Tworzenie i trenowanie niestandardowego modelu wyodrębniania
Ta zawartość dotyczy:![]() v4.0 (wersja zapoznawcza) | Poprzednie wersje:
v4.0 (wersja zapoznawcza) | Poprzednie wersje:![]() v3.1 (GA)v3.0 (GA)
v3.1 (GA)v3.0 (GA)![]()
![]() v2.1
v2.1
Modele analizy dokumentów wymagają nawet pięciu dokumentów szkoleniowych, aby rozpocząć pracę. Jeśli masz co najmniej pięć dokumentów, możesz rozpocząć trenowanie modelu niestandardowego. Możesz wytrenować niestandardowy model szablonu (formularz niestandardowy) lub niestandardowy model neuronowy (dokument niestandardowy). Proces trenowania jest identyczny zarówno dla modeli, jak i w tym dokumencie przedstawiono proces trenowania dowolnego modelu.
Niestandardowe wymagania dotyczące danych wejściowych modelu
Najpierw upewnij się, że zestaw danych szkoleniowych jest zgodny z wymaganiami wejściowymi dotyczącymi analizy dokumentów.
Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
Obsługiwane formaty plików:
Model PDF Obraz:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) i HTMLPrzeczytaj ✔ ✔ ✔ Układ ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Dokument ogólny ✔ ✔ Wstępnie utworzona ✔ ✔ Niestandardowe wyodrębnianie ✔ ✔ Klasyfikacja niestandardowa ✔ ✔ ✔ (2024-02-29-preview) W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron (w przypadku subskrypcji w warstwie Bezpłatna przetwarzane są tylko pierwsze dwie strony).
Rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i 4 MB za bezpłatną (F0).
Wymiary obrazu muszą mieć od 50 x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Minimalna wysokość tekstu do wyodrębnienia to 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada około
8-point text na 150 kropek na cal (DPI).W przypadku trenowania modelu niestandardowego maksymalna liczba stron dla danych szkoleniowych wynosi 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
W przypadku trenowania niestandardowego modelu wyodrębniania łączny rozmiar danych treningowych wynosi 50 MB dla modelu szablonu i 1G-MB dla modelu neuronowego.
W przypadku trenowania niestandardowego modelu klasyfikacji całkowity rozmiar danych treningowych wynosi
1GBmaksymalnie 10 000 stron.
Porady dotyczące danych szkoleniowych
Postępuj zgodnie z poniższymi wskazówkami, aby zoptymalizować zestaw danych pod kątem trenowania:
- Użyj dokumentów PDF opartych na tekście zamiast dokumentów opartych na obrazach. Zeskanowane pliki PDF są obsługiwane jako obrazy.
- Użyj przykładów, które mają wszystkie pola ukończone dla formularzy z polami wejściowymi.
- Używaj formularzy z różnymi wartościami w każdym polu.
- Użyj większego zestawu danych (10–15 obrazów), jeśli obrazy formularzy mają niższą jakość.
Przekazywanie danych treningowych
Po zebraniu zestawu formularzy lub dokumentów na potrzeby trenowania należy przekazać go do kontenera usługi Azure Blob Storage. Jeśli nie wiesz, jak utworzyć konto usługi Azure Storage za pomocą kontenera, wykonaj czynności opisane w przewodniku Szybki start usługi Azure Storage dla witryny Azure Portal. Możesz użyć bezpłatnej warstwy cenowej (F0), aby wypróbować usługę, a następnie uaktualnić ją do warstwy płatnej dla środowiska produkcyjnego.
Wideo: Trenowanie modelu niestandardowego
- Po zebraniu i przekazaniu zestawu danych szkoleniowych możesz przystąpić do trenowania modelu niestandardowego. W poniższym filmie wideo utworzymy projekt i zapoznamy się z niektórymi podstawowymi informacjami dotyczącymi pomyślnego etykietowania i trenowania modelu.
