Antywzorzec zajętego frontonu
Wykonywanie asynchronicznych działań na dużej liczbie wątków w tle może blokować zasoby innych jednoczesnych zadań pierwszego planu, zmniejszając czasy odpowiedzi do poziomów nie do przyjęcia.
Opis problemu
Zadania obciążające zasoby mogą wydłużyć czas odpowiedzi dla żądań użytkowników i spowodować duże opóźnienie. Jednym ze sposobów skrócenia czasu odpowiedzi jest odciążenie zadania obciążającego zasoby do oddzielnego wątku. Takie podejście umożliwia aplikacji dalsze reagowanie, zaś przetwarzanie odbywa się w tle. Jednak zadania, które są uruchamiane w wątku tła, nadal zużywają zasoby. Jeśli istnieje ich zbyt wiele, mogą zablokować wątki obsługujące żądania.
Uwaga
Termin zasoby może obejmować wiele elementów, takich jak użycie procesora CPU, zajętość pamięci i operacje we/wy sieci lub dysku.
Ten problem zazwyczaj występuje, gdy aplikacja jest opracowana jako monolityczny kod i ma całość logiki biznesowej umieszczoną w pojedynczej warstwie współdzielonej z warstwą prezentacji.
Oto przykład korzystający z programu ASP.NET, który pokazuje problem. Pełny przykład można znaleźć tutaj.
public class WorkInFrontEndController : ApiController
{
[HttpPost]
[Route("api/workinfrontend")]
public HttpResponseMessage Post()
{
new Thread(() =>
{
//Simulate processing
Thread.SpinWait(Int32.MaxValue / 100);
}).Start();
return Request.CreateResponse(HttpStatusCode.Accepted);
}
}
public class UserProfileController : ApiController
{
[HttpGet]
[Route("api/userprofile/{id}")]
public UserProfile Get(int id)
{
//Simulate processing
return new UserProfile() { FirstName = "Alton", LastName = "Hudgens" };
}
}
Metoda
PostkontroleraWorkInFrontEndimplementuje operację POST protokołu HTTP. Ta operacja symuluje długotrwałe zadanie wykorzystujące dużo mocy procesora CPU. Praca jest wykonywana w oddzielnym wątku w ramach próby włączenia operacji POST i jej szybkiego zakończenia.Metoda
GetkontroleraUserProfileimplementuje operację GET protokołu HTTP. Ta metoda zużywa znacznie mniej mocy procesora CPU.
Podstawową kwestią są wymagania metody Post dotyczące zasobów. Chociaż umieszcza ona pracę w wątku w tle, praca może nadal zużywać znaczne ilości zasobów procesora CPU. Te zasoby są współużytkowane z innymi operacjami wykonywanymi przez innych równoczesnych użytkowników. Jeśli umiarkowana liczba użytkowników jednocześnie wysyła to żądanie, ogólna wydajność najprawdopodobniej ucierpi, spowalniając wszystkie operacje. Użytkownicy mogą na przykład odczuć znaczne opóźnienie w metodzie Get.
Jak rozwiązać ten problem
Przenieś procesy, które zużywają znaczne zasoby, do oddzielnej wewnętrznej bazy danych.
Przy takim podejściu fronton umieszcza zadania zużywające dużo zasobów w kolejce komunikatów. Wewnętrzna baza danych przejmuje zadania do przetwarzania asynchronicznego. Kolejka działa również jako moduł wyrównywania obciążenia, buforując żądania dla wewnętrznej bazy danych. Jeśli długość kolejki staje się za długa, możesz skonfigurować skalowanie automatyczne do skalowania w poziomie wewnętrznej bazy danych.
Oto zmodyfikowana wersja poprzedniego kodu. W tej wersji metoda Post umieszcza komunikat w kolejce usługi Service Bus.
public class WorkInBackgroundController : ApiController
{
private static readonly QueueClient QueueClient;
private static readonly string QueueName;
private static readonly ServiceBusQueueHandler ServiceBusQueueHandler;
public WorkInBackgroundController()
{
var serviceBusConnectionString = ...;
QueueName = ...;
ServiceBusQueueHandler = new ServiceBusQueueHandler(serviceBusConnectionString);
QueueClient = ServiceBusQueueHandler.GetQueueClientAsync(QueueName).Result;
}
[HttpPost]
[Route("api/workinbackground")]
public async Task<long> Post()
{
return await ServiceBusQueueHandler.AddWorkLoadToQueueAsync(QueueClient, QueueName, 0);
}
}
Wewnętrzna baza danych ściąga wiadomości z kolejki usługi Service Bus i je przetwarza.
