Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym samouczku utworzysz aplikację Python Retrieval Augmented Generation (RAG) przy użyciu FastAPI, Azure OpenAI i Azure AI Search i wdrożysz ją na Azure App Service. Ta aplikacja pokazuje, jak zaimplementować interfejs czatu, który pobiera informacje z własnych dokumentów i korzysta z usług sztucznej inteligencji w Azure w celu zapewnienia dokładnych, kontekstowych odpowiedzi z odpowiednimi cytatami. Rozwiązanie używa tożsamości zarządzanych do uwierzytelniania bez hasła między usługami.
W tym poradniku nauczysz się, jak:
- Wdróż aplikację FastAPI korzystającą ze wzorca RAG z usługami sztucznej inteligencji w Azure.
- Skonfiguruj Azure openAI i Azure AI Search na potrzeby wyszukiwania hybrydowego.
- Przekazywanie i indeksowanie dokumentów do użycia w aplikacji opartej na sztucznej inteligencji.
- Użyj tożsamości zarządzanych do bezpiecznej komunikacji między usługami.
- Przetestuj implementację RAG lokalnie przy użyciu usług produkcyjnych.
Przegląd architektury
Przed rozpoczęciem wdrażania warto zrozumieć architekturę aplikacji, którą utworzysz. Na poniższym diagramie przedstawiono wzorzec Custom RAG dla Azure AI Search:

W tym samouczku aplikacja Blazer w usłudze App Service zajmuje się zarówno interfejsem użytkownika aplikacji, jak i serwerem aplikacji. Jednak nie tworzy oddzielnego zapytania o wiedzę do usługi Azure AI Search. Zamiast tego informuje Azure OpenAI, aby wykonać zapytania do bazy wiedzy, określając jako źródło danych Azure AI Search. Ta architektura oferuje kilka kluczowych zalet:
- Integrated Vectorization: Wbudowane możliwości wektoryzacji w Azure AI Search ułatwiają szybkie przetwarzanie wszystkich dokumentów do wyszukiwania, bez konieczności pisania dodatkowego kodu do generowania osadzeń.
- Uproszczony dostęp do interfejsu API: korzystając z wzorca Azure OpenAI dla Twoich danych z Azure AI Search jako źródła danych dla kompletności Azure OpenAI, nie trzeba implementować złożonego wyszukiwania wektorowego ani generowania osadzania. Jest to tylko jedno wywołanie interfejsu API, a Azure OpenAI obsługuje wszystko, w tym inżynierię podpowiedzi i optymalizację zapytań.
- Zaawansowane możliwości wyszukiwania: zintegrowana wektoryzacja zapewnia wszystko, co jest potrzebne do zaawansowanego wyszukiwania hybrydowego z semantycznymi refrankingami, które łączy mocne strony dopasowywania słów kluczowych, podobieństwa wektorów i klasyfikacji opartej na sztucznej inteligencji.
- Pełna obsługa cytatów: odpowiedzi automatycznie zawierają cytaty do dokumentów źródłowych, dzięki czemu informacje są weryfikowalne i możliwe do śledzenia.
Wymagania wstępne
- Konto Azure z aktywną subskrypcją — Utwórz bezpłatne konto.
- GitHub konto do używania GitHub Codespaces — Dowiedz się więcej o GitHub Codespaces.
1. Otwórz przykład za pomocą usługi Codespaces
Najprostszym sposobem rozpoczęcia pracy jest użycie GitHub Codespaces, który zapewnia kompletne środowisko programistyczne ze wszystkimi wymaganymi wstępnie zainstalowanymi narzędziami.
Przejdź do repozytorium GitHub pod adresem https://github.com/Azure-Samples/app-service-rag-openai-ai-search-python.
Wybierz przycisk Kod, wybierz kartę Codespaces, a następnie kliknij Utwórz przestrzeń kodu w obszarze głównym.
Zaczekaj chwilę na zainicjowanie usługi Codespace. Gdy wszystko będzie gotowe, zobaczysz w przeglądarce w pełni skonfigurowane środowisko programu VS Code.
