Wizualizowanie metryk usługi Azure Databricks za pomocą pulpitów nawigacyjnych
Uwaga
Ten artykuł opiera się na bibliotece open source hostowanej w witrynie GitHub pod adresem : https://github.com/mspnp/spark-monitoring.
Oryginalna biblioteka obsługuje środowiska Azure Databricks Runtimes 10.x (Spark 3.2.x) i starsze.
Usługa Databricks udostępniła zaktualizowaną wersję do obsługi środowiska Azure Databricks Runtimes 11.0 (Spark 3.3.x) i nowszego w l4jv2 gałęzi pod adresem : https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Należy pamiętać, że wersja 11.0 nie jest zgodna z poprzednimi wersjami ze względu na różne systemy rejestrowania używane w środowiskach Databricks Runtime. Pamiętaj, aby użyć poprawnej kompilacji środowiska Databricks Runtime. Biblioteka i repozytorium GitHub są w trybie konserwacji. Nie ma planów dalszych wydań, a pomoc techniczna dotycząca problemów będzie dostępna tylko w najlepszym celu. Aby uzyskać dodatkowe pytania dotyczące biblioteki lub planu monitorowania i rejestrowania środowisk usługi Azure Databricks, skontaktuj się z .azure-spark-monitoring-help@databricks.com
W tym artykule pokazano, jak skonfigurować pulpit nawigacyjny narzędzia Grafana w celu monitorowania zadań usługi Azure Databricks pod kątem problemów z wydajnością.
Usługa Azure Databricks to szybka, zaawansowana i oparta na współpracy usługa analizy oparta na platformie Apache Spark, która ułatwia szybkie opracowywanie i wdrażanie rozwiązań do analizy danych big data i sztucznej inteligencji (AI). Monitorowanie jest krytycznym składnikiem obsługi obciążeń usługi Azure Databricks w środowisku produkcyjnym. Pierwszym krokiem jest zebranie metryk w obszarze roboczym na potrzeby analizy. Na platformie Azure najlepszym rozwiązaniem do zarządzania danymi dzienników jest usługa Azure Monitor. Usługa Azure Databricks nie obsługuje natywnie wysyłania danych dziennika do usługi Azure Monitor, ale biblioteka dla tej funkcji jest dostępna w usłudze GitHub.
Ta biblioteka umożliwia rejestrowanie metryk usługi Azure Databricks oraz metryk zapytań przesyłania strumieniowego struktury platformy Apache Spark. Po pomyślnym wdrożeniu tej biblioteki w klastrze usługi Azure Databricks można jeszcze bardziej wdrożyć zestaw pulpitów nawigacyjnych narzędzia Grafana , które można wdrożyć w ramach środowiska produkcyjnego.
Wymagania wstępne
Skonfiguruj klaster usługi Azure Databricks do korzystania z biblioteki monitorowania zgodnie z opisem w pliku readme usługi GitHub.
Wdrażanie obszaru roboczego usługi Azure Log Analytics
Aby wdrożyć obszar roboczy usługi Azure Log Analytics, wykonaj następujące kroki:
Przejdź do
/perftools/deployment/loganalyticskatalogu.Wdróż szablon usługi Azure Resource Manager logAnalyticsDeploy.json. Aby uzyskać więcej informacji na temat wdrażania szablonów usługi Resource Manager, zobacz Wdrażanie zasobów przy użyciu szablonów usługi Resource Manager i interfejsu wiersza polecenia platformy Azure. Szablon ma następujące parametry:
- location: region, w którym wdrożono obszar roboczy i pulpity nawigacyjne usługi Log Analytics.
- serviceTier: warstwa cenowa obszaru roboczego. Zobacz tutaj , aby uzyskać listę prawidłowych wartości.
