Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Przetwarzanie języka naturalnego obejmuje techniki, które analizują, rozumieją i generują język ludzki na podstawie danych tekstowych. Azure udostępnia zarządzane usługi oparte na interfejsie API i rozproszone struktury typu open source, które dotyczą obciążeń przetwarzania języka naturalnego, które wahają się od analizy tonacji i rozpoznawania jednostek do klasyfikacji dokumentów i podsumowania tekstu. Ten przewodnik ułatwia ocenę i wybór spośród podstawowych opcji przetwarzania języka naturalnego w Azure, dzięki czemu można dopasować odpowiednią technologię do wymagań dotyczących obciążenia.
Notatka
Ten przewodnik koncentruje się na możliwościach przetwarzania języka naturalnego dostępnych za pośrednictwem Azure Language i Apache Spark z usługą Spark NLP w Azure Databricks lub Microsoft Fabric. Nie zawiera wskazówek dotyczących wybierania modeli językowych ani projektowania Azure rozwiązań OpenAI. Niektóre opisy platform mogą odwoływać się do obsługiwanych integracji modelu podstawowego lub modelu mowy jako szczegółów implementacji, ale ten przewodnik koncentruje się na wyborze usługi przetwarzania języka naturalnego. Aby uzyskać więcej informacji, zobacz Wybieranie technologii usług sztucznej inteligencji.
Omówienie przetwarzania języka naturalnego i modeli językowych
Zanim ocenisz usługi Azure, dowiedz się, czym jest przetwarzanie języka naturalnego, czym różni się od modeli językowych i jakie zadania rozwiązuje.
Rozróżnianie przetwarzania języka naturalnego od modeli językowych
W tej sekcji wyjaśniono granicę między przetwarzaniem języka naturalnego a modelami języka naturalnego, a także bada podstawowe możliwości, które umożliwiają techniki przetwarzania języka naturalnego.
| Wymiar | Przetwarzanie języka naturalnego | Modele językowe |
|---|---|---|
| Scope | Szerokie pole obejmujące różne techniki przetwarzania tekstu, w tym tokenizację, sprowadzanie do rdzenia, rozpoznawanie encji, analizę tonacji i klasyfikację dokumentów. | Podzbiór głębokiego uczenia w przetwarzaniu języka naturalnego, który koncentruje się na zadaniach związanych z wysokopoziomowym zrozumieniem i generowaniem języka. |
| Examples | Analizatory oparte na regułach, klasyfikatory TF-IDF, rozpoznawanie jednostek nazwanych, analizatory sentymentu. | Modele GPT, BERT i podobne modele oparte na transformatorach, które generują tekst przypominający ludzki i uwzględniający kontekst. |
| Wynik | Sygnały ustrukturyzowane, takie jak etykiety, wyniki, wyodrębnione zakresy i przeanalizowana składnia. | Płynny język naturalny, taki jak wygenerowany tekst, podsumowania, odpowiedzi i uzupełnienia. |
| Relacja | Domena nadrzędna. Przetwarzanie języka naturalnego obejmuje pełne spektrum metod przetwarzania tekstu. | Narzędzie do przetwarzania języka naturalnego. Modele językowe zwiększają możliwości przetwarzania języka naturalnego bez zastępowania go. Obsługują szersze zadania poznawcze, ale nie są synonimami przetwarzania języka naturalnego. |
Możliwości przetwarzania języka naturalnego
Klasyfikowanie dokumentów przez etykietowanie ich jako poufne lub spam. Przetwarzanie języka naturalnego automatycznie kategoryzuje dokumenty na podstawie zawartości w celu obsługi zgodności i filtrowania przepływów pracy.
Podsumuj tekst, identyfikując jednostki w dokumencie. Przetwarzanie języka naturalnego wyodrębnia kluczowe jednostki w celu utworzenia zwięzłych podsumowań, które przechwytują najważniejsze informacje.
Oznaczanie dokumentów słowami kluczowymi przy użyciu zidentyfikowanych jednostek. Po zidentyfikowaniu jednostek można wygenerować tagi słów kluczowych, które upraszczają organizację dokumentów. Użyj tych tagów do wyszukiwania opartego na zawartości i pobierania.
Wykrywanie tematów dotyczących nawigacji i odkrywanie powiązanych dokumentów. Przetwarzanie języka naturalnego identyfikuje kluczowe tematy za pomocą wyodrębnionych jednostek, które obsługują kategoryzację dokumentów i nawigację tematyczną.
Ocena tonacji tekstu. Analiza tonacji ocenia emocjonalny ton tekstu i klasyfikuje zawartość jako pozytywną, negatywną lub neutralną.
Przekaż dane wyjściowe przetwarzania języka naturalnego do podrzędnych przepływów pracy. Wyniki, takie jak wyodrębnione jednostki, oceny tonacji i etykiety tematów, służą jako dane wejściowe do przetwarzania, indeksowania wyszukiwania i analizy.