2. Wdrażanie przykładowej architektury
W terminalu zaloguj się do Azure przy użyciu interfejsu wiersza polecenia dewelopera Azure:
azd auth loginPostępuj zgodnie z instrukcjami, aby ukończyć proces uwierzytelniania.
Aprowizuj zasoby Azure za pomocą szablonu AZD:
azd provisionPo wyświetleniu monitu podaj następujące odpowiedzi:
Pytanie Odpowiedź Wprowadź nową nazwę środowiska: Wpisz unikatową nazwę. Wybierz subskrypcję Azure do użycia: Wybierz subskrypcję. Wybierz grupę zasobów do użycia: Wybierz pozycję Utwórz nową grupę zasobów. Wybierz lokalizację, w ramach których chcesz utworzyć grupę zasobów: Wybierz dowolny region. Zasoby zostaną utworzone w regionie Wschodnie stany USA 2. Wprowadź nazwę nowej grupy zasobów: Wpisz Enter. Poczekaj na zakończenie wdrożenia. Ten proces będzie następujący:
- Utwórz wszystkie wymagane zasoby Azure.
- Wdróż aplikację w Azure App Service.
- Skonfiguruj bezpieczne uwierzytelnianie między usługami przy użyciu tożsamości zarządzanych.
- Skonfiguruj niezbędne przypisania ról w celu zapewnienia bezpiecznego dostępu między usługami.
Uwaga / Notatka
Aby dowiedzieć się więcej o działaniu tożsamości zarządzanych, zobacz Czym są tożsamości zarządzane dla zasobów Azure? i Jak używać tożsamości zarządzanych z usługą App Service.
Po pomyślnym wdrożeniu zobaczysz adres URL wdrożonej aplikacji. Zanotuj ten adres URL, ale nie uzyskaj do niego dostępu, ponieważ nadal musisz skonfigurować indeks wyszukiwania.
3. Przekazywanie dokumentów i tworzenie indeksu wyszukiwania
Po wdrożeniu infrastruktury należy przesłać dokumenty oraz utworzyć indeks wyszukiwania, którego będzie używać aplikacja:
W portalu Azure przejdź do konta pamięci masowej utworzonego przez wdrożenie. Nazwa rozpocznie się od podanej wcześniej nazwy środowiska.
Wybierz pozycję Kontenery przechowywania danych> z menu nawigacyjnego po lewej stronie i otwórz kontener dokumentów.
Przekaż przykładowe dokumenty, klikając pozycję Przekaż. Możesz użyć przykładowych dokumentów z folderu
sample-docsw repozytorium lub własnego pliku PDF, Word lub plików tekstowych.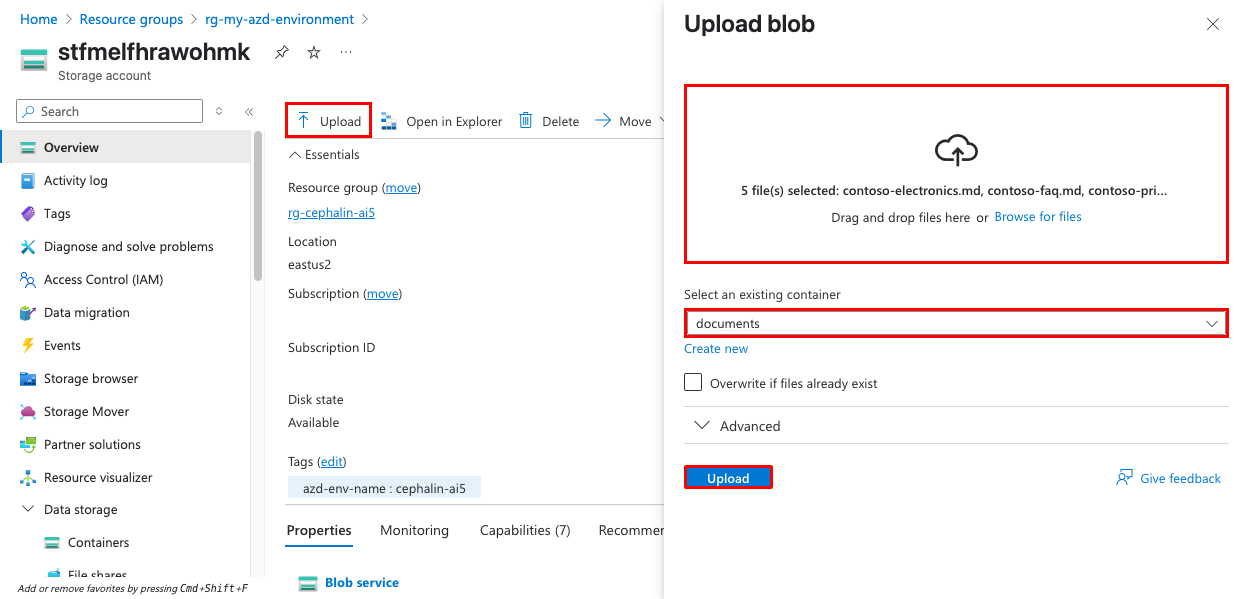
Przejdź do usługi Azure AI Search w portalu Azure.