- dataRetention (opcjonalnie): liczba dni przechowywania danych dziennika w obszarze roboczym usługi Log Analytics. Wartość domyślna to 30 dni. Jeśli warstwa cenowa to
Free, przechowywanie danych musi wynosić siedem dni. - workspaceName (opcjonalnie): nazwa obszaru roboczego. Jeśli nie zostanie określony, szablon generuje nazwę.
az deployment group create --resource-group <resource-group-name> --template-file logAnalyticsDeploy.json --parameters location='East US' serviceTier='Standalone'
Ten szablon tworzy obszar roboczy, a także tworzy zestaw wstępnie zdefiniowanych zapytań używanych przez pulpit nawigacyjny.
Wdrażanie narzędzia Grafana na maszynie wirtualnej
Grafana to projekt typu open source, który można wdrożyć w celu wizualizacji metryk szeregów czasowych przechowywanych w obszarze roboczym usługi Azure Log Analytics przy użyciu wtyczki Grafana dla usługi Azure Monitor. Narzędzie Grafana jest wykonywane na maszynie wirtualnej i wymaga konta magazynu, sieci wirtualnej i innych zasobów. Aby wdrożyć maszynę wirtualną z obrazem Grafana z certyfikatem Bitnami i skojarzonymi zasobami, wykonaj następujące kroki:
Użyj interfejsu wiersza polecenia platformy Azure, aby zaakceptować warunki obrazu witryny Azure Marketplace dla aplikacji Grafana.
az vm image terms accept --publisher bitnami --offer grafana --plan defaultPrzejdź do
/spark-monitoring/perftools/deployment/grafanakatalogu w lokalnej kopii repozytorium GitHub.Wdróż szablon usługi grafanaDeploy.json Resource Manager w następujący sposób:
export DATA_SOURCE="https://raw.githubusercontent.com/mspnp/spark-monitoring/master/perftools/deployment/grafana/AzureDataSource.sh" az deployment group create \ --resource-group <resource-group-name> \ --template-file grafanaDeploy.json \ --parameters adminPass='<vm password>' dataSource=$DATA_SOURCE
Po zakończeniu wdrażania na maszynie wirtualnej zostanie zainstalowany obraz bitnami narzędzia Grafana.
Aktualizowanie hasła narzędzia Grafana
W ramach procesu instalacji skrypt instalacji narzędzia Grafana generuje tymczasowe hasło użytkownika administratora . Aby się zalogować, potrzebujesz tego tymczasowego hasła. Aby uzyskać hasło tymczasowe, wykonaj następujące kroki:
- Zaloguj się w witrynie Azure Portal.
- Wybierz grupę zasobów, w której wdrożono zasoby.
- Wybierz maszynę wirtualną, na której zainstalowano aplikację Grafana. Jeśli w szablonie wdrożenia użyto domyślnej nazwy parametru, nazwa maszyny wirtualnej jest poprzedzona ciągiem sparkmonitoring-vm-grafana.
- W sekcji Pomoc techniczna i rozwiązywanie problemów kliknij pozycję Diagnostyka rozruchu, aby otworzyć stronę diagnostyki rozruchu.
- Kliknij pozycję Dziennik seryjny na stronie diagnostyki rozruchu.
- Wyszukaj następujący ciąg: "Ustawianie hasła aplikacji Bitnami na".
- Skopiuj hasło do bezpiecznej lokalizacji.
Następnie zmień hasło administratora narzędzia Grafana, wykonując następujące kroki:
- W witrynie Azure Portal wybierz maszynę wirtualną i kliknij pozycję Przegląd.
- Skopiuj publiczny adres IP.
- Otwórz przeglądarkę internetową i przejdź do następującego adresu URL:
http://<IP address>:3000. - Na ekranie logowania narzędzia Grafana wprowadź nazwę użytkownika jako administrator i użyj hasła narzędzia Grafana z poprzednich kroków.
- Po zalogowaniu wybierz pozycję Konfiguracja (ikona koła zębatego).
- Wybierz pozycję Administrator serwera.
- Na karcie Użytkownicy wybierz identyfikator logowania administratora.
- Zaktualizuj hasło.