public async Task RunAsync(CancellationToken cancellationToken)
{
this._queueClient.OnMessageAsync(
// This lambda is invoked for each message received.
async (receivedMessage) =>
{
try
{
// Simulate processing of message
Thread.SpinWait(Int32.MaxValue / 1000);
await receivedMessage.CompleteAsync();
}
catch
{
receivedMessage.Abandon();
}
});
}
Kwestie wymagające rozważenia
- Takie podejście wprowadza nieco większą złożoność do aplikacji. Musisz bezpiecznie obsługiwać usługi kolejkowania i usuwania z kolejki, aby uniknąć utraty żądań w przypadku awarii.
- Aplikacja przyjmuje zależność od dodatkowej usługi dla kolejki wiadomości.
- Środowisko przetwarzania musi być wystarczająco skalowalne, aby obsłużyć oczekiwane obciążenie i spełnić wymagane cele przepływności.
- Chociaż ta metoda powinna zwiększyć ogólną szybkość reakcji, wykonanie zadań, które są przenoszone do wewnętrznej bazy danych, może potrwać dłużej.
Jak wykryć problem
Objawy zajętego frontonu obejmują duże opóźnienie podczas wykonywania zadań intensywnie używających zasobów. Użytkownicy końcowi mogą zgłaszać rozszerzone czasy odpowiedzi lub błędy spowodowane przekroczeniem limitu czasu usług. Te błędy mogą również zwracać błędy HTTP 500 (wewnętrzny serwer) lub HTTP 503 (usługa niedostępna). Sprawdź dzienniki zdarzeń serwera internetowego, które najprawdopodobniej zawierają bardziej szczegółowe informacje dotyczące przyczyn i okoliczności błędów.
Możesz wykonać następujące kroki, aby ułatwić zidentyfikowanie tego problemu:
- Monitoruj procesy systemu produkcyjnego, aby zidentyfikować punkty, gdzie czasy odpowiedzi są długie.
- Przeanalizuj dane telemetryczne przechwycone w tych punktach, aby określić mieszankę różnych wykonywanych operacji i używane zasoby.
- Znajdź wszelkie korelacje między długim czasem odpowiedzi oraz woluminami i kombinacjami operacji, które były wykonywane w tym czasie.
- Przetestuj pod obciążeniem każdą podejrzaną operację, aby zidentyfikować, które operacje zużywają zasoby i blokują inne operacje.
- Przejrzyj kod źródłowy tych operacji, aby określić, dlaczego mogą one powodować nadmierne wykorzystanie zasobów.
Przykładowa diagnostyka
W poniższych sekcjach zastosowano te kroki do opisanej wcześniej przykładowej aplikacji.
Identyfikowanie punktów spowolnienia
Przygotuj instrumentację każdej metody do śledzenia czasu trwania i zasobów używanych przez każde żądanie. Następnie monitoruj aplikację w środowisku produkcyjnym. Może to zapewnić ogólny obraz sposobu konkurowania żądań ze sobą. W okresach dużego obciążenia wolno działające, zużywające dużo zasobów żądania prawdopodobnie będą miały wpływ na inne operacje, a to zachowanie można zaobserwować, monitorując system i zapisując spadki wydajności.