Wybierz pozycję Importuj dane (nowe), aby rozpocząć proces tworzenia indeksu wyszukiwania.
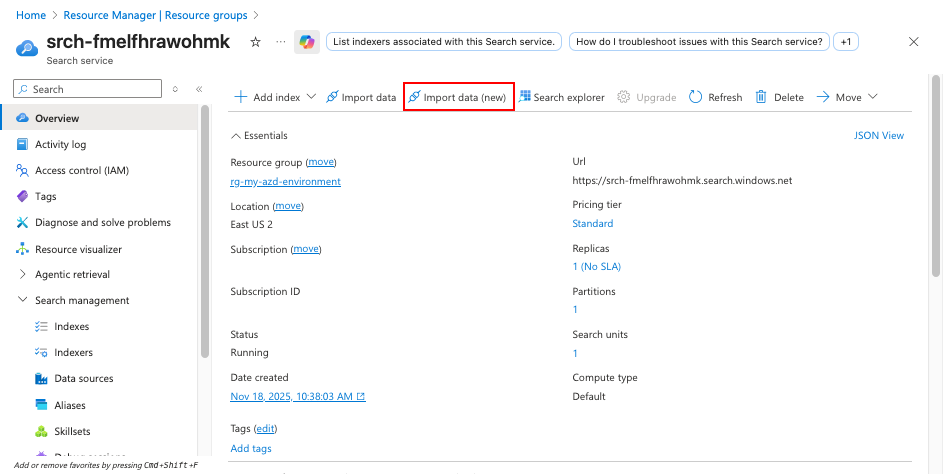
W kroku Łączenie z danymi :
- Wybierz Azure Blob Storage jako źródło danych.
- Wybierz RAG
- Wybierz konto magazynowe i kontener dokumentów.
- Wybierz pozycję Uwierzytelnij przy użyciu tożsamości zarządzanej.
- Wybierz Dalej.
W kroku Wektoryzuj tekst :
- Wybierz swoją Azure usługę OpenAI.
- Wybierz text-embedding-ada-002 jako model osadzania. Szablon AZD już wdrożył ten model.
- Wybierz pozycję Tożsamość przypisana przez system na potrzeby uwierzytelniania.
- Zaznacz pole wyboru potwierdzenia, aby zaakceptować dodatkowe koszty.
- Wybierz Dalej.
Wskazówka
Dowiedz się więcej o wyszukiwaniu wektorowego w Azure AI Search i osadzaniu tekstu w Azure OpenAI.
W kroku Wektoryzacja i wzbogacanie obrazów :
- Zachowaj ustawienia domyślne.
- Wybierz Dalej.
W kroku Ustawienia zaawansowane :
- Upewnij się, że wybrano opcję Włącz rangę semantyczną .
- (Opcjonalnie) Wybierz harmonogram indeksowania. Jest to przydatne, jeśli chcesz regularnie odświeżać indeks przy użyciu najnowszych zmian w pliku.