Tworzenie źródła danych usługi Azure Monitor
Utwórz jednostkę usługi, która umożliwia narzędziu Grafana zarządzanie dostępem do obszaru roboczego usługi Log Analytics. Aby uzyskać więcej informacji, zobacz Tworzenie jednostki usługi platformy Azure przy użyciu interfejsu wiersza polecenia platformy Azure
az ad sp create-for-rbac --name http://<service principal name> \ --role "Log Analytics Reader" \ --scopes /subscriptions/mySubscriptionIDZanotuj wartości appId, password i tenant w danych wyjściowych tego polecenia:
{ "appId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "displayName": "azure-cli-2019-03-27-00-33-39", "name": "http://<service principal name>", "password": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }Zaloguj się do aplikacji Grafana zgodnie z wcześniejszym opisem. Wybierz pozycję Konfiguracja (ikona koła zębatego), a następnie pozycję Źródła danych.
Na karcie Źródła danych kliknij pozycję Dodaj źródło danych.
Wybierz pozycję Azure Monitor jako typ źródła danych.
W sekcji Ustawienia wprowadź nazwę źródła danych w polu tekstowym Nazwa.
W sekcji Szczegóły interfejsu API usługi Azure Monitor wprowadź następujące informacje:
- Identyfikator subskrypcji: Identyfikator subskrypcji platformy Azure.
- Identyfikator dzierżawy: identyfikator dzierżawy z wcześniejszej wersji.
- Identyfikator klienta: wartość "appId" z wcześniejszej wersji.
- Klucz tajny klienta: wartość "password" z wcześniejszej wersji.
W sekcji Szczegóły interfejsu API usługi Azure Log Analytics zaznacz pole wyboru Te same szczegóły co interfejs API usługi Azure Monitor.
Kliknij pozycję Zapisz i przetestuj. Jeśli źródło danych usługi Log Analytics jest poprawnie skonfigurowane, zostanie wyświetlony komunikat o powodzeniu.
Tworzenie pulpitu nawigacyjnego
Utwórz pulpity nawigacyjne w narzędziu Grafana, wykonując następujące kroki:
Przejdź do
/perftools/dashboards/grafanakatalogu w lokalnej kopii repozytorium GitHub.Uruchom następujący skrypt:
export WORKSPACE=<your Azure Log Analytics workspace ID> export LOGTYPE=SparkListenerEvent_CL sh DashGen.shDane wyjściowe skryptu to plik o nazwie SparkMonitoringDash.json.
Wróć do pulpitu nawigacyjnego narzędzia Grafana i wybierz pozycję Utwórz (ikona plusa).
Wybierz Importuj.
Kliknij pozycję Przekaż plik .json.
Wybierz plik SparkMonitoringDash.json utworzony w kroku 2.
W sekcji Opcje w obszarze ALA wybierz utworzone wcześniej źródło danych usługi Azure Monitor.
Kliknij przycisk Importuj.
Wizualizacje na pulpitach nawigacyjnych
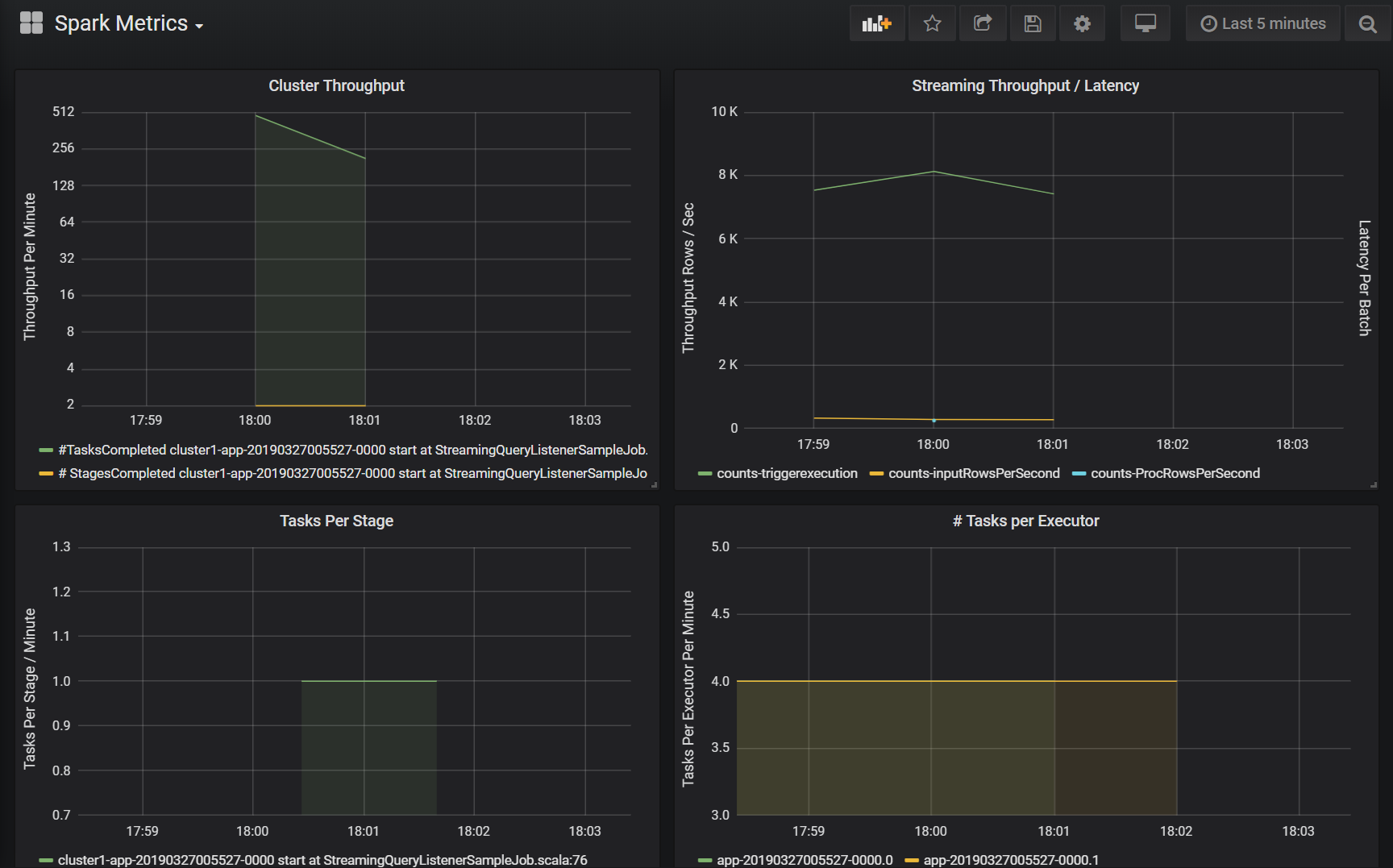
Pulpity nawigacyjne usługi Azure Log Analytics i Grafana obejmują zestaw wizualizacji szeregów czasowych. Każdy graf to wykres szeregów czasowych danych metryk związanych z zadaniem platformy Apache Spark, etapami zadania i zadaniami, które składają się na każdy etap.
Wizualizacje to:
Opóźnienie zadania
Ta wizualizacja przedstawia opóźnienie wykonywania zadania, które jest grubszym widokiem na ogólną wydajność zadania. Wyświetla czas trwania wykonywania zadania od początku do ukończenia. Należy pamiętać, że czas rozpoczęcia zadania nie jest taki sam jak czas przesyłania zadania. Opóźnienie jest reprezentowane jako percentyle (10%, 30%, 50%, 90%) wykonania zadania indeksowane według identyfikatora klastra i identyfikatora aplikacji.
Opóźnienie etapu
Wizualizacja przedstawia opóźnienie każdego etapu na klaster, aplikację i poszczególne etapy. Ta wizualizacja jest przydatna do identyfikowania konkretnego etapu, który działa wolno.
Opóźnienie zadania
Ta wizualizacja pokazuje opóźnienie wykonywania zadań. Opóźnienie jest reprezentowane jako percentyl wykonywania zadań na klaster, nazwę etapu i aplikację.