Tworzenie projektu w programie Document Intelligence Studio
Program Document Intelligence Studio udostępnia i organizuje wszystkie wywołania interfejsu API wymagane do ukończenia zestawu danych i trenowania modelu.
Zacznij od przechodzenia do programu Document Intelligence Studio. Przy pierwszym użyciu programu Studio należy zainicjować subskrypcję, grupę zasobów i zasób. Następnie postępuj zgodnie z wymaganiami wstępnymi dotyczącymi projektów niestandardowych, aby skonfigurować program Studio w celu uzyskania dostępu do zestawu danych szkoleniowych.
W programie Studio wybierz kafelek Modele niestandardowe na stronie modele niestandardowe i wybierz przycisk Utwórz projekt .

W oknie dialogowym tworzenie projektu podaj nazwę projektu, opcjonalnie opis i wybierz pozycję Kontynuuj.
W następnym kroku przepływu pracy wybierz lub utwórz zasób analizy dokumentów przed wybraniem pozycji Kontynuuj.
Ważne
Niestandardowe modele neuronowe są dostępne tylko w kilku regionach. Jeśli planujesz trenowanie modelu neuronowego, wybierz lub utwórz zasób w jednym z tych obsługiwanych regionów.
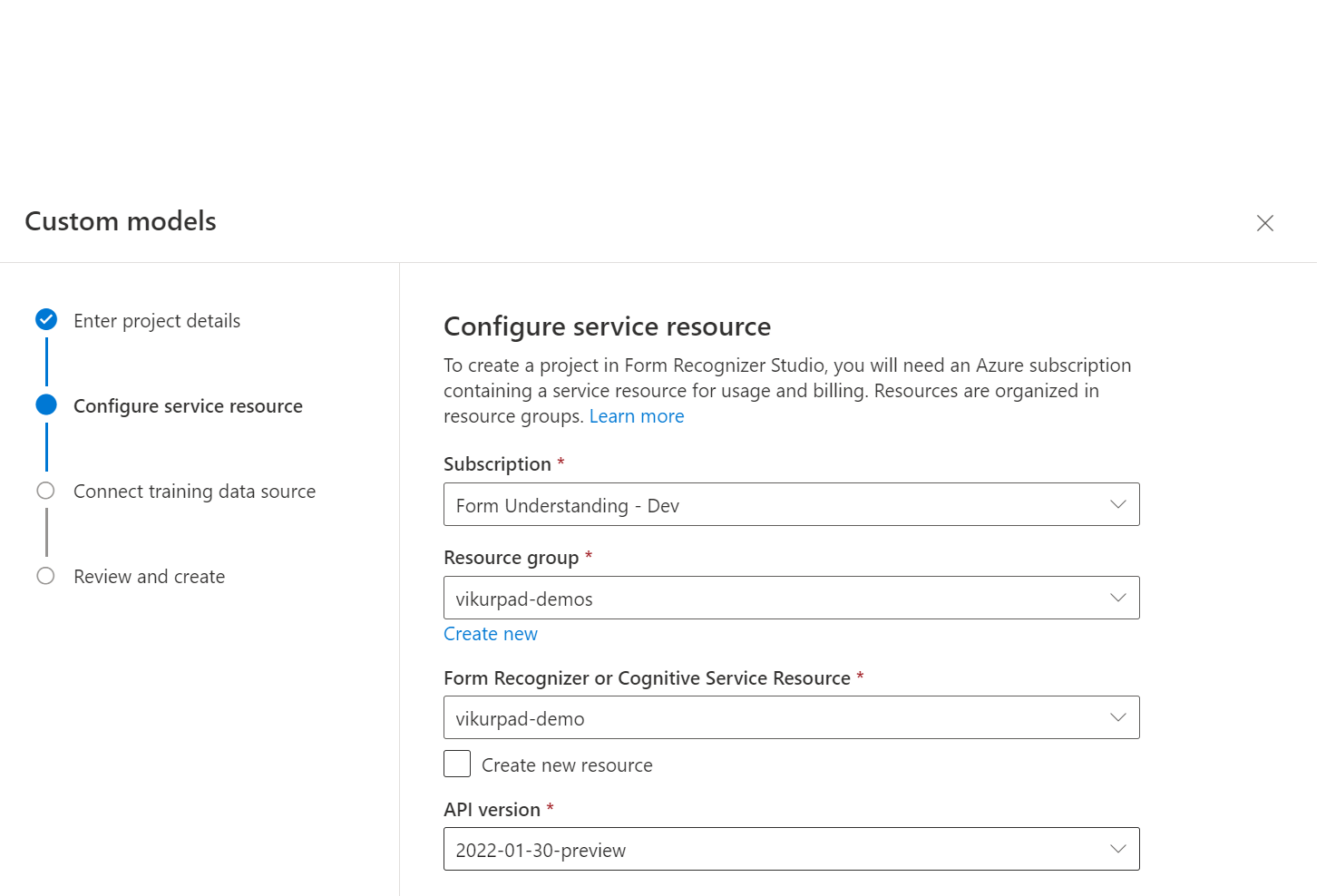
Następnie wybierz konto magazynu użyte do przekazania niestandardowego zestawu danych trenowania modelu. Ścieżka folderu powinna być pusta, jeśli dokumenty szkoleniowe znajdują się w katalogu głównym kontenera. Jeśli dokumenty znajdują się w podfolderze, wprowadź ścieżkę względną z katalogu głównego kontenera w polu Ścieżka folderu. Po skonfigurowaniu konta magazynu wybierz pozycję Kontynuuj.
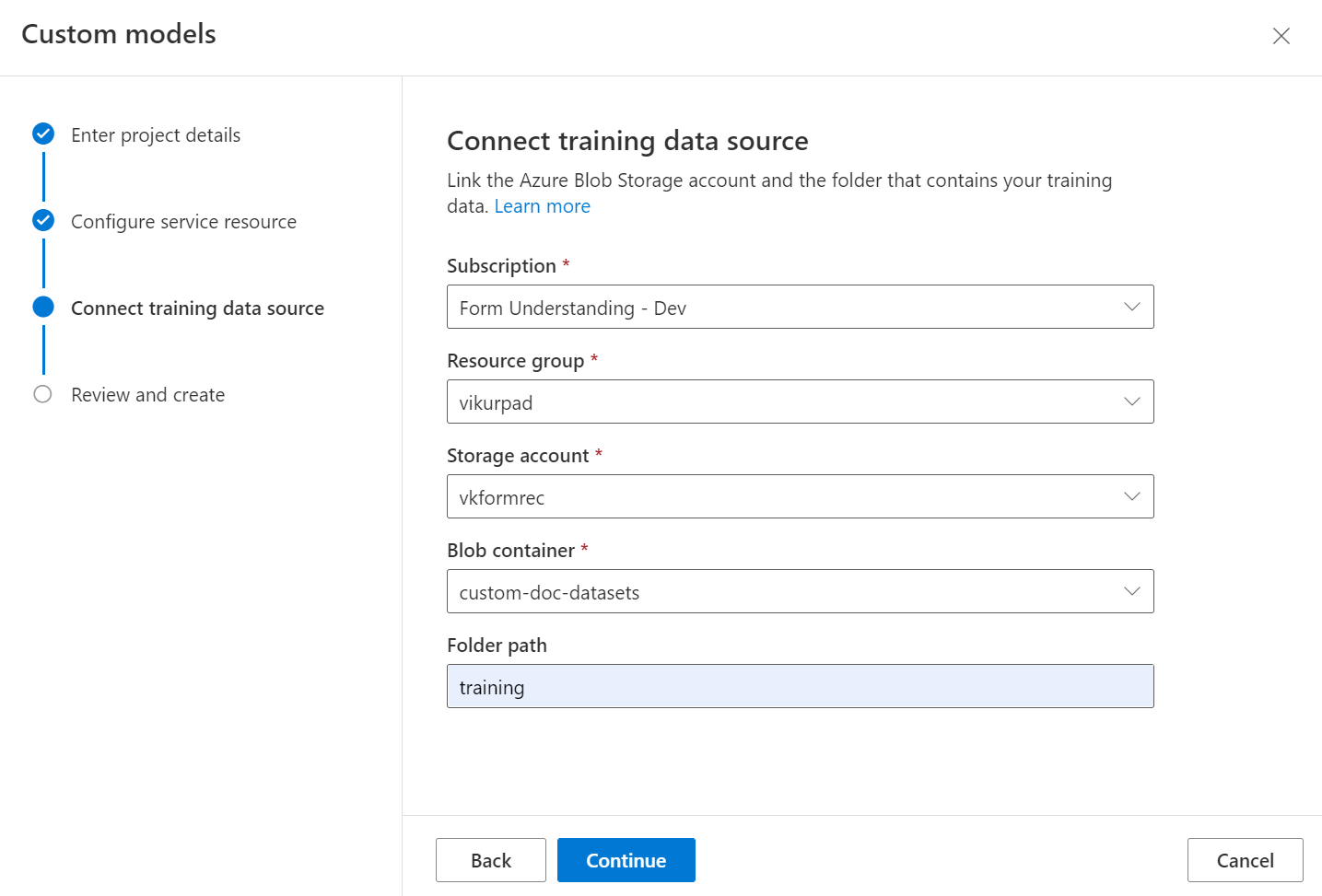