- Wybierz Dalej.
W kroku Przeglądanie i tworzenie :
- Skopiuj wartość prefiksu nazwy obiektów . Jest to nazwa indeksu wyszukiwania.
- Wybierz pozycję Utwórz , aby rozpocząć proces indeksowania.
Poczekaj na zakończenie procesu indeksowania. Może to potrwać kilka minut w zależności od rozmiaru i liczby dokumentów.
Aby przetestować importowanie danych, wybierz pozycję Rozpocznij wyszukiwanie i spróbuj wykonać zapytanie wyszukiwania, takie jak "Powiedz mi o firmie".
Po powrocie do terminalu usługi Codespace ustaw nazwę indeksu wyszukiwania jako zmienną środowiskową AZD:
azd env set SEARCH_INDEX_NAME <your-search-index-name>Zastąp ciąg
<your-search-index-name>nazwą indeksu skopiowaną wcześniej. AZD używa tej zmiennej w kolejnych wdrożeniach, aby ustawić konfigurację aplikacji App Service.
4. Testowanie aplikacji i wdrażanie
Jeśli wolisz przetestować aplikację lokalnie przed wdrożeniem lub po nim, możesz uruchomić ją bezpośrednio z poziomu usługi Codespace:
W terminalu usługi Codespace pobierz wartości środowiska AZD:
azd env get-valuesOtwórz
.env. Korzystając z danych wyjściowych terminalu, zaktualizuj następujące wartości w odpowiednich miejscach<input-manually-for-local-testing>.AZURE_OPENAI_ENDPOINTAZURE_SEARCH_SERVICE_URLAZURE_SEARCH_INDEX_NAME
Zaloguj się do Azure przy użyciu Azure CLI:
az loginDzięki temu biblioteka klienta Azure Identity w przykładowym kodzie odbiera token uwierzytelniania dla zalogowanego użytkownika.
Uruchom aplikację lokalnie:
pip install -r requirements.txt uvicorn main:appGdy zobaczysz, że aplikacja uruchomiona na porcie 8000 jest dostępna , wybierz pozycję Otwórz w przeglądarce.
Spróbuj zadać kilka pytań w interfejsie czatu. Jeśli otrzymasz odpowiedź, aplikacja łączy się pomyślnie z zasobem Azure OpenAI.
Zatrzymaj serwer deweloperski za pomocą Ctrl+C.
Zastosuj nową konfigurację
SEARCH_INDEX_NAMEw Azure i wdróż przykładowy kod aplikacji:azd up
5. Testowanie wdrożonej aplikacji RAG
Po pełnym wdrożeniu i skonfigurowaniu aplikacji można teraz przetestować funkcję RAG:
Otwórz adres URL aplikacji podany na końcu wdrożenia.
Zostanie wyświetlony interfejs czatu, w którym można wprowadzić pytania dotyczące zawartości przekazanych dokumentów.
Spróbuj zadać pytania specyficzne dla zawartości dokumentów. Na przykład, jeśli przekazałeś dokumenty w folderze sample-docs, możesz wypróbować następujące pytania:
- Jak firma Contoso korzysta z moich danych osobowych?