Sumowanie wykonywania zadań na hosta
Ta wizualizacja przedstawia sumę opóźnienia wykonywania zadań na hosta uruchomionego w klastrze. Wyświetlanie opóźnienia wykonywania zadań na hoście identyfikuje hosty, które mają znacznie większe ogólne opóźnienie zadań niż inne hosty. Może to oznaczać, że zadania były nieefektywne lub nierównomiernie rozłożone na hosty.
Metryki zadań
Ta wizualizacja przedstawia zestaw metryk wykonywania dla wykonania danego zadania. Te metryki obejmują rozmiar i czas trwania mieszania danych, czas trwania operacji serializacji i deserializacji oraz inne. Aby uzyskać pełny zestaw metryk, wyświetl zapytanie usługi Log Analytics dla panelu. Ta wizualizacja jest przydatna do zrozumienia operacji tworzących zadanie i identyfikowania zużycia zasobów każdej operacji. Skoki na wykresie reprezentują kosztowne operacje, które należy zbadać.
Przepływność klastra
Ta wizualizacja to ogólny widok elementów roboczych indeksowanych przez klaster i aplikację do reprezentowania ilości pracy wykonanej dla klastra i aplikacji. Przedstawia liczbę zadań, zadań i etapów ukończonych dla klastra, aplikacji i etapu w ciągu jednej minuty.
Przepływność/opóźnienie przesyłania strumieniowego
Ta wizualizacja jest powiązana z metrykami skojarzonymi ze ustrukturyzowanym zapytaniem przesyłania strumieniowego. Wykres przedstawia liczbę wierszy wejściowych na sekundę i liczbę przetworzonych wierszy na sekundę. Metryki przesyłania strumieniowego są również reprezentowane dla aplikacji. Te metryki są wysyłane, gdy zdarzenie OnQueryProgress jest generowane w miarę przetwarzania ustrukturyzowanego zapytania przesyłania strumieniowego, a wizualizacja reprezentuje opóźnienie przesyłania strumieniowego jako ilość czasu (w milisekundach) wykonywanego w celu wykonania partii zapytań.
Użycie zasobów na funkcję wykonawcza
Następnie znajduje się zestaw wizualizacji dla pulpitu nawigacyjnego pokazujący określony typ zasobu i sposób jego użycia na funkcję wykonawcza w każdym klastrze. Te wizualizacje pomagają identyfikować wartości odstające w użyciu zasobów na funkcję wykonawcza. Na przykład jeśli alokacja pracy dla określonego wykonawcy jest niesymetryczna, użycie zasobów zostanie podniesione w odniesieniu do innych funkcji wykonawczych uruchomionych w klastrze. Może to być identyfikowane przez skoki zużycia zasobów dla funkcji wykonawczej.
Metryki czasu obliczeniowego funkcji wykonawczej
Następnie jest zestaw wizualizacji dla pulpitu nawigacyjnego, które pokazują stosunek czasu wykonywania serializacji, deserializacji czasu, czasu procesora CPU i czasu maszyny wirtualnej Java do ogólnego czasu wykonywania obliczeń. Pokazuje to wizualnie, ile każda z tych czterech metryk przyczynia się do ogólnego przetwarzania funkcji wykonawczej.
Metryki shuffle
Ostatni zestaw wizualizacji przedstawia metryki mieszania danych skojarzone ze ustrukturyzowanym zapytaniem przesyłania strumieniowego we wszystkich funkcjach wykonawczych. Obejmują one operacje mieszania bajtów odczytu, mieszania bajtów zapisywanych, mieszania pamięci i użycia dysku w zapytaniach, w których jest używany system plików.
Następne kroki
Powiązane zasoby
- Monitorowanie usługi Azure Databricks
- Wysyłanie dzienników aplikacji usługi Azure Databricks do usługi Azure Monitor
- Nowoczesna architektura analizy za pomocą usługi Azure Databricks
- Pozyskiwanie, ETL (wyodrębnianie, przekształcanie, ładowanie) i potoki przetwarzania strumieniowego za pomocą usługi Azure Databricks