Na koniec przejrzyj ustawienia projektu i wybierz pozycję Utwórz projekt , aby utworzyć nowy projekt. Powinien być teraz w oknie etykietowania i zobaczyć pliki na liście zestawów danych.
Etykietowanie danych
W projekcie pierwszym zadaniem jest oznaczanie zestawu danych polami, które chcesz wyodrębnić.
Pliki przekazane do magazynu są wyświetlane po lewej stronie ekranu z pierwszym plikiem gotowym do etykietowania.
Rozpocznij etykietowanie zestawu danych i tworzenie pierwszego pola, wybierając przycisk plus (➕) w prawym górnym rogu ekranu.
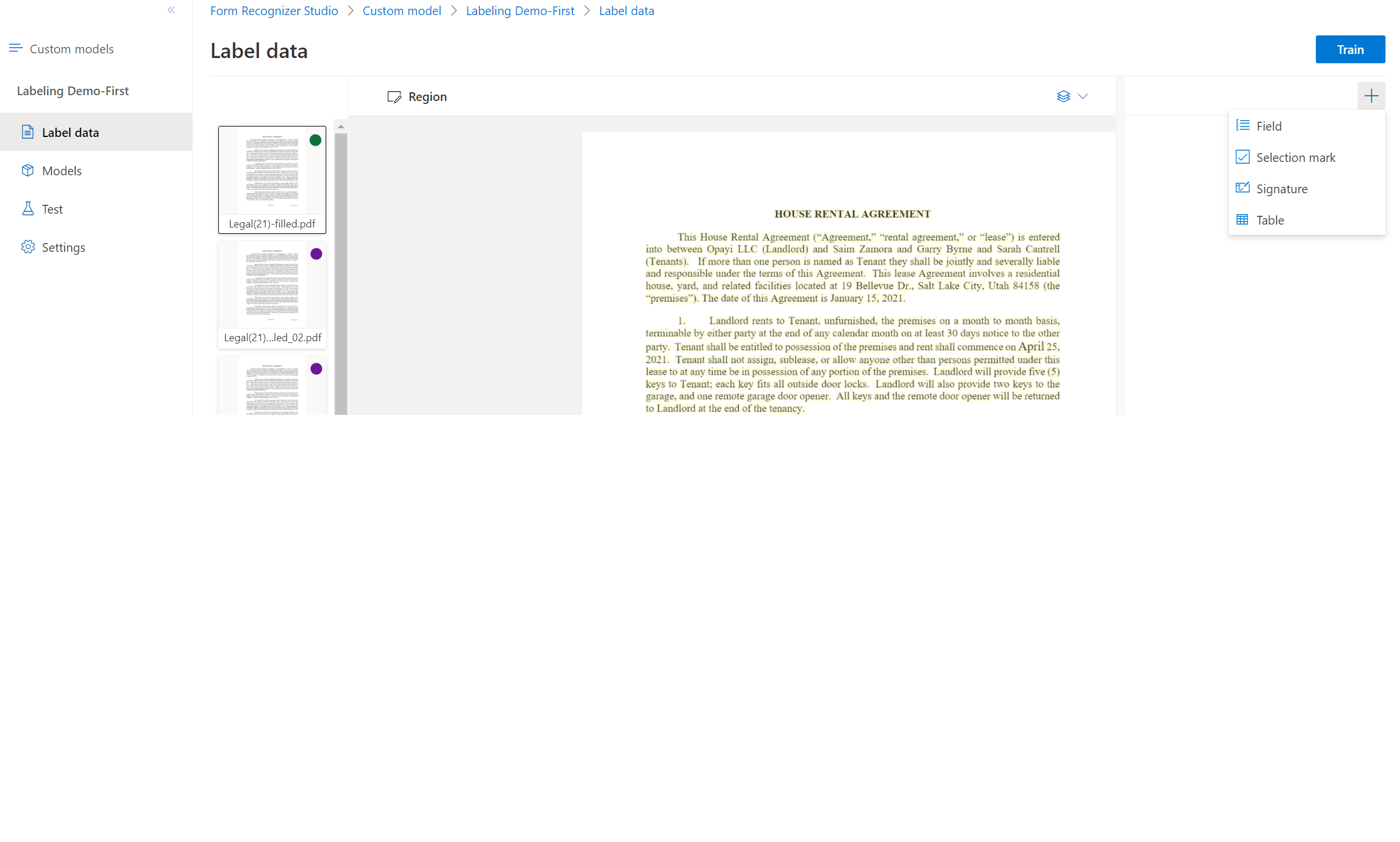
Wprowadź nazwę pola.
Przypisz wartość do pola, wybierając wyraz lub wyrazy w dokumencie. Wybierz pole z listy rozwijanej lub listy pól na prawym pasku nawigacyjnym. Wartość oznaczona etykietą znajduje się poniżej nazwy pola na liście pól.
Powtórz proces dla wszystkich pól, które chcesz oznaczyć dla zestawu danych.
Oznacz etykiety pozostałych dokumentów w zestawie danych, wybierając każdy dokument i wybierając tekst, który ma być oznaczony etykietą.
Masz teraz wszystkie dokumenty z etykietą zestawu danych. Pliki .labels.json i .ocr.json odpowiadają każdemu dokumentowi w zestawie danych trenowania i nowym pliku fields.json. Ten zestaw danych trenowania jest przesyłany do trenowania modelu.
Szkolenie modelu
Zestaw danych z etykietą jest teraz gotowy do trenowania modelu. Wybierz przycisk pociągu w prawym górnym rogu.
W oknie dialogowym Trenowanie modelu podaj unikatowy identyfikator modelu i opcjonalnie opis. Identyfikator modelu akceptuje typ danych ciągu.
W trybie kompilacji wybierz typ modelu, który chcesz wytrenować. Dowiedz się więcej o typach i możliwościach modelu.