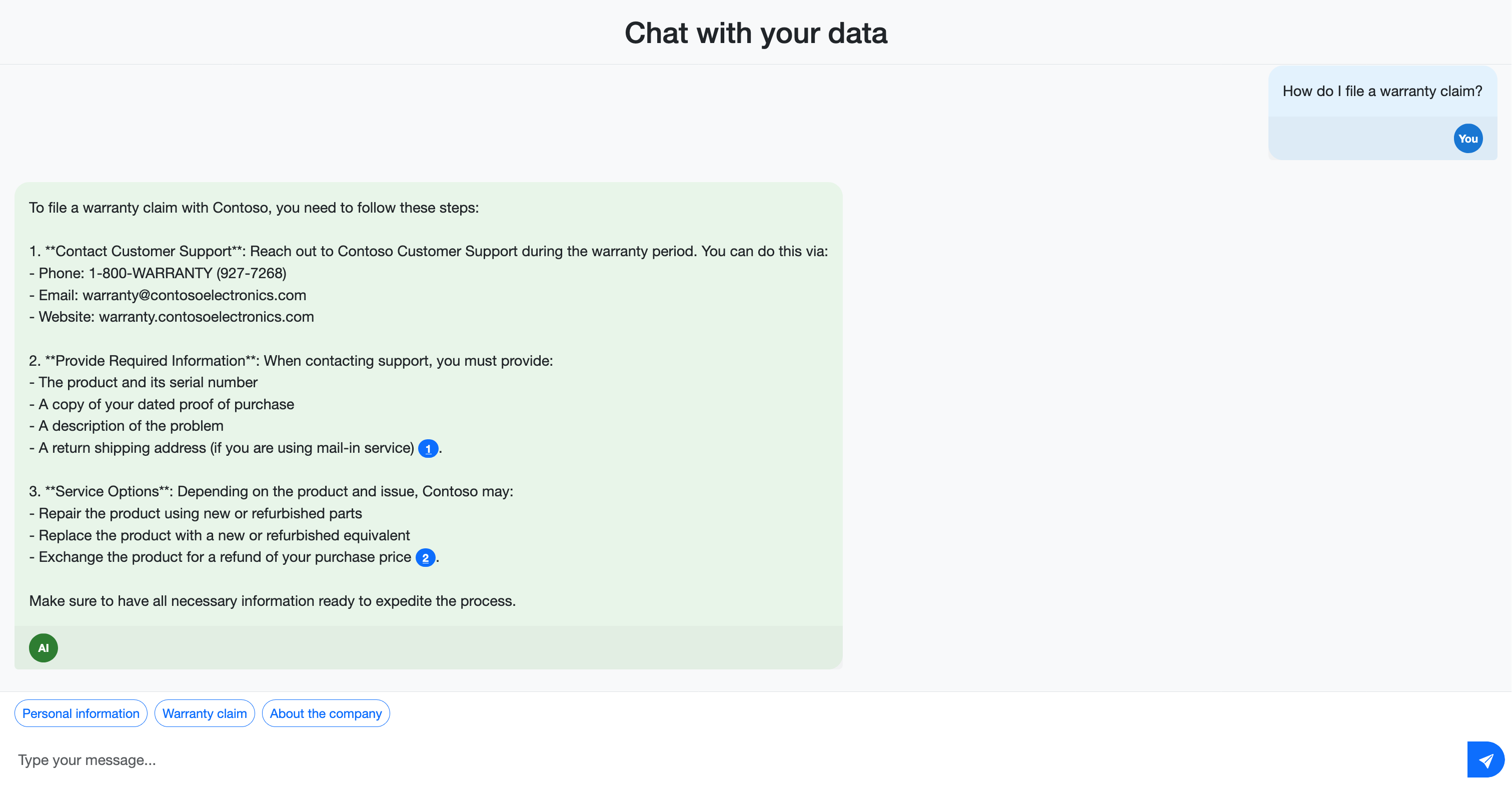
- W jaki sposób składasz roszczenie o gwarancji?
Zwróć uwagę, że odpowiedzi obejmują cytaty odwołujące się do dokumentów źródłowych. Te cytaty pomagają użytkownikom zweryfikować dokładność informacji i znaleźć więcej szczegółów w materiale źródłowym.