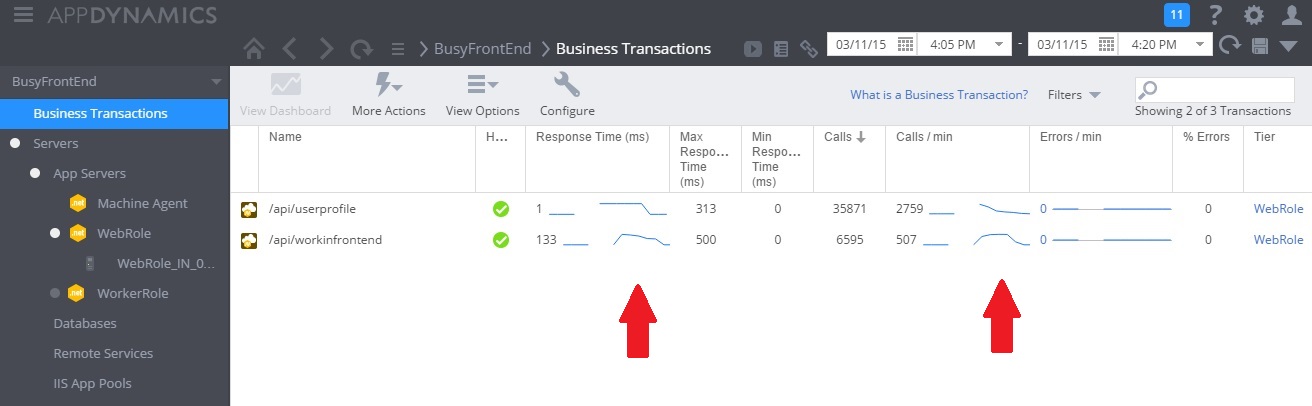
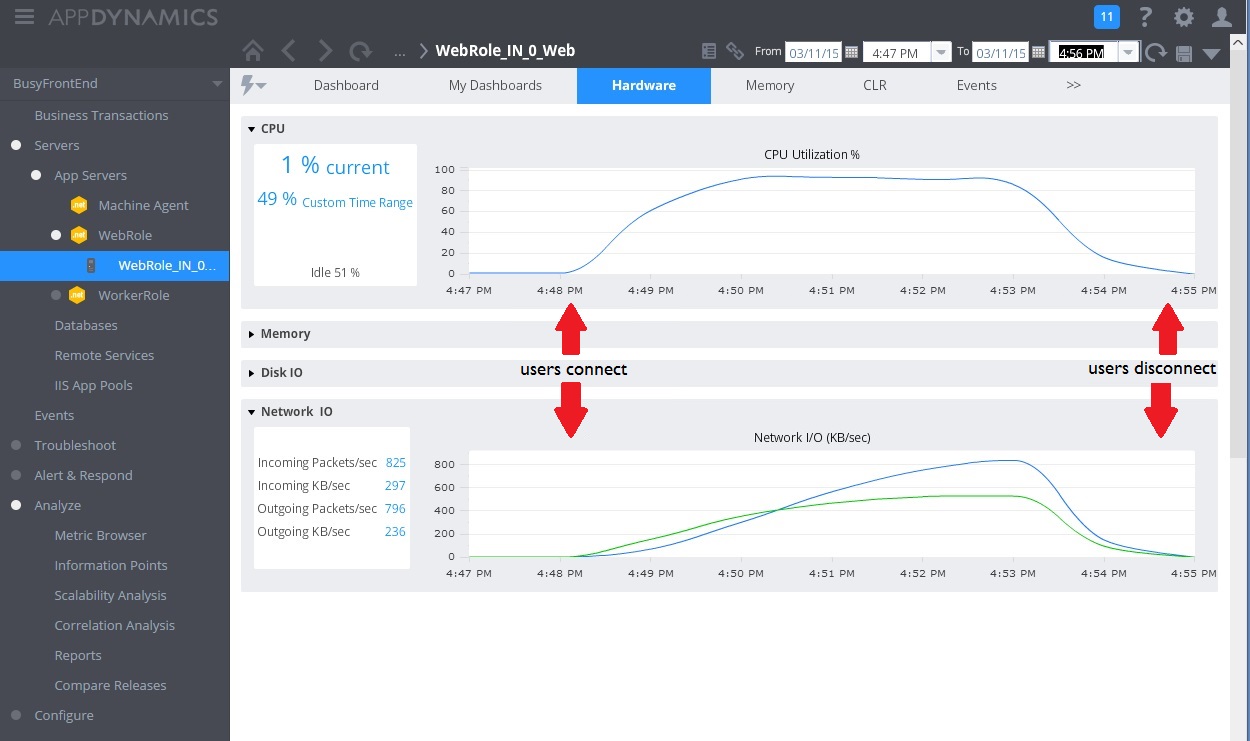
Poniższa ilustracja przedstawia pulpit nawigacyjny monitorowania. (Użyliśmy AppDynamics dla naszych testów). Początkowo system ma lekkie obciążenie. Następnie użytkownicy zaczynają żądać metody GET UserProfile. Wydajność jest względnie dobra dopóki inni użytkownicy nie zaczną wprowadzać żądań do metody POST WorkInFrontEnd. W tym punkcie zdecydowanie wzrasta czas odpowiedzi (pierwsza strzałka). Czasy odpowiedzi poprawiają się dopiero tym, jak zmniejsza się liczba żądań do kontrolera WorkInFrontEnd (druga strzałka).