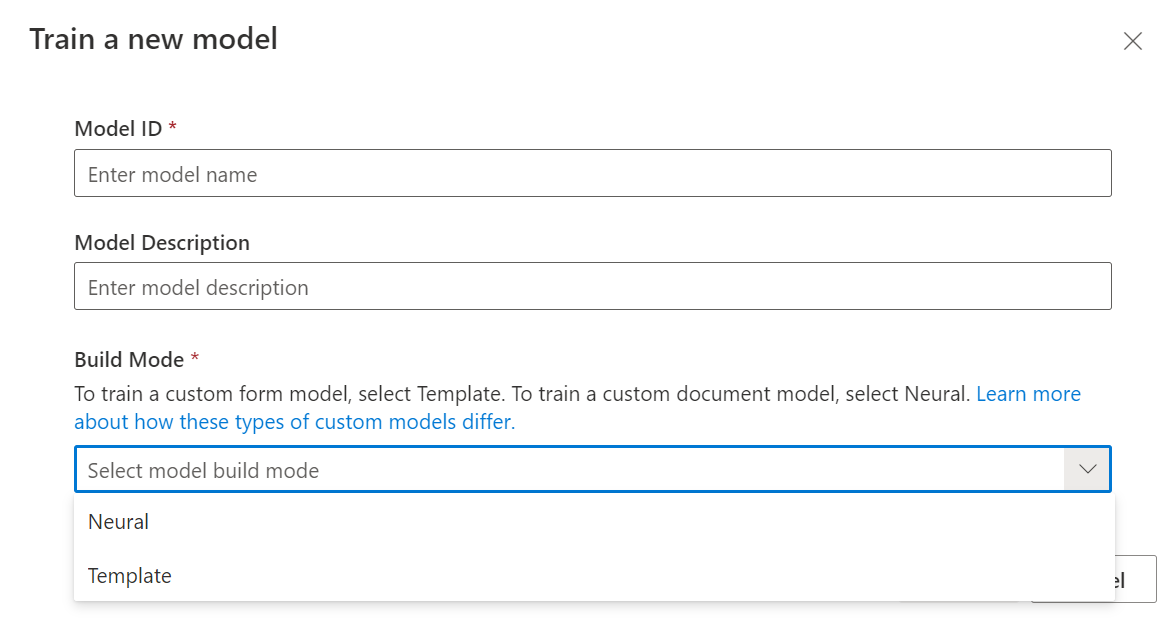
Wybierz pozycję Trenuj , aby zainicjować proces trenowania.
Modele szablonów trenują w ciągu kilku minut. Trenowanie modeli neuronowych może potrwać do 30 minut.
Przejdź do menu Modele , aby wyświetlić stan operacji trenowania.
Testowanie modelu
Po zakończeniu trenowania modelu możesz przetestować model, wybierając model na stronie listy modeli.
Wybierz model i wybierz przycisk Testuj.
Wybierz przycisk,
+ Addaby wybrać plik do przetestowania modelu.Po wybraniu pliku wybierz przycisk Analizuj , aby przetestować model.
Wyniki modelu są wyświetlane w oknie głównym, a wyodrębnione pola są wyświetlane na prawym pasku nawigacyjnym.
Zweryfikuj model, oceniając wyniki dla każdego pola.
Prawy pasek nawigacyjny zawiera również przykładowy kod do wywoływania modelu i wyników JSON z interfejsu API.
Gratulacje, których nauczyliśmy się trenować model niestandardowy w programie Document Intelligence Studio! Model jest gotowy do użycia z interfejsem API REST lub zestawem SDK do analizowania dokumentów.
Dotyczy:![]() v2.1. Inne wersje:v3.0
v2.1. Inne wersje:v3.0
Korzystając z niestandardowego modelu analizy dokumentów, należy podać własne dane szkoleniowe do operacji Train Custom Model (Trenowanie modelu niestandardowego), aby model mógł trenować do formularzy specyficznych dla branży. Postępuj zgodnie z tym przewodnikiem, aby dowiedzieć się, jak zbierać i przygotowywać dane do efektywnego trenowania modelu.
Potrzebujesz co najmniej pięciu wypełnionych formularzy tego samego typu.
Jeśli chcesz użyć ręcznie oznaczonych danymi treningowymi, musisz zacząć od co najmniej pięciu wypełnionych formularzy tego samego typu. Nadal można używać formularzy bez etykiet oprócz wymaganego zestawu danych.
Niestandardowe wymagania dotyczące danych wejściowych modelu
Najpierw upewnij się, że zestaw danych szkoleniowych jest zgodny z wymaganiami wejściowymi dotyczącymi analizy dokumentów.
Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
Obsługiwane formaty plików:
Model PDF Obraz:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) i HTMLPrzeczytaj ✔ ✔ ✔ Układ ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Dokument ogólny ✔ ✔ Wstępnie utworzona ✔ ✔ Niestandardowe wyodrębnianie ✔ ✔ Klasyfikacja niestandardowa ✔ ✔ ✔ (2024-02-29-preview) W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron (w przypadku subskrypcji w warstwie Bezpłatna przetwarzane są tylko pierwsze dwie strony).
Rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i 4 MB za bezpłatną (F0).
Wymiary obrazu muszą mieć od 50 x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Minimalna wysokość tekstu do wyodrębnienia to 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada około
8-point text na 150 kropek na cal (DPI).W przypadku trenowania modelu niestandardowego maksymalna liczba stron dla danych szkoleniowych wynosi 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
W przypadku trenowania niestandardowego modelu wyodrębniania łączny rozmiar danych treningowych wynosi 50 MB dla modelu szablonu i 1G-MB dla modelu neuronowego.
W przypadku trenowania niestandardowego modelu klasyfikacji całkowity rozmiar danych treningowych wynosi
1GBmaksymalnie 10 000 stron.
Porady dotyczące danych szkoleniowych
Postępuj zgodnie z tymi wskazówkami, aby jeszcze bardziej zoptymalizować zestaw danych na potrzeby trenowania.
- Użyj dokumentów PDF opartych na tekście zamiast dokumentów opartych na obrazach. Zeskanowane pliki PDF są obsługiwane jako obrazy.
- Użyj przykładów, które zawierają wszystkie pola wypełnione dla wypełnionych formularzy.
- Używaj formularzy z różnymi wartościami w każdym polu.
- Użyj większego zestawu danych (10–15 obrazów) dla wypełnionych formularzy.
Przekazywanie danych treningowych
Po zebraniu zestawu dokumentów na potrzeby trenowania należy przekazać go do kontenera usługi Azure Blob Storage. Jeśli nie wiesz, jak utworzyć konto usługi Azure Storage za pomocą kontenera, postępuj zgodnie z przewodnikiem Szybki start usługi Azure Storage w witrynie Azure Portal. Użyj warstwy wydajności standardowej.
Jeśli chcesz użyć ręcznie oznaczonych danymi, przekaż pliki .labels.json i .ocr.json odpowiadające dokumentom szkoleniowym. Aby wygenerować te pliki, możesz użyć narzędzia Do etykietowania przykładowego (lub własnego interfejsu użytkownika).
Organizowanie danych w podfolderach (opcjonalnie)
Domyślnie interfejs API trenowania modelu niestandardowego używa tylko dokumentów znajdujących się w katalogu głównym kontenera magazynu. Można jednak trenować za pomocą danych w podfolderach, jeśli określisz je w wywołaniu interfejsu API. Zwykle treść wywołania Train Custom Model ma następujący format, gdzie <SAS URL> jest adresem URL sygnatury dostępu współdzielonego kontenera:
{
"source":"<SAS URL>"
}
Jeśli dodasz następującą zawartość do treści żądania, interfejs API trenuje z dokumentami znajdującymi się w podfolderach. Pole "prefix" jest opcjonalne i ogranicza zestaw danych treningowych do plików, których ścieżki zaczynają się od danego ciągu. Dlatego wartość "Test", na przykład powoduje, że interfejs API będzie przeglądać tylko pliki lub foldery, które zaczynają się od słowa Test.
{
"source": "<SAS URL>",
"sourceFilter": {
"prefix": "<prefix string>",
"includeSubFolders": true
},
"useLabelFile": false
}
Następne kroki
Teraz, gdy wiesz już, jak utworzyć zestaw danych treningowych, postępuj zgodnie z przewodnikiem Szybki start, aby wytrenować niestandardowy model analizy dokumentów i rozpocząć korzystanie z niego w formularzach.