Identyfikowanie potencjalnych przypadków użycia
Scenariusze biznesowe w wielu branżach korzystają z rozwiązań przetwarzania języka naturalnego. W poniższych przypadkach użycia pokazano, jak techniki przetwarzania języka naturalnego odnoszą się do rzeczywistych wyzwań, od przetwarzania dokumentów bez struktury w celu umożliwienia pojawiającym się aplikacjom w zakresie cyberbezpieczeństwa i ułatwień dostępu.
Przetwarzanie dokumentów i tekstu bez struktury
Wyodrębnianie analizy z dokumentów utworzonych przez maszynę. Przetwarzanie języka naturalnego umożliwia przetwarzanie dokumentów w różnych sektorach finansów, opieki zdrowotnej, handlu detalicznego, instytucji rządowych i innych sektorów. Możesz analizować dokumenty utworzone cyfrowo, aby wyodrębnić informacje ustrukturyzowane z danych wejściowych bez struktury. W przypadku dokumentów odręcznych użyj Azure Document Intelligence aby przekonwertować zawartość odręczną na tekst przed zastosowaniem technik przetwarzania języka naturalnego.
Zastosuj niezależne od branży zadania przetwarzania języka naturalnego na potrzeby przetwarzania tekstu. Rozpoznawanie nazwanych jednostek (NER), klasyfikacja, podsumowanie i wyodrębnianie relacji ułatwiają automatyczne przetwarzanie i analizowanie zawartości dokumentu bez struktury. Te zadania działają w różnych domenach i nie wymagają dostosowania specyficznego dla branży.
Tworzenie modeli specyficznych dla domeny na potrzeby wyspecjalizowanej analizy. Przykłady tych zadań obejmują modele stratyfikacji ryzyka dla opieki zdrowotnej, klasyfikację ontologii na potrzeby zarządzania wiedzą oraz podsumowania dotyczące danych sprzedaży detalicznej dla danych o produktach i klientach. Trenowanie modeli niestandardowych w Azure Language i Spark NLP pomaga poprawić dokładność formatów dokumentów specyficznych dla danej domeny.
Generowanie zautomatyzowanych raportów na podstawie danych wejściowych strukturalnych. Możesz syntetyzować i generować kompleksowe raporty tekstowe na podstawie danych strukturalnych. Ta funkcja ułatwia sektorom, takim jak finanse i zgodność, które wymagają dokładnej dokumentacji.
Włączanie wyszukiwania, tłumaczenia i analizy
Tworzenie grafów wiedzy i włączanie semantycznego wyszukiwania za pomocą pobierania informacji. Przetwarzanie języka naturalnego obsługuje tworzenie grafu wiedzy i wyszukiwanie semantyczne, co pozwala systemom interpretować znaczenie zapytania, a nie polegać tylko na dopasowywaniu słów kluczowych.
Wspieranie odnajdywania leków i badań klinicznych za pomocą grafów wiedzy medycznej. Systemy przetwarzania języka naturalnego analizują tekst kliniczny. Wykresy wiedzy medycznej utworzone na podstawie tego tekstu wspierają procesy odkrywania leków i dopasowywania badań klinicznych. Te grafy łączą jednostki, takie jak leki, warunki i wyniki, aby przyspieszyć przepływy pracy badań. Text analytics for health in Azure Language wyodrębnia jednostki medyczne, relacje i asercje, których można użyć do konstruowania tych grafów.
Tłumaczenie tekstu dla konwersacyjnej sztucznej inteligencji w aplikacjach przeznaczonych dla klientów. Tłumaczenie tekstu umożliwia konwersacyjną sztuczną inteligencję w wielu branżach. Możesz tworzyć wielojęzyczne aplikacje dla klientów, które przetwarzają i reagują w preferowanym języku użytkownika. Usługa Spark NLP zapewnia możliwości tłumaczenia bezpośrednio. W Azure użyj Azure Translator która jest oddzielną usługą od języka Azure.
Analiza nastrojów i inteligencji emocjonalnej w kontekście percepcji marki. Analiza tonacji pomaga monitorować postrzeganie marki i analizować opinie klientów, wyrażając pozytywne, negatywne i zniuansowane sygnały emocjonalne z tekstu.
Rozszerzanie przetwarzania języka naturalnego na nowe domeny
Twórz interfejsy aktywowane głosowo dla internetu rzeczy (IoT) i inteligentnych urządzeń. Przetwarzanie języka naturalnego obsługuje dane wyjściowe tekstu systemów rozpoznawania mowy w celu zrozumienia intencji użytkownika i wyodrębnienia znaczenia w scenariuszach IoT i inteligentnych urządzeń. Scenariusze aktywowane głosowo wymagają Azure speech do konwersji mowy na tekst przed przetwarzaniem języka naturalnego.