Sprawdzanie danych telemetrycznych i znajdowanie korelacji
Następny obraz przedstawia niektóre metryki zebrane do monitorowania wykorzystania zasobów w tym samym przedziale czasu. Najpierw niewielu użytkowników uzyskuje dostęp do systemu. W miarę podłączania większej liczby użytkowników wykorzystanie procesora CPU staje się bardzo duże (100%). Należy też zauważyć, że szybkość operacji we/wy sieci początkowo rośnie wraz ze wzrostem wykorzystania procesora CPU. Jednak, gdy użycie procesora CPU skacze, operacje we/wy sieci w rzeczywistości spadają. Wynika to z tego, że system może obsłużyć tylko niewielką liczbę żądań, gdy procesor CPU osiągnie maksymalną wydajność. W miarę odłączania użytkowników obciążenie procesora CPU spada.
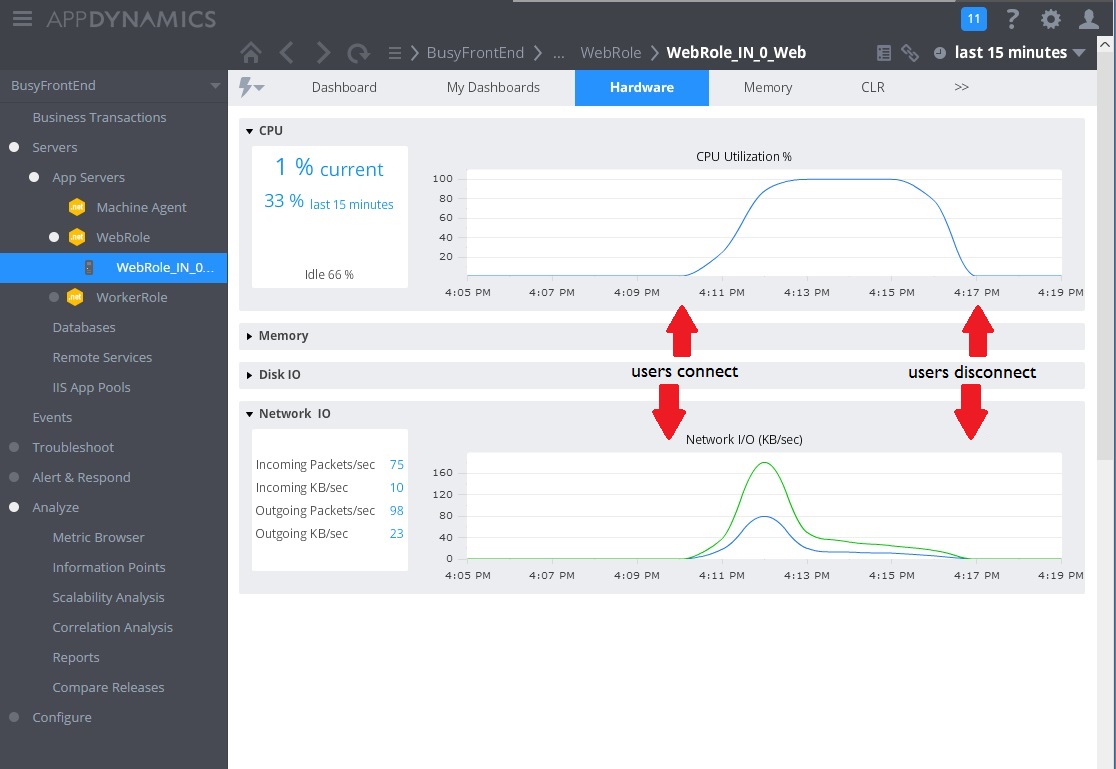
W tym momencie wydaje się, że metoda Post na kontrolerze WorkInFrontEnd jest podstawowym kandydatem do dokładniejszej kontroli. Aby potwierdzić hipotezę, potrzebna jest praca w środowisku kontrolowanym.
Wykonywanie testów obciążenia
Następnym krokiem jest do wykonanie testów w środowisku kontrolowanym. Na przykład uruchom serię testów obciążenia, które obejmują, a następnie pomijają każde żądanie po kolei, aby zobaczyć skutki.