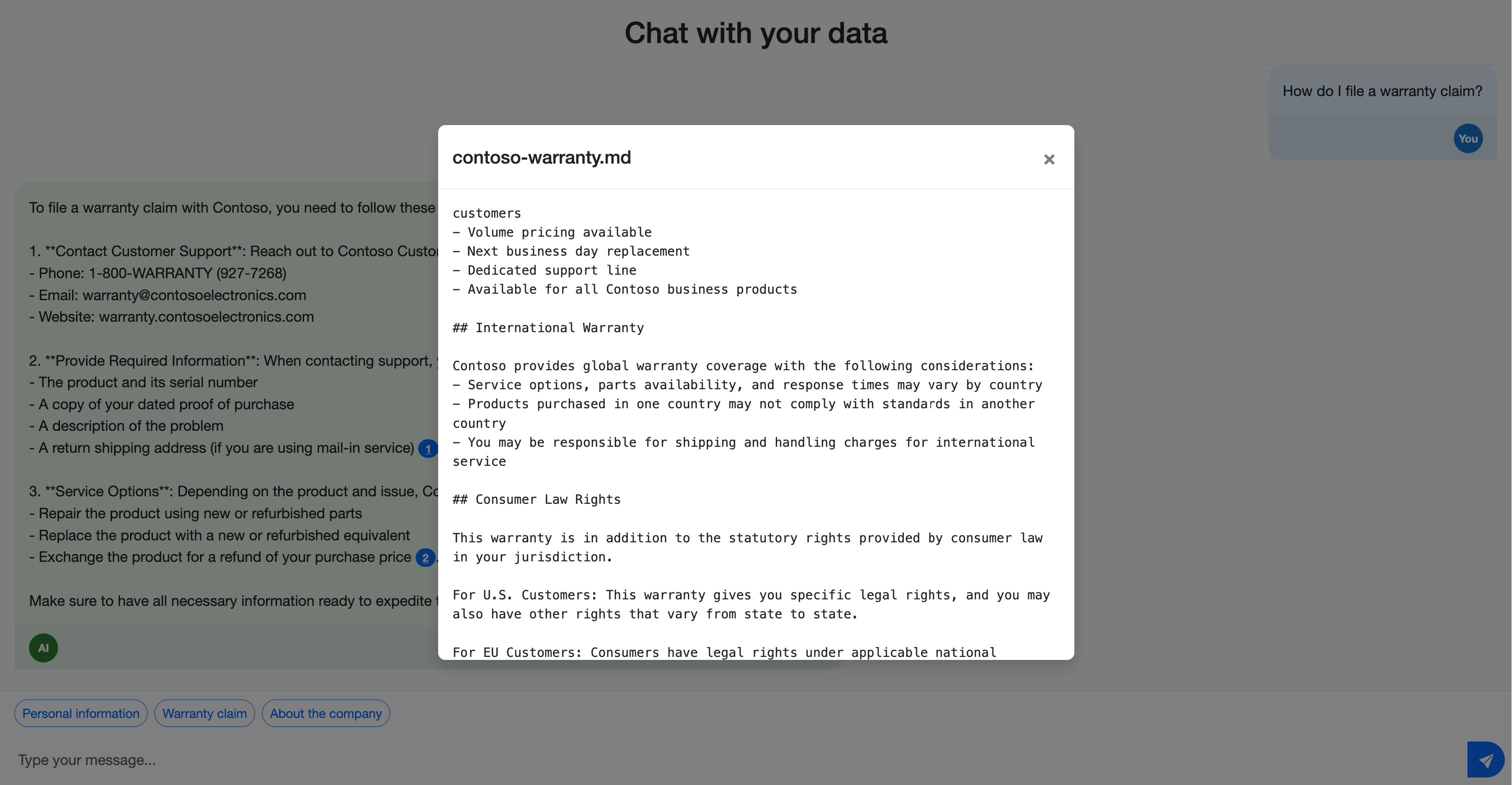
Przetestuj możliwości wyszukiwania hybrydowego, zadając pytania, które mogą korzystać z różnych metod wyszukiwania:
- Pytania dotyczące konkretnej terminologii (dobre dla wyszukiwania słów kluczowych).
- Pytania dotyczące pojęć, które mogą być opisane przy użyciu różnych terminów (dobre dla wyszukiwania wektorów).
- Złożone pytania wymagające zrozumienia kontekstu (dobre dla klasyfikacji semantycznej).
Uprzątnij zasoby
Po zakończeniu pracy z aplikacją możesz usunąć wszystkie zasoby, aby uniknąć ponoszenia dodatkowych kosztów:
azd down --purge
To polecenie usuwa wszystkie zasoby skojarzone z aplikacją.
Najczęściej zadawane pytania
- Jak przykładowy kod pobiera cytaty z odpowiedzi czatu generowanych przez Azure OpenAI?
- Jaka jest zaleta korzystania z tożsamości zarządzanych w tym rozwiązaniu?
- W jaki sposób tożsamość zarządzana przypisana przez system jest używana w tej architekturze i przykładowej aplikacji?
- W jaki sposób wyszukiwanie hybrydowe z semantycznym rankerem zaimplementowano w przykładowej aplikacji?
- Dlaczego wszystkie zasoby są tworzone w regionie Wschodnie USA 2?
- Czy mogę używać własnych modeli OpenAI zamiast tych dostarczonych przez Azure?
- Jak mogę poprawić jakość odpowiedzi?
W jaki sposób przykładowy kod pobiera cytowania z kompletań czatu w Azure OpenAI?
Przykład pobiera cytaty przy użyciu źródła danych z Azure AI Search dla klienta czatu. Po zażądaniu dokończenia czatu, odpowiedź zawiera obiekt citations w kontekście wiadomości. Przykładowa aplikacja przekazuje obiekt odpowiedzi do kodu klienta, który wyodrębnia cytaty w następujący sposób:
fetch('/api/chat/completion', {
// ...
})
// ...
.then(data => {
// ...
const message = choice.message;
const content = message.content;
// Extract citations from context
const citations = message.context?.citations || [];
// ...
})
W komunikacie odpowiedzi zawartość używa notacji [doc#], aby odwołać się do odpowiadającego cytatu na liście, umożliwiając użytkownikom śledzenie informacji do oryginalnych dokumentów źródłowych. Aby uzyskać więcej informacji, zobacz:
Jaka jest zaleta korzystania z tożsamości zarządzanych w tym rozwiązaniu?
Zarządzane tożsamości eliminują potrzebę przechowywania poświadczeń w kodzie lub konfiguracji. Korzystając z tożsamości zarządzanych, aplikacja może bezpiecznie uzyskiwać dostęp do usług Azure, takich jak Azure OpenAI i Azure AI Search, bez zarządzania tajnymi informacjami. Takie podejście jest zgodne z zasadami zabezpieczeń Zero Trust i zmniejsza ryzyko ujawnienia poświadczeń.
W jaki sposób tożsamość zarządzana przypisana przez system jest używana w tej architekturze i przykładowej aplikacji?
Wdrożenie AZD tworzy tożsamości zarządzane przypisane przez system dla Azure App Service, Azure OpenAI i Azure AI Search. Tworzy również odpowiednie przypisania ról dla każdego z nich (zobacz plik main.bicep ). Aby uzyskać informacje na temat wymaganych przypisań ról, zobacz Konfiguracja sieci i dostępu dla Azure OpenAI w Twoich danych.
W przykładowej aplikacji FastAPI, Azure SDKs używają tej tożsamości zarządzanej do bezpiecznego uwierzytelniania, więc nie trzeba przechowywać poświadczeń ani wpisów tajnych gdziekolwiek. Na przykład klient AsyncAzureOpenAI jest inicjowany przy użyciu DefaultAzureCredential, która automatycznie używa tożsamości zarządzanej podczas uruchamiania w Azure:
self.credential = DefaultAzureCredential()
token_provider = get_bearer_token_provider(
self.credential,
"https://cognitiveservices.azure.com/.default"
)
self.openai_client = AsyncAzureOpenAI(
azure_endpoint=self.openai_endpoint,
azure_ad_token_provider=token_provider,
api_version="2024-10-21"
)
Podobnie podczas konfigurowania źródła danych dla Azure AI Search tożsamość zarządzana jest określana na potrzeby uwierzytelniania:
data_source = {
"type": "azure_search",
"parameters": {
"endpoint": self.search_url,
"index_name": self.search_index_name,
"authentication": {
"type": "system_assigned_managed_identity"
},
# ...
}
}
response = await self.openai_client.chat.completions.create(
model=self.gpt_deployment,
messages=messages,
extra_body={
"data_sources": [data_source]
},
stream=False
)
Ta konfiguracja umożliwia bezpieczną, bez hasła komunikację między aplikacją FastAPI i usługami Azure, postępując zgodnie z najlepszymi rozwiązaniami dotyczącymi zabezpieczeń Zero Trust. Dowiedz się więcej na temat DefaultAzureCredential oraz biblioteki klienta Azure Identity dla Python.