Dynamiczne dostosowywanie danych wyjściowych języka przy użyciu modeli języka adaptacyjnego. Modele adaptacyjne języka dynamicznie dostosowują dane wyjściowe językowe, aby odpowiadały różnym poziomom zrozumienia odbiorców, które obsługują dostarczanie treści edukacyjnych i ułatwienia dostępu.
Wykrywanie wyłudzania informacji i dezinformacji za pośrednictwem analizy tekstu cyberbezpieczeństwa. Przetwarzanie języka naturalnego analizuje wzorce komunikacji i użycie języka w czasie rzeczywistym, aby zidentyfikować potencjalne zagrożenia bezpieczeństwa w komunikacji cyfrowej. Ta analiza pomaga wykrywać próby wyłudzania informacji i kampanie dezinformacji.
Ocena języka Azure
Azure Language to oparta na chmurze usługa udostępniająca funkcje przetwarzania języka naturalnego do zrozumienia i analizowania tekstu. Dostęp do niego można uzyskać za pośrednictwem portalu Foundry, interfejsów API REST i bibliotek klienckich Python, C#, Java i JavaScript bez infrastruktury do zarządzania. W przypadku tworzenia agenta sztucznej inteligencji można również uzyskać dostęp do tych funkcji za pośrednictwem serwera Azure Language Model Context Protocol (MCP). Dostęp do niego można uzyskać jako serwer zdalny w katalogu narzędzi Microsoft Foundry lub jako lokalny serwer hostowany samodzielnie.
Przygotowane funkcje
Wstępnie utworzone funkcje nie wymagają trenowania modelu i są gotowe do użycia:
NER: Identyfikuje i kategoryzuje jednostki w tekście na wstępnie zdefiniowane typy, takie jak osoby, organizacje, lokalizacje i daty.
Wykrywanie danych PII: Identyfikuje i redaguje dane osobowe, w tym dane wrażliwe osobowe i zdrowotne, w tekstach i transkrypcjach konwersacji.
Wykrywanie języka: Wykrywa język dokumentu w wielu różnych językach i dialektach.
Analiza tonacji i wyszukiwania opinii: Identyfikuje pozytywną, negatywną lub neutralną tonację w tekście i łączy opinie z określonymi elementami, takimi jak atrybuty produktu lub aspekty usługi.
Wyodrębnianie kluczowych fraz: Ocenia tekst bez struktury i zwraca listę głównych pojęć i kluczowych fraz.
Podsumowanie: Kondensuje dokumenty i konwersacje przy użyciu podejścia wyodrębniającego lub abstrakcyjnego, które wspiera podsumowanie tekstu, czatu i centrum obsługi klienta.
Analiza tekstu pod kątem zdrowia: Wyodrębnia i oznacza odpowiednie informacje o zdrowiu z nieustrukturyzowanego tekstu klinicznego, w tym jednostki medyczne, relacje i asercje.
Trenowanie modeli niestandardowych
Za pomocą funkcji dostosowywalnych można trenować modele na danych w celu obsługi zadań przetwarzania języka naturalnego specyficznych dla domeny:
- Niestandardowe rozpoznawanie nazwanych jednostek (CNER): Tworzenie modeli niestandardowych w celu wyodrębnienia kategorii jednostek specyficznych dla domeny z tekstu bez struktury. Użyj CNER, gdy wstępnie utworzone kategorie NER nie obejmują słownictwa domeny.
Azure Language MCP server and agents (Serwer i agenci MCP języka Azure)
Notatka
Serwer MCP języka Azure oraz system routingu intencji i agent odpowiadający na dokładne pytania są w wersji zapoznawczej. Funkcje w wersji zapoznawczej nie obejmują umowy dotyczącej poziomu usług (SLA) i nie zalecamy ich obsługi w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą nie być obsługiwane lub mogą mieć ograniczone możliwości. Aby uzyskać więcej informacji, zobacz Dodatkowe warunki użytkowania dla Microsoft Azure wersji zapoznawczej.
język Azure udostępnia wstępnie utworzonych agentów i elastyczne opcje wdrażania dla produkcyjnych obciążeń przetwarzania języka naturalnego:
Agent trasowania intencji: Zarządza przepływem konwersacji. Rozumie intencje i trasy użytkowników w celu dokładnej odpowiedzi za pomocą deterministycznej, kontrolowanej logiki. Użyj tego agenta, gdy potrzebujesz przezroczystego, deterministycznego routingu konwersacyjnego.
Dokładny agent odpowiedzi na pytania: Zapewnia niezawodne odpowiedzi word-for-word na pytania krytyczne dla działania firmy przy zachowaniu nadzoru człowieka i kontroli jakości. Użyj tego agenta, gdy dokładność odpowiedzi i spójność są niezbędne.
Dostęp do obu agentów można uzyskać za pośrednictwem katalogu narzędzi Foundry. Aby uzyskać więcej informacji, zobacz Azure Language MCP server and agents (preview).