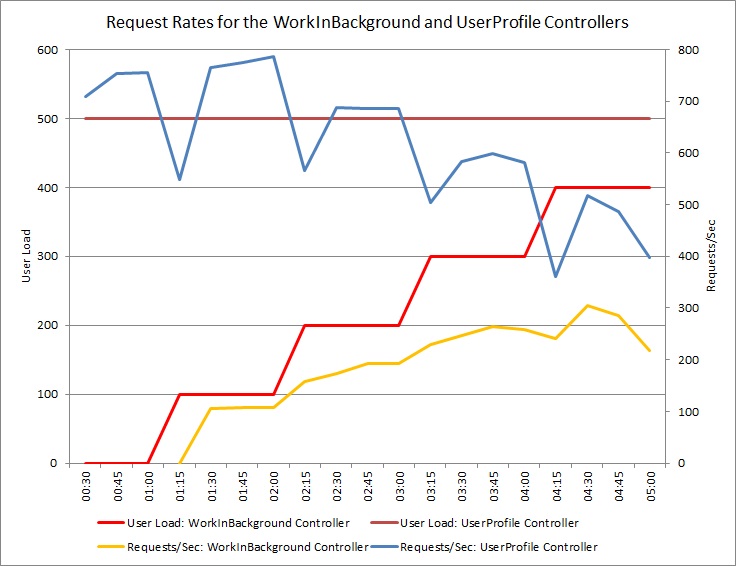
Wykres poniżej przedstawia wyniki testu obciążenia wykonanego dla identycznego wdrożenia usługi w chmurze używanego w poprzednich testach. Test używał stałego obciążenia równego 500 użytkowników wykonujących operację Get w kontrolerze UserProfile oraz obciążenia krokowego użytkownikami wykonującymi operację Post w kontrolerze WorkInFrontEnd.
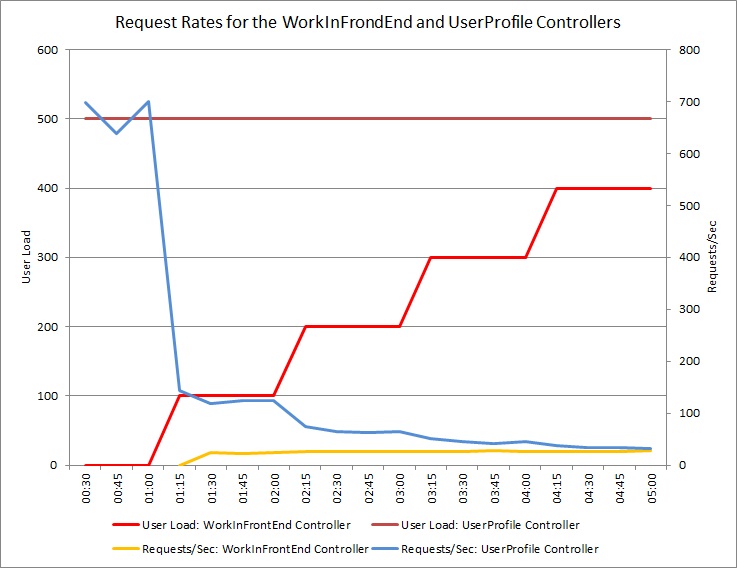
Początkowo krok obciążenia wynosi 0, więc tylko aktywni użytkownicy wprowadzają żądania UserProfile. System jest w stanie odpowiedzieć na około 500 żądań na sekundę. Po 60 sekundach zwiększono obciążenie o 100 dodatkowych użytkowników rozpoczynających wysyłanie żądań POST do kontrolera WorkInFrontEnd. Niemal natychmiast obciążenie wysyłane do kontrolera UserProfile spada do około 150 żądań na sekundę. Jest to spowodowane sposobem funkcjonowania modułu uruchamiającego test obciążenia. Czeka on na odpowiedź przed wysłaniem następnego żądania, więc im dłużej trzeba czekać na odpowiedź, tym niższa jest częstotliwość żądań.
Im więcej użytkowników wysyła żądania POST do kontrolera WorkInFrontEnd, tym mniejsza jest częstotliwość odpowiedzi kontrolera UserProfile. Należy jednak pamiętać, że liczba żądań obsługiwanych przez WorkInFrontEnd kontroler pozostaje względnie stała. Nasycenie systemu staje się oczywiste, gdy ogólna częstotliwość obu żądań dąży do stałego, ale niskiego ograniczenia.