W jaki sposób wyszukiwanie hybrydowe z semantycznym rankerem zaimplementowano w przykładowej aplikacji?
Przykładowa aplikacja konfiguruje wyszukiwanie hybrydowe przy użyciu klasyfikacji semantycznej przy użyciu zestawu SDK platformy Azure OpenAI. W zapleczu źródło danych jest skonfigurowane w następujący sposób:
data_source = {
"type": "azure_search",
"parameters": {
# ...
"query_type": "vector_semantic_hybrid",
"semantic_configuration": f"{self.search_index_name}-semantic-configuration",
"embedding_dependency": {
"type": "deployment_name",
"deployment_name": self.embedding_deployment
}
}
}
Ta konfiguracja umożliwia aplikacji łączenie wyszukiwania wektorowego (podobieństwa semantycznego), dopasowywania słów kluczowych i klasyfikacji semantycznej w jednym zapytaniu. Semantyczny klasyfikator zmienia kolejność wyników, aby zwrócić najbardziej trafne i kontekstowo odpowiednie odpowiedzi, które są następnie używane przez Azure OpenAI w celu generowania odpowiedzi.
Nazwa konfiguracji semantycznej jest automatycznie definiowana przez zintegrowany proces wektoryzacji. Używa ona nazwy indeksu wyszukiwania jako prefiksu i dołączania -semantic-configuration jako sufiksu. Gwarantuje to, że konfiguracja semantyczna jest unikatowo skojarzona z odpowiednim indeksem i jest zgodna z spójną konwencją nazewnictwa.
Dlaczego wszystkie zasoby są tworzone w regionie Wschodnie USA 2?
W przykładzie użyto modeli gpt-4o-mini i text-embedding-ada-002, które są dostępne w standardowym typie wdrożenia w regionie wschód USA 2. Te modele są również wybierane, ponieważ nie są one zaplanowane na wycofanie wkrótce, zapewniając stabilność wdrożenia próbnego. Dostępność modelu i typy wdrożeń mogą się różnić w zależności od regionu, dlatego wybrano Wschodnie USA 2, aby upewnić się, że przykład jest gotowy do użycia. Jeśli chcesz użyć innego regionu lub modeli, wybierz modele, które są dostępne dla tego samego typu wdrożenia w tym samym regionie. Podczas wybierania własnych modeli sprawdź zarówno ich dostępność, jak i daty wycofania, aby uniknąć zakłóceń.
- Dostępność modelu: modele usługi Azure OpenAI
- Daty wycofania modeli: Wycofanie i zakończenie wsparcia modeli usługi Azure OpenAI.
Czy mogę używać własnych modeli OpenAI zamiast tych udostępnianych przez Azure?
To rozwiązanie jest przeznaczone do pracy z Azure OpenAI Service. Chociaż można zmodyfikować kod tak, aby używał innych modeli OpenAI, utracisz zintegrowane funkcje zabezpieczeń, obsługę tożsamości zarządzanych i bezproblemową integrację z Azure AI Search zapewniane przez to rozwiązanie.
Jak mogę poprawić jakość odpowiedzi?
Jakość odpowiedzi można poprawić, wykonując następujące czynności:
- Przesyłanie dokumentów o wyższej jakości i większej relewantności.
- Dostosowywanie strategii segmentacji w procesie indeksowania usługi Azure AI Search. Nie można jednak dostosować dzielenia na fragmenty za pomocą zintegrowanej wektoryzacji pokazanej w tym samouczku.
- Eksperymentowanie z różnymi szablonami monitów w kodzie aplikacji.
- Dostrajanie wyszukiwania za pomocą innych właściwości w
type: "azure_searchźródle danych. - Korzystanie z bardziej wyspecjalizowanych modeli Azure OpenAI dla określonej domeny.