Serwer MCP języka Azure obsługuje wiele opcji wdrażania:
Zdalny serwer MCP hostowany w chmurze: Wykaz narzędzi foundry zawiera listę tego serwera. Serwer zapewnia zarządzany przez chmurę dostęp do funkcji języka Azure i nie wymaga lokalnej infrastruktury.
Lokalny własny serwer MCP: Obsługuje wdrożenia lokalne lub samoobsługowe na potrzeby zgodności, zabezpieczeń lub rezydencji danych.
Wdrożenie konteneryzowane: Poniższe funkcje obsługują konteneryzowane wdrażanie w scenariuszach, które wymagają lokalnego przetwarzania lub środowiska z przerwami w powietrzu. Aby uzyskać pełną listę dostępnych kontenerów i ich statusu dostępności, zobacz Wsparcie dla kontenerów Azure AI.
- Analiza emocji
- Wykrywanie języka
- Wyciąganie kluczowych fraz
- rozpoznawanie jednostek nazwanych
- Wykrywanie danych osobowych (PII)
- CNER
- Analiza tekstu dla opieki zdrowotnej
- Podsumowanie (wersja zapoznawcza)
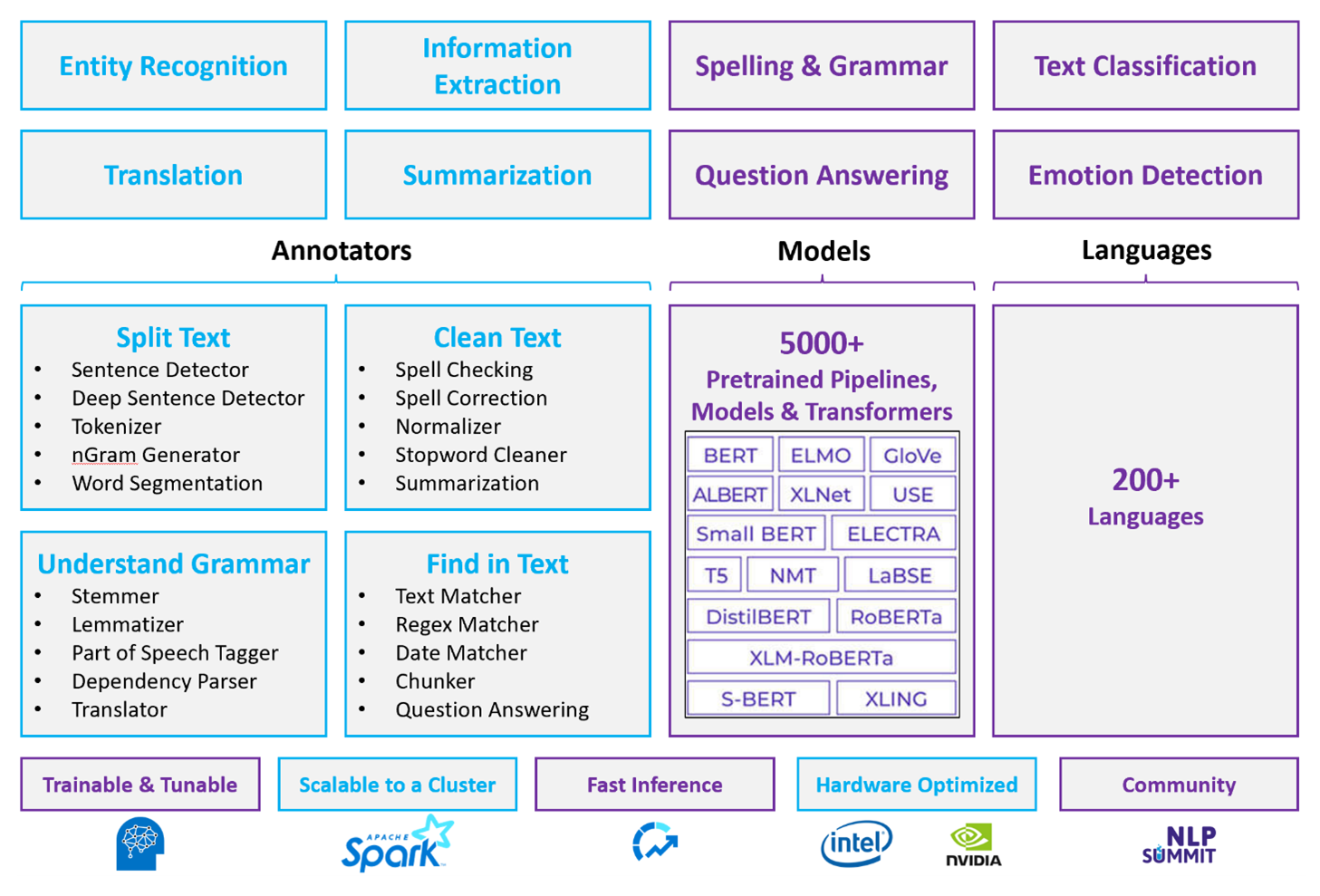
Ocena platformy Apache Spark za pomocą Spark NLP
Platforma Apache Spark z Spark NLP to rozproszone podejście open source do przetwarzania języka naturalnego, które działa na dużą skalę klastra. Architektura platformy Spark NLP, wydajność i wstępnie zbudowany ekosystem modeli sprawiają, że jest to silna opcja dla obciążeń związanych z przetwarzaniem języka naturalnego na dużą skalę i dostosowywalnych w Azure Databricks lub Fabric.