Przegląd kodu źródłowego
Ostatni krok polega na przeglądzie kodu źródłowego. Zespół deweloperów był świadomy, że metoda Post może zająć znaczną ilość czasu, dlatego oryginalna implementacja używa oddzielnego wątku. Rozwiązało to bezpośredni problem, ponieważ metoda Post nie blokowała oczekiwania na ukończenie długotrwałego zadania.
Jednak praca wykonana przez tę metodę nadal zużywa moc procesora, pamięć i inne zasoby. Włączenie tego procesu, aby działał asynchronicznie, może faktycznie pogorszyć wydajność, ponieważ użytkownicy mogą jednocześnie wyzwalać dużą liczbę tych operacji w sposób niekontrolowany. Istnieje ograniczona liczba wątków, które można uruchomić na serwerze. Poza tym ograniczeniem aplikacja najprawdopodobniej uzyska wyjątek, gdy spróbuje uruchomić nowy wątek.
Uwaga
Nie oznacza to, że należy unikać operacji asynchronicznych. Wykonywanie asynchronicznego oczekiwania na wywołanie w sieci jest zalecanym rozwiązaniem. (Zobacz Synchroniczny antywzorzec we/wy ). Problem polega na tym, że praca intensywnie korzystająca z procesora CPU została zduplikowana w innym wątku.
Implementowanie rozwiązania i weryfikowanie wyniku
Na poniższej ilustracji przedstawiono monitorowanie wydajności po zaimplementowaniu rozwiązania. Obciążenie było podobne do przedstawionego wcześniej, ale czasy odpowiedzi dla kontrolera UserProfile są teraz znacznie krótsze. Liczba żądań wzrosła w tym samym czasie z 2759 do 23 565.
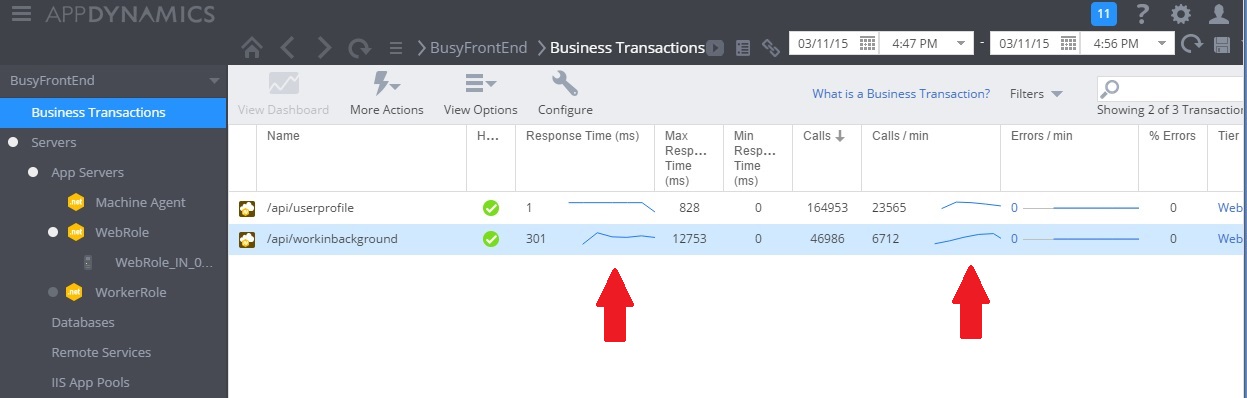
Należy pamiętać, że kontroler WorkInBackground również obsługiwał znacznie większą liczbę żądań. Jednak w tym przypadku nie można przeprowadzić bezpośredniego porównania, ponieważ praca wykonywana w tym kontrolerze bardzo różni się od oryginalnego kodu. Nowa wersja po prostu kolejkuje żądania zamiast wykonywania czasochłonnych obliczeń. Główną kwestią jest, że ta metoda już nie ściąga w dół całego systemu pod obciążeniem.
Wykorzystanie procesora CPU i sieci również wykazuje lepszą wydajność. Wykorzystanie procesora CPU nigdy nie osiąga 100% i liczba obsłużonych żądań sieci była znacznie większa niż wcześniej i nie spadła do chwili porzucenia obciążenia.
Poniższy wykres pokazuje wyniki testów obciążenia. Ogólna liczba obsłużonych żądań jest znacznie większa w porównaniu z wcześniejszymi testami.
Wskazówki pokrewne
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla