024 12:19:12.616 * Setting secondary replication ID to c0b5b2df8a43b19a4d43d8f8b272a07139e0ca34, valid up to offset: 7225808. New replication ID is 029fcfbae0e3e4a1dccd73066043deba6140c699 1:M 05 Nov 2024 12:19:12.616 * Cluster state changed: okW tym przedziale czasu 18 sekund obserwujemy, że zapisy do fragmentu należącego do usuniętego zasobnika kończą się niepowodzeniem, a klaster Valkey wybiera nowy element podstawowy. Opóźnienie żądania zwiększa się do 60 ms w tym przedziale czasu.
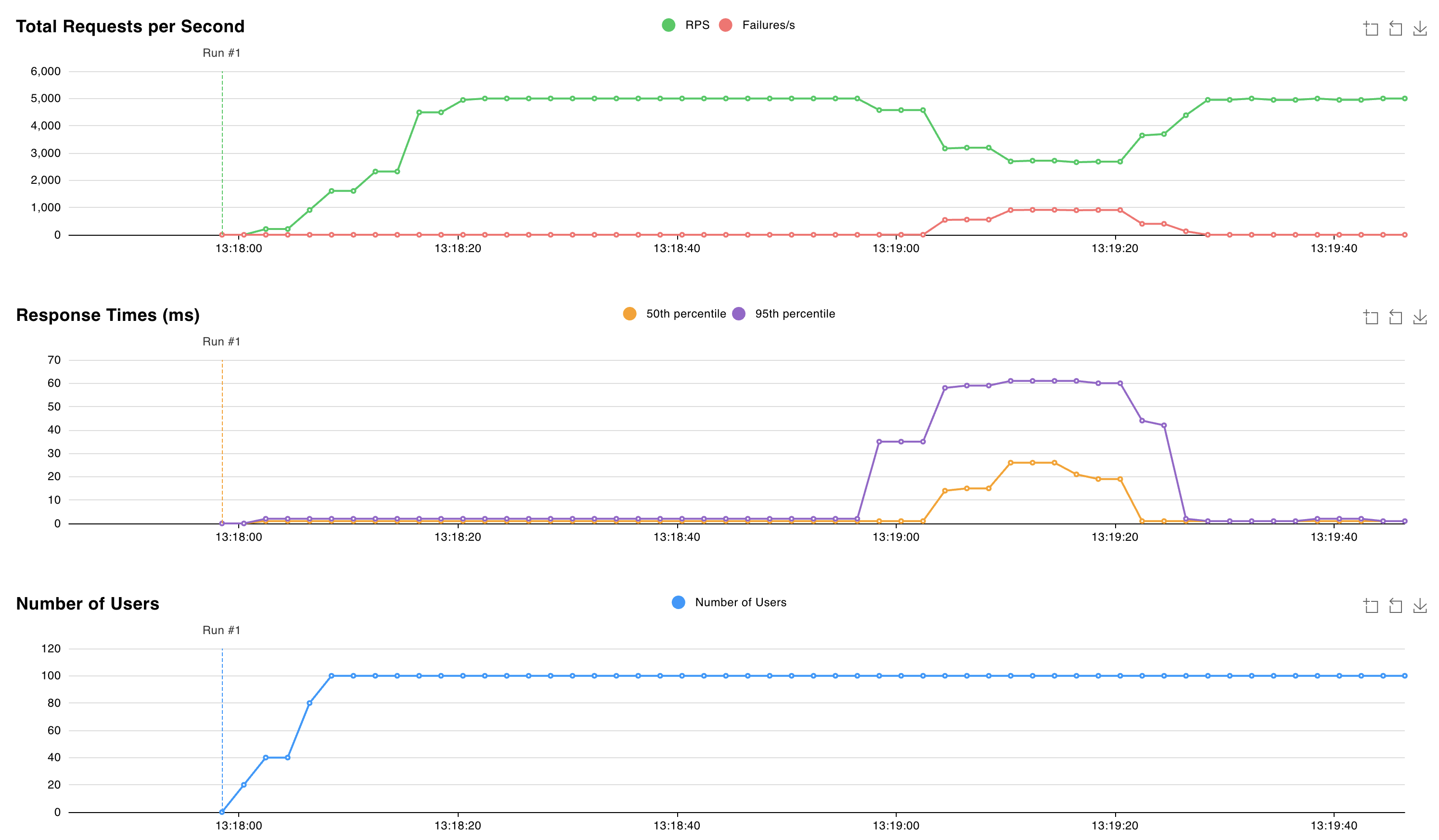
Po wybraniu nowego podstawowego klaster Valkey nadal obsługuje żądania z opóźnieniem około 2 ms.
Następny krok
Contributors
Firma Microsoft utrzymuje ten artykuł. Następujący współautorzy pierwotnie to napisali:
- Nelly Kiboi | Inżynier usługi
- Saverio Proto | Główny inżynier środowiska klienta