Omówienie platformy i architektury
Zalecamy użycie Fabric lub Azure Databricks dla obciążeń przetwarzania języka naturalnego opartego na platformie Apache Spark.
Platforma Apache Spark zapewnia równoległe przetwarzanie w pamięci na potrzeby analizy danych big data. Fabric i Azure Databricks zapewniają dostęp do możliwości przetwarzania platformy Apache Spark dla obciążeń przetwarzania języka naturalnego na dużą skalę.
Spark NLP działa jako natywne rozszerzenie Spark ML na ramach danych. Ta integracja umożliwia ujednolicone przetwarzanie języka naturalnego i potoki uczenia maszynowego o lepszej wydajności w klastrach rozproszonych.
Spark NLP to biblioteka typu open source z obsługą Python, Java i Języka Scala. Biblioteka udostępnia funkcje porównywalne z spaCy i Natural Language Toolkit (NLTK), w tym sprawdzanie pisowni, analiza tonacji i klasyfikacja dokumentów.

Apache®, Apache Spark oraz logo płomienia są zastrzeżonymi znakami towarowymi lub znakami towarowymi Fundacji Apache Software Foundation w Stanach Zjednoczonych oraz/lub innych krajach. Użycie tych znaków nie sugeruje poparcia przez The Apache Software Foundation.
Ocena wydajności i skalowalności
Publiczne testy porównawcze pokazują znaczne ulepszenia szybkości w innych bibliotekach przetwarzania języka naturalnego. W porównaniu z platformami, takimi jak spaCy i NLTK, usługa Spark NLP demonstruje szybsze trenowanie i wnioskowanie w klastrach rozproszonych. Modele niestandardowe, które są trenowane przez Spark NLP, osiągają poziomy dokładności porównywalne z innymi platformami przetwarzania języka naturalnego, co czyni go odpowiednim do obciążeń produkcyjnych wymagających szybkości i precyzji.
Zoptymalizowane kompilacje dla procesorów CPU, procesorów GPU i procesorów Intel Xeon w pełni używają klastrów Apache Spark. Te kompilacje umożliwiają trenowanie i wnioskowanie w celu wydajnego skalowania między węzłami klastra.
Osadzenia MPNet i obsługa ONNX umożliwiają precyzyjne przetwarzanie z uwzględnieniem kontekstu. Sieć MPNet tworzy gęste reprezentacje wektorów, które przechwytują znaczenie semantyczne, a obsługa ONNX umożliwia importowanie i uruchamianie zoptymalizowanych modeli na potrzeby wnioskowania.
Używanie wstępnie utworzonych modeli i pipeline'ów
Wstępnie utworzone modele uczenia głębokiego obsługują rozpoznawanie nazwanych jednostek (NER), klasyfikację dokumentów oraz analizę sentymentu. Biblioteka zawiera wstępnie utworzone modele uczenia głębokiego.
Wstępnie wytrenowane modele językowe obsługują osadzanie wyrazów, fragmentów, zdań i dokumentów. Biblioteka zawiera wstępnie wytrenowane modele językowe, które obsługują poziomy osadzania wyrazów, fragmentów, zdań i dokumentów. Te osadzania zapewniają gęste reprezentacje wektorów, które umożliwiają podrzędne zadania, takie jak wyszukiwanie podobieństwa i klasyfikacja.
Ujednolicone przetwarzanie języka naturalnego i potoki uczenia maszynowego obsługują klasyfikację dokumentów i przewidywanie ryzyka. Integracja z usługą Spark ML obsługuje ujednolicone przetwarzanie języka naturalnego i potoki uczenia maszynowego na potrzeby zadań takich jak klasyfikacja dokumentów i przewidywanie ryzyka. Dzięki temu ujednoliconemu podejściu można połączyć przetwarzanie tekstu z tradycyjnymi modelami uczenia maszynowego w jednym potoku, co zmniejsza złożoność architektury.
Rozwiązywanie typowych problemów z przetwarzaniem języka naturalnego
Zarówno Azure Language, jak i Apache Spark with Spark NLP napotykają typowe wyzwania związane z przetwarzaniem języka naturalnego na dużą skalę. Jeśli rozumiesz te wyzwania, możesz zaplanować zasoby, zaprojektować procesy projektowe i ustalić oczekiwania dotyczące dokładności przed zatwierdzeniem jednej z tych opcji.
Przetwarzanie zasobów
Przetwarzanie tekstu wolnego formularza wymaga znacznych zasobów obliczeniowych i czasu. Dokumenty tekstowe w dowolnej formie są kosztowne obliczeniowo i czasochłonne do analizowania. Każdy dokument wymaga tokenizacji, normalizacji i wnioskowania modelu przed wygenerowaniem użytecznych wyników.
Obciążenia nlp platformy Spark często wymagają wdrożenia obliczeń procesora GPU. W przypadku dużych potoków Spark NLP klastry z akceleracją GPU na platformach Azure Databricks lub Fabric zapewniają wymaganą moc przetwarzania równoległego do treningu i wnioskowania. Optymalizacje, takie jak kwantyzacja modelu Llama 3.x, pomagają zmniejszyć zużycie pamięci i zwiększyć przepływność tych intensywnych zadań.
Azure Language wymaga planowania przepływności i zarządzania limitami przydziału. Usługa obsługuje zarządzanie zasobami, ale wywołania interfejsu API o dużej liczbie wywołań wymagają starannego planowania przepustowości. Monitoruj stawki żądań względem limitów usług i limitów szybkości, aby uniknąć ograniczania przepustowości i zapewnić spójną wydajność przetwarzania.
Standaryzacja dokumentów
Rzeczywiste dokumenty rzadko są zgodne ze spójną strukturą. Ta niespójność stwarza wyzwania dla potoków wyodrębniania i wymaga celowych strategii utrzymania dokładności między źródłami.
Niespójne formaty: Bez ustandaryzowanego formatu dokumentu wyodrębnianie określonych faktów z tekstu wolnego może być trudne. Na przykład może być wyzwaniem wyodrębnienie numerów faktur i dat od różnych dostawców, ponieważ układy pól, etykiety i formatowanie różnią się w różnych źródłach.
Trenowanie modelu niestandardowego: Podczas trenowania modeli niestandardowych w usługach Spark NLP i Azure Language można dostosować się do formatów dokumentów specyficznych dla domeny. Podczas trenowania na reprezentatywnych próbkach rzeczywistych dokumentów można zwiększyć dokładność wyodrębniania pól, jednostek i wzorców, które wstępnie utworzone modele nie obsługują dobrze.
Różnorodność i złożoność danych
Zróżnicowane struktury dokumentów i niuanse językowe dodają złożoność. Dane tekstowe w świecie rzeczywistym są dostępne w wielu formatach, stylach pisania i językach. Rozwiązanie tych odmian wymaga modeli, które mogą obsługiwać niejednoznaczność, slang, skróty i terminologię specyficzną dla domeny przy zachowaniu dokładności.
Osadzenia MPNet w Spark NLP zapewniają lepsze zrozumienie kontekstu. Osadzenia MPNet przechwytują kontekstowe relacje między wyrazami i frazami, co pomaga potokom Spark NLP efektywniej obsługiwać zniuansowany tekst. Te osadzania tworzą gęste reprezentacje wektorów, które zachowują znaczenie semantyczne w różnych formatach dokumentów.
Modele niestandardowe w języku Azure dostosowują się do wzorców tekstu specyficznych dla domeny. Za pomocą narzędzia CNER można trenować modele na własnych danych oznaczonych etykietami, aby rozpoznawać wzorce specyficzne dla twojej domeny. Takie podejście zwiększa niezawodność, ucząc model rozpoznawania jednostek i kategorii, które wstępnie utworzone modele przegapią.
Zastosowanie kluczowych kryteriów wyboru
Użyj poniższych kryteriów, aby określić, która opcja przetwarzania języka naturalnego Azure najlepiej odpowiada Twoim wymaganiom. Każde kryterium opisuje charakterystykę obciążenia i identyfikuje usługę, która go obsługuje.
Zarządzane możliwości przetwarzania języka naturalnego: Użyj interfejsów API Azure Language do rozpoznawania jednostek, identyfikacji intencji, wykrywania tematów lub analizy nastrojów. Te funkcje są dostępne jako usługi zarządzane z minimalną konfiguracją i nie trzeba aprowizować żadnej infrastruktury ani zarządzać nią.
Wstępnie zbudowane lub wstępnie wytrenowane modele: Użyj Azure Language, jeśli planujesz używać wstępnie zbudowanych lub wstępnie wytrenowanych modeli bez zarządzania infrastrukturą. Takie podejście pasuje do małych i średnich zestawów danych i standardowych zadań przetwarzania języka naturalnego, w których wstępnie utworzone modele zapewniają wystarczającą dokładność. Zapewnia ona automatyczne skalowanie, wbudowane zabezpieczenia i rozliczanie w modelu płatności za wywołanie bez obciążenia związanego z zarządzaniem klastrem.
Trenowanie modelu niestandardowego w dużych zestawach danych tekstowych: Użyj Azure Databricks lub Fabric z Spark NLP. Te platformy zapewniają moc obliczeniową i elastyczność, której potrzebujesz do rozbudowanego trenowania modelu w dużych zestawach danych tekstowych. Modele można również pobrać za pośrednictwem usługi Spark NLP, w tym Llama 3.x i MPNet.
Podstawowe operacje przetwarzania języka naturalnego: Użyj Azure Databricks lub Fabric z usługą Spark NLP na potrzeby tokenizacji, przycinania, lemmatyzacji i funkcji TF-IDF. Alternatywnie należy użyć biblioteki open source, takiej jak spaCy lub NLTK. Azure Language in Foundry Tools używa tokenizacji wewnętrznie w ramach potoku modelu, ale nie ujawnia tych kroków jako autonomicznych, kontrolowalnych interfejsów API.
Tworzenie potoków przetwarzania języka naturalnego przy użyciu usługi Spark NLP
Podczas uruchamiania potoku przetwarzania języka naturalnego Spark NLP stosuje ten sam wzorzec rozwoju jak tradycyjne modele Spark ML. Zarządza się wytrenowanymi modelami przy użyciu platformy MLflow do śledzenia eksperymentów i wdrażania produkcyjnego.

Zmontuj podstawowe składniki potoku
Potok NLP Spark łączy adnotacje w sekwencję. Każdy anotator przekształca wynik poprzedniego etapu i buduje z nieprzetworzonego tekstu do wektorów semantycznych.
DocumentAssembler to punkt wejścia dla każdego potoku nlp platformy Spark. Użyj
setCleanupModedo przeprowadzenia opcjonalnego przetwarzania wstępnego tekstu, takiego jak usuwanie tagów HTML lub normalizacja białych znaków, przed uruchomieniem dalszego przetwarzania przez anotatory podrzędne.Funkcja SentenceDetector identyfikuje granice zdań w zebranym dokumencie. Zwraca wykryte zdania w postaci
Arrayw obrębie jednego wiersza lub jako oddzielne wiersze, w zależności od konfiguracji potoku. Dokładne wykrywanie zdań jest ważne, ponieważ wiele podrzędnych adnotacji działa na poziomie zdania.Tokenizer dzieli nieprzetworzone tekst na tokeny dyskretne, takie jak wyrazy, liczby i symbole. Jeśli reguły domyślne nie są wystarczające dla twojej domeny, dodaj reguły niestandardowe do obsługi wyspecjalizowanego słownictwa, terminów łączników lub wzorców specyficznych dla domeny.
Normalizator uściśla tokeny, stosując wyrażenia regularne i przekształcenia słownika. Czyści tekst w celu zmniejszenia szumu przed osadzeniem. Można na przykład usuwać akcenty, konwertować na małe litery lub stosować niestandardowe mapowania słowników w celu standaryzacji terminologii.
WordEmbeddings mapuje tokeny na wektory semantyczne na potrzeby przetwarzania kontekstowego. Każdy token jest reprezentowany jako gęsty wektor, który przechwytuje jego znaczenie względem innych tokenów. Nierozwiązane tokeny, które nie są wyświetlane w słownictwie osadzania, domyślnie mają wartość zero wektorów.
Zarządzanie modelami przy użyciu biblioteki MLflow
Spark NLP używa potoków Spark MLlib z natywną obsługą MLflow. Nie musisz pisać niestandardowej serializacji ani kodu integracji.
Rozwiązanie MLflow zarządza śledzeniem eksperymentów, przechowywaniem wersji modeli i wdrażaniem. Parametry pipeline, metryki i artefakty można rejestrować podczas przebiegów trenowania. Platforma MLflow śledzi każdy eksperyment, dzięki czemu można porównać wyniki między iteracjami i odtworzyć pomyślne konfiguracje.
Rozwiązanie MLflow integruje się bezpośrednio z Azure Databricks i Fabric. W Azure Databricks platforma MLflow jest wstępnie zainstalowana i ściśle integruje się z obszarem roboczym. Fabric udostępnia również wbudowane środowisko MLflow z natywnym śledzeniem eksperymentów i automatycznym rejestrowaniem, dzięki czemu nie trzeba instalować MLflow osobno. Jeśli uruchamiasz usługę Spark NLP w innym środowisku opartym na platformie Apache Spark, możesz zainstalować narzędzie MLflow oddzielnie i skonfigurować go do śledzenia eksperymentów na serwerze śledzenia zdalnego.
Użyj rejestru modeli MLflow, aby wdrożyć modele do produkcji i zachować nadzór. Rejestr modeli udostępnia centralne repozytorium do zarządzania wersjami modeli w potokach przetwarzania języka naturalnego. W przypadku wdrożeń klasycznych modele przechodzą przez etapy, takie jak przejściowe, produkcyjne i zarchiwizowane. W Azure Databricks nowsze wdrożenia używają Modeli w Unity Catalog, co zastępuje stałe etapy niestandardowymi aliasami i tagami dla bardziej elastycznego zarządzania cyklem życia. W Fabric obszar roboczy udostępnia własny rejestr modeli oparty na platformie MLflow.
Macierz możliwości
W poniższych tabelach podsumowano kluczowe różnice w możliwościach między usługą Spark NLP w Azure Databricks lub Fabric i Azure Language.
Ogólne możliwości
| Zdolność | Spark NLP (Azure Databricks lub Fabric) | język Azure |
|---|---|---|
| Wstępnie wytrenowane modele jako usługa | Tak | Tak |
| interfejs API REST | Tak | Tak |
| Programowalność | Python, Scala | Zobacz Obsługiwane języki programowania. |
| Obsługuje przetwarzanie dużych zestawów danych i dużych dokumentów | Tak | Ograniczone 1 |
1.Azure Language ma limity rozmiaru dokumentu na żądanie, które różnią się w zależności od trybu. Żądania synchroniczne obsługują maksymalnie 5120 znaków na dokument, a żądania asynchroniczne obsługują maksymalnie 125 000 znaków na dokument. Oba tryby obsługują maksymalnie 25 dokumentów na wywołanie interfejsu API. Duże woluminy zestawów danych można przetwarzać za pomocą dzielenia na partie i stronicowania, ale poszczególne dokumenty, które przekraczają limit znaków dla wybranego trybu, wymagają fragmentowania. Aby uzyskać więcej informacji, zobacz Data and rate limits for Azure Language.
Możliwości adnotacji
| Zdolność | Spark NLP (Azure Databricks lub Fabric) | język Azure |
|---|---|---|
| Detektor zdań | Tak | Nie |
| Wykrywacz głębokich zdań | Tak | Nie |
| narzędzie do tokenizacji | Tak | Tylko wewnętrzny (nie uwidoczniony jako autonomiczny interfejs API) |
| Generator n-gramów | Tak | Nie |
| segmentacja słów | Tak | Tak |
| Stemmer | Tak | Nie |
| Lematyzator | Tak | Nie |
| Tagowanie części mowy | Tak | Nie |
| Analizator zależności | Tak | Nie |
| Tłumaczenie | Tak | Nie |
| Czyszczenie stopwordów | Tak | Nie |
| Korekta pisowni | Tak | Nie |
| Normalizator | Tak | Tak |
| Narzędzie do dopasowywania tekstu | Tak | Nie |
| TF-IDF | Tak | Nie |
| Mechanizm dopasowywania wyrażeń regularnych | Tak | Ograniczony |
| Dopasowywacz dat | Tak | Ograniczony |
| Dzielnik | Tak | Nie |
Zaawansowane możliwości przetwarzania języka naturalnego
| Zdolność | Spark NLP (Azure Databricks lub Fabric) | język Azure |
|---|---|---|
| Sprawdzanie pisowni | Tak | Nie |
| Podsumowania | Tak | Tak |
| Odpowiadanie na pytania | Tak | Tak |
| Wykrywanie emocji | Tak | Tak |
| Wykrywanie emocji | Tak | Ograniczone 2 |
| Klasyfikacja tokenów | Tak | Ograniczone 3 |
| Klasyfikacja tekstu | Tak | Ograniczone 3 |
| Reprezentacja tekstu | Tak | Nie |
| rozpoznawanie jednostek nazwanych | Tak | Tak (przygotowane wcześniej). Model CNER jest dostępny za pośrednictwem modeli niestandardowych. 3 |
| Wykrywanie języka | Tak | Tak |
| Obsługuje języki inne niż angielski | Tak. Zobacz Języki obsługiwane przez usługę Spark NLP. | Tak. Zobacz języki obsługiwane Azure Language. |
2.Azure Język obsługuje analizę opinii, która identyfikuje sentymenty związane z określonymi aspektami tekstu, ale nie oferuje dedykowanego wykrywania emocji, takiej jak klasyfikacja radości, gniewu lub smutku.
3. Dostępneza pośrednictwem modeli dostosowanych. Użytkownik trenuje modele CNER lub dostosowane modele rozpoznawania jednostek na danych oznaczonych przez użytkownika.
Współpracownicy
Microsoft aktualizuje ten artykuł. Następujący współautorzy napisali ten artykuł.
Główni autorzy:
- Ananya Ghosh Chowdhury | Główny architekt rozwiązań w chmurze
- Kranthi Manchikanti | Starszy inżynier rozwiązań sztucznej inteligencji
Inni współautorzy:
- Freddy Ayala | Architekt rozwiązań w chmurze
- Tincy Elias | Starszy architekt rozwiązań w chmurze
- Moritz Steller | Starszy architekt rozwiązań w chmurze
Aby wyświetlić profile LinkedIn niepublikacyjnych, zaloguj się do LinkedIn.
Następne kroki
- Wprowadzenie do sztucznej inteligencji w Azure
- Opracowywanie rozwiązań przetwarzania języka naturalnego przy użyciu narzędzi Foundry
Powiązane zasoby
dokumentacja języka Azure:
- omówienie języka Azure
- Dokumentacja usługi Foundry
Dokumentacja nlp platformy Spark:
Składniki Azure
Zasoby platformy Learn: